

9. Text mining
На сьогодні в особистих ПК, локальних і глобальних мережах накопичено величезну кількість інформації і її обсяг стрімко збільшується. Пошук в гігантських масивах текстових даних і аналіз об'ємних текстів є малоефективними, тому стають затребуваними технології, які спроможні обробляти неструктуровані або слабкоструктуровані тексти.
Зазвичай, для ведення документації більшість організацій користуються природною мовою. За даними аналітиків понад 80% інформації, яка зберігається в документах представлена в текстовій формі.
Text Mining - технологія з автоматичного видобутку знань з великих обсягів текстового матеріалу, що заснована на поєднанні лінгвістичних, семантичних, статистичних методик та машинного навчання.
Новітня технологія Text Mining призначена для виявлення в сирих або частково оброблених даних раніше невідомих нетривіальних практично корисних і доступних до інтерпретації знань, необхідних для прийняття рішень у різних сферах людської діяльності.
Text Mining часто називають текстовим Data Mining. ТМ додає до технології DM додатковий етап - переведення неструктурованих текстових масивів в структуровані. Після чого дані можуть оброблятися за допомогою стандартних методів DM. Якщо DM дозволяє видобувати нові знання (приховані закономірності, факти, невідомі взаємозв'язки тощо) з великих обсягів структурованої інформації (збереженої в сховищах даних), то ТМ призначений знаходити нові знання в неструктурованих текстових масивах.
Історична довідка
Розвиток технології Text Mining припадає на роки правління президента США Річарда Ніксона (1969-1974 рр..). Тоді було виділено десятки мільйонів доларів на розвиток наукових напрямів, пов'язаних з автоматизацією перекладу. Це відбувалося в епоху холодної війни, коли, зокрема, дуже актуальною була задача комп'ютерного перекладу з російської мови на англійську найрізноманітніших документів, починаючи з наукових доповідей і закінчуючи технічною документацією. Цей проект носив закритий характер.
У той же самий час з'явилася нова область знань - Natural Language Processing (NLP), в країнах СНД - комп'ютерна лінгвістика. В 90-х роках у відкритих джерелах стали з'являтися не тільки доповіді з наукових конференцій, але і програмні коди, що дозволило залучити до розробок більш широке міжнародне наукове співтовариство. Найбільш активні в цій галузі вчені США, Великобританії, Франції та Німеччини.
В нашій країні розвиток комп'ютерної лінгвістики мало свою специфіку. Вона розвивалася в основному в інтересах оборонних підприємств і служб безпеки і не була орієнтована на вирішення конкретних бізнес-завдань. Позначилася і відсутність в останні роки цільового фінансування цієї галузі. Тим не менш бурхливий розвиток ЗМІ та Інтернету породжує попит як з боку державних служб, так і з боку комерційних організацій (конкурентна розвідка, наприклад).
Text Mining в системі управління знаннями
Технологія глибинного аналізу тексту Text Mining здатна виступити в ролі «репетитора», який після обробки масиву тексту, викладає лише ключову і значиму інформацію. Користувач позбавляється рутинного перегляду величезної кількості неструктурованої інформації. Розроблені на основі статистичного і лінгвістичного аналізу, а також штучного інтелекту технології Text Mining призначені для проведення змістовного аналізу, забезпечення навігації і пошуку в неструктурованих текстах. Системи, що базуються на технології Text Mining надають користувачу нову цінну інформацію - знання.
Класична схема обробки текстів передбачає кілька послідовних етапів:
Нормалізація слів з врахуванням морфології мови (морфологічний аналіз).
Семантичний аналіз тексту, для визначення конкретного змісту слова залежно від контексту.
Створення семантичного образу вихідного документа, на основі якого робляться інтелектуальні запити на аналіз текстів.
Важливим компонентом технології Text Mining є видобуток з тексту його характерних елементів або властивостей, які можуть використовуватися як метадані документа, ключові слова, анотації. Іншим завданням є віднесення документа до категорій відповідно до заданої схеми їх систематизації.
Технологія аналізу тексту
Сьогодні питання аналізу структурованої інформації в різних прикладних областях в залежності від специфіки завдань вирішені на 90-100%. З точки зору технологій це пояснюється дуже просто: сучасні інструменти аналізу дозволяють "бачити" дані, що зберігаються в БД. На ринку широко представлено звичні для користувачів технології, як OLAP та Data Mining, що засновані на популярних методах статистичної обробки, прогнозування та візуалізації.
В загальному технологія аналізу тексту містить 4 основні етапи
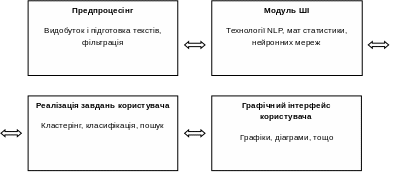
Обов'язковим інструментом ТМ є інформаційні сховища, де буде розміщена оброблена інформація.
Препроцесінг об'єднує технології видобутку та фільтрації текстів, що надходять до обробки.
Модуль Штучного інтелекту відповідає за «розуміння» текстів на природній мові.
Реалізація завдань користувача містить набір технологічних рішень для широкого кола задач:
Класифікація та кластеризація даних.
Отримання структурованої інформації.
Визначення тематики або галузі знань.
Автоматичне реферування документів.
Анотування, суммарізація.
Створення таксономій і тезаурусів.
Задачі автоматичної фільтрації контенту.
Визначення семантичних зв'язків.
Знаходження шаблонів даних.
Пошук за ключовими словами.
Відповідь на запит.
Для вирішення завдань ТМ використовують статистичні методи, методи інтерполяції, апроксимації та екстраполяції, нечіткі методи, методи контент-аналізу.
Графічний інтерфейс об'єднує засоби, що формують наочне представлення результатів обробки і є важливим компонентом системи. Представлена в зручному вигляді інформація дозволяє користувачу побачити додаткові приховані закономірності, які не вдається виявити іншими методами.