

Занятие 7 Конспекты для студентов 1 курса
Т |
 ема:
Дискретное
(цифровое) представление текстовой,
графической, звуковой информации и
видеоинформации.
ема:
Дискретное
(цифровое) представление текстовой,
графической, звуковой информации и
видеоинформации.
М ы
уже говорили, что вся информация, которую
обрабатывает компьютер, должна быть
представлена в виде двоичного кода с
помощью двух цифр 0 и 1. Эти два символа
принято называть двоичными цифрами или
битами. С помощью двух цифр 0 и 1 можно
закодировать
любое сообщение, то есть в компьютере
обязательно должно быть организованно
два важных процесса: кодирование
и декодирование
информации.
ы
уже говорили, что вся информация, которую
обрабатывает компьютер, должна быть
представлена в виде двоичного кода с
помощью двух цифр 0 и 1. Эти два символа
принято называть двоичными цифрами или
битами. С помощью двух цифр 0 и 1 можно
закодировать
любое сообщение, то есть в компьютере
обязательно должно быть организованно
два важных процесса: кодирование
и декодирование
информации.
Кодирование – это процесс представления информации в виде последовательности условных обозначений. Для компьютера кодирование – это преобразование входной информации в двоичный код. Декодирование – обратный процесс, т.е. преобразование данных из двоичного кода в форму, понятную человеку.
Вспомним, что с точки зрения технической реализации использование двоичной системы счисления для кодирования информации оказалось намного более простым, чем применение других способов. Действительно, удобно кодировать информацию в виде последовательности нулей и единиц, если представить эти значения как два возможных устойчивых состояния электронного элемента:
0 – отсутствие электрического сигнала;
1 – наличие электрического сигнала.
Эти
состояния легко различать. Недостаток
двоичного кодирования – длинные коды.
Но в технике легче иметь дело с большим
количеством простых элементов, чем с
небольшим числом сложных. Напомним, как
выглядит главная
формула информатики:
 ,
где
i
–
разрядность ячейки памяти (в битах),
N –
количество различных целых положительных
чисел, которые можно записать в эту
ячейку.
,
где
i
–
разрядность ячейки памяти (в битах),
N –
количество различных целых положительных
чисел, которые можно записать в эту
ячейку.
Р ассмотрим,
как в компьютере представляется
информация различного типа: текстовая
графическая
и звуковая.
С текстовой и графической информацией
конструкторы «научили» работать ЭВМ
(электронно-вычислительные машины),
начиная с третьего поколения (1970 годы).
А работу со звуком «освоили» лишь машины
четвёртого поколения, современные
персональные компьютеры. С этого момента
началось распространение технологии
мультимедиа,
что добавило к компьютеру дополнительные
периферийные устройства для ввода и
вывода текстов, графики, видео и звука.
Процессор и оперативная память по своим
функциям изменились мало, лишь возросло
их быстродействие и объём памяти.
ассмотрим,
как в компьютере представляется
информация различного типа: текстовая
графическая
и звуковая.
С текстовой и графической информацией
конструкторы «научили» работать ЭВМ
(электронно-вычислительные машины),
начиная с третьего поколения (1970 годы).
А работу со звуком «освоили» лишь машины
четвёртого поколения, современные
персональные компьютеры. С этого момента
началось распространение технологии
мультимедиа,
что добавило к компьютеру дополнительные
периферийные устройства для ввода и
вывода текстов, графики, видео и звука.
Процессор и оперативная память по своим
функциям изменились мало, лишь возросло
их быстродействие и объём памяти.
Представление текстовой информации в компьютере.
Принципиально важно, что текстовая информация уже дискретна – состоит из отдельных знаков. Модель представления текста в памяти компьютера весьма проста. За каждой буквой алфавита, цифрой, знаком препинания и иным символом закрепляется определённый двоичный код, который хранится в кодовой таблице в компьютере. Кодовая таблица – это внутреннее представление символов в компьютере. Нажатие любой символьной клавиши приводит к тому, что в компьютер посылается сигнал в виде двоичного числа.
В качестве стандарта долгое время использовалась кодовая таблица ASCII (American Standard Code for International Interchange – Американский стандартный код информационного обмена).
В этой системе кодировки каждый символ заменяется на 7-разрядное целое положительное двоичное число. Для хранения этого числа необходимо выделить ячейку памяти размером 7 бит. Согласно главной формуле информатики, определяем, что размер алфавита, который можно закодировать, равен: 27 = 128 символов. Каждое 7-разрядное число является порядковым номером символа в кодовой таблице. Для сокращения записи и удобства пользования кодами таблицы ASCII используют шестнадцатеричную систему счисления, состоящую из 16 символов – 10 цифр и 6 латинских букв: A, B, C, D, E, F. При кодировании символов сначала записывается цифра строки, а затем столбца, на пересечении которых находится символ.
П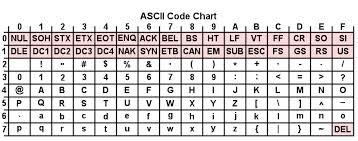 ервые
32 символа (от 0 до 31) стандарта ASCII
являются управляющими и предназначены
для передачи команд управления. Остальные
символы 32-127 – цифры, буквы латинского
алфавита и другие символы.
ервые
32 символа (от 0 до 31) стандарта ASCII
являются управляющими и предназначены
для передачи команд управления. Остальные
символы 32-127 – цифры, буквы латинского
алфавита и другие символы.
И спользуя
8-битную
кодировку можно расширить кодовую
таблицу до 256
символов (28 =
256).
Этого достаточно для кодировки как
английского, так и русского алфавита
(кириллицы). Хронологически одним из
первых стандартов кодирования русских
букв на компьютерах был КОИ8 (Код обмена
информацией, 8-битный). Эта кодировка
применялась ещё в СССР на компьютерах
серии ЕС ЭВМ, и когда в середине 80-х
появились первые русифицированные
версии операционной системы UNIX, они
переняли эту кодировку у своих "старших
братьев". Сеть Релком, с которой
начинался российский Интернет в начале
90-х и которая поначалу состояла в основном
из компьютеров с UNIX, также приняла
кодировку КОИ8 в качестве стандартной.
Сейчас КОИ8-R является единственно
допустимой кодировкой в русскоязычной
электронной почте и телеконференциях.
КОИ8-R
- одна из кодировок, которые обязательно
должна поддерживать любая русская
страница в WWW (см. таблицу справа).
спользуя
8-битную
кодировку можно расширить кодовую
таблицу до 256
символов (28 =
256).
Этого достаточно для кодировки как
английского, так и русского алфавита
(кириллицы). Хронологически одним из
первых стандартов кодирования русских
букв на компьютерах был КОИ8 (Код обмена
информацией, 8-битный). Эта кодировка
применялась ещё в СССР на компьютерах
серии ЕС ЭВМ, и когда в середине 80-х
появились первые русифицированные
версии операционной системы UNIX, они
переняли эту кодировку у своих "старших
братьев". Сеть Релком, с которой
начинался российский Интернет в начале
90-х и которая поначалу состояла в основном
из компьютеров с UNIX, также приняла
кодировку КОИ8 в качестве стандартной.
Сейчас КОИ8-R является единственно
допустимой кодировкой в русскоязычной
электронной почте и телеконференциях.
КОИ8-R
- одна из кодировок, которые обязательно
должна поддерживать любая русская
страница в WWW (см. таблицу справа).
На сегодняшний день существует пять кодировок кириллицы: КОИ8-R (в Unix), CP1251 (в Windows), CP866 (в MS DOS), ISO, Mac. Для преобразования текстовых документов из одной кодировки в другую существуют программы, которые называются Конверторы.
Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную 16-разрядную систему кодировки Unicode, разработанную в 1991 г. В ней код символа занимает 2 байта (16 бит), то есть можно закодировать 216 = 65 536 различных символов. В начале кодовой таблицы Unicode, называемой UTF-16 (от англ. UNICODE Transformation Format – формат преобразования Unicode) содержатся символы ASCII, а дальше есть и символы кириллицы.
В современной версии Unicode можно закодировать
231 =
2 147 483 648
различных знаков, однако реально
используются немногим более 100 000
символов. Unicode включает в себя все
существующие, вымершие и искусственно
созданные алфавиты мира, множество
математических, музыкальных, химических
и прочих символов. Достоинство системы
Unicode в том, что она позволяет использовать
символы разных языков одном документе
и решает проблему правильного отображения
текста, вызванную использованием разных
кодовых таблиц.
современной версии Unicode можно закодировать
231 =
2 147 483 648
различных знаков, однако реально
используются немногим более 100 000
символов. Unicode включает в себя все
существующие, вымершие и искусственно
созданные алфавиты мира, множество
математических, музыкальных, химических
и прочих символов. Достоинство системы
Unicode в том, что она позволяет использовать
символы разных языков одном документе
и решает проблему правильного отображения
текста, вызванную использованием разных
кодовых таблиц.