

Лекция 1
Программы BIOS
В персональном компьютере все основные программы, предназначенные для начальной загрузки, собраны в универсальную программу, которая записана в постоянном запоминающем устройстве, носящем название ROM BIOS или BIOS — Basic Input/Output System (базовая система ввода/вывода). Объем современной BIOS не менее 1—2 Мбайт.
Традиционно все программы, записанные в микросхеме BIOS, можно разделить по выполнению следующих функций:
инициализация и начальное тестирование всех основных (стандартных) узлов компьютера — расположенных на системной плате, подключенных к шине IDE и вставленных в слоты расширения. Для этого используется программа POST (Power On Self Test), также записанная в микросхеме BIOS. Отметим, что "нестандартные" платы расширения, например старые интерфейсы сканеров не тестируются;
загрузка операционной системы с внешнего устройства — гибкого диска, винчестера, компакт-диска или ПЗУ сетевой карты. В самых первых персональных компьютерах был вариант, когда можно было загрузить интерпретатор языка Basic, который находился в дополнительной микросхеме ПЗУ;
обслуживание аппаратных прерываний, например, от клавиатуры и таймера, обработка программных прерываний BIOS, которые предназначены для управления обменом данными между операционной системой компьютера и подключенными к нему периферийными устройствами, выполнение базовых функций, например, вывод на экран монитора символов и работа с дисковыми устройствами;
настройка и конфигурирование узлов системной платы и устройств, подключенных к ней, что выполняется с помощью программы BIOS Setup.
После включения питания или нажатия кнопки Reset у компьютера на адресной шине системной платы аппаратно устанавливается адрес точки входа в программу BIOS, которая в момент старта находится в самых старших ячейках адресуемой памяти. Например, в процессорах 8086/8088 по возникновении сигнала RESET прекращаются все текущие процедуры, а по окончании действия этого сигнала управление передается инструкции по адресу 0FFFF0h, в процессорах 386 — по адресу OFFFFFFOh и т. д.
Следует заметить, что первоначальный адрес загрузки искусственно формируется чипсетом системной платы, который принудительно устанавливает все адресные линии, кроме первых четырех, в единичное состояние. После передачи управления BIOS точка входа становится доступной по стандартному адресу 0FFFF0h, где ею может воспользоваться любая программа.
В персональных компьютерах с процессорами х86 принято, что данные из памяти читаются словами длиною два байта, причем первый байт — это младшая часть 16-разрядного слова, а второй байт — его старшая часть. То есть ячейки чередуются как 2, 1, 4, 3 и т. д. При этом следует помнить, что программисты стараются выравнивать данные и код по четным адресам, по границе 16-байтных параграфов и 64-килобайтных сегментов, что позволяет ускорить работу программ. Конечно, всегда можно прочитать или записать одиночный байт или бит, но этот режим не является оптимальным для процессора, памяти и чипсета. Заметим, что другие процессоры не придерживаются такого способа адресации.
Фиксированные ячейки BIOS |
||
Адрес |
Размер, байт |
Назначение |
Р000:0000 |
11 |
55h, признак ПЗУ |
F000:0001 |
11 |
AAh, признак ПЗУ |
F000:FFF0 |
5 |
команда перехода на POST по сбросу — FAR JMP |
F000:FFF5 |
8 |
Дата выпуска BIOS, например "08/01/95" |
F000:FFFE |
1 |
Тип компьютера (OFFh — для оригинального PC, 0FEh - XT, 0FCh - AT) |
F000:FFFF |
1 |
Дополнение до 0 контрольной суммы BIOS |
Ключевые адреса программ BIOS
Программы, находящиеся в BIOS, используют ряд ресурсов компьютера для хранения данных, полученных в ходе инициализации оборудования, тестирования и для работы служебных подпрограмм. На рис. показано распределение оперативной памяти компьютера PC.
Наиболее важная служебная зона адресов размером в 1 Кбайт начинается с нулевого адреса. В ней находятся векторы аппаратных и программных прерываний, с которыми работают процессор и программное обеспечение. Сами векторы представляют собой инструкцию безусловного перехода на подпрограмму обработки прерывания. Каждый вектор занимает 4 байта, соответственно, всего может быть всего 256 прерываний.

С прерываниями связана одна из проблем персональных компьютеров, которая осложняет жизнь системным программистам. Дело в том, что зону векторов, расположенную с нулевого адреса, используют как сами процессоры семейства х8б, так и различные устройства компьютера, в чем виноваты разработчики IBM PC. Вначале это не особенно осложняло жизнь программистам, поскольку у процессора было не так много аппаратных прерываний, но в дальнейшем, по мере совершенствования процессоров, 256 векторов стало маловато.
Ниже, только для иллюстрации использования таблицы векторов приведено назначение нескольких прерываний компьютера IBM PC AT (для современных процессоров назначение ряда векторов несколько иное):
INT 00h — деление на 0;
INT 01h — пошаговый режим;
INT 02h — немаскируемое прерывание;
ТХТТ ATI INT ОЗh — точка останова;
INT 04h — переполнение;
INT 08h — таймер;
INT 09h — клавиатура;
INT 33h — поддержка мыши;
INT 4Ah — будильник пользователя.
После зоны векторов прерываний идет область, называемая BIOS Data Area, где размещаются данные, полученные в ходе тестирования оборудования, буфера системных устройств, например буфер клавиатуры, и различные служебные регистры. Эта область данных имеет размер не менее 256 байтов и начинается с адреса 0000:0400h или 0040:0000h. Назначение наиболее интересных для пользователя зон в области BIOS Data Area приведено в табл.
Назначение ячеек BIOS Data Area |
||
Адрес |
Размер, байт |
Назначение |
040:000 |
4x2 |
Базовые адреса портов СОМ 1— COM4 |
040:008 |
3x2 |
Базовые адреса портов LPT1— LPT3 |
040:010 040:017 |
2x39 |
Установленное оборудование Область флагов и буфер клавиатуры |
040:049 |
1 |
Текущий видеорежим |
040:04А |
2 |
Ширина экрана (число колонок символов) |
040:050 |
16 |
Позиция курсора (младшая половина — колонка, старшая — ряд) |
040:060 |
2 |
Размер курсора (в младшем байте — последняя строка, в старшем — первая) |
040:067 |
5 |
Область данных POST |
Для работы с видеоадаптером BIOS использует область видеопамяти, расположенную выше 640 Кбайт. Видеопамять занимает 128 Кбайт, начиная с адреса A0000h и до C0000h, но для конкретного режима работы видеоадаптера (монитора) используется строго определенная часть памяти. Например, в текстовом режиме могут использоваться только 4 Кбайт
Системное ПО
Совокупность программ, предназначенная для решения задач на ПК, называется программным обеспечением. Состав программного обеспечения ПК называют программной конфигурацией.
Программное обеспечение, можно условно разделить на три категории:
системное ПО (программы общего пользования), выполняющие различные вспомогательные функции, например создание копий используемой информации, выдачу справочной информации о компьютере, проверку работоспособности устройств компьютера и т.д.
прикладное ПО, обеспечивающее выполнение необходимых работ на ПК: редактирование текстовых документов, создание рисунков или картинок, обработка информационных массивов и т.д.
инструментальное ПО (системы программирования), обеспечивающее разработку новых программ для компьютера на языке программирования.
Системное ПО - Это программы общего пользования не связаны с конкретным применением ПК и выполняют традиционные функции: планирование и управление задачами, управления вводом-выводом и т.д.
Другими словами, системные программы выполняют различные вспомогательные функции, например, создание копий используемой информации, выдачу справочной информации о компьютере, проверку работоспособности устройств компьютера и т.п.
К системному ПО относятся:
операционные системы (эта программа загружается в ОЗУ при включении компьютера)
программы – оболочки (обеспечивают более удобный и наглядный способ общения с компьютером, чем с помощью командной строки DOS, например, Norton Commander)
операционные оболочки – интерфейсные системы, которые используются для создания графических интерфейсов, мультипрограммирования и.т.
Драйверы (программы, предназначенные для управления портами периферийных устройств, обычно загружаются в оперативную память при запуске компьютера)
утилиты (вспомогательные или служебные программы, которые представляют пользователю ряд дополнительных услуг)
К утилитам относятся:
диспетчеры файлов или файловые менеджеры
средства динамического сжатия данных (позволяют увеличить количество информации на диске за счет ее динамического сжатия)
средства просмотра и воспроизведения
средства диагностики; средства контроля позволяют проверить конфигурацию компьютера и проверить работоспособность устройств компьютера, прежде всего жестких дисков
средства коммуникаций (коммуникационные программы) предназначены для организации обмена информацией между компьютерами
средства обеспечения компьютерной безопасности (резервное копирование, антивирусное ПО).
Необходимо отметить, что часть утилит входит в состав операционной системы, а другая часть функционирует автономно. Большая часть общего (системного) ПО входит в состав ОС. Часть общего ПО входит в состав самого компьютера (часть программ ОС и контролирующих тестов записана в ПЗУ или ППЗУ, установленных на системной плате). Часть общего ПО относится к автономными программам и поставляется отдельно.
Периферия ПК
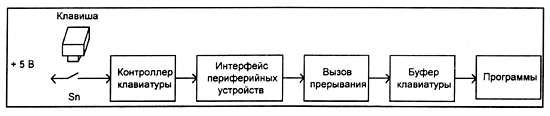
Пример работы с периферией (клавиатурой)
61h –порт работы с клавиатурой. Ин-лайн ассемблер:
//простой пример функции для управления системным динамиком
void PC_dinamik (bool bOn){ switch (bOn){ case true: _asm { in al,61h or al, 00000011b out 61h, al } break; case false: _asm { in al, 61h and al, 11111100b out 61h, al } break; } }
программирование на Си:
//функция для управления клавиатурой
void KeyBoard_OnOff ( bool bOff) { BYTE state; // текущее состояние if (bOff){ // выключить клавиатуру state = _inp ( 0x61); // получаем текущее состояние state |= 0x80; // устанавливаем бит 7 в 1 _outp ( 0x61, state); // записываем обновленное значение в порт } else { // включить клавиатуру state = _inp ( 0x61); // получаем текущее состояние state &= 0x7F; // устанавливаем бит 7 в 0 _outp ( 0x61, state); } // записываем обновленное значение в порт }
лекция 2
Прерывания
Прерывание (англ. interrupt) — сигнал, сообщающий процессору о наступлении какого-либо события. При этом выполнение текущей последовательности команд приостанавливается и управление передаётся обработчику прерывания, который реагирует на событие и обслуживает его, после чего возвращает управление в прерванный код.
В зависимости от источника возникновения сигнала прерывания делятся на:
асинхронные или внешние (аппаратные) — события, которые исходят от внешних источников (например, периферийных устройств) и могут произойти в любой произвольный момент: сигнал от таймера, сетевой карты или дискового накопителя, нажатие клавиш клавиатуры, движение мыши. Факт возникновения в системе такого прерывания трактуется как запрос на прерывание (англ. Interrupt request, IRQ);
синхронные или внутренние — события в самом процессоре как результат нарушения каких-то условий при исполнении машинного кода: деление на ноль или переполнение, обращение к недопустимым адресам или недопустимый код операции;
программные (частный случай внутреннего прерывания) — инициируются исполнением специальной инструкции в коде программы. Программные прерывания как правило используются для обращения к функциям встроенного программного обеспечения (firmware), драйверов и операционной системы.
В зависимости от возможности запрета внешние прерывания делятся на:
маскируемые — прерывания, которые можно запрещать установкой соответствующих битов в регистре маскирования прерываний (в x86-процессорах — сбросом флага IF в регистре флагов);
немаскируемые (англ. Non maskable interrupt, NMI) — обрабатываются всегда, независимо от запретов на другие прерывания. К примеру, такое прерывание может быть вызвано сбоем в микросхеме памяти.
Обработчики прерываний обычно пишутся таким образом, чтобы время их обработки было как можно меньшим, поскольку во время их работы могут не обрабатываться другие прерывания, а если их будет много (особенно от одного источника), то они могут теряться.
До окончания обработки прерывания обычно устанавливается запрет на обработку этого типа прерывания, чтобы процессор не входил в цикл обработки одного прерывания. Приоритезация означает, что все источники прерываний делятся на классы и каждому классу назначается свой уровень приоритета запроса на прерывание. Приоритеты могут обслуживаться как относительные и абсолютные
Относительное обслуживание прерываний означает, что если во время обработки прерывания поступает более приоритетное прерывание, то это прерывание будет обработано только после завершения текущей процедуры обработки прерывания.
Абсолютное обслуживание прерываний означает, что если во время обработки прерывания поступает более приоритетное прерывание, то текущая процедура обработки прерывания вытесняется, и процессор начинает выполнять обработку вновь поступившего более приоритетного прерывания. После завершения этой процедуры процессор возвращается к выполнению вытесненной процедуры обработки прерывания.
Вектор прерывания — закреплённый за устройством номер, который идентифицирует соответствующий обработчик прерываний. Векторы прерываний объединяются в таблицу векторов прерываний, содержащую адреса обработчиков прерываний. Местоположение таблицы зависит от типа и режима работы процессора.
Программное прерывание — синхронное прерывание, которое может осуществить программа с помощью специальной инструкции.
В процессорах архитектуры x86 для явного вызова синхронного прерывания имеется инструкция Int, аргументом которой является номер прерывания (от 0 до 255). В IBM PC-совместимых компьютерах обработку некоторых прерываний осуществляют подпрограммы BIOS, хранящиеся в ПЗУ, и это служит интерфейсом для доступа к сервису, предоставляемому BIOS. Также, обслуживание прерываний могут взять на себя BIOS карт расширений (например, сетевых или видеокарт), операционная система и даже обычные (прикладные) программы, которые постоянно находятся в памяти во время работы других программ (т. н. резидентные программы). В отличие от реального режима, в защищённом режиме x86-процессоров обычные программы не могут обслуживать прерывания, эта функция доступна только системному коду (операционной системе).
MS-DOS использует для взаимодействия со своими модулями и прикладными программами прерывания с номерами от 20h до 3Fh (числа даны в шестнадцатеричной системе счисления, как это принято при программировании на языке ассемблера x86). Например, доступ к основному множеству функций MS-DOS осуществляется исполнением инструкции Int 21h (при этом номер функции и её аргументы передаются в регистрах). Это распределение номеров прерываний не закреплено аппаратно и другие программы могут устанавливать свои обработчики прерываний вместо или поверх уже имеющихся обработчиков, установленных MS-DOS или другими программами, что, как правило, используется для изменения функциональности или расширения списка системных функций. Также, этой возможностью пользуются вирусы.
Клавиатурное прерывание
Клавиатура подключена к линии прерывания IRQ1. Этой линии соответствует прерывание INT 09h.
Клавиатурное прерывание обслуживается модулями BIOS. Драйверы клавиатуры и резидентные программы могут организовывать дополнительную обработку прерывания INT 09h. Для этого может быть использована цепочка обработчиков прерывания. В первой книге первого тома мы приводили примеры расширения обработчика прерывания INT 09h.
Как работает стандартный обработчик клавиатурного прерывания, входящий в состав BIOS?
Этот обработчик выполняет следующие действия:
читает из порта 60h скан-код нажатой клавиши;
записывает вычисленное по скан-коду значение ASCII-кода нажатой клавиши в специальный буфер клавиатуры, расположенный в области данных BIOS;
устанавливает в 1 бит 7 порта 61h, разрешая дальнейшую работу клавиатуры;
возвращает этот бит в исходное состояние;
записывает в порт 20h значение 20h для правильного завершения обработки аппаратного прерывания.
Обработчик прерывания INT 09h не просто записывает значение ASCII-кода в буфер клавиатуры. Дополнительно отслеживаются нажатия таких комбинаций клавиш, как Ctrl-Alt-Del, обрабатываются специальные клавиши PrtSc и SysReq. При вычислении кода ASCII нажатой клавиши учитывается состояние клавиш Shift и CapsLock.
Буфер клавиатуры имеет длину 32 байта и расположен по адресу 0000h:041Eh для машин IBM PC/XT.
В IBM AT и PS/2 расположение клавиатурного буфера задается содержимым двух слов памяти с адресами 0000h:0480h (компонента смещения адреса начала буфера) и 0000h:0482h (смещение конца буфера). Обычно в IBM AT эти ячейки памяти содержат значения, соответственно, 001Eh и 003Eh. Так как смещения заданы относительно сегментного адреса 0040h, то видно, что обычное расположение клавиатурного буфера в IBM AT и PS/2 соответствует его расположению в IBM PC/XT.
Клавиатурный буфер организован циклически. Это означает, что при его переполнении самые старые значения будут потеряны. Две ячейки памяти, находящиеся в области данных BIOS с адресами 0000h:041Ah и 0000h:041Ch содержат, соответственно, указатели на начало и конец буфера. Если значения этих указателей равны друг другу, буфер пуст. (Можно удалить все символы из буфера клавиатуры, установив оба указателя на начало буфера. Однако есть более предпочтительный способ с использованием прерывания BIOS INT 16h).
Указателями на начало и конец клавиатурного буфера обычно управляют обработчики прерываний INT 09h и INT 16h.
Программа извлекает из буфера коды нажатых клавиш, используя различные функции прерывания INT 16h.
Помимо управления содержимым буфера клавиатуры, обработчик прерывания INT 09h отслеживает нажатия на так называемые переключающие клавиши - NumLock, ScrollLock, CapsLock, Ins. Состояние этих клавиш записывается в область данных BIOS в два байта с адресами 0000h:0417h и 0000h:0418h.
Формат байта 0000h:0417h:
Биты |
Значение |
0 |
Нажата правая клавиша Shift. |
1 |
Нажата левая клавиша Shift. |
2 |
Нажата комбинация клавиш Ctrl-Shift с любой стороны. |
3 |
Нажата комбинация клавиш Alt-Shift с любой стороны. |
4 |
Состояние клавиши ScrollLock. |
5 |
Состояние клавиши NumLock. |
6 |
Состояние клавиши CapsLock. |
7 |
Состояние клавиши Insert. |
Формат байта 0000h:0418h:
Биты |
Значение |
0 |
Нажата левая клавиша Shift вместе с клавишей Ctrl. |
1 |
Нажата левая клавиша Shift вместе с клавишей Alt. |
2 |
Нажата клавиша SysReq. |
3 |
Состояние клавиши Pause. |
4 |
Нажата клавиша ScrollLock. |
5 |
Нажата клавиша NumLock. |
6 |
Нажата клавиша CapsLock. |
7 |
Нажата клавиша Insert. |
Если вы изменяете состояние светодиодов на панели клавиатуры, не забывайте устанавливать соответствующие биты в байтах состояния клавиатуры.
Программой обработки прерывания INT 09h отслеживаются некоторые комбинации клавиш. В таблице приведены эти комбинации и действия, выполняемые обработчиком прерывания при их обнаружении:
Комбинация клавиш |
Выполняемые действия |
Ctrl-Alt-Del |
Сброс и перезагрузка системы |
Ctrl-NumLock, Pause |
Перевод машины в состояние ожидания до нажатия любой клавиши |
Shift-PrtSc |
Распечатка на принтере содержимого видеопамяти. |
Ctrl-Break |
Выполнение прерывания INT 1Bh, завершающего работу программы. |
Кольцевой буфер (417h, 418h)
Работой клавиатуры управляет специальный контроллер клавиатуры, обеспечивающий распознавание активной клавиши при нажатии и отпускании и формирование с учетом регистра клавиатуры скан-кода, который передается в порт 60h. Одновременно с передачей скан-кода в порт контроллер генерирует прерывание 09h. Базовый обработчик BIOS-прерывания клавиатуры анализирует значение скан-кода и, если это не код управляющей клавиши, транслирует его а двухбайтный код клавиши и помещает в буфер ввода клавиатуры (41 Eh).
Кольцевой буфер клавиатуры обеспечивает синхронизацию ввода данных с клавиатуры и приема их активной программой и вмещает 15 слов. Для работы с буфером служат два указателя: головной (41Аh) и хвостовой (41Сh). Хвостовой указатель хранит полный адрес первой свободной ячейки буфера, головной - адрес самого старого принятого от клавиатуры, но еще не востребованного программой кода. Если оба указателя имеют один и тот же адрес, то буфер пуст. Если хвостовой указатель на единицу меньше головного, то буфер заполнен полностью. Буфер клавиатуры обслуживается по дисциплине FIFO.
При трансляции скан-кодов базовый обработчик использует информацию о состоянии управляющих клавиш смены регистров и клавиш-переключателей клавиатуры, которая хранится в статусных байтах 417h и 418h. Поступающая с клавиатуры комбинация кодов, не имеющая Специального значения, игнорируется. При длительном нажатии какой-либо клавиши контроллер клавиатуры генерирует последовательность кодов этой клавиши.
Системные средства ввода данных с клавиатуры Коды клавиш из буфера клавиатуры читаются соответствующей программой DOS или пользователя. Для этого используются системные средства BIOS или DOS. Если компьютер не выполняет никаких программ, то за вводом с клавиатуры фактически "следит" командный процессор СОМMAND.COM через DOS-прерывание 21h. Когда выполняется программа, ведущая диалог с пользователем, то ввод из кольцевого буфера производится либо через BIOS-прерывание 16h, либо через DOS-прерывание.
BIOS-прерывание 16h реализует ряд функций), которые обеспечивают работу с буфером на самом низком уровне. Операционная система MS-DOS позволяет пользователю обращаться к клавиатуре, как к файлу, либо реализовывать посимвольный ввод с клавиатуры. Для этого используются соответствующие функции DOS-прерывания 21h
Перепрограммирование прерываний клавиатуры.
В качестве примера построения обработчика пользователя и дополнения базового обработчика клавиатуры рассмотрим задачу создания процедуры пользователя по формированию клавиатурного макроса на заданный расширенный код ASCII (Alt+X, где Х-заданная буква верхнего регистра). В качестве макроса формируется определенный текст до 15 символов. Необходимо разработать алгоритм (процедуру) инициализации обработчика прерываний пользователя, ввода с клавиатуры заданной комбинации клавиш с выводом на экран монитора текста соответствующего клавиатурного макроса с последующим восстановлением состояния начальной загрузки процессора (выполнение основной программы пользователя должно производиться в интерактивном режиме)
Скан-коды
При нажатии любой клавиши контроллер клавиатуры (специализированный микропроцессор) вырабатывает два скан-кода, соответствующих позиции этой клавиши, которые передаются в компьютер. Первый скан-код вырабатывается, когда нажимается клавиша, а второй — при ее отпускании. Чтобы отличить второй скан-код, он предваряется посылкой байта со значением F0h.
При получении байта от клавиатуры чипсет системной платы формирует сигнал аппаратного прерывания IRQ1. Появление такого прерывания однозначно требует от процессора начать выполнение подпрограммы BIOS, отвечающей за обработку сигналов клавиатуры. Если полученный байт является скан-кодом нажатой или отпущенной клавиши, то его значение будет записано в буфер клавиатуры, который занимает 32 байта и имеет начальный адрес 0040:001А. Служебные коды, которые может вырабатывать контроллер клавиатуры, передаются для обработки другим подпрограммам BIOS.
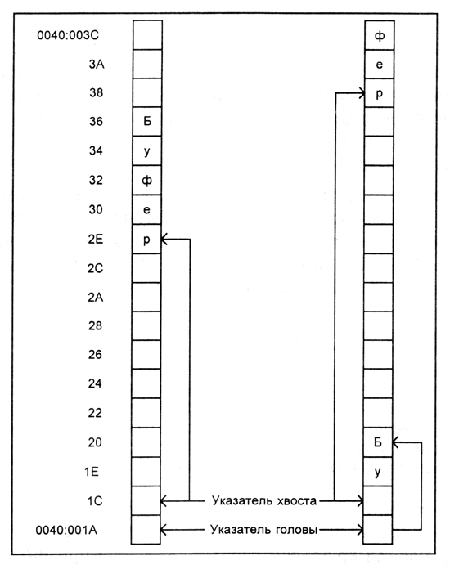
В буфере клавиатуры для кода клавиши отводится по 2 байта, т. е. он рассчитан на 16 символов. Чтобы можно было вводить неограниченное количество символов, буфер клавиатуры работает по принципу FIFO ("первым вошел -- первым ушел").
После того как скан-код клавиши помещен в буфер клавиатуры, его может прочитать любая программа однозадачной операционной системы, например MS-DOS. В многозадачной операционной системе Windows служебные подпрограммы отлеживают, чтобы символы от клавиатуры получала активная в момент ввода символа программа.
ASCII
ASCII (англ. American Standard Code for Information Interchange) — американский стандартный код для обмена информацией.
ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов. Изначально разработанная как 7-битная, с широким распространением 8-битного байта ASCII стала восприниматься как половина 8-битной. В компьютерах обычно используют расширения ASCII с задействованной второй половиной байта
Наложение символов
Благодаря символу BS (возврат на шаг) на принтере можно печатать один символ поверх другого. В ASCII было предусмотрено добавление таким образом диакритики к буквам, например:
a BS '→á
a BS `→à
a BS ^→â
o BS /→ø
c BS ,→ç
n BS ~ → ñ
Национальные варианты ASCII
Стандарт ISO 646 (ECMA-6) предусматривает возможность размещения национальных символов на месте @ [ \ ] ^ ` { | } ~. В дополнение к этому, на месте # может быть размещён £, а на месте $ — ¤. Такая система хорошо подходит для европейских языков, где нужны лишь несколько дополнительных символов. Вариант ASCII без национальных символов называется US-ASCII, или «International Reference Version».
Для некоторых языков с нелатинской письменностью (русского, греческого, арабского, иврита) существовали более радикальные модификации ASCII. Одним из вариантов был отказ от строчных латинских букв — на их месте размещались национальные символы (для русского и греческого — только заглавные буквы). Другой вариант — переключение между US-ASCII и национальным вариантом «на лету» с помощью символов SO (Shift Out) и SI (Shift In) — в этом случае в национальном варианте можно полностью устранить латинские буквы и занять всё пространство под свои символы. См. также КОИ-7.
Впоследствии оказалось удобнее использовать 8-битные кодировки (кодовые страницы), где нижнюю половину кодовой таблицы (0—127) занимают символы US-ASCII, а верхнюю (128—255) — дополнительные символы, включая набор национальных символов. Таким образом, верхняя половина таблицы ASCII до повсеместного внедрения Юникода активно использовалась для представления локализированных символов, букв местного языка. Отсутствие единого стандарта размещения кириллических символов в таблице ASCII доставляло множество проблем с кодировками (КОИ-8, Windows-1251 и другие). Другие языки с нелатинской письменностью тоже страдали из-за наличия нескольких разных кодировок.
В Юникоде первые 128 символов тоже совпадают с соответствующими символами US-ASCII.
Кодировка
|
|
||||||||||||||||
|
.0 |
.1 |
.2 |
.3 |
.4 |
.5 |
.6 |
.7 |
.8 |
.9 |
.A |
.B |
.C |
.D |
.E |
.F |
|
0. |
NUL |
SOH |
STX |
ETX |
EOT |
ENQ |
ACK |
BEL |
BS |
TAB |
LF |
VT |
FF |
CR |
SO |
SI |
|
1. |
DLE |
DC1 |
DC2 |
DC3 |
DC4 |
NAK |
SYN |
ETB |
CAN |
EM |
SUB |
ESC |
FS |
GS |
RS |
US |
|
2. |
|
! |
" |
# |
$ |
% |
& |
' |
( |
) |
* |
+ |
, |
— |
. |
/ |
|
3. |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
0 |
: |
; |
< |
= |
> |
|
4. |
@ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
|
5. |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
[ |
\ |
] |
^ |
_ |
|
6. |
` |
a |
b |
c |
d |
e |
f |
j |
h |
i |
j |
k |
l |
m |
n |
o |
|
7. |
p |
q |
r |
s |
t |
u |
v |
w |
x |
y |
z |
{ |
| |
} |
~ |
DEL |
|
Символ 0x5e в первой версии стандарта ASCII (1963) соответствовал стрелке вверх, а символ 0x5f — стрелке влево. Стандарт ECMA-6 (1965) заменил их на знак вставки (используемый также в роли циркумфлекса) и нижнюю черту (подчёркивание) соответственно.
Структурные свойства таблицы
Цифры 0—9 представляются своими двоичными значениями (например, 5=01012), перед которыми стоит 00112. Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева 00112 к каждому двоично-десятичному полубайту.
Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в 2-ичной системе счисления, перед которыми стоит 1002 (для букв верхнего регистра) или 1102 (для букв нижнего регистра).
Командная строка DOS(ознакомиться)
Команды MS DOS бывают двух типов:
Внутренние команды, их выполняет командый процессор COMMAND.COM (например, dir, copy).
Внешние команды - программы, поставляемые вместе с ОС в виде отдельных файлов. Они размещаются на диске и выполняют действия обслуживающего характера (например, форматирование диска, очистка экрана, проверка диска).
Команды состоят из имени команды и, возможно, параметров, разделенных пробелами. Скобками будут отмечены необязательные элементы команд.
Работа с файлами
Создание текстовых файлов
copy con имя_файла
После ввода этой команды нужно будет поочередно вводить строки файла. В конце каждой строки надо щелкать клавишей Enter. А после ввода последней - одновременно нажать Ctrl и Z, а затем Enter.
Удаление файлов
del (путь)имя_файла
Путь прописывается только тогда, когда удаляемый файл находится в другом каталоге.
Переименование файлов
ren (путь)имя_файла1 имя_файла2
Имя_файла1 - имя файла, который вы хотите переименовать.
Имя_файла2 - новое имя файла, которое будет ему присвоено после выполнения команды.
Путь прописывается только тогда, когда удаляемый файл находится в другом каталоге.
Копирование файлов
copy имя_файла (путь)имя_файла1
Путь прописывается, если файл копируется в другой каталог.
Работа с каталогами
Команда смены текущего диска
A: - переход на диск А
C: - переход на диск С
Просмотр каталога
dir (путь)(имя_файла) (/p) (/w)
Если не введены путь и имя файла, то на экран выведется информация о содержимом каталога (имена файлов, их размер и дата последнего изменения).
Параметр /p задает вывод информации в поэкранном режиме, с задержкой до тех пор, пока пользователь не щелкнет по какой-либо клавише. Это удобно для больших каталогов.
Параметр /w задает вывод информации только об именах файлов в каталоге по пять имен в строке.
Изменение текущего каталога
cd путь
Создание каталога
md путь
Удаление каталога
rd путь
Командная строка
Это строка, которую вы увидите на экране после загрузки MS DOS. Она называется еще пригашением DOS и имеет вид, например, такой
C:\>
здесь C: - имя диска; > - символ приглашения, после которого мерцает курсор, указывая место, куда надо ввести команду.
Лекция 3
Дисковое прерывание 13h
Прерывание INT 13h предназначено для обслуживания жестких и флоппи-дисков. Многочисленные функции прерывания INT 13h выполняют все операции по вводу/выводу на диски.
00h - Сброс дисковой системы.
Эта функция выполняет установку в исходное состояние всей дисковой системы или выбранного дискового устройства. Используется обычно перед началом работы с устройством.
01h - Получить состояние дисковой системы.
Эта функция позволяет проверить результат выполнения предыдущей операции. Если операция завершилась аварийно, при помощи этой функции можно определить код ошибки.
02H/03h - Чтение/запись секторов.
Выполняется чтение секторов в оперативную память компьютера или запись информации из памяти в сектора диска.
Сектор задается для выбранных устройства, дорожки и головки. Программа должна также задать количество читаемых/записываемых секторов.
04h - Проверка секторов.
Функция проверяет сектора на правильность циклической контрольной суммы, CRC (Cyclic Redundancy Check); записи содержимого секторов в память не происходит.
Другие функции прерывания INT 13h.
Среди других функций прерывания INT 13h - форматирование дорожки, позиционирование головки на заданную дорожку диска, тестирование и предварительная установка диска, запуск диагностики контроллера и многое другое.
Структуры дисков
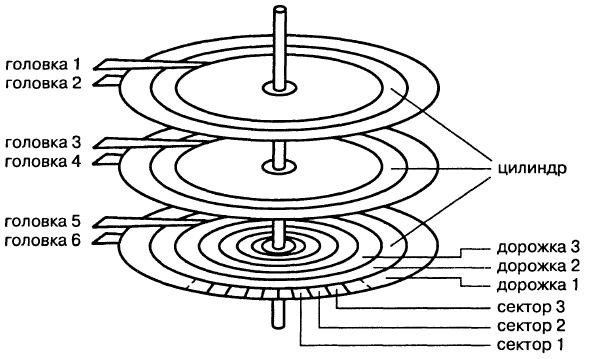
Физическая структура диска
Файловая система обращается к диску непосредственно (напрямую), и поэтому она должна знать его физическую структуру (геометрию). Магнитный диск состоит из нескольких пластин, обслуживаемых читающими/пишущими головками (рис. 8.8). Пластины разделены на дорожки, а дорожки — на сектора. Дорожки, расположенные друг над другом, образуют «цилиндр». Исторически сложилось так, что точное место на диске определяется указанием трех «координат»: цилиндра, головки и сектора.
 Физическая
структура диска
Физическая
структура диска
Дорожки — ЭТО концентрические круги, разделенные на отдельные сектора. Подобно странице памяти, сектор диска — это наименьший блок информации, размер его обычно равен 512 байтам. Головки чтения/записи «плавают» над поверхностью диска. Значения трех вышеупомянутых «координат» позволяют головкам определить нужный сектор диска для чтения или записи данных.
Для цилиндров, головок и секторов были определены диапазоны приемлемых значений. Поскольку объемы дисков росли, увеличивалось и количество цилиндров, головок и секторов. Увеличивалось оно до тех пор, пока не вышло за пределы этого самого диапазона. Вот поэтому некоторые старые компьютеры не могут прочитать диски размером 60 Гб и более (а некоторые и того меньше). Вместо увеличения этих диапазонов были разработаны различные преобразования, которые позволяют вернуть комбинации сектора, головки и цилиндра назад в указанный диапазон.
Было решено заменить адресацию геометрического типа логической (или линейной) адресацией, где отдельные секторы были просто пронумерованы от О до последнего доступного сектора. Теперь для того, чтобы обратиться к сектору, нужно просто указать его номер.
Логические диски
Необязательно, чтобы файловая система занимала весь диск. Обычно диск разбивают на логические диски, или разделы. Так даже безопаснее: например, на одном логическом диске у вас находится операционная система, на другом— прикладные программы, на третьем — ваши данные. Если какая-то программа повредила один раздел, остальные два останутся неповрежденными.
Первый сектор любого диска отведен под таблицу разделов (partition table). Каждая запись этой таблицы содержит адреса начального и конечного секторов одного раздела в геометрической (три «координаты») и логической (последовательный номер) форме. А на каждом разделе хранится таблица файлов, позволяющая определить «координаты» файла на диске.
Мастер-таблица
MFT (Master File Table — Эталонная файловая таблица) — главная файловая таблица (база данных), в которой хранится информация о содержимом тома с файловой системой NTFS, представляющая собой таблицу, строки которой соответствуют файлам тома, а столбцы — атрибутам файлов).
MFT представляет собой файл (разделенный на записи (строки), обычно размером 1 Кб), в котором хранится информация обо всех файлах тома, в том числе и о самом MFT.
Файлами, которым отведено первые 16 записей, являются метафайлы, недоступные операционной системе, но важные для файловой системы NTFS, причем они дублируются ровно посередине тома.
Система не может выполнять перемещение записей MFT-зоны для ликвидации их фрагментации по мере их расширения, поэтому сразу после форматирования NTFS том делится как бы на две части: служебную область, зарезервированную под MFT (12.5 %) и файловое пространство.
Механизм использования MFT-зоны достаточно гибок, и когда файловое пространство заполняется, то MFT-зона просто сокращается, а когда в файловом пространстве появится свободное место, то она может быть вновь расширена. MFT-зона сохраняется целой как можно дольше, так как при её расширении она может фрагментироваться, что нежелательно в связи с возможностью понижения скорости работы с томом.
Модульность структуры MFT обеспечивает устойчивость NTFS к ошибкам по сравнению с FAT, так как MFT может переместить и фрагментировать все свои области обойдя повреждения диска (кроме первых 16 записей).
Метафайлы
Метафайлы NTFS — служебные файлы (области), каждый из которых выполняет ту или иную функцию файловой системы NTFS. Все метафайлы находятся в корневом каталоге NTFS тома, недоступном ОС.
$MFT — основная таблица MFT
$MFTmirr — копия первых 16 записей MFT (размещенная ровно посередине тома)
$Boot — загрузчик (только на первичном томе)
$ — корневой каталог
$LogFile — журнал файловой системы
$Volume — служебная информация (метка тома, версия файловой системы, т.д.)
$Bitmap — карта свободного места тома
$AttrDef — список стандартных атрибутов файлов на томе
$Quota — записи с правами пользователей на использование дискового пространства (квотами)
$Secure — дескрипторы безопасности файловых объектов (права доступа)
Загрузочный сектор
Загрузочный сектор — это особый сектор на жёстком диске, дискете или другом дисковом устройстве хранения информации. (Для дискеты это первый физический сектор, для жесткого диска — первый физический сектор для каждого раздела) В процессе загрузки компьютера с дискеты он загружается в память программой POST (в компьютерах архитектуры IBM PC обычно с адреса 0000:7c00), ему передается управление командой long jump.
Загрузочный сектор, иногда называемый stage1, то есть первым этапом загрузки операционной системы, загружает программу второго этапа загрузки операционной системы stage2 (вторичный загрузчик, иногда в качестве stage2 загружается boot manager или программа авторизации и защиты доступа). (В некоторых ОС роль stage1 выполняет MBR и при загрузке ОС с жесткого диска загрузочный сектор не используется. На незагружаемых разделах жесткого диска загрузочные секторы также могут не содержать программу загрузки)
FAT
FAT (англ. File Allocation Table — «таблица размещения файлов») — классическая архитектура файловой системы, которая из-за своей простоты всё ещё широко используется для флеш-дисков и карт памяти.
В файловой системе FAT смежные секторы диска объединяются в единицы, называемые кластерами. Количество секторов в кластере может быть равно 1 или степени двойки (см. далее). Для хранения данных файла отводится целое число кластеров (минимум один), так что, например, если размер файла составляет 40 байт, а размер кластера 4 кбайт, реально занят информацией файла будет лишь 1% отведенного для него места. Для избежания подобных ситуаций целесообразно уменьшать размер кластеров, а для сокращения объема адресной информации и повышения скорости файловых операций – наоборот. На практике выбирают некоторый компромисс. Так как емкость диска вполне может и не выражаться целым числом кластеров, обычно в конце тома присутствуют т.н. surplus sectors – «остаток» размером менее кластера, который не может отводиться ОС для хранения информации.
Существует три версии FAT — FAT12, FAT16 и FAT32. Они отличаются разрядностью записей в дисковой структуре, т.е. количеством бит, отведённых для хранения номера кластера. FAT12 применяется в основном для дискет, FAT16 — для дисков малого объёма. На основе FAT была разработана новая файловая система exFAT (extended FAT), используемая преимущественно для флеш-накопителей.
Изначально FAT не поддерживала иерархическую систему каталогов. Все файлы располагались в корневом каталоге. Это оказалось неудобно и к тому же малый размер корневого каталога ограничивал количество файлов на диске. Каталоги были введены с выходом MS-DOS 2.0.
В различных операционных системах также были внедрены различные расширения FAT. Например, в DR-DOS имеются дополнительные атрибуты доступа к файлам; в Windows 95, Linux и Proolix — поддержка длинных имён файлов (LFN) в формате Unicode (Virtual FAT — VFAT); в OS/2 — расширенные атрибуты всех файлов. [править] VFAT
VFAT — это расширение FAT, появившееся в Windows 95. В FAT имена файлов имеют формат 8.3 и состоят только из символов кодировки ASCII. В VFAT была добавлена поддержка длинных (до 255 символов) имён файлов (англ. Long File Name, LFN) в кодировке UTF-16LE, при этом LFN хранятся одновременно с именами в формате 8.3, ретроспективно называемыми SFN (англ. Short File Name). LFN нечувствительны к регистру при поиске, однако, в отличие от SFN, которые хранятся в верхнем регистре, LFN сохраняют регистр символов, указанный при создании файла.
Пространство тома FAT32 логически разделено на три смежные области:
Зарезервированная область. Содержит служебные структуры, которые принадлежат загрузочной записи раздела (Partition Boot Record – PBR, для отличия от Master Boot Record – главной загрузочной записи диска; также PBR часто некорректно называется загрузочным сектором) и используются при инициализации тома;
Область таблицы FAT, содержащая массив индексных указателей ("ячеек"), соответствующих кластерам области данных. Обычно на диске представлено две копии таблицы FAT в целях надежности;
Область данных, где записано собственно содержимое файлов – т.е. текст текстовых файлов, кодированное изображение для файлов рисунков, оцифрованный звук для аудиофайлов и т.д. – а также т.н. метаданные – информация относительно имен файлов и папок, их атрибутов, времени создания и изменения, размеров и размещения на диске.
В FAT12 и FAT16 также специально выделяется область корневого каталога. Она имеет фиксированное положение (непосредственно после последнего элемента таблицы FAT) и фиксированный размер в секторах.
Следующая важная структура тома FAT – это сама таблица FAT, занимающая отдельную логическую область. Она определяет список (цепочку) кластеров, в которых размещаются файлы и папки тома. Между кластерами и индексными указателями таблицы имеется взаимно однозначное соответствие – N-й указатель соответствует кластеру с тем же номером. Первому кластеру области данных присваивается номер 2. Значение индексного указателя соответствует состоянию соответствующего кластера. Возможны следующие состояния:
кластер свободен – указатель обнулен;
кластер занят файлом и не является последним кластером файла – значение указателя суть номер следующего кластера файла;
кластер является последним кластером файла – указатель содержит метку EOC (End Of Clusterchain), значение которой зависит от версии FAT: для FAT12 меткой EOC считается любое значение, большее или равное 0x0FF8 (по умолчанию 0x0FFF); для FAT16 – большее или равное 0xFFF8 (по умолчанию 0xFFFF); для FAT32 – любое значение, большее или равное 0x0FFFFFF8 (по умолчанию 0x0FFFFFFF);
кластер поврежден – указатель содержит специальную метку, значение которой для FAT12 0x0FF7, для FAT16 0xFFF7 и для FAT32 0x0FFFFFF7. Поврежденный кластер не может использоваться файловой системой для хранения данных; соответствующие указатели не затрагиваются при форматировании тома, когда все остальные указатели обнуляются;
кластер зарезервирован «для будущей стандартизации» – указатель содержит значение, превышающее CountofClusters, но меньшее метки поврежденного кластера (т.е. до 0xFFF6 включительно для FAT16). В этом случае кластер, не соответствуя никаким реальным данным, считается занятым и пропускается при поиске свободного, но никакой другой информации о нем не предоставляется.
Непосредственно после окончания последней таблицы FAT следует область данных, содержащая файлы и папки. Каталог FAT (папка, директория) является обычным файлом, помеченным специальным атрибутом. Данными (содержимым) такого файла в любой версии FAT является цепочка 32-байтных файловых записей (записей каталога). Директория не может штатно содержать два файла с одинаковым именем. Если программа проверки диска обнаруживает искусственно созданную пару файлов с идентичным именем в одном каталоге, один из них переименовывается.
NTFS
NTFS (от англ. New Technology File System — «файловая система новой технологии») — стандартная файловая система для семейства операционных систем Microsoft Windows NT.
NTFS заменила использовавшуюся в MS-DOS и Microsoft Windows файловую систему FAT. NTFS поддерживает систему метаданных и использует специализированные структуры данных для хранения информации о файлах для улучшения производительности, надёжности и эффективности использования дискового пространства. NTFS хранит информацию о файлах в главной файловой таблице — Master File Table (MFT). NTFS имеет встроенные возможности разграничивать доступ к данным для различных пользователей и групп пользователей (списки контроля доступа — Access Control Lists (ACL)), а также назначать квоты (ограничения на максимальный объём дискового пространства, занимаемый теми или иными пользователями). NTFS использует систему журналирования для повышения надёжности файловой системы.
NTFS разработана на основе файловой системы HPFS (от англ. High Performance File System — высокопроизводительная файловая система), создававшейся Microsoft совместно с IBM для операционной системы OS/2. Но, получив такие несомненно полезные новшества, как квотирование, журналируемость, разграничение доступа и аудит, в значительной степени утратила присущую прародительнице (HPFS) весьма высокую производительность файловых операций.
NTFS |
|
Разработчик |
Microsoft |
Файловая система |
New Technology File System |
Дата представления |
Июль 1993 (Windows NT 3.1) |
Метка тома |
0x07 (MBR) EBD0A0A2-B9E5-4433-87C0-68B6B72699C7 (GPT) |
Структура |
|
Содержимое папок |
B±дерево |
Размещение файлов |
Bitmap |
Сбойные сектора |
$badclus |
Ограничения |
|
Максимальный размер файла |
264 байтов (16 ЭБ) минус 1 КБ |
Максимум файлов |
4 294 967 295 (232−1) |
Максимальная длина имени файла |
255 UTF-16 16-битных слов |
Максимальный размер тома |
264 − 1 кластер |
Допустимые символы в названиях> |
В пространстве имён любое из 16-битных слов в кодировке UTF-16 (чувствительных к регистру) за исключением U+0000 (NUL) и / (косая). В пространстве имена Win32 любое 16-битное слово в кодировке UTF-16 (не чувствительные к регистру) за исключением U+0000 (NUL) / (косая) \ (обратная косая) : (двоеточие) * (звездочка) ? (знак вопроса) " (кавычки) < (знак меньше) > (знак больше) и | (пайп) |
Возможности |
|
Свойства |
Создание, изменение, изменения согласно POSIX, доступ |
Диапазон дат |
1 января 1601 — 28 мая 60056 (на хранение даты и времени отведено 64 бита, шаг — 100-наносекунд (десять миллионов интервалов в секунду), что позволит указать дату и время в промежутке из 58 тысяч лет) |
Точность хранения даты |
100 нанонескунд> |
Потоки метаданных |
Да |
Атрибуты |
Только чтение (Read-only), Скрытый (hidden), Системный (system), Требует архивации (archive), Не проиндексирован (not content indexed), Недоступен (off-line), Временный (temporary), Сжатый (compressed) |
Права доступа |
ACL |
Фоновая компрессия |
По-файлово, LZ77 (Windows NT 3.51 и старше) |
Фоновое шифрование |
По-файлово, DESX (Windows 2000 и старше), Triple DES (Windows XP и старше), AES (Windows XP Service Pack 1, Windows Server 2003 и старше) |
Поддерживается ОС |
Семейство Windows NT: (начиная с Windows NT 3.1 до Windows NT 4.0, Windows 2000, Windows XP, Windows Server 2003, Windows Vista, Windows Server 2008, Windows 7, Windows Server 2008 R2), Mac OS X, Linux |
Редактирование системных ресурсов
Обычно под системными ресурсами подразумевают:
адреса памяти;
каналы запросов прерываний (IRQ);
каналы прямого доступа к памяти (DMA);
адреса портов ввода-вывода.
В приведенном списке порядок размещения системных ресурсов соответствует уменьшению вероятности возникновения из-за них конфликтных ситуаций в компьютере. Наиболее распространенные проблемы связаны с ресурсами памяти, иногда разобраться в них и устранить причины их возникновения довольно сложно. Более подробно эти проблемы рассматриваются в главе 6. В данной главе речь идет о других видах перечисленных выше ресурсов. В частности, возникает значительно больше конфликтов, связанных с ресурсами IRQ, чем с ресурсами DMA, поскольку прерывания запрашиваются чаще. Практически во всех платах используются каналы IRQ. Каналы DMA применяются реже, поэтому обычно их более чем достаточно. Порты ввода-вывода используются во всех подключенных к шине устройствах, но 64 Кбайт памяти, отведенной под порты, обычно хватает, чтобы избежать конфликтных ситуаций. Общим для всех видов ресурсов является то, что любая установленная в компьютере плата (или устройство) должна использовать уникальный системный ресурс, иначе отдельные компоненты компьютера не смогут разделить ресурсы между собой и произойдет конфликт.
Все эти ресурсы необходимы для различных компонентов компьютера. Платы адаптеров используют ресурсы для взаимодействия со всей системой и для выполнения специфических функций. Каждой плате адаптера нужен свой набор ресурсов. Так, последовательным портам для работы необходимы каналы IRQ и уникальные адреса портов ввода-вывода, для аудиоус-тройств требуется еще хотя бы один канал DMA. Большинством сетевых плат используется блок памяти емкостью 16 Кбайт, канал IRQ и адрес порта ввода-вывода.
По мере установки дополнительных плат в компьютере растет вероятность конфликтов, связанных с использованием ресурсов. Конфликт возникает при установке двух или более плат, каждой из которых требуется линия IRQ или адрес порта ввода-вывода. Для предотвращения конфликтов на большинстве плат устанавливаются перемычки или переключатели, с помощью которых можно изменить адрес порта ввода-вывода, номер IRQ и т.д. А в современных операционных системах Windows 9х, удовлетворяющих спецификации Plug and Play, установка правильных параметров осуществляется на этапе инсталляции оборудования. К счастью, найти выход из конфликтных ситуаций можно почти всегда, для этого нужно лишь знать правила игры.
Операционная система имеет объемную информацию, необходимую для загрузки и конфигурирования. Начиная с Windows 95, эта информация хранится в централизованной базе данных, называемой реестром (registry). Для модификации данных реестра имеются штатные утилиты (regedit или редактор реестра).
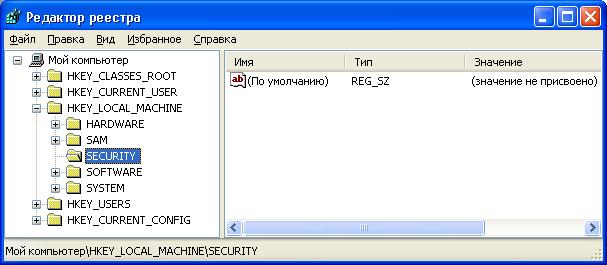
Данные реестра хранятся в виде иерархической древовидной структуры. Каждый узел или каталог называется разделом или ключом (keys), а каталоги верхнего уровня начинаются со строки HKEY. Раздел может содержать подраздел (subkey). Записи нижней части структуры называются параметрами (values), данные типизированы. Реестр содержит шесть корневых разделов:
HKEY_CURRENT_USER,
HKEY__USERS,
HKEY_CLASSES_ROOT,
HKEY_LOCAL_MACHINE,
HKEY_PERFORMANCE_DATA
и HKEY_CURRENT_CONFIG.
Наиболее важным является раздел HKEY_LOCAL_MACHINE. В нем содержится вся информация о локальной системе. Пространство имен реестра интегрировано с общим пространством имен ядра. Оно является третьим пространством имен в системе наряду с пространствами имен объектов и файлов. Для интеграции система поддерживает объект "раздел реестра" (key есть среди типов объектов). Реестр хранится на диске в виде набора файлов, называемых "кустами" или "ульями" (hives). Большинство из них находится в каталоге \Systemroot\System32\Config. Система ведет протоколы модификации кустов (при помощи так называемых регистрационных кустов, log hives), обеспечивая возможность восстановления постоянных кустов реестра. На диске поддерживаются копии критически важных кустов, их описатели можно просмотреть с помощью утилиты Handleex.exe с сайта www.sysinternals.com. Данные реестра доступны через Win32 API. Чтобы получить доступ к данным, открывают соответствующий раздел функцией RegOpenKeyEx. Для записи или удаления используют функции RegSetValue, RegDeleteValue.
http://sistemprog.elitno.net/lec/modul_2/lec_04/lec_21-1.html
Лекция 4
Каталоги, корневой каталог
Каталог (англ. directory — справочник, указатель) — объект в файловой системе, упрощающий организацию файлов. Типичная файловая система содержит большое количество файлов, и каталоги помогают упорядочить её путём их группировки.
Термин папка (англ. folder) был введён для представления объектов файловой системы в графическом пользовательском интерфейсе путём аналогии с офисными папками. Он был впервые использован в Mac OS, а в системах семейства Microsoft Windows он появился с выходом Windows 95. Эта метафора на сегодня используется в большом числе операционных систем: Windows NT, Mac OS, Mac OS X, а также в большом количестве сред рабочего стола для систем семейства UNIX (например, в KDE или GNOME).
В этой терминологии, папка, находящаяся в другой папке, называется подпапка или вложенная папка. Все вместе папки на компьютере представляют иерархическую структуру, представляющую собой дерево каталогов. Подобная древообразная структура возможна в операционных системах, не допускающих существование «физических ссылок» (старые версии Windows допускали только аналог символических ссылок — Shortcut (Ярлык)). В общем случае файловая система представляет собой ориентированный граф.
Дерево каталогов
Формат вывода графически может быть представлен как расположенные ниже и с отступом иконки папок (аналогично ветвям диалоговых систем общения на Интернет-страницах - форумах), открываемые (показывающие своё содержимое) при нажатии на + (для у программы Windows Проводник).
Существуют как встроенные, так и внешние утилиты, предоставляющие информацию о дереве каталогов.
Встроенные
Windows - команда dir
Внешние
Windows
NikFileTree
Каталоги в UNIX
Каталог в UNIX — это файл, содержащий несколько inode и привязанные к ним имена. В современных UNIX-подобных ОС вводится структура каталогов, соответствующая стандарту FHS.
Иерархия каталогов в Microsoft Windows
 Слева
направо: системная папка Корзина, обычная
папка, ярлык к папке.
Слева
направо: системная папка Корзина, обычная
папка, ярлык к папке.
Каталог, который не является подкаталогом ни одного другого каталога, называется корневым. Это значит, что этот каталог находится на самом верхнем уровне иерархии всех каталогов. В системах Linux корневой каталог обозначается как /, в Windows каждый из дисков имеет свою корневой каталог (C:\, D:\ и т. д). На самом деле, в Windows вся информация хранится подобно тому, как это происходит в Linux, доступ к корневому каталогу запрещён.
Каталоги в Windows бывают системные (служебные, созданные ОС) и пользовательские (созданные пользователем). Пример системных каталогов: «Рабочий стол», «Корзина», «Сетевое окружение», «Панель управления», каталоги логических дисков и т. п.
Иерархия файлов ОС Windows состоит из дисков, директорий (папок) и файлов. У каждого диска также есть свой собственный каталог. Обычно каталог основного диска (который и хранит все системные файлы, необходимые для работы операционной системы) называется «C:\», а буквы «A:\» и «B:\» используются для дисководов гибких дисков. А начиная с каталога с буквой «C:\» идут папки жёстких, логических, сетевых и внешних дисков, приводов оптических дисков и т. д.
Загрузчик ОС, этапы загрузки ОС
Процесс загрузки компьютера казалось бы изучен нами до мелочей: кнопка - BIOS - операционная система - логин... А ты задумывался когда-нибудь о том что же на самом деле происходит в это время внутри твоего компьютера? Можешь по шагам рассказать как работает компьютер? Уверен, что нет. Поэтому сегодня проведем короткий ликбез - расскажем о том, как же на самом деле загружается компьютер.
Эта статья рассматривает работу Windows XP, в остальных системах процесс, естественно, несколько отличается.
Включается тумблер питания.
Блок питания проводит самодиагностику. Когда все электрические параметры в норме БП посылает сигнал Power Good процессору. Время между включением питания и уходом сигнала обычно 0.1-0.5 секунд.
Таймер микропроцессора получает сигнал Power Good.
С получением этого сигнала таймер перестает посылать сигнал Reset процессору, позволяя тому включиться.
CPU начинает выполнять код ROM BIOS.
Процессор загружает ROM BIOS начиная с адреса FFFF:0000. По этому адресу прописан только переход на адрес настоящего кода BIOS ROM.
Система выполняет начальный тест железа.
Каждая ошибка, встречающаяся на этом этапе сообщается определенными звуковыми кодами (в прошлом биканьем, сейчас уже вероятно более современно - голосом), так как видео система еще не инициализирована.
BIOS ищет адаптеры, которые могут потребовать загрузки своего BIOS-а.
Самым типичным случаем в этом случае является видео карта. Загрузочная процедура сканирует память с адреса C000:0000 по C780:0000 для поиска видео ROM. Таким образом загружаются системы всех адаптеров.
ROM BIOS проверяет выключение это или перезагрузка.
Процедура два байта по адресу 0000:0472. Любое значение отличное от 1234h является свидетельством "холодного" старта.
Если это включение ROM BIOS запускает полный POST (Power On Self Test). Если это перезагрузка, то из POST процедуры исключается проверка памяти.
Процедуру POST можно разделить на три компоненты:
Видео тест инициализирует видео адаптер, тестирует карту и видео память, показывает конфигурацию или возникшие ошибки.
Идентификация BIOS-а показывает версию прошивки, производителя и дату.
Тест памяти проверяет чипы памяти и подсчитывает размер установленной памяти.
Ошибки, которые могут возникнуть в ходе POST проверки можно разделить на смертельные и не очень :). Во втором случае они показываются на экране, но позволяют продолжить процесс загрузки. Ясно, что в первом случае процесс загрузки останавливается, что обычно сопровождается серией бип-кодов.
BIOS читает конфигурационную информацию из CMOS.
Небольшая область памяти (64 байт) питается от батарейки на материнской платы. Самое главное для загрузки в ней - порядок, в котором должны опрашиваться приводы, какой из них должен быть первым - дисковод, CD-ROM или винчестер.
Если первым является жесткий диск, BIOS проверяет самый первый сектор диска на наличие Master Boot Record (MBR). Для дисковода проверяется Boot Record в первом секторе.
Master Boot Record - первый сектор на цилиндре 0, 0 головке, 512 байт размером. Если она находится, то загружается в память по адресу 0000:7C00, потом проверяется на правильную сигнатуру - два последних байта должны быть 55AAh. Отсутствие MBR или этих проверочных байт останавливает процесс загрузки и выдает предупреждение. Сама MBR состоит из двух частей - системного загрузчика (partition loader или Boot loader), программы, которая получает управление при загрузке с этого жесткого диска; таблицы разделов (партиций), которая содержит информацию о логических дисках, имеющихся на жестком диске.
Правильная MBR запись записывается в память и управление передается ее коду.
Процесс установки нескольких операционных систем на один компьютер обычно заменяет оригинальный лоадер на свою программу, которая позволяет выбрать с какого диска производить остальную загрузку.
Дальше Boot Loader проверяет таблицу партиций в поисках активной. Загрузчик дальше ищет загрузочную запись (Boot Record) на самом первом секторе раздела.
В данном случае Boot Record это еще 512 байт - таблица с описанием раздела (количество байт в секторе, количество секторов в кластере и т.п.) и переход на первый файл операционной системы (IO.SYS в DOS).
Операционная система.
Управление передается операционной системы. Как же она работает, как проходит процесс загрузки?
Boot Record проверяется на правильность и если код признается правильным то код загрузочного сектора исполняется как программа.
Загрузка Windows XP контролируется файлом NTLDR, находящемся в корневой директории системного раздела. NTLDR работает в четыре приема:
Начальная фаза загрузки
Выбор системы
Определение железа
Выбор конфигурации
В начальной фазе NTLDR переключает процессор в защищенный режим. Затем загружает соответствующий драйвер файловой системы для работы с файлами любой файловой системы, поддерживаемой XP.
Если кто забыл, то наша любимая ОСь может работать с FAT-16, FAT-32 и NTFS.
Если в корневой директории есть BOOT.INI, то его содержание загружается в память. Если в нем есть записи более чем об одной операционной системе, NTLDR останавливает работу - показывает меню с выбором и ожидает ввода от пользователя определенный период времени.
Если такого файла нет, то NTLDR продолжает загрузку с первой партиции первого диска, обычно это C:\.
Если в процессе выбора пользователь выбрал Windows NT, 2000 или XP, то проверяется нажатие F8 и показ соответствующего меню с опциями загрузки.
После каждой удачной загрузки XP создает копию текущей комбинации драйверов и системных настроек известную как Last Known Good Configuration. Этот коллекцию можно использовать для загрузки в случае если некое новое устройство внесло разлад в работу операционной системы.
Если выбранная операционная система XP, то NTLDR находит и загружает DOS-овскую программу NTDETECT.COM для определения железа, установленного в компьютере.
NTDETECT.COM строит список компонентов, который потом используется в ключе HARDWARE ветки HKEY_LOCAL_MACHINE реестра.
Если компьютер имеет более одного профиля оборудования программа останавливается с меню выбора конфигурации.
После выбора конфигурации NTLDR начинает загрузку ядра XP (NTOSKRNK.EXE).
В процессе загрузки ядра (но перед инициализацией) NTLDR остается главным в управлении компьютером. Экран очищается и внизу показывается анимация из белых прямоугольников. Кроме ядра загружается и Hardware Abstraction Layer (HAL.DLL), дабы ядро могло абстрагироваться от железа. Оба файла находятся в директории System32.
NTLDR загружает драйвера устройств, помеченные как загрузочные. Загрузив их NTLDR передает управление компьютером дальше.
Каждый драйвер имеет ключ в HKEY_LOCAL_MACHINE\SYSTEM\Services. Если значение Start равно SERVICE_BOOT_START, то устройство считается загрузочным. Для кажого такого устройства на экране печатается точка.
NTOSKRNL в процессе загрузки проходит через две фазы - так называемую фазу 0 и фазу 1. Первая фаза инициализирует лишь ту часть микроядра и исполнительные подсистемы, которая требуется для работы основных служб и продолжения загрузки. На этом этапе на экране показывается графический экран со статус баром.
XP дизейблит прерывания в процессе фазы 0 и включает их только перед фазой 1. Вызывается HAL для подготовки контроллера прерываний. Инициализируются Memory Manager, Object Manager, Security Reference Monitor и Process Manager. Фаза 1 начинается когда HAL подготавливает систему для обработки прерываний устройств. Если на компьютере установлено более одного процессор они инициализируются. Все исполнительные подсистемы реинициализируются в следующем порядке:
Object Manager
Executive
Microkernel
Security Reference Monitor
Memory Manager
Cache Manager
LPCS
I/O Manager
Process Manager
Инициализация Менеджера ввода/Вывода начинает процесс загрузки всех системных драйверов. С того момента где остановился NTLDR загружаются драйвера по приоритету.
Сбой в загрузке драйвера может заставить XP перезагрузиться и попытаться восстановить Last Known Good Configuration.
Последняя задача фазы 1 инициализации ядра - запуск Session Manager Subsystem (SMSS). Подсистема ответственна за создание пользовательского окружения, обеспечивающего интерфейс NT.
SMSS работает в пользовательском режиме, но в отличии от других приложений SMSS считается доверенной частью операционной системы и "родным" приложением (использует только исполнительные функции), что позволяет ей запустить графическую подсистему и login.
SMSS загружает win32k.sys - графическую подсистему.
Драйвер переключает компьютер в графический режим, SMSS стартует все сервисы, которые должны автоматически запускаться при старте. Если все устройства и сервисы стартовали удачно процесс загрузки считается удачным и создается Last Known Good Configuration.
Процесс загрузки не считается завершенным до тех пор, пока пользователь не залогинился в систему. Процесс инициализируется файлом WINLOGON.EXE, запускаемым как сервис и поддерживается Local Security Authority (LSASS.EXE), который и показывает диалог входа в систему.
Это диалоговое окно показывается примерно тогда, когда Services Subsystem стартует сетевую службу.
Системный диск
Загрузочный (системный) диск (дискета) позволит загрузить компьютер в обход установленной на жестком диске операционной системы.
Не зависимо от того где и как был изготовлен загрузочный (системный) диск (дискета) компьютер загрузится именно с него, а не с жесткого диска. Если вы изготовили загрузочный диск в Windows 98, а на жестком диске установлена совершенно друга операционная система, то компьютер все равно загрузится с загрузочной дискеты.
Загрузочный (системный) диск может быть изготовлен на CD (лазерный диск).
Загрузочный (системный) диск это лишь первый шаг. В зависимости от метода изготовления загрузочного (системного) диска, будут зависеть результаты вашей работы.
Загрузочный (системный) диск, который вы получите, используя перечисленные ниже способы, будет иметь различную функциональность.
Я рекомендую пользоваться загрузочным диском, изготовленным в операционной системе Windows 98, именно этот диск будет обладать максимальной функциональностью. Если же на основе этого диска вы изготовите лазерный загрузочный диск, то в этом случае ваши возможности будут практически не ограничены ничем, кроме вашего мастерства.
Диск содержащий рабочую версию ОС Windows XP содержит правильную главную загрузочную запись (сектор) и блок начальной загрузки в начале раздела диска (тома), кроме этого в корне дискового тома файлы ntldr, ntdetect.com, boot.ini, bootfont.bin и каталог с системными файлами ОС, обычно указанный в boot.ini (ниже типичное содержание такого файла)
[boot loader] timeout=3 default=multi(0)disk(0)rdisk(0)partition(1)\WINDOWS [operating systems] multi(0)disk(0)rdisk(0)partition(1)\XPWINSP2="Microsoft Windows XP Professional RU SP2" /fastdetect multi(0)disk(0)rdisk(0)partition(1)\WINDOWS="Microsoft Windows XP Professional RU" /fastdetect
в отсутствие файла boot.ini загрузка будет идти в предположении о наличии каталога \WINDOWS. В самом конце загрузки Windows XP на экране монитора отображается страница приветствия. На этой странице перечислены все имена зарегистрированных пользователей. Если вы единоличный пользователь компьютера, страница приветствия может быть не нужна, а требуется, чтобы система автоматически загружалась под каким-либо пользователем, без появления окна приветствия.
Чтобы настроить это, нужно в разделе реестра HKEY_LOCAL_MACHINE\Software\Microsoft\WindowsNT\ CurrentVersion\Winlogon установить для параметра AutoAdminLogon (типа DWORD) значение 1. В том же разделе в значениях параметров DefaultUserName и BefaultPassword указать имя пользователя и пароль, под которыми должен осуществляться запуск системы, также указать имя домена в параметре DefaultDomainName, если ваш компьютер использует домен. Задать число автоматических входов можно, перейдя в раздел HKEY_LOCAL_MACHINE\Software\Microsoft\WindowsNT\CurrentVersion\Winlogon и создав параметр AutoLogonCount типа DWORD, в качестве значения задав нужное число. Когда установленное число автоматических загрузок будет исчерпано, ключи AutoLogonCount и DefaultPassword будут удалены, параметру AutoAdininLogon будет присвоено нулевое значение.
Настройка системы
Какой бы совершенной не была ОС, она нуждается в настройке под личные вкусы пользователей и определенной оптимизации. Большинство настроек спрятяно в реестре, но далеко не каждый может провести этот процесс. Это знают некоторые программисты, поэтому и были созданы многие программы-настройщики. Ниже рассматриваются, основные программы-твикеры, которые могут почти всё.
Tweak-XP
Считается
одной из лучших утилит для тонкой
настройки Windows XP. Удобный интерфейс,
быстрая работа и широкий охват настроек,
- все это характерно для нее. Программа
имеет четыре раздела: улучшение общей
производительности системы в целом,
ускорение 
файловой системы, повышение скорости работы с Интернетом и настройка файлов помощи, а также настройка других программ.
Tweak-XP объединяет в себе 22 важные утилиты, которые должны существенно облегчить жизнь пользователю. Это и блокирование открывающихся окон в IE, и блокирование рекламных баннеров, и Minimizer-XP, позволяющий нанести порядок в системном трее, и Trans-XP, утилита, позволяющая сделать любое окно полупрозрачным, и оптимизатор RAM, а также Atomic Clock 2001, который позволит вам видеть всегда точнейшее время. Tweak-XP позволяет оптимизировать память, кэш, работу жесткого диска. Присутствуют настройки для наиболее популярных процессоров от AMD и Intel(Pentium). Присутсвует удобная возможность запускать системные утилиты прямо из программы. Также можно отслеживать все запускаемые системой при стaрте файлы, изменять пути к стандартным папкам. А также многочисленные настройки Explorer(a) и меню "Пуск". Существует очень полезная функция - защита паролем определенных программ от запуска. Пользователь не сможет запустить программу,без введения правильного пароля (Вкладка System+File Tweaks ->Program Sensorship). Итак, чтобы провести минимальную оптимизацию необходимо сделать следующее:
Force Windows to unload DLL's from memory. Данная команда находится во вкладке оптимизации памяти и позволяет выгружать из памяти динамические библиотеки неиспользуемых программ. Очень важно, когда памяти меньше 128 МБ.
Increase NTFS Performance by Disabling the Last Access Time Stamp. Команда находится на вкладке cache optimization. Позволяет запретить файловой системе NTFS вести протокол времени обращения к файлам. В таком случае, папка, содержащая большое количество файлов будет открываться быстрее.
Enable boot defrag for faster booting. Команда находится на той же вкладке. Позволяет ускорить процесс загрузки, располагая загрузочные файлы рядом друг с другом.
Clear pagefile (swapfile) on shutdown. Безопасность. Позволяет обнулять (уничтожать) файл подкачки. При включенной опции выключение системы может продолжаться чуть дольше обычного.
C ustomizer
XP
ustomizer
XP
Следующая программа-твикер Windows XP - это Customizer XP. Это бесплатная программа, которая в отличие от Tweak-XP сосредоточена только на работе с реестром. То есть изменение внешнего вида ОС, и, конечно же, функций. Вообще взаимное использование этих программ может принести очень хороший результат. Эта программа включает в себя следующие опции:
Registry Tweak
RAM Optimizer
Disk Cleaner
OEM Info
Create Shortcut
Process Info
Startup Manager
Add/Remove
Всё это вместе позволит настроить Windows по своему вкусу. На вкладке Explorer можно: убрать стрелочки с ярлыков (Remove arrow symbol on shortcut), убрать надпись о версии системы (Show Windows version number), заставить использовать Блокнот для открытия незнакомых файлов (Use Notepad to open unknown files), отменить функцию Active Desktop (Disable Active Desktop feature), предотвратить сворачивание неиспользуемых иконок в трее (Disable grouping similar taskbar buttons), предотвратить группирование сходных кнопок на панели задач и кое-что ещё. Программа позволяет убрать многочисленные вкладки из диалоговых окон ОС. Таких как экран, Панель Управления, Свойства Системы и многое другое. Этим можно ограничить пользователей менять установки системы. А чтобы они не смогли вернуть все назад можно поставить пароль на запуск Customizer XP в программе Tweak-XP :-).
Tweak UI
Родная
программа-твикер от Microsoft. Входит в
состав PowerToys for Windows XP и продолжает
известную линейку Tweak UI. Программа
абсолютно бесплатна и позволяет совершить
ряд простых настроек. На вкладке General
можно настроить пункт Focus - указать,
каким образом приложение, нуждающееся
в действии пользователя, давало бы о
себе знать. 
А также провести некоторые настройки с быстродействием системы (анимированные выпадающие меню и т. д.). Вкладка Mouse позволит совершить ряд манипуляций с мышью, в том числе указать количество строк прокручивающихся при каждом движении колесика или, используя вкладку x-mouse настроить систему так, чтобы окна становились активными при подводе к ним указателя мыши. На вкладке Explorer можно настроить внешний вид ярлыков и установить командные клавиши для клавиатуы с навигационными клавишами. Вкладка My Computer позволит настроить местонахождение системных папок типа CD-Burning, а также включить или выключить автовоспроизведение компакт-дисков. Control Panel предлагает довольно редкую функцию добавления или удаления апплетов из меню Панели Управления. Довольно интересная функция. Вкладка Internet Explorer позволит определить программу, которая служила бы для просмотра исходного кода Web-страниц, а также присвоить собственный рисунок для панели инструментов IE. На вкладке Logon можно заставить систему подключать файл autoexec.bat при загрузке, а также определить пользователя, который бы загружался автоматически. И последняя вкладка Repair позволит восстановить некоторые системные папки, которые должны выглядеть специальным образом, например, папка Fonts. В заключение можно утверждать, что эта программа должна быть обязательно на компьютере с установленной ХР и дополнять монстры, описанные выше.
Операционные системы
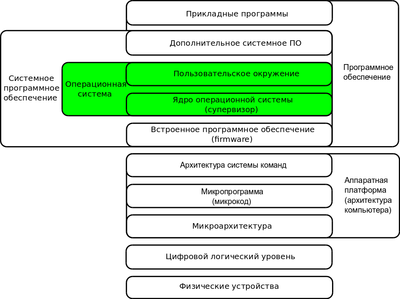 Схема,
иллюстрирующая место операционной
системы в многоуровневой структуре
компьютера
Схема,
иллюстрирующая место операционной
системы в многоуровневой структуре
компьютера
Операционная система, сокр. ОС (англ. operating system, OS) — комплекс управляющих и обрабатывающих программ, которые, с одной стороны, выступают как интерфейс между устройствами вычислительной системы и прикладными программами, а с другой стороны — предназначены для управления устройствами, управления вычислительными процессами, эффективного распределения вычислительных ресурсов между вычислительными процессами и организации надёжных вычислений. Это определение применимо к большинству современных ОС общего назначения.
Функции операционных систем
Основные функции:
Выполнение по запросу программ тех достаточно элементарных (низкоуровневых) действий, которые являются общими для большинства программ и часто встречаются почти во всех программах (ввод и вывод данных, запуск и остановка других программ, выделение и освобождение дополнительной памяти и др.).
Загрузка программ в оперативную память и их выполнение.
Стандартизованный доступ к периферийным устройствам (устройства ввода-вывода).
Управление оперативной памятью (распределение между процессами, организация виртуальной памяти).
Управление доступом к данным на энергонезависимых носителях (таких как жёсткий диск, оптические диски и др.), организованным в той или иной файловой системе.
Обеспечение пользовательского интерфейса.
Сетевые операции, поддержка стека сетевых протоколов.
Дополнительные функции:
Параллельное или псевдопараллельное выполнение задач (многозадачность).
Эффективное распределение ресурсов вычислительной системы между процессами.
Разграничение доступа различных процессов к ресурсам.
Организация надёжных вычислений (невозможности одного вычислительного процесса намеренно или по ошибке повлиять на вычисления в другом процессе), основана на разграничении доступа к ресурсам.
Взаимодействие между процессами: обмен данными, взаимная синхронизация.
Защита самой системы, а также пользовательских данных и программ от действий пользователей (злонамеренных или по незнанию) или приложений.
Многопользовательский режим работы и разграничение прав доступа.
Современные универсальные ОС можно охарактеризовать, прежде всего, как
использующие файловые системы (с универсальным механизмом доступа к данным),
многопользовательские (с разделением полномочий),
многозадачные (с разделением времени).
Многозадачность и распределение полномочий требуют определённой иерархии привилегий компонентов самой ОС. В составе ОС различают три группы компонентов:
ядро, содержащее планировщик; драйверы устройств, непосредственно управляющие оборудованием; сетевая подсистема, файловая система;
системные библиотеки;
оболочка с утилитами.
Большинство программ, как системных (входящих в ОС), так и прикладных, исполняются в непривилегированном («пользовательском») режиме работы процессора и получают доступ к оборудованию (и, при необходимости, к другим ресурсам ядра, а также ресурсам иных программ) только посредством системных вызовов. Ядро исполняется в привилегированном режиме: именно в этом смысле говорят, что ОС (точнее, её ядро) управляет оборудованием.
В определении состава ОС значение имеет критерий операциональной целостности (замкнутости): система должна позволять полноценно использовать (включая модификацию) свои компоненты. Поэтому в полный состав ОС включают и набор инструментальных средств (от текстовых редакторов до компиляторов, отладчиков и компоновщиков).
Ядро операционной системы
Ядро — центральная часть операционной системы, управляющая выполнением процессов, ресурсами вычислительной системы и предоставляющая процессам координированный доступ к этим ресурсам. Основными ресурсами являются процессорное время, память и устройства ввода-вывода. Доступ к файловой системе и сетевое взаимодействие также могут быть реализованы на уровне ядра.
Как основополагающий элемент ОС, ядро представляет собой наиболее низкий уровень абстракции для доступа приложений к ресурсам вычислительной системы, необходимым для их работы. Как правило, ядро предоставляет такой доступ исполняемым процессам соответствующих приложений за счёт использования механизмов межпроцессного взаимодействия и обращения приложений к системным вызовам ОС.
Описанная задача может различаться в зависимости от типа архитектуры ядра и способа её реализации.
Объекты ядра ОС:
Процессы
Файлы
События
Потоки
Семафоры
Мьютексы
Каналы
Файлы, проецируемые в память
Предшественником ОС следует считать служебные программы (загрузчики и мониторы), а также библиотеки часто используемых подпрограмм, начавшие разрабатываться с появлением универсальных компьютеров 1-го поколения (конец 1940-х годов). Служебные программы минимизировали физические манипуляции оператора с оборудованием, а библиотеки позволяли избежать многократного программирования одних и тех же действий (осуществления операций ввода-вывода, вычисления математических функций и т. п.).
В 1950—1960-х годах сформировались и были реализованы основные идеи, определяющие функциональность ОС: пакетный режим, разделение времени и многозадачность, разделение полномочий, реальный масштаб времени, файловые структуры и файловые системы.
Необходимость оптимального использования дорогостоящих вычислительных ресурсов привела к появлению концепции «пакетного режима» исполнения программ. Пакетный режим предполагает наличие очереди программ на исполнение, причём ОС может обеспечивать загрузку программы с внешних носителей данных в оперативную память, не дожидаясь завершения исполнения предыдущей программы, что позволяет избежать простоя процессора.
Уже пакетный режим в своём развитом варианте требует разделения процессорного времени между выполнением нескольких программ.
Необходимость в разделении времени (многозадачности, мультипрограммировании) проявилась ещё сильнее при распространении в качестве устройств ввода-вывода телетайпов (а позднее, терминалов с электронно-лучевыми дисплеями) (1960-е годы). Поскольку скорость клавиатурного ввода (и даже чтения с экрана) данных оператором много ниже, чем скорость обработки этих данных компьютером, использование компьютера в «монопольном» режиме (с одним оператором) могло привести к простою дорогостоящих вычислительных ресурсов.
Разделение времени позволило создать «многопользовательские» системы, в которых один (как правило) центральный процессор и блок оперативной памяти соединялся с многочисленными терминалами. При этом часть задач (таких как ввод или редактирование данных оператором) могла исполняться в режиме диалога, а другие задачи (такие как массивные вычисления) — в пакетном режиме.
Распространение многопользовательских систем потребовало решения задачи разделения полномочий, позволяющей избежать возможности изменения исполняемой программы или данных одной программы в памяти компьютера другой программой (намеренно или по ошибке), а также изменения самой ОС прикладной программой.
Реализация разделения полномочий в ОС была поддержана разработчиками процессоров, предложивших архитектуры с двумя режимами работы процессора — «реальным» (в котором исполняемой программе доступно всё адресное пространство компьютера) и «защищённым» (в котором доступность адресного пространства ограничена диапазоном, выделенном при запуске программы на исполнение).
Применение универсальных компьютеров для управления производственными процессами потребовало реализации «реального масштаба времени» («реального времени») — синхронизации исполнения программ с внешними физическими процессами.
Включение функции реального масштаба времени в ОС позволило создавать системы, одновременно обслуживающие производственные процессы и решающие другие задачи (в пакетном режиме и/или в режиме разделения времени).
Постепенная замена носителей с последовательным доступом (перфолент, перфокарт и магнитных лент) накопителями произвольного доступа (на магнитных дисках).
Файловая система — способ хранения данных на внешних запоминающих устройствах.
Управление задачами и памятью в операционных системах
Способы распределения времени центрального процессора сильно влияют и на скорость выполнения отдельных вычислений, и на общую эффективность вычислительной системы.
От выбранных механизмов распределения памяти между выполняющимися процессорами очень сильно зависит и эффективность использования ресурсов системы, и ее производительность.
Здесь не будем стараться разделять понятия процесс (process) и поток (thread), вместо этого используя обобщающий термин task (задача).
Операционная система выполняет следующие основные функции, связананнные с управлением задачами:
создание и удаление задач;
планирование процессов и диспетчеризация задач;
синхронизация задач, обеспечение их средствами коммуникации.
Создание и удаление задач осуществляется по соответствующим запросам от пользователей или от самих задач.
Созданный новый процесс необходимо разместить в основной памяти — следовательно, ему необходимо выделить часть адресного пространства. Новый порожденный поток текущего процесса необходимо включить в общий список задач, конкурирующих между собой за ресурсы центрального процессора.
Задача может породить новую задачу. При этом между процессами появляются «родственные» отношения. Порождающая задача называется «предком», «родителем», а порожденная — «потомком», «сыном» или «дочерней задачей». «Предок» может приостановить или удалить свою дочернюю задачу, тогда как «потомок» не может управлять «предком».
Если подобрать набор таких процессов, которые не будут конкурировать между собой за неразделяемые ресурсы при параллельном выполнении, то, скорее всего, процессы смогут выполниться быстрее (из-за отсутствия дополнительных ожиданий), да и имеющиеся в системе ресурсы будут использоваться более эффективно. Задача подбора такого множества процессов, что при выполнении они будут как можно реже конфликтовать из-за имеющихся в системе ресурсов, называется планированием вычислительных процессов.
Задача планирования процессов возникла очень давно — в первых пакетных ОС. В настоящее время актуальность этой задачи не так велика.
На первый план вышли задачи динамического (или краткосрочного) планирования, то есть текущего наиболее эффективного распределения ресурсов, возникающего практически при каждом событии. Задачи динамического планирования стали называть диспетчеризацией.
Иногда диспетчеризацию называют краткосрочным планированием.
Долгосрочный планировщик решает, какой из процессов, находящихся во входной очереди, должен быть переведен в очередь готовых процессов в случае освобождения ресурсов.
Краткосрочный планировщик решает, какая из задач, находящихся в очереди готовых к выполнению, должна быть передана на исполнение.
При рассмотрении стратегий планирования, как правило, идет речь о краткосрочном планировании, то есть о диспетчеризации.
Стратегия планирования определяет, какие процессы мы планируем на выполнение для того, чтобы достичь поставленной цели. Известно большое количество различных стратегий выбора процесса, которому необходимо предоставить процессор. Среди них, прежде всего, можно назвать следующие стратегии:
по возможности заканчивать вычисления (вычислительные процессы) в том же самом порядке, в котором они были начаты;
отдавать предпочтение более коротким процессам;
предоставлять всем пользователям (процессам пользователей) одинаковые услуги, в том числе и одинаковое время ожидания
Известно большое количество правил (дисциплин диспетчеризации), в соответствии с которыми формируется список (очередь) готовых к выполнению задач, различают два больших класса дисциплин обслуживания — бесприоритетные и приоритетные.
При бесприоритетном обслуживании выбор задачи производятся в некотором заранее установленном порядке без учета их относительной важности и времени обслуживания.
При реализации приоритетных дисциплин обслуживания отдельным задачам предоставляется преимущественное право попасть в состояние исполнения.
Самой простой в реализации является дисциплина FCFS (first come — first served), согласно которой задачи обслуживаются «в порядке очереди», то есть в порядке их появления. Те задачи, которые были заблокированы в процессе работы (попали в какое-либо из состояний ожидания, например, из-за операций ввода/вывода), после перехода в состояние готовности ставятся в эту очередь готовности перед теми задачами, которые еще не выполнялись.
Другими словами, образуются две очереди (см. рис.): одна очередь образуется из новых задач, а вторая очередь - из ранее выполнявшихся, но попавших в состояние ожидание.

К достоинствам этой дисциплины, прежде всего, можно отнести простоту реализации и малые расходы системных ресурсов на формирование очереди задач.
Однако эта дисциплина приводит к тому, что при увеличении загрузки вычислительной системы растет и среднее время ожидания обслуживания, причем короткие задания (требующие небольших затрат машинного времени) вынуждены ожидать столько же, сколько и трудоемкие задания. Избежать этого недостатка позволяют дисциплины SJN и SRT.
Дисциплина обслуживания SJN (shortest job next: следующим будет выполняться кратчайшее задание) требует, чтобы для каждого задания была известна оценка в потребностях машинного времени. Необходимость сообщать ОС характеристики задач, в которых описывались бы потребности в ресурсах вычислительной системы, привела к тому, что были разработаны соответствующие языковые средства.
Пользователи должны были указывать предполагаемое время выполнения, и чтобы они не пытались указать заведомо меньшее время выполнения, ввели подсчет реальных потребностей. Диспетчер задач сравнивал заказанное время и время выполнения, и в случае превышения указанной оценки в данном ресурсе ставил данное задание не в начало, а в конец очереди.
Дисциплина обслуживания SJN предполагает, что имеется только одна очередь заданий, готовых к выполнению. И задания, которые в процессе своего исполнения были временно заблокированы (например, ожидали завершения операций ввода/вывода), вновь попадают в конец очереди готовых к выполнению наравне с вновь поступающими.
Это приводит к тому, что задания, которым требуется очень немного времени для своего завершения, вынуждены ожидать процессор наравне с длительными работами, что не всегда хорошо.
Для устранения этого недостатка и была предложена дисциплина SRT (shortest remaining time, следующее задание требует меньше всего времени для своего завершения).
Все эти три дисциплины обслуживания могут использоваться для пакетных режимов обработки.
Для интерактивных же вычислений желательно прежде всего обеспечить приемлемое время реакции системы и равенство в обслуживании, если система является мультитерминальной.
Если же это однопользовательская система, но с возможностью мультипрограммной обработки, то желательно, чтобы те программы, с которыми мы сейчас непосредственно работаем, имели лучшее время реакции, нежели наши фоновые задания.
Для решения подобных проблем используется дисциплина обслуживания, называемая RR (round robin, круговая, карусельная), и приоритетные методы обслуживания.
Дисциплина обслуживания RR предполагает, что каждая задача получает процессорное время порциями (говорят: квантами времени, Time slice, q). После окончания кванта времени q задача снимается с процессора и он передается следующей задаче. Снятая задача ставится в конец очереди задач, готовых к выполнению.
Для оптимальной работы системы необходимо правильно выбрать закон, по которому кванты времени выделяются задачам.
Диспетчеризация без перераспределения процессорного времени, то есть не вытесняющая многозадачность (non-preemptive multitasking) — это такой способ диспетчеризации процессов, при котором активный процесс выполняется до тех пор, пока он сам, «по собственной инициативе», не отдаст управление диспетчеру задач для выбора из очереди другого, готового к выполнению процесса или треда.
Дисциплины обслуживания FCFS, SJN, SRT относятся к не вытесняющим.
Диспетчеризация с перераспределением процессорного времени между задачами, то есть вытесняющая многозадачность (preemptive multitasking) — это такой способ, при котором решение о переключении процессора с выполнения одного процесса на выполнение другого процесса принимается диспетчером задач, а не самой активной задачей.
При вытесняющей многозадачности механизм диспетчеризации задач целиком сосредоточен в операционной системе. При этом операционная система выполняет следующие функции:
определяет момент снятия с выполнения текущей задачи,
сохраняет ее контекст в дескрипторе задачи,
выбирает из очереди готовых задач следующую и запускает ее на выполнение, предварительно загрузив ее контекст.
Дисциплина RR и многие другие, построенные на ее основе, относятся к вытесняющим.
Качество диспетчеризации и гарантии обслуживания
Одна из проблем, которая возникает при выборе подходящей дисциплины обслуживания, — это гарантия обслуживания. Дело в том, что при некоторых дисциплинах, например при использовании дисциплины абсолютных приоритетов, низкоприоритетные процессы оказываются обделенными многими ресурсами и, прежде всего, процессорным временем.
Возникает реальная дискриминация низкоприоритетных задач, и ряд таких процессов, имеющих к тому же большие потребности в ресурсах, могут очень длительное время откладываться или, в конце концов, вообще могут быть не выполнены.
Более жестким требованием к системе, чем просто гарантированное завершение процесса, является его гарантированное завершение к указанному моменту времени или за указанный интервал времени.
Существуют различные дисциплины диспетчеризации, учитывающие жесткие временные ограничения.
Гарантировать обслуживание можно следующими тремя способами:
выделять минимальную долю процессорного времени некоторому классу процессов, если по крайней мере один из них готов к исполнению. Например, можно отводить 20 % от каждых 10 мс процессам реального времени, 40 % От каждых 2с — интерактивным процессам и 10 % от каждых 5 мин — пакетным (фоновым) процессам;
выделять минимальную долю процессорного времени некоторому конкретному процессу, если он готов к выполнению;
выделять столько процессорного времени некоторому процессу, чтобы он мог выполнить свои вычисления к сроку.
Для сравнения алгоритмов диспетчеризации обычно используются следующие критерии:
Использование (загрузка) центрального процессора (CPU utilization). В большинстве персональных систем средняя загрузка процессора не превышает 2-3 %, доходя в моменты выполнения сложных вычислений и до 100 %. В серверах, загрузка процессора колеблется в пределах 15-40 % для легко загруженного процессора и до 90-100 % — для сильно загруженного процессора.
Пропускная способность (CPU throughput). Может измеряться количеством процессов, которые выполняются в единицу времени.
Время оборота (turnaround time). Интервал от момента появления процесса во входной очереди до момента его завершения. Включает время ожидания во входной очереди, время ожидания в очереди готовых процессов, время ожидания в очередях к оборудованию, время выполнения в процессоре и время ввода/вывода.
Время ожидания (waiting time). Под временем ожидания понимается суммарное время нахождения процесса в очереди готовых процессов.
Время отклика (response time). Для интерактивных программ важным показателем является время отклика или время, прошедшее от момента попадания процесса во входную очередь до момента первого обращения к терминалу.
Очевидно, что простейшая стратегия краткосрочного планировщика должна быть направлена на максимизацию средних значений загруженности и пропускной способности, минимизацию времени ожидания и времени отклика.
Правильное планирование процессов сильно влияет на производительность всей системы. Можно выделить следующие главные причины, приводящие к уменьшению производительности системы:
Накладные расходы на переключение процессора. Они определяются не только переключениями контекстов задач, но и (при переключении на процессы другого приложения) перемещениями страниц виртуальной памяти, а также необходимостью обновления данных в кэше.
Переключение на другой процесс в тот момент, когда текущий. процесс выполняет критическую секцию, а другие процессы активно ожидают входа в свою критическую секцию.
В случае использования мультипроцессорных систем применяются следующие методы повышения производительности системы:
совместное планирование, при котором все потоки одного приложения (неблокированные) одновременно выбираются для выполнения процессорами и одновременно снимаются с них (для сокращения переключений контекста);
планирование, при котором находящиеся в критической секции задачи не прерываются, а активно ожидающие входа в критическую секцию задачи не выбираются до тех пор, пока вход в секцию не освободится;
планирование с учетом так называемых «советов» программы (во время ее выполнения).
Диспетчеризация задач с использованием динамических приоритетов
При выполнении программ, реализующих какие-либо задачи контроля и управления, может случиться такая ситуация, когда одна или несколько задач не могут быть реализованы (решены) в течение длительного промежутка времени из-за возросшей нагрузки в вычислительной системе.
Потери, связанные с невыполнением таких задач, могут оказаться больше, чем потери от невыполнения программ с более высоким приоритетом. При этом оказывается целесообразным временно изменить приоритет «аварийных» задач (для которых истекает отпущенное для них время обработки). После выполнения этих задач их приоритет восстанавливается.
Поэтому почти в любой ОС реального времени имеются средства для изменения приоритета программ (Dynamic priority variation.)
Лекция 5
Работа со служебными программами
В состав операционных систем обычно входят программы настройки и обслуживания компьютера, а также программы, позволяющие получать информацию о работе компьютера.
Восстановление системы
Дефрагментация диска
Очистка диска
Сведения о системе
Архивация данных
Дефрагментация диска
«Дефрагментация диска» — это системная служебная программа, выполняющая анализ локальных томов с последующим поиском и объединением фрагментированных файлов и папок. Процесс перезаписи частей файла в соседние сектора на жестком диске для ускорения доступа и загрузки. При обновлении файла компьютер стремится сохранить изменения в наибольшей свободной области на жестком диске. Программа анализирует и объединяет фрагментированные файлы и папки таким образом, чтобы каждый файл или папка тома занимали единое непрерывное пространство. В результате чтение и запись файлов и папок выполняется эффективнее.
Объединяя отдельные части файлов и папок, программа дефрагментации также объединяет в единое целое свободное место на томе, что делает менее вероятной фрагментацию новых файлов. Процесс объединения фрагментированных файлов и папок называется дефрагментацией.
 Отчетное
окно дефрагментации
Отчетное
окно дефрагментации
Очистка диска
Во время работы за компьютером на жестком диске накапливается большое количество ненужной информации. Это всевозможные временные файлы, скачанные из Интернет веб-страницы, а также не используемые файлы приложений. Чем больше программ вы устанавливаете и запускаете, чем чаще выходите в Интернет - тем больше шансов появления на жестком диске разного бесполезного мусора, который занимает драгоценное свободное место. Для поддержания порядка на своем ПК необходимо периодически устраивать уборку. Операционная система Windows XP предоставляет множество полезных утилит, среди которых есть программа под названием "Очистка диска".
Утилита "Очистка диска" располагается в стандартном наборе служебных программ Windows XP. Для ее запуска активируйте Пуск (Start), Программы (Programs), Стандартные (Accessories), Служебные (System Tools), Очистка диска (Disk Cleanup). Иначе программу можно запустить из командной строки, набрав ее название: cleanmgr. После запуска утилиты на экране появится рабочее окно программы
Архивация данных
Один из вариантов восстановления системы: создание резервной копию всех файлов и папок своей системы припомощи стандартной утилиты «Архивация данных». Для этого,в «Свойствах» (Properties) жёсткого диска выберите закладку «Сервис »(Tools) и нажмите на кнопку «Выполнить архивацию...» (Backup now...), или (Меню Пуск(Start) —> Программы(Programs) —> Стандартные(Accessories) —> Служебные(System Tools) —> Архивация(Backup)). В открывшемся окне выберите закладку «Архивация» (Backup), и отметьте архивацию всего содержимого данного компьютера.
 Выбор
предлагаемой операции
Выбор
предлагаемой операции
 Выбираем
элементы, которые следует заархивировать
Выбираем
элементы, которые следует заархивировать
Сведения о системе
Программа «Сведения о системе» собирает и отображаетданные о конфигурации системы. Такие данные можно получить как для локального компьютера, так и для удаленного компьютера, с которым установлено соединение.
Сюда входит информация о конфигурации оборудования, компонентах компьютера, а также программном обеспечении, в том числе о подписанных и неподписанных драйверах. При устранении неполадок, связанных с конфигурацией системы, сотрудникам службы технической поддержки необходимы определенные данные о компьютере. Программа «Сведения о системе» позволяет быстро собрать необходимые данные
 Все
сведения о системе, находящейся на
компьютере
Все
сведения о системе, находящейся на
компьютере
API ОС
Интерфейс прикладного программирования (иногда интерфейс программирования приложений) (англ. application programming interface, API) — набор готовых классов, процедур, функций, структур и констант, предоставляемых приложением (библиотекой, сервисом) для использования во внешних программных продуктах. Используется программистами для написания всевозможных приложений.
API как средство интеграции приложений
API определяет функциональность, которую предоставляет программа (модуль, библиотека), при этом API позволяет абстрагироваться от того, как именно эта функциональность реализована.
Если программу (модуль, библиотеку) рассматривать как чёрный ящик, то API — это множество «ручек», которые доступны пользователю данного ящика, которые он может вертеть и дёргать.
Программные компоненты взаимодействуют друг с другом посредством API. При этом обычно компоненты образуют иерархию — высокоуровневые компоненты используют API низкоуровневых компонентов, а те, в свою очередь, используют API ещё более низкоуровневых компонентов.
По такому принципу построены протоколы передачи данных по Internet. Стандартный стек протоколов (сетевая модель OSI) содержит 7 уровней (от физического уровня передачи бит до уровня протоколов приложений, подобных протоколам HTTP и IMAP). Каждый уровень пользуется функциональностью предыдущего уровня передачи данных и, в свою очередь, предоставляет нужную функциональность следующему уровню.
Важно заметить, что понятие протокола близко по смыслу к понятию API. И то и другое является абстракцией функциональности, только в первом случае речь идёт о передаче данных, а во втором — о взаимодействии приложений.
API библиотеки функций и классов включает в себя описание сигнатур и семантики функций.
Сигнатура функции
Сигнатура функции — часть общего объявления функции, позволяющая средствам трансляции идентифицировать функцию среди других. В различных языках программирования существуют разные представления о сигнатуре функции, что также тесно связано с возможностями перегрузки функции в этих языках.
Иногда различают сигнатуру вызова и сигнатуру реализации функции. Сигнатура вызова обычно составляется по синтаксической конструкции вызова функции с учётом сигнатуры области видимости данной функции, имени функции, последовательности фактических типов аргументов в вызове и типе результата. В сигнатуре реализации обычно участвуют некоторые элементы из синтаксической конструкции объявления функции: спецификатор области видимости функции, её имя и последовательность формальных типов аргументов.
Например, в языке программирования Си++ простая функция однозначно опознаётся компилятором по её имени и последовательности типов её аргументов, что составляет сигнатуру функции в этом языке. Если функция является методом некоторого класса, то в сигнатуре будет участвовать и имя класса.
В языке программирования Java сигнатуру метода составляет его имя и последовательность типов параметров; тип значения в сигнатуре не участвует.
Семантика функции
Семантика функции — это описание того, что данная функция делает. Семантика функции включает в себя описание того, что является результатом вычисления функции, как и от чего этот результат зависит. Обычно результат выполнения зависит только от значений аргументов функции, но в некоторых модулях есть понятие состояния. Тогда результат функции может зависеть от этого состояния, и, кроме того, результатом может стать изменение состояния. Логика этих зависимостей и изменений относится к семантике функции. Полным описанием семантики функций является исполняемый код функции или математическое определение функции.
API операционных систем. Проблемы, связанные с многообразием API
Практически все операционные системы (Unix, Windows, Mac OS, и т. д.) имеют API, с помощью которого программисты могут создавать приложения для этой операционной системы. Главный API операционных систем — это множество системных вызовов.
В индустрии программного обеспечения общие стандартные API для стандартной функциональности имеют важную роль, так как они гарантируют, что все программы, использующие общий API, будут работать одинаково хорошо или, по крайней мере, типичным привычным образом. В случае API графических интерфейсов это означает, что программы будут иметь похожий пользовательский интерфейс, что облегчает процесс освоения новых программных продуктов.
С другой стороны, отличия в API различных операционных систем существенно затрудняют перенос приложений между платформами. Существуют различные методы обхода этой сложности — написание «промежуточных» API (API графических интерфейсов Qt, Gtk, и т. п.), написание библиотек, которые отображают системные вызовы одной ОС в системные вызовы другой ОС (такие среды исполнения, как Wine, cygwin, и т. п.), введение стандартов кодирования в языках программирования (например, стандартная библиотека языка C), написания интерпретируемых языков, реализуемых на разных платформах (sh, python, perl, php, tcl, Java, и т. д.).
Также необходимо отметить, что в распоряжении программиста часто находится несколько различных API, позволяющих добиться одного и того же результата. При этом каждый API обычно реализован с использованием API программных компонент более низкого уровня абстракции.
Например: для того чтобы увидеть в браузере строчку «Hello, world!», достаточно лишь создать HTML-документ с минимальным заголовком и простейшим телом, содержащим данную строку. Что произойдёт, когда браузер откроет этот документ? Программа-браузер передаст имя файла (или уже открытый дескриптор файла) библиотеке, обрабатывающей HTML-документы, та, в свою очередь, при помощи API операционной системы прочитает этот файл и разберётся в его устройстве, затем последовательно вызовет через API библиотеки стандартных графических примитивов операции типа «очистить окошко», «написать выбранным шрифтом «Hello, world!». Во время выполнения этих операциях библиотека графических примитивов обратится к библиотеке оконного интерфейса с соответствующими запросами, уже эта библиотека обратится к API операционной системы, чтобы записать данные в буфер видеокарты.
При этом практически на каждом из уровней реально существует несколько возможных альтернативных API. Например: мы могли бы писать исходный документ не на HTML, а на LaTeX, для отображения могли бы использовать любой браузер. Различные браузеры, вообще говоря, используют различные HTML-библиотеки, и, кроме того, всё это может быть (вообще говоря) собрано с использованием различных библиотек примитивов и на различных операционных системах.
Основными сложностями существующих многоуровневых систем API, таким образом, являются:
Сложность портирования программного кода с одной системы API на другую (например, при смене ОС);
Потеря функциональности при переходе с более низкого уровня на более высокий. Грубо говоря, каждый «слой» API создаётся для облегчения выполнения некоторого стандартного набора операций. Но при этом реально затрудняется, либо становится принципиально невозможным выполнение некоторых других операций, которые предоставляет более низкий уровень API.
Наиболее известные API
API операционных систем
POSIX
Windows API
Cocoa
Linux Kernel API
OS/2 API
Amiga ROM Kernel
API графических интерфейсов
OpenGL
OpenVG
X11
Qt
GTK
Motiff
Tk
GDI
GDI+
Direct3D (часть DirectX)
DirectDraw (часть DirectX)
Zune
SDL
API звуковых интерфейсов
DirectSound (часть DirectX)
DirectMusic (часть DirectX)
OpenAL
API аутентификационных систем
BioAPI
PAM
Web API
Используется в веб-разработке, как правило, определенный набор HTTP запросов, а также определение структуры HTTP ответов. Для выражения которых используют XML или JSON форматы. «Web API» является практически синонимом для веб-службы, хотя в последнее время за счет тенденции Web 2.0, осуществлен переход от SOAP к REST типу коммуникации. Веб-интерфейсы обеспечивающие сочетание нескольких сервисов в новых приложениях известны как гибридные.
Структура окон, функций, сообщений
Сообщения являются реакцией системы Windows на различные происходящие в системе события: движение мыши, нажатие клавиши, срабатывание таймера и т. д. Отличительным признаком сообщения является его код, который может принимать значения (для системных сообщений) от 1 до 0x3FF. Каждому коду соответствует своя символическая константа, имя которой достаточно ясно говорит об источнике сообщения. Так, при движении мыши возникают сообщения WMMOUSEMOVE (код 0x200), при нажатии на левую клавишу мыши - сообщение WMLBUTTONDOWN (код 0x201), при срабатывании таймера - WMJTTMER (код Ох 113).
Перечисленные события относятся к числу аппаратных; однако сообщения могут возникать и в результате программных действий системы или прикладной программы. Так, по ходу создания и вывода на экран главного окна Windows последовательно посылает в приложение целую группу сообщений, сигнализирующих об этапах этого процесса: WMGETMINMAXINFO для уточнения размеров окна, WMJ5RASEBK.GND при заполнении окна цветом фона, WMJ3IZE при оценке размеров рабочей области окна, WM PAINT для получения от программы информации о содержимом окна и многие другие. Некоторые из этих сообщений Windows обрабатывает сама; другие обязана обрабо- тать прикладная программа.
Может быть и обратная ситуация, когда сообщение создается в прикладной программе по воле программиста и посылается в Windows для того, чтобы система выполнила требуемые действия (например, заполнила конкретной информацией окно со списком или сообщила о состоянии некоторого элемента управления). Сообщения такого рода тоже стандартизованы и имеют определенные номера. Наконец, программист может предусмотреть собственные сообщения и направлять их в различные окна приложения для оповещения о тех или иных ситуациях.
Оконная функция вызывается, как только в структуру Msg попадает очередное сообщение, извлеченное из входной очереди. Задача оконной функции - определить природу сообщения и обработать его соответствующим образом. Из заголовка оконной функции LRESULT CALLBACK WndProc(HWND hwnd.UINT msg,WPARAM wParam,LPARAM lParam) видно, что она получает при активизации ее (функцией DispatchMessage()) 4 параметра. Первый параметр (hwnd) - дескриптор окна, которому предназначено данное сообщение. Это тот самый дескриптор, который был получен нами как результат работы функции CreateWindow(). Теперь этот же дескриптор вернулся к нам из Windows как параметр оконной функции. Он особенно полезен в тех случаях, когда на базе одного класса создается несколько различающихся чем-то окон. Если класс один, то и оконная функция для всех этих окон одна; анализируя тогда параметр hwnd, программа может определить, в какое именно окно пришло сообщение. У нас окно одно, однако аргумент hwnd все же понадобится.
Второй параметр (msg) определяет код пришедшего сообщения. Поскольку сообщений много, оконная функция должна прежде всего проанализировать этот код и осуществить переход на фрагмент обработки соответствующего сообщения. В настоящем (не лучшем,, как будет видно из дальнейшего) варианте программы анализ аргумента msg осуществляется с помощью конструкции switch...case.
Структура графических интерфейсов
Структура приложения Windows
Программа состоит из нескольких отчетливо выделенных блоков (разделов):
группы операторов препроцессора;
раздела прототипов используемых в программе прикладных функций;
главной функции WinMain();
оконной функции главного окна.
Рассмотрим последовательно эти блоки.
Программа начинается с двух директив препроцессора #include, с помощью которых к программе подключаются заголовочные файлы. Как уже отмечалось, заголовочный файл WINDOWS.H (а также целая группа дополнительных заголовочных файлов, подключаемых 'изнутри" файла WINDOWS.H ) обеспечивает понимание компилятором смысла типов данных Windows, констант и макросов и подключение этого файла к исходному тексту программы является обязательным. Часть определений, используемых в программах (например, макроса GetStockBrush() и других с ним сходных, или макроса HANDLE_MSG, о котором речь будет идти ниже), содержится в файле WINDOWSX.H, который также необходимо включать практически во все приложения Windows.
Вслед за операторами препроцессора в нашем примере идет раздел прототипов, где определяется прототип единственной в данной программе прикладной функции WndProc(). Вообще-то в программе обязательно должны быть указаны прототипы всех используемых функций, как прикладных, так и системных. Вызовов системных функций Windows у нас довольно много: RegisterClass(), CreateWindowQ, GetMessage() и др. Однако прототипы всех этих функций уже определены в заголовочных файлах системы программирования. Так, прототип функции WinMain() описан в файле WINBASE.H:
int WINAPI WinMain( HINSTANCE hlnstance,//Дескриптор текущего экземпляра приложения HINSTANCE hPrevInstance,//Дескриптор предыдущего экземпляра приложения LPSTR lpszCmdLine,//Указатель на параметры командной строки int nCmdShow//Константа, характеризующая начальный вид окна ) ;
Легко увидеть, что заголовок функции WinMain() в нашей программе в точности соответствует приведенному выше прототипу (за исключением того, что мы опустили неиспользуемые параметры). Иначе и быть не может. Достаточно изменить хотя бы немного характеристики нашей функции WinMain(), как программа либо не пройдет этапа компиляции, либо не будет загружаться для выполнения, либо загрузится, но не будет работать.
Прототипы остальных использованных в программе функций Windows определены в файле WINUSER.H. Таким образом, о прототипах функций Windows можно не заботиться. Иное положение с оконной функцией WndProc(). Это прикладная функция, ее имя может быть каким угодно, и системе программирования это имя неизвестно. Более того, 120 Win32. Основы программирования при наличии в приложении нескольких окон (а практически всегда так и бывает) в программе описывается несколько оконных функций, по одной для каждого класса окон. Для всех используемых в программе оконных функций необходимо указывать их прото типы.
С другой стороны, формат оконной функции, т. е. количество и типы входных параметров функции, как и тип возвращаемого ею значения, определены системой Windows и не могут быть произвольно изменены. Действительно, оконная функция вызывается из Windows при поступлении в приложение того или иного сообщения. При ее вызове Windows передает ей вполне определенный список параметров, и функция должна иметь возможность эти параметры принять и работать с ними. Поэтому в интерактивном справочнике системы программирования дается шаблон (template) оконной функции, который по своему виду очень похож на прототип, однако является не прототипом конкретной функции, а заготовкой для прикладного программиста:
LRESULT CALLBACK WindowProc( HWND hwnd,//Дескриптор окна UINT uMsg, 11Код сообщения WPARAM wParam,//Первый параметр сообщения LPARAM lParam //Второй параметр сообщения ) ;
Опять можно заметить, что наша оконная функция, имея другое имя, в точности соответствует приведенному выше шаблону: принимает 4 параметра указанных типов и возвращает (в Windows) результат типа LRESULT. Кроме того, она объявлена с описателем CALLBACK. Что обозначает этот описатель?
В файле WINDEF.H символическое обозначение CALLBACK объявляется равнозначным ключевому слову языка C++ stdcall, которое определяет правила взаимодействия функций с вызывающими процедурами. В Win32 практически для всех функций действует так называемое соглашение стандартного вызова. Это соглашение определяет, что при вызове функции ее параметры помещаются в стек в таком порядке, что в глубине стека оказывается последний параметр, а на вершине - первый. Сама функция, разумеется, знает о таком расположении ее параметров и выбирает их из стека в правильном порядке. Для 16-разрядных функций Windows действует соглашение языка Паскаль, при котором порядок помещения параметров в стек обратный.
Обработка сообщений
Пример функции ReportError для вывода сообщений об ошибках при выполнении системных вызовов
/* Универсальная функция для вывода сообщений о системных ошибках. */
#include "EvryThng.h" VOID ReportError (LPCTSTR UserMessage, DWORD ExitCode, BOOL PrintErrorMsg){ DWORD eMsgLen, LastErr = GetLastError(); LPTSTR lpvSysMsg; HANDLE hStdErr - GetStdHandle (STD_ERROR_HANDLE); PrintMsg (hStdErr, UserMessage); if (PrintErrorMsg){ eMsgLen=FormatMessage (FORMAT_MESSAGE_ALLOCATE_BUFFER|FORMAT_MESSAGE_FROM_SYSTEM, NULL, LastErr, MAKELANGID (LANG_NEUTRAL, SUBLANG_DEFAULT),(LPTSTR) &lpvSysMsg, 0, NULL); PrintStrings (hStdErr, _T (“\n”), lpvSysMsg, _T (n\n")/ NULL);
/* Освободить блок памяти, содержащий сообщение об ошибке. */
HeapFree (GetProcessHeap (), 0, lpvSysMsg); } if (ExitCode > 0) ExitProcess (ExitCode); else return; }
Если отслеживать исключения, которые возникают на том или ином участке программы, надо создать блоки try и except:
__try{ /* Блок контролируемого кода */ } __except(выражение_фильтра){/*Блок обработки исключений*/} __try и __except - ключевые слова, опознаваемые компилятором.
Блоки try являются частью обычного кода приложения. Если на данном участке кода возникает исключение, ОС передает управление обработчику исключений, который представляет собой блок программного кода, следующий за ключевым словом except. Характер последующих действий определяется значением параметра выражение_фильтра. Исключение может возникнуть также в пределах блока, находящегося внутри try-блока; в этом случае средства поддержки времени исполнения "разворачивают" стек, чтобы отыскать в нем информацию об обработчике исключений, после чего передают управление этому обработчику. То же самое происходит и в тех случаях, когда исключения возникают внутри функций, вызванных в пределах try-блока.
События
Последним из типов объектов синхронизации ядра являются события (events). Объекты события используются чтобы сигнализировать другим потокам о наступлении какого-либо события, например, о появлении нового сообщения. Переход в сигнальное состояние единственного объекта события выведет из состояния ожидания одновременно до несколько потоков. Объекты события делятся на сбрасываемые вручную и автоматические, это их свойство устанавливается при вызове CreateEvent.
Сбрасываемые вручную события (manual-reset events) могут сигнализировать одновременно всем потокам, ожидающим наступления этого события, и переводятся в несигнальное состояние программно.
Автоматически сбрасываемые события (auto-reset event) сбрасываются самостоятельно после освобождения одного из ожидающих потоков, тогда как другие ожидающие потоки продолжают ожидать перехода события в сигнальное состояние.
События используют пять новых функций: CreateEvent, OpenEvent, SetEvent, ResetEvent и CreateEvent. HANDLE CreateEvent(LPSECURITY_ATTRIBUTES lpsa, BOOL bManualReset, BOOL bInitialState, LPTCSTR lpEventName) Чтобы создать событие, сбрасываемое вручную, необходимо установить значение параметра bManualReset равным True. Чтобы сделать начальное состояние события сигнальным, установить равным True значение параметра bInitialState. Для открытия именованного объекта события используется функция OpenEvent, это может сделать и другой процесс.
Для управления объектами событий используются следующие три функции:
BOOL SetEvent (HANDLE hEvent)
BOOL ResetEvent (HANDLE hEvent)
BOOL PulseEvent (HANDLE hEvent)
Использование функции ShellExecute
#include <shellapi.h> // открыть страницу в сети Интернет ShellExecute(NULL, "open", "http://www.MyWebPage.com", NULL, NULL, SW_SHOWNORMAL); // открыть текстовый файл, расположенный в папке программы ShellExecute ( NULL, "open", "Readmy.txt", NULL, NULL, SW_SHOWNORMAL); // вывести на печать файл Word из текущей папки ShellExecute(NULL, "print", "Document.doc", NULL, NULL, SW_SHOWMINIMIZED); // найти папку Windows на корневом диске ShellExecute(NULL, "find", "c:\\Windows", NULL, NULL, SW_HIDE); // просмотреть папку Windows ShellExecute(NULL,"explore","c:\\Windows",NULL,NULL, SW_SHOWNORMAL); // написать письмо LPCTSTR lpMail = "mailto:MyBox@service.com?subject=Anekdot \&cc=MyBox@service.com"; ShellExecute ( NULL, NULL, lpMail, NULL, NULL, SW_SHOWNORMAL); // запустить программу из текущей папки ShellExecute ( NULL, NULL, "MyProgramm.exe", "-mycommand", NULL, SW_SHOWNORMAL) ; // просмотреть графический файл ShellExecute(NULL,"open","d:\\images\\pricol.bmp",NULL,NULL,SW_SHOWNORMAL)
Кроме основной функции ShellExecute, существует ее расширенный вариант, именуемый ShellExecuteEx. Отличается она, дополнительной поддержкой свойств объектов СОМ. В большинстве случаев достаточно возможностей базовой функции.
Лекция 6
Ресурсы программ
Перед нами структура PE(PortableExecutable)файла Win (.EXE) и Common Object File Format (COFF). Далее идет описание секций и их атрибутов в порядке Section Name Content Characteristics.


.arch Alpha architecture information IMAGE_SCN_MEM_READ | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_ALIGN_8BYTES | IMAGE_SCN_MEM_DISCARDABLE .bss Uninitialized data IMAGE_SCN_CNT_UNINITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE .data Initialized data IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE .edata Export tables IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ .idata Import tables IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE .pdata Exception information IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ .rdata Read-only initialized data IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ .reloc Image relocations IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_DISCARDABLE .rsrc Resource directory IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE .text Executable code IMAGE_SCN_CNT_CODE | IMAGE_SCN_MEM_EXECUTE | IIMAGE_SCN_MEM_READ .tls Thread-local storage IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE .xdata Exception information IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ
Бывают еще секции .debug и .drectve но их, как правило, в исполняемом файле нет, поскольку они содержат информацию для линкера и отладчика соответственно.
Меню
Windows во многом упрощает нам работу программ, он берёт на себя практически все заботы об обслуживанию нашего окна, предлагает нам диалоги типа MessageBox... Ещё одна очень полезная вещь, это так называемые ресурсы. Нам достаточно записать лишь параметры нужных нам объектов в файл ресурсов, а Windows берёт на себя задачу создания соответствующих объектов и их обработки. Один из объектов ресурсов, он же наиболее часто используемый, меню. Все ресурсы наиболее удобно писать в редакторе ресурсов, например в Borland Workshop, (Распаковывется при помощи WinRar3) однако структура меню настолько легка, что её легче сделать вручную! Для этого надо создать файл расширения .rc , давайте создадим menu.rc, и записать в него следующие:
#define IDM_TEST 0 #define IDM_OPEN 1 #define IDM_SAVE 2 #define IDM_EXIT 3 IDM_MENU MENU { POPUP "&Файл" { MENUITEM "&Сохранить",IDM_SAVE MENUITEM "&Загрузить",IDM_OPEN MENUITEM SEPARATOR MENUITEM "Вы&ход",IDM_EXIT } MENUITEM "&Тест",IDM_TEST }
Прежде чем идти дальше, давайте разберёмся, что же мы записали. Заранее хочу предупредить, что файлы ресурсов пишутся не на ассемблере, именно поэтому я и советую работать с редактором ресурсов. Итак, первые четыре строчки равны следующим строкам на ассемблере:
IDM_TEST equ 1 IDM_OPEN equ 2 IDM_SAVE equ 3 IDM_EXIT equ 4
то есть мы создаём условные значения, которые при компиляции заменяются их реальными значениями. Следующйё строкой мы объявляем меню с именем IDM_MENU, объявляем одну подменю, в которой находится три пункта и разделительная полоса. и ещё одну кнопку в меню. А теперь давайте добавим информацию о меню в window.asm:
IDM_TEST equ 0 IDM_OPEN equ 1 IDM_SAVE equ 2 IDM_EXIT equ 3 include def32.inc include user32.inc include kernel32.inc .386 .model flat .const class db "window class 1",0 name_ db "Da window!",0 sure db "Предупреждение",0 ask db "Вы уверены, что хотите выйти?",0 menu_name db 'IDM_MENU',0 save_msg db 'Вы выбрали пункт Сохранить',0 open_msg db 'Вы выбрали пункт Загрузить',0 test_msg db 'Вы выбрали пункт Тест',0 .data wc wndclassex<4*12, CS_HREDRAW or CS_VREDRAW, offset win_proc, 0, 0, ?, ?, ?, COLOR_WINDOW+1, 0, offset class, 0> .data? msg_ msg <?,?,?,?,?,?> ;сам код .code _start: ;начальная метка xor ebx,ebx push ebx call GetModuleHandle mov esi,eax mov dword ptr wc.hInstance,eax push IDI_APPLICATION push ebx call LoadIcon mov wc.hIcon,eax push idc_arrow push ebx call LoadCursor mov wc.hCursor,eax push offset wc call RegisterClassEx push offset menu_name push esi call LoadMenu mov ecx,CW_USEDEFAULT push ebx push esi push eax ;Это не новая строка push ebx push ecx push ecx push ecx push ecx push WS_OVERLAPPEDWINDOW push offset name_ push offset class push ebx call CreateWindowEx push eax push SW_SHOWNORMAL push eax call ShowWindow call UpdateWindow mov edi,offset msg_ main_: push ebx push ebx push ebx push edi call GetMessage test eax,eax jz exit_ push edi call TranslateMessage push edi call DispatchMessage jmp main_ exit_: push ebx call ExitProcess win_proc proc push ebp mov ebp,esp wp_hWnd equ dword ptr [ebp+08h] wp_uMsg equ dword ptr [ebp+0Ch] wp_wParam equ dword ptr [ebp+10h] wp_lParam equ dword ptr [ebp+14h] cmp wp_uMsg,WM_CLOSE jne not_close push MB_YESNO push offset sure push offset ask push 0 call MessageBox cmp eax,IDYES je not_close mov wp_uMsg,0 jmp not_ not_close: cmp wp_uMsg,WM_DESTROY jne not_ push 0 call PostQuitMessage jmp end_ not_: cmp wp_uMsg,WM_COMMAND jne not_all mov eax,wp_wParam jmp dword ptr menus[eax*4] menus dd offset menu_test dd offset menu_open dd offset menu_save dd offset menu_exit menu_test: mov eax,offset test_msg jmp message_ menu_open: mov eax,offset open_msg jmp message_ menu_save: mov eax,offset save_msg message_: push MB_OK push offset menu_name push eax push wp_hWnd call MessageBox jmp end_ menu_exit: push wp_hWnd call DestroyWindow end_: leave ret 16 not_all: leave jmp DefWindowProc win_proc endp end _start
А теперь давайте разберёмся в новых строках. Итак, первые 4 новые строки, это создание виртуальных значений, это я думаю понятно. Дальше мы создаём 4 переменные, одну с именем меню, и три с сообщениями для messagebox. Следующие добавление, это загрузка меню из ресурсов, выполняемая процедурой LoadMenu, которая получает два параметра, имя меню и handle процесса. Далее мы заменяем одну строку при создании окна. Прошу обратить внимание, что эта строка уже существовала в прошлых примерах, просто мы помещали в стек не handle меню, а 0! Единственное, что нам осталось сделать, это добавить в процедуру нашего окна обработку событий меню. При получении сообщения от меню, главное сообщение содержит команду WM_COMMAND, а уже первый параметр сообщения содержит номер выбранного меню. То есть нам надо добавить только обработку сообщения wm_command. И только если сообщение действительно WM_COMMAND, обрабатывать первый параметр. При этом в файл user32.inc следует дописать следующие строки:
extrn __imp__LoadMenuA@8:dword extrn __imp__DestroyWindow@4:dword LoadMenu equ __imp__LoadMenuA@8 DestroyWindow equ __imp__DestroyWindow@4
А в файл def32.inc
MB_OK equ 0 WM_COMMAND equ 111h
Диалоговые окна
Диалоговое окно (англ. dialog box) — в графическом пользовательском интерфейсе специальный элемент интерфейса, окно, предназначенное для вывода информации и (или) получения ответа от пользователя. Получил своё название потому, что осуществляет двустороннее взаимодействие компьютер-пользователь («диалог»): сообщая пользователю что-то и ожидая от него ответа.
Диалоговые окна подразделяются на модальные и немодальные, в зависимости от того, блокируют ли они возможность взаимодействия пользователя с приложением (или системой в целом) до тех пор, пока не получат от него ответ.
 Пример
окна сообщения.
Пример
окна сообщения.
Простейшим типом диалогового окна является окно сообщения (англ. message box, англ. alert box), которое выводит сообщение и требует от пользователя подтвердить, что сообщение прочитано. Для этого обычно необходимо нажать кнопку OK. Окно сообщения предназначено для подтверждения системой выполнения команды, вывода сообщения об ошибке и тому подобных случаев, не требующих от пользователя какого-либо выбора.
Несмотря на то, что использование окна сообщения является часто применяемым шаблоном проектирования, оно критикуется экспертами по юзабилити как неэффективное решение для поставленной задачи (защита от ошибочных действий пользователя), вдобавок, при наличии лучших альтернатив.
Кнопки
 Пример
запроса подтверждения.
Пример
запроса подтверждения.
В диалоговых окнах многих программ присутствуют кнопки OK и Отмена (Cancel), нажимая первую из которых пользователь выражает своё согласие с тем, что в этот момент отображает диалоговое окно, и тем самым закрывает его, приводя в действие сделанные в нём изменения, а вторая — закрывает окно без применения. Существуют варианты с единственной кнопкой ОК — в информирующих окнах, не подразумевающих каких-либо изменений, и с кнопками ОК, Применить (Apply) и Закрыть (Close), в окнах, результаты изменений в которых пользователь, по мнению автора программы, может оценить не закрывая окна, и в случае неудовлетворительного результата продолжить внесение изменений.
Так же хорошим тоном считается обеспечить в диалоговых окнах справочную систему — обычно это реализуется либо в виде кнопки Справка (Help), открывающей страницу документации, описывающую работу в этом диалоговом окне, либо (в Windows) с помощью кнопки с знаком вопрос в заголовке окна, нажав на которую пользователь переключает мышь в режим одноразовой контекстной подсказки: нажатие мышью в этом режиме на элемент диалогового окна вызывает отображение описания этого элемента.
Немодальные диалоговые окна
Немодальные (англ. modeless) диалоговые окна используются в случаях, когда выводимая в окне информация не является существенной для дальнейшей работы системы. Поэтому окно может оставаться открытым, в то время как работа пользователя с системой продолжается. Разновидностью немодального окна является панель инструментов или окно-«палитра», если она отсоединена или может быть отсоединена от главного окна приложения, так как элементы управления, расположенные на ней, могут использоваться параллельно с работой приложения. Впрочем, такие окна редко называют «диалоговыми».
В общем случае, правила хорошего программного дизайна предлагают использовать именно этот тип диалоговых окон, так как он не принуждает пользователя к определённой (возможно, не очевидной для него) последовательности действий. Примером может быть диалоговое окно для изменения каких-либо свойств текущего документа, например, цвета фона или текста. Пользователь может вводить текст, не обращая внимания на его цвет. Но в любой момент может изменить цвет, используя диалоговое окно. (Приведённый пример не обязательно является лучшим решением. Такую же функциональность может обеспечить и панель инструментов, расположенная в главном окне.)
Модальные на уровне приложения
Модальным называется окно, которое блокирует работу пользователя с родительским приложением до тех пор, пока пользователь это окно не закроет. Диалоговые окна преимущественно реализованы модальными.
Например, модальными являются диалоговые окна настроек приложения — так как проще реализовать режим, когда все сделанные изменения настроек применяются или отменяются одномоментно, и с момента, когда пользователь решил изменить настройки приложения и открыл диалог настроек, и до момента, когда он новые настройки вводит в силу или отказывается от них, приложение ожидает решения пользователя.
Отображение окон в модальном режиме практикуется и в других случаях, когда приложению для продолжения начатой работы требуется дополнительная информация, либо просто подтверждение от пользователя на согласие выполнить запрошенную последовательность действий, если она потенциально опасна.
Специалисты по юзабилити считают модальные окна запросов подтверждений плохими дизайнерскими решениями, так как они могут приводить пользователя к, так называемым, «ошибкам режима программы». Опасные действия должны иметь возможность отмены везде, где это возможно, а модальные окна запросов подтверждений, пугающие пользователя своим неожиданным появлением, через некоторое время пропускаются им автоматически (так как он привык к ним) и, поэтому, не защищают от опасных действий.
Модальные на уровне окна
Для смягчения недостатков модальных диалоговых окон (блокирование доступа к приложению, или, даже, к системе в целом) была предложена концепция модальности на уровне окна (или документа). Такой тип диалогового окна введён, например, в Mac OS X, где он называется «диалоговое модальное окно для документа» (англ. document modal sheet).
При появлении диалогового окна подобного типа, работа с остальными окнами приложения не блокируется. Поскольку окно диалога не перекрывает родительское окно, а прикрепляется к нему, остаётся возможность изменять размеры и положение и самого родительского окна. При этом, естественно, содержимое родительского окна остаётся недоступным до закрытия модального диалогового окна.
Стандартные элементы управления
В предыдущих главах мы познакомились с некоторыми элементами управления, которые обычно используются в составе диалоговых окон, однако могут выступать и элементами главного или вложенных окон приложения. В наших примерах встречались:
нажимаемые кнопки;
альтернативные кнопки;
списки;
комбинированные списки;
статические элементы управления - тексты;
групповые рамки;
линейки прокрутки;
линейки с ползунками;
окна редактирования.
В действительности состав элементов управления шире. В частности, для 32-разрядных приложений разработана группа элементов управления с современным интерфейсом, объединяемых странным названием "стандартные элементы управления" (Common controls). В настоящей главе будут рассмотрены примеры приложений с некоторыми из элементов управления, входящих в эту группу.
Графический список
Графический список (list view) является многофункциональным элементом управления, широко используемым, в частности, для вывода на экран содержимого каталогов. Графическим он называется потому, что позволяет включать в его состав не только текстовые строки, но и значки (пиктограммы). На рисунке изображена одна из форм графи ческого списка (в виде таблицы), где значки присутствуют только в самом левом, основном столбце, а остальные, дополнительные столбцы заполнены текстовыми строками.
Характерной чертой графического списка является наличие в его верхней части заголовка списка - самостоятельного стандартного элемента управления, который можно использовать и отдельно от графического списка, в сочетании с другими элементами управления. Заголовок списка содержит отдельные поля, совпадающие со столбцами списка. Размер полей заголовка и, соответственно, столбцов списка можно изменять, перетаскивая мышью вертикальные линейки, разделяющие поля заголовка. Щелчок мышью по основному (самому левому) элементу списка формирует сообщение Windows, обрабатывая которое можно выполнить любые запланированные действия над этим элементом.
Графический список имеет встроенные средства динамического изменения его вида (таблица, список, мелкие значки, крупные значки), что делает его чрезвычайно удобным для просмотра содержимого дисков и каталогов (папок) и обслуживания файловой системы.
 Кадр
программы "Мой компьютер" с
графическим списком в главном окне
Кадр
программы "Мой компьютер" с
графическим списком в главном окне
Индикатор прогресса
Индикатор прогресса (progress bar) представляет собой окно в виде линейки, заполняемое небольшими яркими полосками по мере продвижения некоторого процесса, например копирования файлов, установки системы или просто длительных вычислений
![]() Индикатор
прогресса
Индикатор
прогресса
Для того чтобы индикатор прогресса мог выполнять свои функции, индицируемый процесс должен состоять из некоторого известного заранее количества шагов, завершение каждого из которых и будет продвигать индикатор прогресса на одно деление.
Наборный счетчик
Наборный счетчик (up-down control или spin control) представляет собой пару кнопок со стрелками, с помощью которых можно увеличивать или уменьшать значение некоторой величины и использовать затем это значение в программе. Часто рядом со стрелками располагают небольшое окно ввода, в котором фиксируется выбранное с помощью стрелок значение и которое можно также использовать для ввода требуемого значения с клавиатуры. Поскольку это окно тесно связано с основным окном счетчика, его называют "приятелем счетчика" (buddy).
![]() Наборный
счетчик с "приятелем" - окном ввода
Наборный
счетчик с "приятелем" - окном ввода
Редакторы ресурса
В операционную систему Windows введено понятие ресурса. Ресурс представляет собой некий визуальный элемент с заданными свойствами, хранящийся в исполняемом файле отдельно от кода и данных, который может отображаться специальными функциями.
Использование ресурсов дает две вполне определенные выгоды:
Ресурсы загружаются в память лишь при обращении к ним, т.е. реализуется экономия памяти.
Свойства ресурсов поддерживаются системой автоматически, не требуя от программиста написания дополнительного кода.
Описание ресурсов хранится отдельно от программы в текстовом файле (*.rc) и компилируется (*.res) специальным транслятором ресурсов. В исполняемый файл ресурсы включаются компоновщиком. Транслятором ресурсов в пакете MASM32 является RC.EXE, в пакете TASM32 - BRCC32.EXE.
Каждая среда программирования имеет редактор ресурсов с соответствующими возможностями. Однако, «правильные» редакторы среди них отсутствуют L, лучшее решение – Restorator resource editor (платное), XN resource editor - бесплатное.
Наиболее употребляемые ресурсы:
Иконки.
Курсоры.
Битовая картинка.
Строка.
Диалоговое окно.
Меню.
Акселераторы.
1. Иконки. Могут быть описаны в самом файле ресурсов, либо храниться в отдельном файле *.ico. Рассмотрим последний случай. Вот файл ресурсов resu.rc:
#define IDI_ICON1 1 IDI_ICON1 ICON "Cdrom01.ico"
Как видите, файл содержит всего две значимых строки. Одна строка определяет идентификатор иконки, вторая - ассоциирует идентификатор с файлом "Cdrom01.ico". Оператор define является Си-оператором препроцессора. Как вы увидите в дальнейшем, язык ресурсов очень напоминает язык Си. Откомпилируем текстовый файл resu.rc: RC resu.rc. На диске появляется объектный файл resu.res. При компоновке укажем этот файл в командной строке:
LINK /subsystem:windows resu.obj resu.res
2. Курсоры. Подход здесь полностью идентичен. Привожу ниже файл ресурсов, где определен и курсор, и иконка.
#define IDI_ICON1 1 #define IDI_CUR1 2 IDI_ICON1 ICON "Cdrom01.ico" IDI_CUR1 CURSOR "4way01.cur"
3. Битовые картинки (*.BMP). Здесь ситуация аналогична двум предыдущим. Вот пример файла ресурсов с битовой картинкой.
#define ВIТ1 1 BIT1 BITMAP "PIR2.BMP"
4. Строки. Чтобы задать строку или несколько строк используется ключевое слово STRINGTABLE. Ниже представлен текст ресурса, задающий две строки. Для загрузки строки в программу используется функция LoadString (см. ниже). Строки, задаваемые в файле ресурсов, могут играть роль констант.
#define STR1 1 #define STR2 2 STRINGTABLE { STR1, "Сообщение" STR2, "Версия 1.01" }
5. Диалоговые окна. Диалоговые окна являются наиболее сложными элементами ресурсов. В отличие от ресурсов, которые мы до сих пор рассматривали, для диалога не задается идентификатор. Обращение к диалогу происходит по его имени (строке).
#define WS_SYSMENU 0x00080000L
#define WS_MINIMIZEBOX 0x00020000L
#define WS_MAXIMIZEBOX 0x00010000L DIAL1 DIALOG 0, 0, 240, 120 STYLE WS_SYSMENU | WS_MINIMIZEBOX | WS_MAXIMIZEBOX CAPTION "Пример диалогового окна" FONT 8, "Arial" { }
6. Меню. Меню также может быть задано в файле ресурсов. Как и диалоговое окно, в программе оно определяется по имени (строке). Меню можно задать и в обычном окне, и в диалоговом окне. Для обычного окна при регистрации класса следует просто заменить строку
MOV DWORD PTR [WC.CLMENNAME],0
на
MOV DWORD PTR [WC.CLMENNAME], OFFSET MENS
Здесь MENS - имя, под которым меню располагается в файле ресурсов. Меню на диалоговое окно устанавливается другим способом, который, разумеется, подходит и для обычного окна. В начале меню загружается при помощи функции LoadMenu, а затем устанавливается функцией SetMenu.
7. Акселераторы. На первый взгляд этот вопрос достаточно прост, но, как станет ясно, он потянет за собой множество других. Акселератор позволяет выбирать пункт меню просто сочетанием клавиш. Это очень удобно и быстро. Таблица акселераторов является ресурсом, имя которого должно совпадать с именем того меню (ресурса), пункты которого она определяет.
Вот пример такой таблицы. Определяется один акселератор на пункт меню MENUP, имеющий идентификатор 4.
MENUP ACCELERATORS { VK_F5, 4, VIRTKEY }
А вот общий вид таблицы акселераторов.
Имя ACCELERATORS
{
Клавиша 1, Идентификатор пункта меню (1) [,тип] [,параметр]
Клавиша 2, Идентификатор пункта меню (2) [,тип] [,параметр]
Клавиша 3, Идентификатор пункта меню (3) [,тип] [,параметр]
...
Клавиша N, Идентификатор пункта меню (N) [,тип] [,параметр]
Реестр
Реестр Windows или системный реестр (англ. Windows Registry) — иерархически построенная база данных параметров и настроек в большинстве операционных систем Microsoft Windows.
Реестр содержит информацию и настройки для аппаратного обеспечения, программного обеспечения, профилей пользователей, предустановки. Большинство изменений в Панели управления, ассоциации файлов, системные политики, список установленного ПО фиксируются в реестре.
Реестр Windows был введён для упорядочения информации, хранившейся до этого во множестве INI-файлов, которые использовались для хранения настроек до того, как появился реестр.
Реестр в том виде, как его использует Windows и как видит его пользователь в процессе использования программ работы с реестром, некоторым образом «нигде не хранится», а формируется из различных данных. Чтобы получилось то, что видит пользователь, редактируя реестр, происходит следующее.
Вначале, в процессе установки и настройки Windows, на диске формируются файлы, в которых хранится часть данных относительно конфигурации системы.
Затем, в процессе каждой загрузки системы, а также в процессе каждого входа и выхода каждого из пользователей, формируется некая виртуальная сущность, называемая «реестром» — объект REGISTRY\. Данные для формирования «реестра» частично берутся из тех самых файлов (Software, System …), частично из информации, собранной ntdetect при загрузке (HKLM\Hardware\Description).
То есть часть данных реестра хранится в файлах, а часть данных формируется в процессе загрузки Windows.
Для редактирования, просмотра и изучения реестра стандартными средствами Windows (программы regedit.exe и regedt32.exe) доступны именно ветки реестра. После редактирования реестра и/или внесения в него изменений эти изменения сразу записываются в файлы.
Однако, есть программы сторонних разработчиков, которые позволяют работать непосредственно с файлами.
Программы оптимизации реестра, твикеры, а также инсталляторы и деинсталляторы программ работают через специальные функции работы с реестром.
Утилиты
Утилита (англ. utility или tool) — компьютерная программа, расширяющая стандартные возможности оборудования и операционных систем, выполняющая узкий круг специфических задач.
Утилиты предоставляют доступ к возможностям (параметрам, настройкам, установкам), недоступным без их применения, либо делают процесс изменения некоторых параметров проще (автоматизируют его).
Утилиты зачастую входят в состав операционных систем или идут в комплекте со специализированным оборудованием.
Функции утилит
Мониторинг показателей датчиков и производительности оборудования — мониторинг температур процессора, видеоадаптера; чтение S.M.A.R.T. жёстких дисков; бенчмарки.
Управление параметрами оборудования — ограничение максимальной скорости вращения CD-привода; изменение скорости вращения кулеров.
Контроль показателей — проверка ссылочной целостности; правильности записи данных.
Расширение возможностей — форматирование и/или переразметка диска с сохранением данных, удаление без возможности восстановления.
Тонкая настройка параметров системы — твикер.
Типы утилит
Дисковые утилиты
Дефрагментаторы
Проверка диска — поиск неправильно записанных либо повреждённых различным путём файлов и участков диска и их последующее удаление для эффективного использования дискового пространства.
CHKDSK
fsck
Scandisk
Очистка диска — удаление временных файлов, ненужных файлов, чистка «корзины».
Очистка диска
CCleaner
Red Button
Разметка диска — деление диска на логические диски, которые могут иметь различные файловые системы и восприниматься операционной системой как несколько различных дисков.
PartitionMagic
GParted
fdisk
Резервное копирование — создание резервных копий целых дисков и отдельных файлов, а также восстановление из этих копий.
Список ПО для резервного копирования
Сжатие дисков — сжатие информации на дисках для увеличения вместимости жёстких дисков.
Менеджеры процессов
AnVir Task Manager
Утилиты работы с реестром
CCleaner
Red Button
Reg Organizer
Утилиты мониторинга оборудования и бенчмарки
SpeedFan
Тесты оборудования
Трансляторы, компиляторы, интерпретаторы
Транслятор — программа или техническое средство, выполняющее трансляцию программы.
Транслятор обычно выполняет также диагностику ошибок, формирует словари идентификаторов, выдаёт для печати тексты программы и т. д.
Трансляция программы — преобразование программы, представленной на одном из языков программирования, в программу на другом языке и, в определённом смысле, равносильную первой.
Язык, на котором представлена входная программа, называется исходным языком, а сама программа — исходным кодом. Выходной язык называется целевым языком или объектным кодом.
Виды трансляторов
Адресный. Функциональное устройство, преобразующее виртуальный адрес (англ. Virtual address) в реальный адрес.
Диалоговый. Обеспечивает использование языка программирования в режиме разделения времени.
Многопроходной. Формирует объектный модуль за несколько просмотров исходной программы.
Обратный. То же, что детранслятор. См. также: декомпилятор, дизассемблер.
Однопроходной. Формирует объектный модуль за один последовательный просмотр исходной программы.
Оптимизирующий. Выполняет оптимизацию кода в создаваемом объектном модуле.
Синтаксически-ориентированный (синтаксически-управляемый). Получает на вход описание синтаксиса и семантики языка и текст на описанном языке, который и транслируется в соответствии с заданным описанием.
Тестовый. Набор макрокоманд языка ассемблера, позволяющих задавать различные отладочные процедуры в программах, составленных на языке ассемблера.
Цель трансляции — преобразовать текст с одного языка на другой, который понятен адресату текста. В случае программ-трансляторов, адресатом является техническое устройство (процессор) или программа-интерпретатор.
Язык процессоров (машинный код) обычно является низкоуровневым. Существуют платформы, использующие в качестве машинного язык высокого уровня (например, iAPX-432), но они являются исключением из правила в силу сложности и дороговизны. Транслятор, который преобразует программы в машинный язык, принимаемый и исполняемый непосредственно процессором, называется компилятором.
Процесс компиляции как правило состоит из нескольких этапов: лексического, синтаксического и семантического анализов (англ. Semantic analysis), генерации промежуточного кода, оптимизации и генерации результирующего машинного кода. Помимо этого, программа как правило зависит от сервисов, предоставляемых операционной системой и сторонними библиотеками (например, файловый ввод-вывод или графический интерфейс), и машинный код программы необходимо связать с этими сервисами. Связывание со статическими библиотеками выполняется редактором связей или компоновщиком (который может представлять из себя отдельную программу или быть частью компилятора), а с операционной системой и динамическими библиотеками связывание выполняется при начале исполнения программы загрузчиком.
Достоинство компилятора: программа компилируется один раз и при каждом выполнении не требуется дополнительных преобразований. Соответственно, не требуется наличие компилятора на целевой машине, для которой компилируется программа. Недостаток: отдельный этап компиляции замедляет написание и отладку и затрудняет исполнение небольших, несложных или разовых программ.
Другой метод реализации — когда программа исполняется с помощью интерпретатора вообще без трансляции. Интерпретатор программно моделирует машину, цикл выборки-исполнения которой работает с командами на языках высокого уровня, а не с машинными командами. Такое программное моделирование создаёт виртуальную машину, реализующую язык. Этот подход называется чистой интерпретацией. Чистая интерпретация применяется как правило для языков с простой структурой (например, АПЛ или Лисп). Интерпретаторы командной строки обрабатывают команды в скриптах в UNIX или в пакетных файлах (.bat) в MS-DOS также как правило в режиме чистой интерпретации.
Достоинство чистого интерпретатора: отсутствие промежуточных действий для трансляции упрощает реализацию интерпретатора и делает его удобнее в использовании, в том числе в диалоговом режиме. Недостаток — интерпретатор должен быть в наличии на целевой машине, где должна исполняться программа.
Существуют компромиссные между компиляцией и чистой интерпретацией варианты реализации языков программирования, когда интерпретатор перед исполнением программы транслирует её на промежуточный язык (например, в байт-код или p-код), более удобный для интерпретации (то есть речь идёт об интерпретаторе со встроенным транслятором). Такой метод называется смешанной реализацией. Примером смешанной реализации языка может служить Perl. Этот подход сочетает как достоинства компилятора и интерпретатора (большая скорость исполнения и удобство использования), так и недостатки (для трансляции и хранения программы на промежуточном языке требуются дополнительные ресурсы; для исполнения программы на целевой машине должен быть представлен интерпретатор). Также, как и в случае компилятора, смешанная реализация требует, чтобы перед исполнением исходный код не содержал ошибок (лексических, синтаксических и семантических).
Трансляция и интерпретация — разные процессы: трансляция занимается переводом программ с одного языка на другой, а интерпретация отвечает за исполнение программ. Однако, поскольку целью трансляции как правило является подготовка программы к интерпретации, то эти процессы обычно рассматриваются вместе. Например, языки программирования часто характеризуются как «компилируемые» или «интерпретируемые», в зависимости от того, преобладает при использовании языка компиляция или интерпретация. Причём практически все языки программирования низкого уровня и третьего поколения, вроде ассемблера, Си или Модулы-2, являются компилируемыми, а более высокоуровневые языки, вроде Python или SQL, — интерпретируемыми.
С другой стороны, существует взаимопроникновение процессов трансляции и интерпретации: интерпретаторы могут быть компилирующими (в том числе с динамической компиляцией), а в трансляторах может требоваться интерпретация для конструкций метапрограммирования (например, для макросов в языке ассемблера, условной компиляции в Си или для шаблонов в C++).
Более того, один и тот же язык программирования может и транслироваться, и интерпретироваться, и в обоих случаях должны присутствовать общие этапы анализа и распознавания конструкций и директив исходного языка. Это относится и к программным реализациям, и к аппаратным — так, процессоры семейства x86 перед исполнением инструкций машинного языка выполняют их декодирование, выделяя в опкодах поля операндов (регистров, адресов памяти, непосредственных значений), разрядности и т. п., а в процессорах Pentium с архитектурой NetBurst машинный код перед сохранением во внутреннем кэше вообще транслируется в последовательность микроопераций.
Отладчики
Отладчик или дебаггер (англ. debugger) является модулем среды разработки или отдельным приложением, предназначенным для поиска ошибок в программе. Отладчик позволяет выполнять пошаговую трассировку, отслеживать, устанавливать или изменять значения переменных в процессе выполнения программы, устанавливать и удалять контрольные точки или условия остановки и т. д.
Обфускаторы
Обфускация (от лат. obfuscare — затенять, затемнять; и англ. obfuscate — делать неочевидным, запутанным, сбивать с толку) или запутывание кода — приведение исходного текста или исполняемого кода программы к виду, сохраняющему ее функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции.
«Запутывание» кода может осуществляться на уровне алгоритма, исходного текста и/или ассемблерного текста. Для создания запутанного ассемблерного текста могут использоваться специализированные компиляторы, использующие неочевидные или недокументированные возможности среды исполнения программы. Существуют также специальные программы, производящие обфускацию, называемые обфускаторами (англ. Obfuscator).
Структура исполняемых файлов в ОС
Исполнимый (исполняемый) модуль, исполнимый файл (англ. executable file) — файл, содержащий программу в виде, в котором она может быть (после загрузки в память и настройки по месту) исполнена компьютером.
Чаще всего он содержит двоичное представление машинных инструкций для определённого процессора (по этой причине на программистском сленге в отношении него используют слово бинарник — кальку с английского binary), но может содержать и инструкции на интерпретируемом языке программирования, для исполнения которых требуется интерпретатор. В отношении последних часто используется термин «скрипт».
Исполнением бинарных файлов занимаются аппаратно- и программно-реализованные машины. К первым относятся процессоры — например, семейств x86 или SPARC. Ко вторым — виртуальные машины, например, виртуальная машина Java или .NET Framework. Формат бинарного файла определяется архитектурой исполняющей его машины. Известны машины, реализованные как аппаратно, так и программно, например, процессоры семейства x86 и виртуальная машина VMware.
Статус исполнимости файла чаще всего определяется принятыми соглашениями. Так, в одних операционных системах исполнимые файлы распознаются благодаря соглашению об именовании файлов (например, путём указания в имени расширения файла — .exe или .bin), тогда как в других исполнимые файлы обладают специфичными метаданными (например, битом разрешения execute в UNIX-подобных операционных системах).
В современных компьютерных архитектурах исполнимые файлы содержат большие объемы данных, не являющихся компьютерной программой: описание программного окружения, в котором программа может быть выполнена, данные для отладки программы, используемые константы, данные, которые могут потребоваться операционной системе для запуска процесса (например, рекомендуемый размер кучи), и даже описания структур окон графической подсистемы, используемых программой.
Зачастую исполнимые файлы содержат вызовы библиотечных функций, например, вызовы функций операционной системы. Таким образом, наряду с процессорозависимостью (машинозависимым является любой бинарный исполнимый файл, содержащий машинный код) исполнимым файлам может быть свойственна зависимость от версии операционной системы и её компонент.
Форматы исполняемых файлов |
|
Windows, DOS и OS/2 |
.COM • .EXE (MZ / NE / LE / LX / PE) |
Unix |
a.out • COFF • ECOFF • ELF • Mach-O • SOM • XCOFF |
Прочие |
Intel HEX • PEF • SREC |
Лекция 9
Структура процессора Intel x86
Системный блок персонального компьютера содержит: блок питания; системную (материнскую) плату; адаптеры внешних устройств; накопители на жестких магнитных (НЖМД) и гибких (НГМД) дисках, а также ряд других устройств. Для нас наибольший интерес представляет системная плата, на которой размещаются постоянное запоминающее устройство ПЗУ (ROM - read only memory), оперативное запоминающее устройство ОЗУ (RAM - random access memory), процессор и логика управления, связанные между собой шинами.
Физически и ОЗУ и ПЗУ выполнены в виде микросхем. Характерным для персонального компьютера является тот факт, что при выключении электропитания содержимое ОЗУ утрачивается (энергозависимая память), а ПЗУ – нет (энергонезависимая память).
Одна из основных задач ПЗУ обеспечить процедуру старта персонального компьютера. В ПЗУ хранятся базовая система ввода/вывода BIOS, а также некоторые служебные программы и таблицы, например, начальный загрузчик, программа тестирования POST и т.п.
Оперативная память ОЗУ предназначена для временного хранения программ и данных, которыми они манипулируют. Логически оперативную память можно представить в виде последовательности ячеек, каждая из которых имеет свой номер, называемый адресом.
Центральный процессор (ЦП) в современных персональных компьютерах выполнен в виде одной сверхбольшой интегральной микросхемы (СБИС). ЦП выполняет машинные команды, выбирая их в заданной последовательности из оперативной памяти. Работа всех электронных устройств компьютера координируется сигналами управления, вырабатываемыми ЦП и некоторыми другими СБИС, сигналами тактового генератора, с помощью которых синхронизируются действия всех сигналов.
Возможности компьютера в большей степени зависят от типа установленного процессора и его тактовой частоты. Семейство процессоров 80х86 корпорации Intel включает в себя микросхемы: 8086, 80186, 80286, 80386, 80486, Pentium, Pentium II, Pentium III и т.д. Совместимые с 80х86 микросхемы выпускают также фирны AMD, IBM, Cyrix. Особенностью этих процессоров является преемственность на уровне машинных команд: программы, написанные для младших моделей процессоров, без каких-либо изменений могут быть выполнены на более старших моделях. При этом базой является система команд процессора 8086, знание которой является необходимой предпосылкой для изучения остальных процессоров.

Структуру центрального процессора Intel 8086 можно разделить на два логических блока (рис.1.1):
блок исполнения (EU:Execution Unit);
блок интерфейса шин (BIU:Bus Interface Unit).
(Интерфейс (interface) - это совокупность средств, обеспечивающих сопряжение устройств и программных модулей как на физическом, так и на логическом уровнях).
В состав EU входят: арифметическо-логическое устройство ALU, устройство управления CU и десять регистров. Устройства блока EU обеспечивают обработку команд, выполнение арифметических и логических операций.
Три части блока BIU - устройство управления шинами, блок очереди команд и регистры сегментов – предназначены для выполнения следующих функций:
управление обменом данными с EU, памятью и внешними устройствами ввода/вывода;
адресация памяти;
выборка команд (осуществляется с помощью блока очереди команд Queue, который позволяет выбирать команды с упреждением).
С точки зрения программиста, процессор 8086 состоит из 8 регистров общего назначения, 4 сегментных регистров, регистра адреса команд (счетчика команд) и регистра флагов. Процессор выставляет на шину адреса адрес выбираемых из памяти команд (или данных), которые поступают в шестибайтный буфер (очередь команд), а затем исполняются.
Адресную шину можно представить в виде 20 проводников, в каждом из которых может либо протекать напряжение заданного уровня (сигнал 1), либо отсутствовать (сигнал 0). Таким образом, микропроцессор оперирует с двоичной системой счисления (двоичной системой представления данных). Символьная информация кодируется в соответствии с кодом ASCII (Американский стандартный код для обмена информацией). Числовые данные кодируются в соответствии с двоичной арифметикой. Отрицательные числа представляются в дополнительном коде.
Минимальная единица информации, соответствующая двоичному разряду, называется бит (Bit). Группа из восьми битов называется байтом (Byte) и представляет собой наименьшую адресуемую единицу – ячейку памяти. Биты в байте нумеруют справа налево цифрами 0...7.
BYTE |
|||||||
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
Двухбайтовое поле образует шестнадцатиразрядное машинное слово (Word), биты в котором нумеруются от 0 до 15 справа налево. Байт с меньшим адресом считается младшим.
WORD |
|||||||||||||||
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
Четырехбайтовое поле образует двойное слово (Double Word), а шестнадцатибайтовое – параграф (Paragraph).
Таким образом, с помощью 16-разрядной шины данных можно передавать числа от 0 (во всех проводниках сигнал 0) до 65535 (во всех проводниках сигнал 1). Несмотря на то, что двоичная система обладает высокой наглядностью, она имеет существенный недостаток – числа, записанные в двоичной системе, слишком громоздки. С другой стороны, привычная для нас десятичная система слишком сложна для перевода чисел в двоичную систему счисления и обратно. Поэтому наибольшее распространение в практике программирования получила шестнадцатеричная система счисления.
При написании программ принято двоичные числа сопровождать латинской буквой B или b, (например, 101B), а шестнадцатеричные – буквой H или h на конце. Если число начинается с буквы, то обязательной является постановка нуля впереди, например, 0BA8H.
Регистры (8, 16, 32, 64 бит)
Процессор 8086 имеет 14 шестнадцатиразрядных регистров, которые используются для управления исполнением команд, адресации и выполнения арифметических операций. Регистр, содержащий одно слово, адресуется по имени.
Регистры общего назначения. К ним относятся 16-разрядные регистры АХ, ВХ, СХ, DX, каждый из которых разделен на 2 части по 8 разрядов:
АХ состоит из АН (старшая часть) и AL (младшая часть);
ВХ состоит из ВH и BL;
СХ состоит из СН и CL;
DX состоит из DH и DL;
В общем случае функция, выполняемая тем или иным регистром, определяется командами, в которых он используется. При этом с каждым регистром связано некоторое стандартное его значение. Ниже перечисляются наиболее характерные функции каждого регистра:
регистр АХ служит для временного хранения данных (регистр аккумулятор); часто используется при выполнении операций сложения, вычитания, сравнения и других арифметических и логических операции;
регистр ВХ служит для хранения адреса некоторой области памяти (базовый регистр), а также используется как вычислительный регистр;
регистр СХ иногда используется для временного хранения данных, но в основном служит счетчиком; в нем хранится число повторений одной команды или фрагмента программы;
регистр DX используется главным образом для временного хранения данных; часто служит средством пересылки данных между разными программными системами, в качестве расширителя аккумулятора для вычислений повышенной точности, а также при умножении и делении.
Регистры для адресации. В микропроцессоре существуют четыре 16-битовых (2 байта или 1 слово) регистра, которые могут принимать участие в адресации операндов. Один из них одновременно является и регистром общего назначения — это регистр ВХ, или базовый регистр. Три другие регистра — это указатель базы ВР, индекс источника SI и индекс результата DI. Отдельные байты этих трех регистров недоступны.
Любой из названных выше 4 регистров может использоваться для хранения адреса памяти, а команды, работающие с данными из памяти, могут обращаться за ними к этим регистрам. При адресации памяти базовые и индексные регистры могут быть использованы в различных комбинациях. Разнообразные способы сочетания в командах этих регистров и других величин называются способами или режимами адресации.
Регистры сегментов. Имеются четыре регистра сегментов, с помощью которых память можно организовать в виде совокупности четырех различных сегментов. Этими регистрами являются:
CS — регистр программного сегмента (сегмента кода) определяет местоположение части памяти, содержащей программу, т. е. выполняемые процессором команды;
DS — регистр информационного сегмента (сегмента данных) идентифицирует часть памяти, предназначенной для хранения данных;
SS — регистр стекового сегмента (сегмента стека) определяет часть памяти, используемой как системный стек;
ES — регистр расширенного сегмента (дополнительного сегмента) указывает дополнительную область памяти, используемую для хранения данных.
Эти 4 различные области памяти могут располагаться практически в любом месте физической машинной памяти. Поскольку местоположение каждого сегмента определяется только содержимым соответствующего регистра сегмента, для реорганизации памяти достаточно всего лишь, изменить это содержимое.
Регистр указателя стека. Указатель стека SP – это 16-битовый регистр, который определяет смещение текущей вершины стека. Указатель стека SP вместе с сегментным регистром стека SS используются микропроцессором для формирования физического адреса стека. Стек всегда растет в направлении меньших адресов памяти, т.е. когда слово помещается в стек, содержимое SP уменьшается на 2, когда слово извлекается из стека, микропроцессор увеличивает содержимое регистра SP на 2.
Регистр указателя команд IP. Регистр указателя команд IP, иначе называемый регистром счетчика команд, имеет размер 16 бит и хранит адрес некоторой ячейки памяти – начало следующей команды. Микропроцессор использует регистр IP совместно с регистром CS для формирования 20-битового физического адреса очередной выполняемой команды, при этом регистр CS задает сегмент выполняемой программы, а IР – смещение от начала сегмента. По мере того, как микропроцессор загружает команду из памяти и выполняет ее, регистр IP увеличивается на число байт в команде. Для непосредственного изменения содержимого регистра IP служат команды перехода.
Регистр флагов. Флаги – это отдельные биты, принимающие значение 0 или 1. Регистр флагов (признаков) содержит девять активных битов (из 16). Каждый бит данного регистра имеет особое значение, некоторые из этих бит содержат код условия, установленный последней выполненной командой. Другие биты показывают текущее состояние микропроцессора.
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
X |
X |
X |
X |
OF |
DF |
IF |
TF |
SF |
ZF |
X |
AF |
X |
PF |
X |
CF |
Биты регистра флагов имеют следующее назначение:
OF (признак переполнения) – равен 1, если возникает арифметическое переполнение, то есть когда объем результата превышает размер ячейки назначения;
DF (признак направления) – устанавливается в 1 для автоматического декремента в командах обработки строк, и в 0 – для инкремента;
IF (признак разрешения прерывания) – прерывания разрешены, если IF=1. Если IF=0, то распознаются лишь немаскированные прерывания;
TF (признаков трассировки) - если TF=1, то процессор переходит в состояние прерывания INT 3 после выполнения каждой команды;
SF (признак знака) – SF=1, когда старший бит результата равен 1. Иными словами, SF=0 для положительных чисел, и SF=1 для отрицательных чисел;
ZF (признак нулевого результата) – ZF=1, если результат равен нулю;
AF (признак дополнительного переноса) – этот флаг устанавливается в 1 во время выполнения команд десятичного сложения и вычитания при возникновении переноса или заема между полубайтами;
PF (признак четности) – этот признак устанавливается в 1, если результат имеет четное число единиц;
CF (признак переноса) – этот флаг устанавливается в 1, если имеет место перенос или заем из старшего бита результата; он полезен для произведения операций над числами длиной в несколько слов, которые сопряжены с переносами и заемами из слова в слово;
X – зарезервированные биты.
Легко заметить, что все флаги младшего байта регистра флагов устанавливаются арифметическими или логическими операциями процессора. За исключением флага переполнения, все флаги старшего байта отражают состояние микропроцессора и влияют на характер выполнения программы. Флаги старшего байта устанавливаются и сбрасываются специально предназначенными для этого командами. Флаги младшего байта являются кодами условного перехода для изменения порядка выполнения программы.
Кеш
Кеш — промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше идёт быстрее, чем выборка исходных данных из оперативной (ОЗУ) и быстрее внешней (жёсткий диск или твердотельный накопитель) памяти, за счёт чего уменьшается среднее время доступа и увеличивается общая производительность компьютерной системы. Прямой доступ к данным, хранящимся в кэше, программным путем невозможен.
 Диаграмма
кэша памяти ЦПУ
Диаграмма
кэша памяти ЦПУ
Кэш — это память с большей скоростью доступа, предназначенная для ускорения обращения к данным, содержащимся постоянно в памяти с меньшей скоростью доступа (далее «основная память»). Кэширование применяется ЦПУ, жёсткими дисками, браузерами, веб-серверами, службами DNS и WINS.
Кэш состоит из набора записей. Каждая запись ассоциирована с элементом данных или блоком данных (небольшой части данных), которая является копией элемента данных в основной памяти. Каждая запись имеет идентификатор, определяющий соответствие между элементами данных в кэше и их копиями в основной памяти.
Когда клиент кэша (ЦПУ, веб-браузер, операционная система) обращается к данным, прежде всего исследуется кэш. Если в кэше найдена запись с идентификатором, совпадающим с идентификатором затребованного элемента данных, то используются элементы данных в кэше. Такой случай называется попаданием кэша. Если в кэше не найдена запись, содержащая затребованный элемент данных, то он читается из основной памяти в кэш, и становится доступным для последующих обращений. Такой случай называется промахом кэша. Процент обращений к кэшу, когда в нём найден результат, называется уровнем попаданий или коэффициентом попаданий в кэш.
Если кэш ограничен в объёме, то при промахе может быть принято решение отбросить некоторую запись для освобождения пространства. Для выбора отбрасываемой записи используются разные алгоритмы вытеснения.
При модификации элементов данных в кэше выполняется их обновление в основной памяти. Задержка во времени между модификацией данных в кэше и обновлением основной памяти управляется так называемой политикой записи.
В кэше с немедленной записью каждое изменение вызывает синхронное обновление данных в основной памяти.
В кэше с отложенной записью (или обратной записью) обновление происходит в случае вытеснения элемента данных, периодически или по запросу клиента. Для отслеживания модифицированных элементов данных записи кэша хранят признак модификации (изменённый или «грязный»). Промах в кэше с отложенной записью может потребовать два обращения к основной памяти: первое для записи заменяемых данных из кэша, второе для чтения необходимого элемента данных.
В случае, если данные в основной памяти могут быть изменены независимо от кэша, то запись кэша может стать неактуальной. Протоколы взаимодействия между кэшами, которые сохраняют согласованность данных, называют протоколами когерентности кэша.
Уровни кэша
Кэш центрального процессора разделён на несколько уровней. В универсальном процессоре в настоящее время число уровней может достигать 3. Кэш-память уровня N+1 как правило больше по размеру и медленнее по скорости доступа и передаче данных, чем кэш-память уровня N.
Самой быстрой памятью является кэш первого уровня — L1-cache. По сути, она является неотъемлемой частью процессора, поскольку расположена на одном с ним кристалле и входит в состав функциональных блоков. В современных процессорах обычно кэш L1 разделен на два кэша, кэш команд (инструкций) и кэш данных (Гарвардская архитектура). Большинство процессоров без L1 кэша не могут функционировать. L1 кэш работает на частоте процессора, и, в общем случае, обращение к нему может производиться каждый такт. Зачастую является возможным выполнять несколько операций чтения/записи одновременно. Латентность доступа обычно равна 2−4 тактам ядра. Объём обычно невелик — не более 128 Кбайт.
Вторым по быстродействию является L2-cache — кэш второго уровня, обычно он расположен на кристалле, как и L1. В старых процессорах — набор микросхем на системной плате. Объём L2 кэша от 128 Кбайт до 1−12 Мбайт. В современных многоядерных процессорах кэш второго уровня, находясь на том же кристалле, является памятью раздельного пользования — при общем объёме кэша в nM Мбайт на каждое ядро приходится по nM/nC Мбайта, где nC количество ядер процессора. Обычно латентность L2 кэша, расположенного на кристалле ядра, составляет от 8 до 20 тактов ядра.
Кэш третьего уровня наименее быстродействующий, но он может быть очень внушительного размера — более 24 Мбайт. L3 кэш медленнее предыдущих кэшей, но всё равно значительно быстрее, чем оперативная память. В многопроцессорных системах находится в общем пользовании и предназначен для синхронизации данных различных L2.
Иногда существует и 4 уровень кэша, обыкновенно он расположен в отдельной микросхеме. Применение кэша 4 уровня оправдано только для высоко производительных серверов и мейнфреймов.
Проблема синхронизации между различными кэшами (как одного, так и множества процессоров) решается когерентностью кэша. Существует три варианта обмена информацией между кэш-памятью различных уровней, или, как говорят, кэш-архитектуры: инклюзивная, эксклюзивная и неэксклюзивная.
Инклюзивная архитектура предполагает дублирование информации кэша верхнего уровня в нижнем (предпочитает фирма Intel).
Эксклюзивная кэш-память предполагает уникальность информации, находящейся в различных уровнях кэша (предпочитает фирма AMD).
В неэксклюзивной кэши могут вести себя как угодно.
Ассемблер
Существует несколько версий программы ассемблер. Одним из наиболее часто используемых является пакет Turbo Assembler, водящий в состав комплекса программ Borland Pascal 7.0. Рассмотрим работу с этим пакетом более подробно.
Входной информацией для ассемблера (TASM.EXE) является исходный файл — текст программы на языке ассемблера в кодах ASCII. В результате работы ассемблера может получиться до 3-х выходных файлов:
объектный файл – представляет собой вариант исходной программы, записанный в машинных командах;
листинговый файл – является текстовым файлом в кодах ASCII, включающим как исходную информацию, так и результат работы программы ассемблера;
файл перекрестных ссылок – содержит информацию об использовании символов и меток в ассемблерной программе (перед использованием этого файла необходима его обработка программой CREF).
Существует много способов указывать ассемблеру имена файлов. Первый и самый простой способ — это вызов команды без аргументов. В этом случае ассемблер сам поочередно запрашивает имена файлов: входной (достаточно ввести имя файла без расширения ASM), объектный, листинговый и файл перекрестных ссылок. Для всех запросов имеются режимы, применяемые по умолчанию, если в ответ на запрос нажать клавишу Enter:
объектному файлу ассемблер присваивает то же имя, что и у исходного, но с расширением OBJ;
для листингового файла и файла перекрестных ссылок принимается значение NUL — специальный тип файла, в котором все, что записывается, недоступно и не может быть восстановлено.
Если ассемблер во время ассемблирования обнаруживает ошибки, он записывает сообщения о них в листинговый файл. Кроме того, он выводит их на экран дисплея.
Другой способ указать ассемблеру имена файлов — это задать их прямо в командной строке через запятую при вызове соответствующей программы, например:
TASM Test, Otest, Ltest, Ctest
При этом первым задается имя исходного файла, затем объектного, листингового и, наконец, файла перекрестных ссылок. Если какое-либо имя пропущено, то это служит указанием ассемблеру сгенерировать соответствующий файл по стандартному соглашению об именах.
Программа, полученная в результате ассемблирования (объектный файл), еще не готова к выполнению. Ее необходимо обработать командой редактирования связей TLINK, которая может связать несколько различных объектных модулей в одну программу и на основе объектного модуля формирует исполняемый загрузочный модуль.
Входной информацией для программы TLINK являются имена объектных модулей (файлы указываются без расширение OBJ). Если файлов больше одного, то их имена вводятся через разделитель «+». Модули связываются в том же порядке, в каком их имена передаются программе TLINK. Кроме того, TLINK требует указания имени выходного исполняемого модуля. По умолчанию ему присваивается имя первого из объектных модулей, но с расширением ЕХЕ. Вводя другое имя, можно изменять имя файла, но не расширение. Далее можно указать имя файла, для хранения карты связей (по умолчанию формирование карты не производится). Последнее, что указывается программе TLINK – это библиотеки программ, которые могут быть включены в полученный при связывании модуль. По умолчанию такие библиотеки отсутствуют.
Информацию обо всех этих файлах программа TLINK запрашивает у пользователя после ее вызова.
Графически процесс создания программы на языке Ассемблера можно представить как это показано на рис 3.1.

Все ассемблерные программы состоят из одного или более предложений и комментариев. Предложение и комментарии представляют собой комбинацию знаков, входящих в алфавит языка, а также чисел и идентификаторов, которые тоже формируются из знаков алфавита. Алфавит языка составляют цифры, строчные и прописные буквы латинского алфавита, а также следующие символы:
? @ _ $ : . [ ] ( ) < > { } + / * & % ! ' ~ | \ = # ^ ; , ` "
Конструкции языка ассемблера формируются из идентификаторов и ограничителей. Идентификатор представляет собой набор букв, цифр и символов «_», «.», «?», «$» или «@» (символ «.» может быть только первым символом идентификатора), не начинающийся с цифры. Идентификатор должен полностью размещаться на одной строке и может содержать от 1 до 31 символа (точнее, значимым является только первый 31 символ идентификатора, остальные игнорируются). Друг от друга идентификаторы отделяются пробелом или ограничителем, которым считается любой недопустимый в идентификаторе символ. Посредством идентификаторов представляются следующие объекты программы:
переменные;
метки;
имена.
Переменные идентифицируют хранящиеся в памяти данные. Все переменные имеют три атрибута:
СЕГМЕНТ, соответствующий тому сегменту, который ассемблировался, когда была определена переменная;
СМЕЩЕНИЕ, являющееся смещением данного поля памяти относительно начала сегмента;
ТИП, определяющий число байтов, подвергающихся манипуляциям при работе с переменной.
Метка является частным случаем переменной, когда известно, что определяемая ею память содержит машинный код. На нее можно ссылаться посредством переходов или вызовов. Метка имеет два атрибута: СЕГМЕНТ и СМЕЩЕНИЕ.
Именами считаются символы, определенные директивой EQU и имеющие значением символ или число. Значения имен не фиксированы в процессе ассемблирования, но при выполнении программы именам соответствуют константы.
Некоторые идентификаторы, называемые ключевыми словами, имеют фиксированный смысл и должны употребляться только в соответствии с этим. Ключевыми словами являются:
директивы ассемблера;
инструкции процессора;
имена регистров;
операторы выражений.
В идентификаторах одноименные строчные и заглавные буквы считаются эквивалентными. Например, идентификаторы AbS и abS считаются совпадающими.
Ниже описаны типы и формы представления данных, которые могут быть использованы в выражениях, директивах и инструкциях языка ассемблера.
Целые числа имеют следующий синтаксис (xxxx – цифры):
[+|-]xxxx
[+|-]xxxxB
[+|-]xxxxQ
[+|-]xxxxO
[+|-]xxxxD
[+|-]xxxxH
Латинский символ (в конце числа), который может кодироваться на обоих регистрах, задает основание системы счисления числа: B – двоичное, Q и O – восьмеричное, D – десятичное, H – шестнадцатеричное. Шестнадцатеричные числа не должны начинаться с буквенных цифр (например, вместо некорректного ABh следует употреблять 0ABh). Шестнадцатеричные цифры от A до F могут кодироваться на обоих регистрах. Первая форма целого числа использует умалчиваемое основание (обычно десятичное).
Символьные и строковые константы имеют следующий синтаксис:
'символы'
"символы"
Символьная константа состоит из одного символа алфавита языка. Строковая константа включает в себя 2 или более символа. В отличие от других компонент языка, строковые константы чувствительны к регистру. Символы «'» и «"» в теле константы должны кодироваться дважды.
Кроме целых и символьных типов ассемблер содержит еще ряд типов (например, вещественные числа, двоично-десятичные числа), однако их рассмотрение выходит за рамки данного пособия.
Лекция 10 Структура программ ассемблера
Исходный программный модуль – это последовательность предложений. Различают два типа предложений: инструкции процессора и директивы ассемблера. Инструкции управляют работой процессора, а директивы указывают ассемблеру и редактору связей, каким образом следует объединять, инструкции для создания модуля, который и станет работающей программой.
Инструкция процессора на языке ассемблера состоит не более чем из четырех поле и имеет следующий формат:
[[метка:]] мнемоника [[операнды]] [[;комментарии]]
Единственное обязательное поле – поле кода операции (мнемоника), определяющее инструкцию, которую должен выполнить микропроцессор. Поле операндов определяется кодом операции и содержит дополнительную информацию о команде. Каждому коду операции соответствует определенное число операндов. Метка служит для обозначения какого-то определенного места в памяти, т. е. содержит в символическом виде адрес, по которому храниться инструкция. Преобразование символических имен в действительные адреса осуществляется программой ассемблера. Часть строки исходного текста после символа «;» (если он не является элементом знаковой константы или строки знаков) считается комментарием и ассемблером игнорируется. Комментарии вносятся в программу как поясняющий текст и могут содержать любые знаки до ближайшего символа конца строки. Для создания комментариев, занимающих несколько строк, может быть использована директива COMMENT. Пример:
Метка |
Код операции |
Операнды |
;Комментарий |
MET: |
MOVE |
AX, BX |
;Пересылка |
Предложения
Как было указано выше, исходный программный модуль – это последовательность предложений, каждое из которых записывается в отдельной строке:
<Предложение>
<Предложение>
...
<Предложение>
Предложения определяют структуру и функции программы, они могут начинаться с любой позиции и содержать не более 128 символов. При записи предложений действуют следующие правила расстановки пробелов:
пробел обязателен между рядом стоящими идентификаторами и/или числами (чтобы отделить их друг от друга);
внутри идентификаторов и чисел пробелы недопустимы;
в остальных местах пробелы можно ставить или не ставить;
там, где допустим один пробел, можно ставить любое число пробелов.
Все предложения языка ассемблера делятся на директивы ассемблера и инструкции (команды) процессора.
Директивы ассемблера действуют лишь в период компиляции программы и позволяют устанавливать режимы компиляции, задавать структуру сегментации программы, определять содержимое полей данных, управлять печатью листинга программы, а также обеспечивают условную компиляцию и некоторые другие функции. В результате обработки директив компилятором объектный код не генерируется.
Инструкции процессора представляют собой мнемоническую форму записи машинных команд, непосредственно выполняемых микропроцессором. Все инструкции в соответствии с выполняемыми ими функциями делятся на 5 групп:
инструкции пересылки данных;
арифметические, логические и операции сдвига;
операции со строками;
инструкции передачи управления;
инструкции управления процессором.
Выражения
В языке ассемблера выражения могут быть использованы в инструкциях или директивах и состоят из операндов и операторов.
Операнды представляют значения, регистры или адреса ячеек памяти, используемых определенным образом по контексту программы.
Операторы выполняют арифметические, логические, побитовые и другие операции над операндами выражений.
Ниже даны описания наиболее часто используемых в выражениях операторов.
Арифметические операторы.
выражение_1 |
* |
выражение_2 |
выражение_1 |
/ |
выражение_2 |
выражение_1 |
MOD |
выражение_2 |
выражение_1 |
+ |
выражение_2 |
выражение_1 |
- |
выражение_2 |
|
+ |
выражение |
|
- |
выражение |
Эти операторы обеспечивают выполнение основных арифметических действий (здесь MOD - остаток от деления выражения_1 на выражение_2, а знаком / обозначается деление нацело). Результатом арифметического оператора является абсолютное значение.
Операторы сдвига.
выражение |
SHR |
счетчик |
выражение |
SHL |
счетчик |
Операторы SHR и SHL сдвигают значение выражения соответственно вправо и влево на число разрядов, определяемое счетчиком. Биты, выдвигаемые за пределы выражения, теряются. Замечание: не следует путать операторы SHR и SHL с одноименными инструкциями процессора.
Операторы отношений.
выражение_1 |
EQ |
выражение_2 |
выражение_1 |
NE |
выражение_2 |
выражение_1 |
LT |
выражение_2 |
выражение_1 |
LE |
выражение_2 |
выражение_1 |
GT |
выражение_2 |
выражение_1 |
GE |
выражение_2 |
Мнемонические коды отношений расшифровываются следующим образом:
EQ – равно;
NE – не равно;
LT – меньше;
LE – меньше или равно;
GT – больше;
GE – больше или равно.
Операторы отношений формируют значение 0FFFFh при выполнении условия и 0000h в противном случае. Выражения должны иметь абсолютные значения. Операторы отношений обычно используются в директивах условного ассемблирования и инструкциях условного перехода.
Операции с битами.
|
NOT |
выражение |
выражение_1 |
AND |
выражение_2 |
выражение_1 |
OR |
выражение_2 |
выражение_1 |
XOR |
выражение_2 |
Мнемоники операций расшифровываются следующим образом:
NOT – инверсия;
AND – логическое И;
OR – логическое ИЛИ;
XOR – исключающее логическое ИЛИ.
Операции выполняются над каждыми соответствующими битами выражений. Выражения должны иметь абсолютные значения.
Оператор индекса.
[[выражение_1]] [выражение_2]
Оператор индекса [] складывает указанные выражения подобно тому, как это делает оператор +, с той разницей, что первое выражение необязательно, при его отсутствии предполагается 0 (двойные квадратные скобки указывают на то, что операнд не обязателен).
Оператор PTR
тип PTR выражение
При помощи оператора PTR переменная или метка, задаваемая выражением, может трактоваться как переменная или метка указанного типа. Тип может быть задан одним из следующих имен или значений:
Таблица 1. Типы оператора PTR |
|
Имя типа |
Значение |
BYTE |
1 |
WORD |
2 |
DWORD |
4 |
QWORD |
8 |
TBYTE |
10 |
NEAR |
0FFFFh |
FAR |
0FFFEh |
Оператор PTR обычно используется для точного определения размера, или расстояния, ссылки. Если PTR не используется, ассемблер подразумевает умалчиваемый тип ссылки. Кроме того, оператор PTR используется для организации доступа к объекту, который при другом способе вызвал бы генерацию сообщения об ошибке (например, для доступа к старшему байту переменной размера WORD).
Операторы HIGH и LOW
HIGH |
выражение |
LOW |
выражение |
Операторы HIGH и LOW вычисляют соответственно старшие и младшие 8 битов значения выражения. Выражение может иметь любое значение.
Оператор SEG
SEG выражение
Этот оператор вычисляет значение атрибута СЕГМЕНТ выражения. Выражение может быть меткой, переменной, именем сегмента, именем группы или другим символом.
Оператор OFFSET
OFFSET выражение
Этот оператор вычисляет значение атрибута СМЕЩЕНИЕ выражения. Выражение может быть меткой, переменной, именем сегмента или другим символом. Для имени сегмента вычисляется смещение от начала этого сегмента до последнего сгенерированного в этом сегменте байта.
Оператор SIZE
SIZE переменная
Оператор SIZE определяет число байтов памяти, выделенных переменной.
Приоритеты операций
При вычислении значения выражения операции выполняются в соответствии со следующим списком приоритетов (в порядке убывания):
LENGTH, SIZE, WIDTH, MASK, (), [], <>.
Оператор имени поля структуры (.).
Оператор переключения сегмента (:).
PTR, OFFSET, SEG, TYPE, THIS.
HIGH, LOW.
Унарные + и -.
*, /, MOD, SHR, SHL.
Бинарные + и -.
EQ, NE, LT, LE, GT, GE.
NOT.
AND.
OR, XOR.
SHORT, .TYPE.
(Некоторые операции не были рассмотрены выше ввиду довольно редкого их использования)
Ссылки вперед
Хотя ассемблер и допускает ссылки вперед (т.е. к еще необъявленным объектам программы), такие ссылки могут при неправильном использовании приводить к ошибкам. Пример ссылки вперед:
JMP MET
...
MET: ...
Всякий раз, когда ассемблер обнаруживает неопределенное имя на 1-м проходе, он предполагает, что это ссылка вперед. Если указано только имя, ассемблер делает предположения о его типе и используемом регистре сегмента, в соответствии с которыми и генерируется код. В приведенном выше примере предполагается, что MET – метка типа NEAR и для ее адресации используется регистр CS, в результате чего генерируется инструкция JMP, занимающая 3 байта. Если бы, скажем, в действительности тип ссылки оказался FAR, ассемблеру нужно было бы генерировать 5-байтовую инструкцию, что уже невозможно, и формировалось бы сообщение об ошибке. Во избежание подобных ситуаций рекомендуется придерживаться следующих правил:
Если ссылка вперед является переменной, вычисляемой относительно регистров ES, SS или CS, следует использовать оператор переключения сегмента. Если он не использован, делается попытка вычисления адреса относительно регистра DS.
Если ссылка вперед является меткой инструкции в команде JMP и отстоит не далее, чем на 128 байтов, можно использовать оператор SHORT. Если этого не делать, метке будет присвоен тип FAR, что не вызовет ошибки, но на 2-м проходе ассемблер для сокращения размера содержащей ссылку инструкции вынужден будет вставить дополнительную и ненужную инструкцию NOP.
Если ссылка вперед является меткой инструкции в командах CALL или JMP, следует использовать оператор PTR для определения типа метки. Иначе ассемблер устанавливает тип NEAR, и, если в действительности тип метки окажется FAR, будет выдано сообщение об ошибке.
Директивы определения данных
Директивы определения данных служат для задания размеров, содержимого и местоположения полей данный, используемых в программе на языке ассемблера.
Директивы определения данных могут задавать:
скалярные данные, представляющие собой единичное значение или набор единичных значений;
записи, позволяющие манипулировать с данными на уровне бит;
структуры, отражающие некоторую логическую структуру данных.
Скалярные данные
Директивы определения скалярных данных приведены в таблице.
Таблица 2. Директивы определения скалярных данных. |
|
Формат |
Функция |
[[имя]] DB значение,... |
определение байтов |
[[имя]] DW значение,... |
определение слов |
[[имя]] DD значение,... |
определение двойных слов |
[[имя]] DQ значение,... |
определение квадрослов |
[[имя]] DT значение,... |
определение 10 байтов |
Директива DB обеспечивает распределение и инициализацию 1 байта памяти для каждого из указанных значений. В качестве значения может кодироваться целое число, строковая константа, оператор DUP (см. ниже), абсолютное выражение или знак «?». Знак «?» обозначает неопределенное значение. Значения, если их несколько, должны разделяться запятыми. Если директива имеет имя, создается переменная типа BYTE с соответствующим данному значению указателя позиции смещением.
Если в одной директиве определения памяти заданы несколько значений, им распределяются последовательные байты памяти. В этом случае, имя, указанное в начале директивы, именует только первый из этих байтов, остальные остаются безымянными. Для ссылок на них используется выражение вида имя+k, где k – целое число.
Строковая константа может содержать столько символов, сколько помещается на одной строке. Символы строки хранятся в памяти в порядке их следования, т.е. 1-й символ имеет самый младший адрес, последний - самый старший.
Во всех директивах определения памяти в качестве одного из значений может быть задан оператор DUP. Он имеет следующий формат:
счетчик DUP (значение,...)
Указанный в скобках список значений повторяется многократно в соответствии со значением счетчика. Каждое значение в скобках может быть любым выражением, имеющим значением целое число, символьную константу или другой оператор DUP (допускается до 17 уровней вложенности операторов DUP). Значения, если их несколько, должны разделяться запятыми.
Оператор DUP может использоваться не только при определении памяти, но и в других директивах.
Синтаксис директив DW, DD, DQ и DT идентичен синтаксису директивы DB.
Примеры директив определения скалярных данных:
integer1 |
DB |
16 |
string1 |
DB |
'abCDf' |
empty1 |
DB |
? |
contan2 |
DW |
4*3 |
string3 |
DD |
'ab' |
high4 |
DQ |
18446744073709551615 |
high5 |
DT |
1208925819614629174706175d |
db6 |
DB |
5 DUP(5 DUP(5 DUP(10))) |
dw6 |
DW |
DUP(1,2,3,4,5) |
Лекция 10
Директивы
Структура директивы аналогична структуре инструкции. Второе поле – код псевдооперации определяет смысловое содержание директивы. Как и у инструкции, у директивы есть операнды, причем их может быть один или несколько и они отделяются друг от друга запятыми. Допустимое число операндов в директиве определяется кодом псевдооперации. Пример:
ARRAY B 0, 0, 0, 0, 0
END START
Директива может быть помечена символическим именем и содержать поле комментария. Символическое имя, стоящее в начале директивы распределения памяти, называется переменной. В отличие от метки команды после символического имени директивы двоеточие не ставиться. Комментарий записывается также как и в случае команды и может занимать целую строку.
Программа на языке ассемблера состоит из программных модулей, содержащихся в различных файлах. Каждый модуль, в свою очередь, состоит из инструкций процессора или директив ассемблера и заканчивается директивой END. Метка, стоящая после кода псевдооперации END, определяет адрес, с которого должно начаться выполнение программы и называется точкой входа в программу.
Каждый модуль также разбивается на отдельные части директивами сегментации, определяющими начало и конец сегмента. Каждый сегмент начинается директивой начала сегмента – SEGMENT и заканчивается директивой конца сегмента – ENDS. В начале директив ставится имя сегмента. Оператор SEGMENT может указывать выравнивание сегмента в памяти, способ, которым он объединяется с другими сегментами, а также имя класса. Существует два типа выравнивания сегмента: тип PARA, когда сегмент будет расположен начиная с границы параграфа, и тип BYTE, когда сегмент расположен начиная с любого адреса. Различные виды взаимной связи сегментов определяют параметры сборки, например, при модульном программировании. Объявление PUBLIC вызывает объединение всех сегментов с одним и тем же именем в виде одного большого сегмента. Объявление AT с адресным выражением располагает сегмент по заданному абсолютному адресу.
Каждый сегмент может быть также разбит на части. В общем случае информационные сегменты SS, ES и DS состоят из определений данных, а программный сегмент CS – из инструкций и директив, группирующих инструкции в блоки. Программный сегмент может разбиваться на части директивами определения процедур – некоторых выделенных блоков программы. Как и для определения сегмента, имеются две директивы определения процедуры (подпрограммы) – директива начала PROC и директива конца ENDP. Процедура имеет имя, которое должно включаться в обе директивы. В сегменте процедуры могут располагаться последовательно одна за другой или могут быть вложенными одна в другую.
Директива EQU
Константы в языке Ассемблера описываются с помощью директивы эквивалентности EQU, имеющей следующий синтаксис:
<имя> EQU <операнд>
Здесь обязательно должно быть указано имя и только один операнд. Директивой EQU автор программы заявляет, что указанному операнду он дает указанное имя, и требует, чтобы все вхождения этого имени в текст программы ассемблер заменял на этот операнд. Директиву EQU можно ставить в любое место программы.
Директива ASSUME
С помощью директивы ASSUME ассемблеру сообщается информация о соответствии между сегментными регистрами, и программными сегментами. Директива имеет следующий формат:
ASSUME <пара>[[, <пара>]]
ASSUME NOTHING
где <пара> - это <сегментный регистр> :<имя сегмента>
либо <сегментный регистр> :NOTHING
Например, директива
ASSUME ES:A, DS:B, CS:C
сообщает ассемблеру, что для сегментирования адресов из сегмента А выбирается регистр ES, для адресов из сегмента В – регистр DS, а для адресов из сегмента С – регистр CS.
Таким образом, директива ASSUME дает право не указывать в командах (по крайней мере, в большинстве из них) префиксы – опущенные префиксы будет самостоятельно восстанавливать ассемблер.
В качестве особенностей директивы прежде всего следует отметить, что директива ASSUME не загружает в сегментные регистры начальные адреса сегментов. Этой директивой автор программы лишь сообщает, что в программе будет сделана такая, загрузка. Директиву ASSUME можно размешать в любом месте программы, но обычно ее указывают в начале сегмента команд, так как информация из нее нужна только при трансляции инструкций. При этом в директиве обязательно должно быть указано соответствие между регистром CS и данным сегментом кода, иначе при появлении первой же метки ассемблер зафиксирует ошибку.
Если в директиве ASSUME указано несколько пар с одним и тем же сегментным регистром, то последняя из них «отменяет» предыдущие, т. к. каждому сегментному регистру, можно поставить в соответствие только один сегмент. В то же время на один и тот же сегмент могут указывать разные сегментные регистры. Если в директиве ASSUME в качестве второго элемента пары задано служебное слово NOTHING (ничего), например, ASSUME ES: NOTHING, то это означает, что с данного момента сегментный регистр не указывает ни на какой сегмент, что ассемблер не должен использовать этот регистр при трансляции команд.
В связи с тем, что директивой ASSUME автор программы лишь сообщает, что все имена из таких-то программных сегментов должны сегментироваться по таким-то сегментным регистрам (в начале выполнения программы в этих регистрах ничего нет), то выполнение программы необходимо начинать с команд, которые загружают в сегментные регистры адреса соответствующих сегментов памяти.
Загрузка производится следующим образом. Пусть регистр DS необходимо установить на начало сегмента В. Для загрузки регистра необходимо выполнить присваивание вида DS:=B. Однако сделать это командой MOV DS,B нельзя, поскольку имя сегмента – это константное выражение, т. е. непосредственный операнд, а по команде MOV запрещена пересылка непосредственного операнда в сегментный регистр (см. ниже). Поэтому такую пересылку следует делать через другой, несегментный регистр, например, через АХ:
MOV АХ,В
MOV DS,AX ;DS:=B
Аналогичным образом загружается и регистр ES.
Регистра CS загружать нет необходимости, так как к началу выполнения программы этот регистр уже будет указывать, на начало сегмента кода. Такую загрузку выполняет операционная система, прежде чем передает управление программе.
Загрузить регистр SS можно двояко. Во-первых, его можно загрузить в самой программе так же, как DS или ES. Во-вторых, такую загрузку можно поручить операционной системе. Для этого в директиве SEGMENT, открывающей описание сегмента стека, надо указать специальный параметр STACK, например:
S SEGMENT STACK
...
S ENDS
В таком случае загрузка S в регистр SS будет выполнена автоматически до начала выполнения программы.
Директива INCLUDE
Встречая директиву INCLUDE, ассемблер весь текст, хранящийся в указанном файле, подставит в программу вместо этой директивы. В общем случае обращение к директиве INCLUDE (включить) имеет следующий вид:
INCLUDE <имя файла>
Директиву INCLUDE можно указывать любое число раз и в любых местах программы. В ней можно указать любой файл, причем название файла записывается по правилам операционной системы.
Директива полезна, когда в разных программах используется один и тот же фрагмент текста; чтобы не выписывать этот фрагмент в каждой программе заново, его записывают в какой-то файл, а затем подключают к программам с помощью данной директивы.
Команды
Команды пересылки
Команда MOV
Команда MOV – основная команда пересылки данных, которая пересылает один байт или слово данных из памяти в регистр, из регистра в память или из регистра в регистр. Команда MOV может также занести число (непосредственный операнд) в регистр или память. На приведенном ниже рисунке представлены различные способы, которыми в микропроцессоре можно пересылать данные из одного места в другое. Каждый прямоугольник означает здесь регистр или ячейку памяти. Стрелки показывают пути пересылки данных, которые допускает микропроцессор. Необходимо также помнить, что все команды микропроцессора могут указывать только один операнд памяти.

Примеры использования команды пересылки:
MOV Data,DI
MOV BX,CX
MOV DI,Index
MOV Start_Seg,DS
MOV ES,Buffer
MOV Days,356
MOV DI,0
Команда обмена данных XCHG
Команда XCHG меняет местами содержимое двух операндов. Порядок следования операндов не имеет значения. В качестве операндов могут выступать регистры (кроме сегментных) и ячейки памяти.
Примеры использования команды XCHG:
XCHG BL,BH
XCHG DH,Char
XCHG AX,BX
Команды загрузки полного указателя LDS и LES
Эти команды загружают полный указатель из памяти и записывают его в выбранную пару «сегментный регистр : регистр». При этом первое слово из адресуемой памяти загружается в регистр первого операнда, второе в регистр DS, если выполняется команда LDS, или в регистр ES если выполняется команда LES.
Примеры использования команд:
LDS BX,[BP+4]
LES DI,TablePtr
Команда перекодировки XLAT
Команда XLAT заменяет содержимое регистра AL байтом из таблицы перекодировки (максимальная длинна – 256 байт), начальный адрес которой относительно сегмента DS находится в регистре BX.
XLAT всегда использует в качестве смещения начала таблицы содержимое регистра BX, поэтому перед выполнением команды необходимо поместить в BX смещение таблицы.
Пример использования команды XLAT:
MOV BX,OFFSET Talbe
MOV AL,2
XLAT
...
Table DB ‘abcde’
Команды арифметического сложения ADD и ADC
Команда ADD выполнят целочисленное сложение двух операндов, представленных в двоичном коде. Результат помещается на место первого операнда, второй операнд не изменяется. Команда корректирует регистр флагов в соответствии с результатом сложения. Существуют две формы сложения: 8-битовое и 16-битовое. В различных формах сложения принимают участие различные регистры. Компилятор следит за тем, чтобы операнды соответствовали друг другу. На следующих рисунках иллюстрируются различные варианты команды ADD.
|
|
Команда сложения с переносом ADC – это та же команда ADD, за исключением того, что в сумму включается флаг переноса CF, который прибавляется к младшему биту результата. Для любой формы команды ADD существует аналогичная ей команда ADC. Команда ADC часто выполняется как часть многобайтной или многословной операции сложения.
Примеры использования команд ADD и ADC:
ADD AL,12h
ADD Count,1
ADC BX,4
ADD AX,BX
ADC Count,DI
Команды арифметического вычитания SUB и SBB
Команда вычитания SUB – идентична команде сложения, за исключением того, что она выполняет вычитание, а не сложение. Для нее верны предыдущие схемы, если в них поменять знак «+» на «–», т. е. она из первого операнда вычитает второй и помещает результат на место первого операнда. Команда вычитания также устанавливает флаги состояния в соответствии с результатом операции (флаг переноса здесь трактуется как заем). Команда вычитания с заемом SBB учитывает флаг заема CF, то есть значение заема вычитается из младшего бита результата.
Примеры использования команд SUB и SBB:
SUB AL,12h
SUB Count,1
SBB BX,4
SUB AX,BX
SBB Count,DI
Команда смены знака NEG
Команда отрицания NEG – оператор смены знака. Она меняет знак двоичного кода операнда – байта или слова.
Команды инкремента INC и декремента DEC
Команды инкремента и декремента изменяют значение своего единственного операнда на единицу. Команда INC прибавляет 1 к операнду, а команда DEC вычитает 1 из операнда. Обе команды могут работать с байтами или со словами. На флаги команды влияния не оказывают.
Команды умножения MUL и IMUL
Существуют две формы команды умножения. По команде MUL умножаются два целых числа без знака, при этом результат тоже не имеет знака. По команде IMUL умножаются целые числа со знаком. Обе команды работают с байтами и со словами, но для этих команд диапазон форм представления гораздо уже, чем для команд сложения и вычитания. На приведенных ниже рисунках представлены все варианты команд умножения.


При умножении 8-битовых операндов результат всегда помещается в регистр AX. При умножении 16-битовых данных результат, который может быть длиною до 32 бит, помещается в пару регистров: в регистре DX содержатся старшие 16-бит, а в регистре AX – младшие 16-бит. Умножение не допускает непосредственного операнда.
Установка флагов командой умножения отличается от других арифметических команд. Единственно имеющие смысл флаги – это флаг переноса и переполнения.
Команда MUL устанавливает оба флага, если старшая половина результата не нулевая. Если умножаются два байта, установка флагов переполнения и переноса показывает, что результат умножения больше 255 и не может содержаться в одном байте. В случае умножения слов флаги устанавливаются, если результат больше 65535.
Команда IMUL устанавливает флаги по тому же принципу, т. е. если произведение не может быть представлено в младшей половине результата, но только в том случае если старшая часть результата не является расширением знака младшей. Это означает, что если результат положителен, флаг устанавливается как в случае команды MUL. Если результат отрицателен, то флаги устанавливаются в случае, если не все биты кроме старшего, равны 1. Например, умножение байт с отрицательным результатом устанавливает флаги, если результат меньше 128.
Примеры использования команд умножения:
MUL CX
IMUL Width
Команды деления DIV и IDIV
Как и в случае умножения, существуют две формы деления – одна для двоичных чисел без знака DIV, а вторая для чисел со знаком – IDIV. Любая форма деления может работать с байтами и словами. Один из операндов (делимое) всегда в два раза длиннее обычного операнда. Ниже приведены схемы, иллюстрирующие команды деления.
Байтовая команда делит 16-битовое делимое на 8-битовый делитель. В результате деления получается два числа: частное помещается в регистр AL, а остаток – в AH. Команда, работающая со словами, делит 32-битовое делимое на 16-битовый делитель. Делимое находится в паре регистров DX:AX, причем регистр DX содержит старшую значимую часть, а регистр AX – младшую. Команда деления помещает частное в регистр AX, а остаток в DX.
Ни один из флагов состояния не определен после команды деления. Однако, если частное больше того, что может быть помещено в регистр результата (255 для байтового деления и 65535 для деления слов), возникает ошибка значимости и выполняется программное прерывание уровня 0.
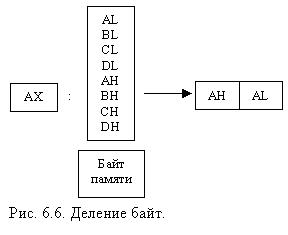
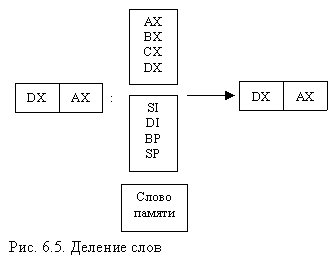
Примеры использования команд деления:
IDIV CX
DIV Count
Команды, выполняющие логические операции
К командам, выполняющим логические операции, относятся AND, OR и XOR. Указанные команды выполняют соответственно операции «логическое умножение» (конъюнкцию), «логическое сложение» (дизъюнкцию) и «исключающее или» для двух операндов и помещают результат на место первого операнда. К группе логических команд также относится команда TEST, которая производит те же действия, что и команда AND, но не изменяет своих операндов, а лишь устанавливает соответствующие флаги.
В качестве операндов логических команд могут выступать те же операнды, что и у команд сложения и вычитания.
Примеры использования логических команд:
AND BL,100
TEST CX,DX
OR DX,Mask
XOR Flag,1000b
Команды, выполняющие операции сдвигов
Команды сдвига перемещает все биты в поле данных либо вправо, либо влево, работая либо с байтами, либо со словами. Каждая команда содержит два операнда: первый операнд – поле данных – может быть либо регистром, либо ячейкой памяти; второй операнд – счетчик сдвигов. Его значение может быть равным 1, или быть произвольным. В последнем случае это значение необходимо занести в регистр CL, который указывается в команде сдвига. Число в CL может быть в пределах 0-255, но его практически имеющие смысл значения лежат в пределах 0-16.
Общая черта всех команд сдвига – установка флага переноса.
Ниже приведен перечень команд сдвига:
команды логического сдвига вправо SHR и влево SHL;
команды арифметического сдвига вправо SAR и влево SAL;
команды циклического сдвига вправо ROR и влево ROL;
команды циклического сдвига вправо RCR и влево RCL с переносом;
Действие команд сдвига иллюстрируют следующие рисунки.








Примеры использования команд сдвига:
SHL CH,1
SHL [BP],CL
RCL Size,1
Компиляция, компоновка, отладка
На рис.1 приведена общая схема процесса разработки программы на ассемблере. Название программы соответствует рассмотренному ранее примеру программы. На схеме выделено четыре этапа этого процесса. На первом этапе, когда вводится код программы, можно использовать любой текстовый редактор. В Windows таким редактором может быть Блокнот (Notepad). При выборе редактора нужно учитывать, что он не должен вставлять «посторонних» символов (специальных символов форматирования). С этой точки зрения Microsoft Word в качестве основного редактора ассемблерных программ не годится. Очень интересный редактор — Asm Editor for Windows. Созданный с помощью текстового редактора файл должен иметь расширение .asm.
 Рис.
1. Схема процесса разработки программы
на ассемблере
Рис.
1. Схема процесса разработки программы
на ассемблере
Для выполнения остальных этапов разработки требуются специализированные программные средства из пакета MASM или TASM. В ходе настоящего обсуждения будут описываться средства обоих пакетов, но в основном на примере TASM, поскольку процесс разработки ассемблерных Программ с использованием этого пакета более нагляден. В принципе, все пакеты ассемблера выполняют практически одну работу, но по-разному, например, маскируют ее с помощью интегрированный среды или объединяют некоторые этапы разработки. Поняв суть преобразований исходной программы, выполняемых пакетом TASM, освоить другие пакеты ассемблера будет на порядок легче.
Компиляция
Компилятор — Программа, предназначенная для трансляции высокоуровневого языка в абсолютный код или, иногда, в язык ассемблера. Входной информацией для компилятора (исходный код) является описание алгоритма или программа на проблемно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).
Компиляция — трансляция программы, составленной на исходном языке, и последующая её компоновка в программу на некоем машинонезависимом низкоуровневом интерпретируемом коде (как например в случае языка Java).
Любой компилятор состоит из транслятора и компоновщика. Часто в качестве компоновщика компилятор использует внешний компоновщик, реализованный в виде самостоятельной программы, а сам выполняет лишь трансляцию исходного текста (по этой причине многие ошибочно считают компилятором разновидность транслятора). Компилятор может быть реализован и как своеобразная программа-менеджер, для трансляции программы вызвающая сооствествующий транслятор (трансляторы - если разные части программы написаны на разных языках программирования) и затем - для компоновки программы, - вызывающая компоновщик. Ярким примером такого компилятора является имеющаяся во всех UNIX-системах (и Linux-системах в том числе) утилита make (имеются реализации утилиты make и в других системах, в частности в Windows-системах).
Процесс компиляции состоит из следующих фаз:
Лексический анализ. На этой фазе последовательность символов исходного файла преобразуется в последовательность лексем.
Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в древо разбора.
Семантический анализ. Древо разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их определениям, типам данным, проверка совместимости типов данных, определение результирующих типов данных выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным древом разбора, новым древом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
Оптимизация. Удаляются избыточные команды и упрощается (где это возможно) код с сохранением его смысла, т. е. реализуемого им алгоритма (в том числе предвычисляются (т. е. вычисляются на фазе трансляции) выражения, результаты которых практически являются константами). Оптимизация может быть на разных уровнях и этапах — например, над промежуточным кодом или над конечным машинным кодом.
Генерация кода. Из промежуточного представления порождается код на целевом языке (в том числе выполняется компоновка программы).
Кодовое представление команд
Команда микропроцессора — это команда, которая выполняет требуемое действие над данными или изменяет внутреннее состояние процессора.
Существует две основные архитектуры процессоров. Первая называется RISC (Reduced Instruction Set Computer) — компьютер с уменьшенным набором команд. Архитектура RISC названа в честь первого компьютера с уменьшенным набором команд — RISC I. Идея этой архитектуры основывается на том, что процессор большую часть времени тратит на выполнение ограниченного числа инструкций (например, переходов или команд присваивания), а остальные команды используются редко.
Разработчики RISC-архитектуры создали «облегченный» процессор. Благодаря упрошенной внутренней логике (меньшему числу команд, менее сложным логическим контурам), значительно сократилось время выполнения отдельных команд и увеличилась общая производительность. Архитектура RISC подобна «архитектуре общения» с собакой — она знает всего несколько команд, но выполняет их очень быстро.
Вторая архитектура имеет сложную систему команд, она называется CISC (Complex Instruction Set Computer) — компьютер со сложной системой команд. Архитектура CISC подразумевает использование сложных инструкций, которые можно разделить на более простые. Все х86-совместимые процессоры принадлежат к архитектуре CISC.
Давайте рассмотрим команду «загрузить число 0x1234 в регистр АХ». На языке ассемблера она записывается очень просто — MOV АХ, 0x1234. К настоящему моменту вы уже знаете, что каждая команда представляется в виде двоичного числа (пункт 7 концепции фон Неймана). Ее числовое представление называется машинным кодом. Команда MOV АХ, 0x1234 на машинном языке может быть записана так:
0x11хх: предыдущая команда
0х1111:0хВ8, 0x34, 0x12
0x1114: следующие команды
Мы поместили команду по адресу 0x1111. Следующая команда начинается тремя байтами дальше, значит, под команду с операндами отведено 3 байта. Второй и третий байты содержат операнды команды MOV. А что такое 0хВ8? После преобразования 0хВ8 в двоичную систему мы получим значение 10111000b.
Первая часть — 1011 — и есть код команды MOV. Встретив код 1011, контроллер «понимает», что перед ним — именно MOV. Следующий разряд (1) означает, что операнды будут 16-разрядными. Три последние цифры определяют регистр назначения. Три нуля соответствуют регистру АХ (или AL, если предыдущий бит был равен О, указывая таким образом, что операнды будут 8-разрядными).
Чтобы декодировать команды, контроллер должен сначала прочитать их из памяти. Предположим, что процессор только что закончил выполнять предшествующую команду, и IP (указатель команд) содержит значение 0x1111. Прежде чем приступить к обработке следующей команды, процессор «посмотрит » на шину управления, чтобы проверить, требуются ли аппаратные прерывания.
Если запроса на прерывание не поступало, то процессор загружает значение, сохраненное по адресу 0x1111 (в нашем случае — это 0хВ8), в свой внутренний (командный) регистр. Он декодирует это значение так, как показано выше, и «понимает», что нужно загрузить в регистр АХ 16-разрядное число —- два следующих байта, находящиеся по адресам 0x1112 и 0x1113 (они содержат наше число, 0x1234). Теперь процессор должен получить из памяти эти два байта. Для этого процессор посылает соответствующие команды в шину и ожидает возвращения по шине данных значения из памяти.
Получив эти два байта, процессор запишет их в регистр АХ. Затем процессор увеличит значение в регистре IP на 3 (наша команда занимает 3 байта), снова проверит наличие запросов на прерывание и, если таких нет, загрузит один байт по адресу 0x1114 и продолжит выполнять программу.
Если запрос на прерывание поступил, процессор проверит его тип, а также значение флага IF. Если флаг сброшен (0), процессор проигнорирует прерывание; если же флаг установлен (1), то процессор сохранит текущий контекст и начнет выполнять первую инструкцию обработчика прерывания, загрузив ее из таблицы векторов прерываний.
К счастью, нам не придется записывать команды в машинном коде, поскольку ассемблер разрешает использовать их символические имена.
Лекция 11
Адресация памяти
Мы уже знаем, что адрес, как и сама команда, — это число. Чтобы не запоминать адреса всех «переменных», используемых в программе, этим адресам присваивают символические обозначения, которые называются переменными (иногда их также называют указателями).
При использовании косвенного операнда адрес в памяти, по которому находится нужное значение, записывается в квадратных скобках: [адрес]. Если мы используем указатель, то есть символическое представление адреса, например, [ESI], то в листинге машинного кода мы увидим, что указатель был заменен реальным значением адреса. Можно также указать точный адрес памяти, например, [0x594F].
Чаще всего мы будем адресовать память по значению адреса, занесенному в регистр процессора. Чтобы записать такой косвенный операнд, нужно просто написать имя регистра в квадратных скобках. Например, если адрес загружен в регистр ESI, вы можете получить данные, расположенные по этому адресу, используя выражение [ESI].
Теперь рассмотрим фрагмент программы, в которой регистр ESI содержит адрес первого элемента (нумерация начинается с 0) в массиве байтов. Как получить доступ, например, ко второму элементу (элементу, адрес которого на 1 байт больше) массива? Процессор поддерживает сложные способы адресации, которые очень нам пригодятся в дальнейшем. В нашем случае, чтобы получить доступ ко второму элементу массива, нужно записать косвенный операнд [ESI + 1].
Имеются даже более сложные типы адресации: [адрес + ЕВХ + 4]. В этом случае процессор складывает адрес, значение 4 и значение, содержащееся в регистре ЕВХ. Результат этого выражения называется эффективным адресом (ЕА, Effective Address) и используется в качестве адреса, по которому фактически находится операнд (мы пока не рассматриваем сегментные регистры). При вычислении эффективного адреса процессор 80386 также позволяет умножать один член выражения на константу, являющуюся степенью двойки: [адрес + ЕВХ * 4]. Корректным считается даже следующее «сумасшедшее» выражение:
[число - б + ЕВХ * 8 + ESI]
На практике мы будем довольствоваться только одним регистром [ESI] или суммой регистра и константы, например, [ESI + 4]. В зависимости от режима процессора, мы можем использовать любой 16-разрядный или 32-разрядный регистр общего назначения [ЕАХ], [ЕВХ],... [ЕВР].
Процессор предыдущего поколения 80286 позволял записывать адрес в виде суммы содержимого регистра и константы только для регистров ВР, SI, DI, и ВХ.
В адресации памяти участвуют сегментные регистры. Их функция зависит от режима процессора. Каждый способ адресации предполагает, что при вычислении реального (фактического) адреса используется сегментный регистр по умолчанию. Сменить регистр по умолчанию можно так:
ES:[ESI]
Некоторые ассемблеры требуют указания регистра внутри скобок:
[ES:ESI]
В наших примерах мы будем считать, что все сегментные регистры содержат одно и то же значение, поэтому мы не будем использовать их при адресации.
Команды АЛУ
Арифметико-логическое устройство (АЛУ) (англ. arithmetic and logic unit, ALU) — блок процессора, который под управлением устройства управления (УУ) служит для выполнения арифметических и логических преобразований (начиная от элементарных) над данными, представляемыми в виде машинных слов, называемыми в этом случае операндами.
Арифметическо-логическое устройство в зависимости от выполнения функций можно разделить на две части: микропрограммное устройство (устройство управления), задающее последовательность микрокоманд (команд); операционное устройство (АЛУ), в котором реализуется заданная последовательность микрокоманд (команд).
Функции регистров, входящих в арифметическо-логическое устройство
Рг1 — сумматор (или сумматоры) — главный регистр АЛУ, в котором образуется результат вычислений;
Рг2,Рг3 — регистры операндов (слагаемого/сомножителя/делителя/делимого и др.) в зависимости от выполняемой операции;
Рг4 — регистр адреса (или адресные регистры), предназначенные для запоминания (бывает что формирования) адреса операндов результата;
Рг6 — k индексных регистров, содержимое которых используется для формирования адресов;
Рг7 — l вспомогательных регистров, которые по желанию программиста могут быть аккумуляторами, индексными регистрами или использоваться для запоминания промежуточных результатов.
Все выполняемые в АЛУ операции являются логическими операциями (функциями), которые можно разделить на следующие группы:
операции двоичной арифметики для чисел с фиксированной точкой;
операции двоичной (или шестнадцатеричной) арифметики для чисел с плавающей точкой;
операции десятичной арифметики;
операции индексной арифметики (при модификации адресов команд);
операции специальной арифметики;
операции над логическими кодами (логические операции);
операции над алфавитно-цифровыми полями.
Команды этой группы выполняют АЛУ операции между младшими полусловами регистров. Примечание: все команды этой группы влияют на флаги регистра CPSR.
OP |
THUMB ассемблер |
ARM эквивалент |
Действия |
0000 |
AND Rd, Rs |
ANDS Rd, Rd, Rs |
Rd:= Rd AND Rs |
0001 |
EOR Rd, Rs |
EORS Rd, Rd, Rs |
Rd:= Rd EOR Rs |
0010 |
LSL Rd, Rs |
MOVS Rd, Rd, LSL Rs |
Rd := Rd << Rs |
0011 |
LSR Rd, Rs |
MOVS Rd, Rd, LSR Rs |
Rd := Rd >> Rs |
0100 |
ASR Rd, Rs |
MOVS Rd, Rd, ASR Rs |
Rd := Rd ASR Rs |
0101 |
ADC Rd, Rs |
ADCS Rd, Rd, Rs |
Rd := Rd + Rs + Carry |
0110 |
SBC Rd, Rs |
SBCS Rd, Rd, Rs |
Rd := Rd - Rs - NOT Carry |
0111 |
ROR Rd, Rs |
MOVS Rd, Rd, ROR Rs |
Rd := Rd ROR Rs |
1000 |
TST Rd, Rs |
TST Rd, Rs |
Установить флаги регистра CPSR для Rd AND Rs |
1001 |
NEG Rd, Rs |
RSBS Rd, Rs, #0 |
Rd = -Rs |
1010 |
CMP Rd, Rs |
CMP Rd, Rs |
Установить флаги регистра CPSR для Rd - Rs |
1011 |
CMN Rd, Rs |
CMN Rd, Rs |
Установить флаги регистра CPSR для Rd + Rs |
1100 |
ORR Rd, Rs |
ORRS Rd, Rd, Rs |
Rd := Rd OR Rs |
1101 |
MUL Rd, Rs |
MULS Rd, Rs, Rd |
Rd := Rs * Rd |
1110 |
BIC Rd, Rs |
BICS Rd, Rd, Rs |
Rd := Rd AND NOT Rs |
1111 |
MVN Rd, Rs |
MVNS Rd, Rs |
Rd := NOT Rs |
Все команды этого формата эквивалентны командам в режиме ARM согласно таблице 15. Число машинных тактов выполнения этих команд в режиме THUMB идентично с числом тактов выполнения ее в режиме ARM.
Примеры
EOR R3, R4 |
; R3 := R3 EOR R4 и установить флаги условий. |
ROR R1, R0 |
; Сдвиг R1 вправо на число бит, указанное в R0, |
|
; результат поместить в R1 и установить флаги условий. |
NEG R5, R3 |
; Вычесть содержимое R3 из нуля, разместить результат в регистре R5 |
|
; и установить флаги условий. Т.е. R5 = -R3. |
CMP R2, R6 |
; Установить флаги условий в зависимости от результата R2 - R6. |
MUL R0, R7 |
; R0 := R7 * R0 и установить флаги условий. |
Базирование и косвенные адреса
Правило использования косвенной адресации:
если 1-ый операнд содержит косвенный адрес, то 2-ой операнд ссылается на регистр или непосредственное значение;
если 2-ой операнд содержит косвенный адрес, то 1-ый операнд ссылается на регистр.
Существует 2 варианта косвенной адресации ячеек ОП:
косвенная обычная, когда исполнительных адрес находится в регистре, например:
MOV AX, [BX].
Исполнительный адрес операнда может находиться в базовом регистре BX, регистре указателя базы BP или индексном регистре SI или DI. Косвенный регистровый операнд заключается в квадратные скобки, что означает "в качестве адреса брать содержимое того адреса, на который указывает заключенный в квадратные скобки регистр". Чтобы адрес-смещение переменной мог оказаться в РОН, используется команда пересылки следующего вида:
MOV BX, offset SOURCE.
Функции этой команды заключаются в том, что смещение (offset) ячейки памяти с именем SOURCE помещается в РОН ВХ. Естественно, в программе эта команда должна предшествовать команде пересылки с косвенной адресацией.
Т.к. содержимое регистра легко изменить в ходе выполнения программы, данный способ адресации позволяет динамически назначить адрес операнда для некоторой машинной команды. Это свойство применяется для организации циклических вычислений и для работы со структурами данных типа таблиц и массивов.
Так, командами
MOV BX, offset SOURCE
M1: MOV AX, [BX]
INC BX
INC BX
возвращаясь в цикле на метку М1 можно организовать последовательную пересылку в регистр АХ всех элементов массива SOURCE.
Еще пример. Пусть в сегменте данных описан вектор TABL DB 12,15,16,10,8,2,5,0.
Ниже первая команда загружает адрес вектора TABL в базовый регистр ВХ, а следующая команда заменяет первый байт в векторе на нулевое значение:
MOV BX,OFFSET TABL
MOV BYTE PTR [BX],0
после выполнения этих программных инструкций содержимое вектора будет: TABL DB 0,15,16,10,8,2,5,0.
косвенная с индексированием - адресация от предыдущей отличается тем, что исполнительный адрес берется в виде суммы адресов, находящихся в базовом и индексном регистрах:
MOV AX, [BX+SII].
Смешанная непосредственная адресация ячеек памяти имеет несколько вариантов:
непосредственная обычная:
MOV AX, offset pole.
Здесь в качестве непосредственного операнда берется смещение адреса переменной pole;
непосредственная с индексированием, когда в качестве исполнительного адреса операнда берется сумма значений индексного регистра и непосредственного смещения:
MOV AX, [SI+const],
причем смещение, обозначенное const, может быть задано числом, идентификатором константы, смещением адреса переменной (offset), или их комбинацией в виде простого выражения;
непосредственная с базированием, в которой, в отличие от предыдущей адресации, фигурирует базовый, а не индексный регистр:
MOV AX, [BX+const].
Форма записи смещения относительно базы может быть любой из 3-ех нижеприведенных:
MOV AX, [BX]+4 ,
MOV AX, 4[BX] ,
MOV AX, [BX+4].
Это примечание относится и к форме записи команд с индексированием (предыдущий вид адресации);
непосредственная с базированием и индексированием отличается тем, что для вычисления исполнительного адреса берется сумма базового и индексного регистра, к которым добавляется непосредственно фигурирующее в команде смещение:
MOV AX, pole[BX+SI+const].
Адресация с базированием и индексированием очень полезна при работе с двумерными массивами и таблицами. В ней исполнительный адрес вычисляется как сумма значений базового регистра, индексного регистра и (возможно) сдвига. В случае двумерного массива базовый адрес может содержать начальный адрес массива, а значения сдвига и индексного регистра могут содержать смещения по строке и столбцу. Допустимыми форматами команд являются следующие записи:
MOV AX, [BX+2+DI],
MOV AX, [DI+BX+2]
MOV AX, [BX+2][DI]
MOV AX, [BX+2+DI]
MOV AX, [BX][DI+2]
MOV AX, NUMBER [BP][SI].
Команды пересылки данных
При написании программ на ассемблере производится интенсивная работа с адресами операндов, находящимися в памяти. Для поддержки такого рода операций есть специальная группа команд, в которую входят следующие команды.
<приемник>,<источник> — загрузка эффективного адреса;
<приемник>,<источник> — загрузка указателя в регистр сегмента данных ds;
<приемник>,<источник> — загрузка указателя в регистр дополнительного сегмента данных es;
<приемник>,<источник> — загрузка указателя в регистр дополнительного сегмента данных gs;
<приемник>,<источник> — загрузка указателя в регистр дополнительного сегмента данных fs;
<приемник>,<источник> — загрузка указателя в регистр сегмента стека ss.
Команда LEA похожа на команду MOV тем, что она также производит пересылку, однако команда LEA производит пересылку не данных, а эффективного адреса данных (то есть смещения данных относительно начала сегмента данных) в регистр, указанный операндом <приемник>.
Часто для выполнения некоторых действий в программе недостаточно знать значение одного лишь эффективного адреса данных, а необходимо иметь полный указатель на данные. Вы помните, что полный указатель на данные состоит из сегментной составляющей и смещения. Все остальные команды этой группы позволяют получить в паре регистров такой полный указатель на операнд в памяти. При этом имя сегментного регистра, в который помещается сегментная составляющая адреса, определяется кодом операции. Соответственно, смещение помещается в регистр общего назначения, указанный операндом <приемник>. Но не все так просто с операндом <источник>. На самом деле в команде в качестве источника нельзя указывать непосредственно имя операнда в памяти, на который мы бы хотели получить указатель. Предварительно необходимо получить само значение полного указателя в некоторой области памяти и задать в команде получения полного адреса имя этой области. Для выполнения этого действия необходимо вспомнить директивы резервирования и инициализации памяти. При применении этих директив возможен частный случай, когда в поле операндов указывается имя другой директивы определения данных (фактически, имя переменной). В этом случае в памяти формируется адрес этой переменной. Какой адрес будет сформирован (эффективный или полный), зависит от применяемой директивы. Если это DW, то в памяти формируется только 16-разрядное значение эффективного адреса, если же DD — в память записывается полный адрес. Размещение этого адреса в памяти следующее: в младшем слове находится смещение, в старшем— 16-разрядная сегментная составляющая адреса.
Лекция 12
Регистр флагов
Состояние регистра флагов влияет на выполнение команд микропроцессором. Сейчас мы рассмотрим структуру регистра флагов. Регистр флагов состоит из 16 бит.
 Рис.
1. Регистр, флагов микропроцессоров
8086/8088.
Рис.
1. Регистр, флагов микропроцессоров
8086/8088.
Из 16 бит семь зарезервированы, остальные выполняют различные функции, которые мы сейчас разберем.
CF - флаг переноса. Равен 1, если произошел перенос при сложении или заем при вычитании, в противном случае он равен нулю. При выполнении операции сдвига CF содержит бит, который вышел за границу ячейки или регистра. CF также служит индикатором результата умножения.
PF - флаг четности. Равен 1, если в результате операции получилось число с четным числом единиц, и 0 - в противном случае.
AF - вспомогательный флаг переноса. Аналогичен флагу CF, но контролирует заем или перенос третьего бита.
ZF - флаг нуля. Равен 1, если в результате операции получен нуль, и 0 - в противоположном случае.
SF - флаг знака. Дублирует значение старшего бита результата операции. Используется при работе с числами со знаком.
TF - флаг трассировки. Если этот бит равен 1, то после выполнения каждой операции микропроцессор обращается к специальной процедуре (прерыванию). Используется при отладке программы.
IF - флаг прерывания. Если данный флаг сброшен в 0, то микропроцессор не реагирует ни на какие внешние сигналы (сигналы прерывания). Исключение составляет немаскируемое прерывание (NMI). По линии NMI микропроцессор получает сообщения о таких критических ситуациях, как отключение питания и ошибка памяти.
DF - флаг направления. Используется строковыми (цепочечными) командами. Если он сброшен, цепочка обрабатывается с первого элемента, имеющего наименьший адрес. В противном случае цепочка обрабатывается от наибольшего адреса к наименьшему.
OF - флаг переполнения. Флаг равен 1, если результат сложения двух чисел с одинаковым знаком или результат вычитания двух чисел с противоположными знаками выйдет за пределы допустимого диапазона. Флаг обращается в 1, если старший бит операнда изменился в результате операции арифметического сдвига. OF=0, если частное от деления двух чисел переполняет результирующий регистр.
Выполнив команды PUSHF и POP AX, вы сможете проверить любой из вышеперечисленных флагов, даже если он никак не воздействует на команды условных переходов. Аналогично (PUSH AX/POPF) можно изменить любой флаг по своему усмотрению. Кстати, раз мы здесь говорим о регистре флагов, следует упомянуть один подход, который позволяет различать микропроцессоры Intel. Одна модификация микропроцессора может отличаться от предыдущей версии тем, что в ней появляется новый флаг. Это значит, что мы можем его изменить, а следовательно, отличить один микропроцессор от другого.
|