

Лабораторна робота № 1 Технології формування вибірки
Мета роботи: освоєння найпоширеніших технологій формування основних типів вибірок із використанням пакета MS Excel.
Теорія: Підручник, розділ 3.1 (с. 111-123).
Завдання:
1. Виконати приклади 3.1 і 3.2 Підручника (с. 112, 115).
2. Для генеральної сукупності осіб жіночої і чоловічої статі (табл. 11.1) отримати дві рандомізовані вибірки: просту обсягом 12 осіб і стратифіковану по статі обсягом 15 осіб. Зробити висновки.
Таблиця 11.1
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
ч |
ж |
ч |
ч |
ж |
ж |
ж |
ж |
ч |
ж |
ч |
ч |
ж |
ж |
ч |
ч |
ч |
ч |
ж |
ч |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
ч |
ч |
ч |
ж |
ж |
ч |
ж |
ч |
ж |
ч |
ч |
ж |
ж |
ж |
ж |
ж |
ж |
ч |
ч |
ч |
3.1. Технології формування вибірки
Основним стратегіям формування вибірок (розділ 2.2.5.) відповідають певні математичні методи. Існує декілька технологій формування репрезентативних вибірок за принципом рівноймовірнісного відбору, серед яких найпоширенішими вважаються прості й систематичні рандомізовані вибірки, стратифіковані (розшаровані) і кластерні вибірки. Розглянемо методики формування цих вибірок докладніше.
3.1.1. Проста рандомізована вибірка
Для формування простої рандомізованої вибірки необхідно мати список усіх об'єктів (екземплярів) генеральної сукупності (або всієї популяції) і систему відбору, яка б гарантувала для кожного об'єкта популяції рівну ймовірність попадання його у вибірку. У цьому варіанті ми маємо три групи:
усю генеральну сукупність;
групу рандомізації, з якої проводиться відбір;
експериментальну рандомізовану вибірку.
На практиці способом випадкового відбору формують будь-яку групу випробовуваних, потім вимірюють у них значущу для експерименту індивідуальну властивість. Після цього випробовуваних рівноймовірнісним способом розподіляють по групах.
В основу технологій рандомізації покладено процес генерації послідовності псевдовипадкових чисел. В Excel така послідовність (таблиця) чисел може бути отримана за допомогою:
функції =СЛЧИС()1, яка розраховує дійсні рівномірно розподілені випадкові числа в інтервалі (0;1),
функції =СЛУЧМЕЖДУ(), що генерує дискретні цілочисельні значення за рівномірним розподілом у заданому інтервалі;
пакета «Аналіз даних», до складу якого входять розділи «Генерація випадкових чисел» і «Вибірка».
Указані способи базуються на однакових математичних процедурах, дають схожі результати і не мають суттєвих переваг. Розглянемо формування простої рандомізованої вибірки з використанням функції, яка найбільше підходить, – =СЛУЧМЕЖДУ().
Приклад 3.1. Необхідно отримати просту рандомізовану вибірку обсягом n=10 з популяції обсягом N=30 (обмеженість обсягів n і N вибрана лише з метою зручності й наочності викладання, проте N може сягати сотень і навіть тисяч).
Послідовність рішення
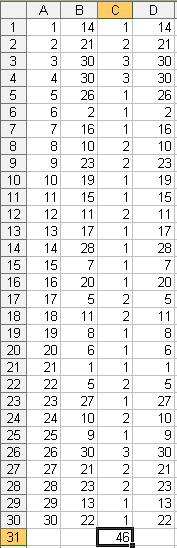
У комірки А1:А30 (рис. 3.1) заносимо послідовний список з N об'єктів популяції у вигляді індексів – чисел від 1 до 30.
|
|
|
Рис. 3.1. |
Рис. 3.2. |
Рис. 3.3. |
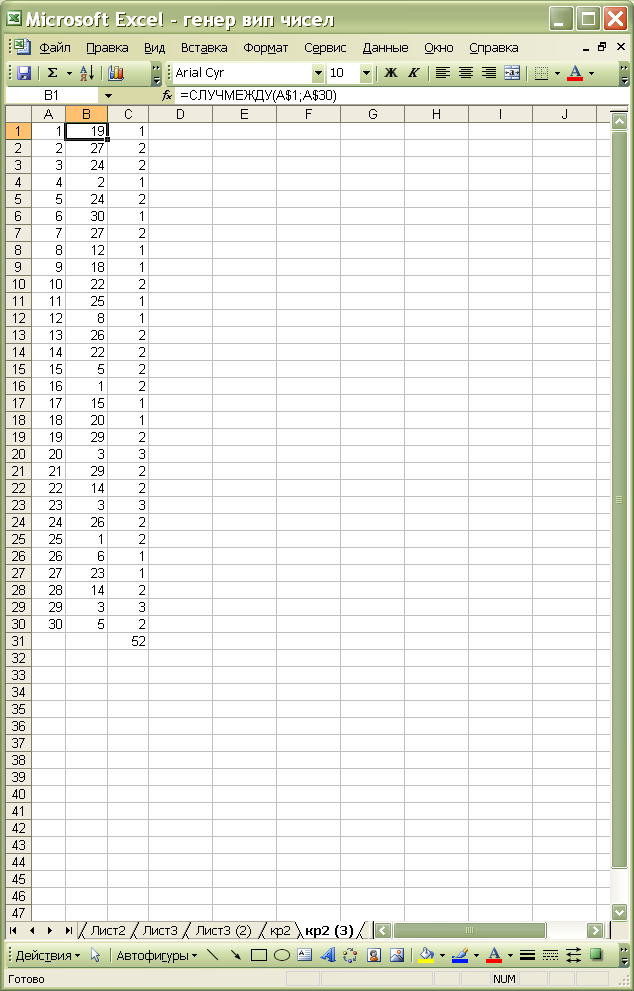
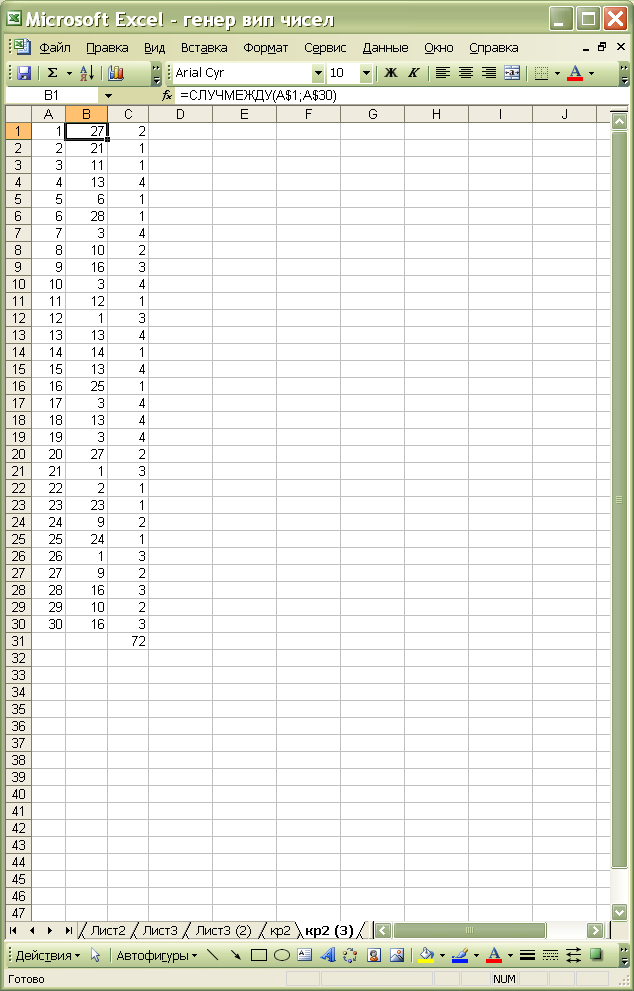
Для генерації дискретних цілочисельних значень за рівномірним розподілом в інтервалі від 1 до 30 у комірки В1:В30 заносимо функцію =СЛУЧМЕЖДУ(A$1;A$30), а в комірки С1:С30 – функції), =СЧЁТЕСЛИ(B$1:B$30;B1 що підраховують кількість повторень кожного випадкового числа.
У результаті у стовпчику В отримаємо 30 випадкових значень індексів, з яких необхідно узяти перші 10, що не повторюються. Якщо запланована вибірка мала за обсягом, вибір індексів можна здійснити «вручну». У нашому прикладі вони будуть: 19, 27, 24, 2, 30, 12, 18, 22, 25, 8 (рис 3.1). Якщо запланована вибірка потенційних осіб значна за обсягом, щоб уникнути помилок, пов'язаних із повторенням індексів, пропонується продовжити цю роботу в такій послідовності.
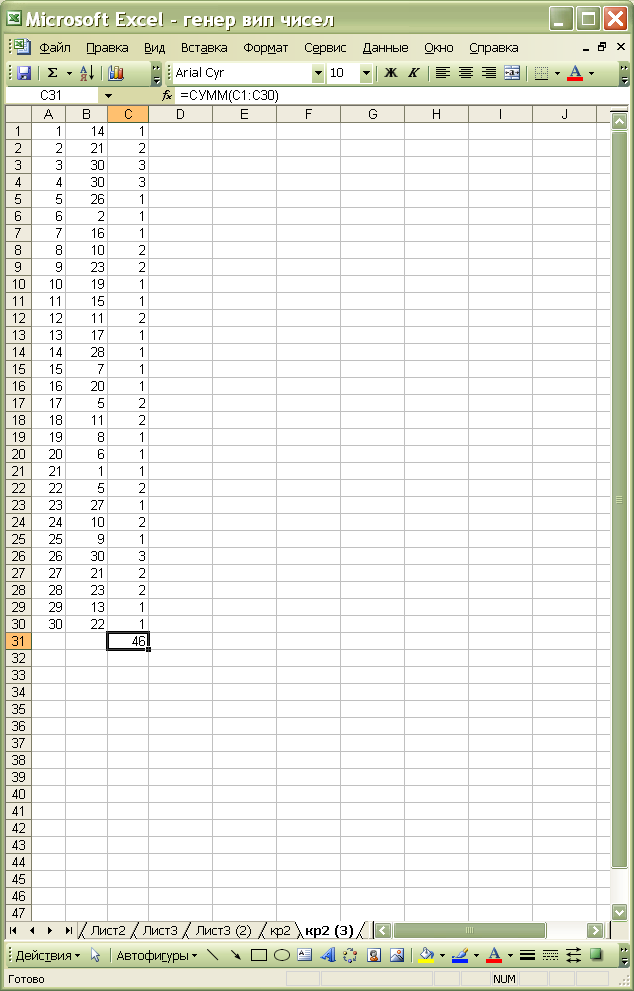
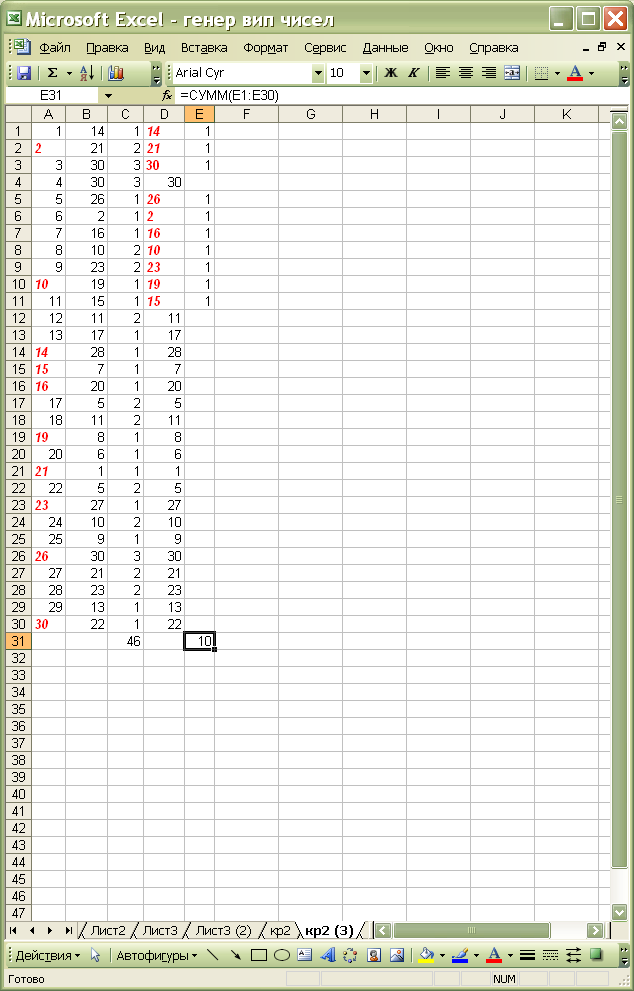
У комірку С31 заносимо формулу =СУММ(C1:C30) для того, щоб оцінити загальну кількість повторень.
Натискуючи на клавіатурі клавішу F9, ми можемо в Excel повторювати генерацію в комірках B1:B30 нової послідовності випадкових індексів (див. рис. 3.1 – 3.3). Процес рекомендуємо припинити, коли в комірці С31 значення суми повторень буде мінімальним. У прикладі ми зупинилися на варіанті суми, що дорівнює 46, і це нас влаштовує (рис. 3.3 ).
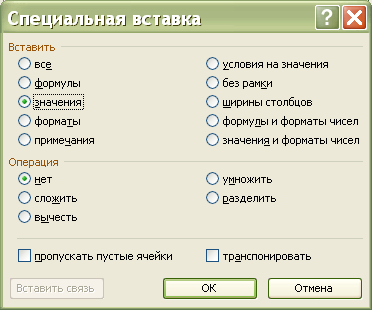
Для того, щоб зафіксувати саме цю випадкову послідовність індексів, вміст комірок В1:В30 бажано cкопіювати у якесь інше місце електронної таблиці, наприклад, у комірки D1:D30. Копіювання виконати в режимі «Спеціальна вставка» (рис. 3.4).
|
Рис. 3.4. Копіювання значень у режимі «Спеціальна вставка» |
У результаті отримаємо випадкову послідовність індексів для формування вибірки (рис. 3.5). Щоб уникнути помилок, рекомендуємо фіксування індексів у стовпчиках А і D супроводжувати засобами текстового редагування: колір або стиль літер – курсив, підкреслення, вирівнювання тощо (рис. 3.6 і 3.7).
|
|
|
Рис. 3.5. |
Рис. 3.6. |
Рис. 3.7. |

Отже, проста рандомізована вибірка обсягом n=10 із відомої популяції обсягом N=30 може містити такі об'єкти: 2, 10, 14, 15, 16, 19, 21, 23, 26, 30.