

Описательная статистика
Я провёл
исследование описательной статистики
по выборке. В результате я получил
следующую таблицу, содержащую в себе
данные по среднему значению, медиане,
максимуму, минимуму, стандартному
отклонению, коэффициенту асимметрии,
коэффициенту эксцесса, статистике
Харке-Бера, вероятности и количеству
наблюдений.
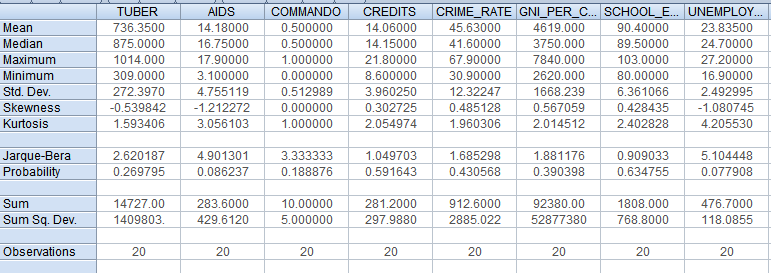
Рис. 11 – таблица описательной статистики
Рассмотрим самые интересные для нас величины и наблюдения:
Медиана ни в одном из случаев сильно не отличается от среднего значения (в случае же с переменной commando эти измерения вовсе нерелевантны из-за бинарности переменной). Однако при учёте минимального и максимального значения переменных становятся заметны отклонения. Так, уровень заболеваемости ВИЧ/СПИД имеет не сильно отличающиеся медиану и среднее значение (16,75 и 14,18 соответственно), но при этом они очень близки к максимальному значению (17,9) и очень далеки от минимального (3,1), что свидетельствует о резком росте заболеваемости и высоком уровне на протяжении большей части периода 1994-2013 гг. Чем-то схожая картина наблюдается и в случае с уровнем национального дохода на душу населения, но здесь смещение идёт, напротив, в сторону минимума, что говорит о том, что большую часть периода значения НД были далеки от максимума (о том же говорит и разница между средним значением и медианой почти в 1000 долларов в пользу среднего значения).
Стандартное отклонение при нормальном распределении должно соответствовать «правилу трёх сигм», согласно которому около 99% наблюдений должны лежать в рамках +/- 3σ от среднего значения. Я провёл подсчёты в программе Microsoft Excel (исключив бинарную переменную commando) и сравнил минимальные и максимальные значения выборки с вычислениями «среднее значение плюс/минус три стандартных отклонения».
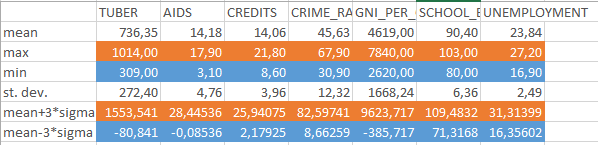
Рис. 12 – сравнение минимальных и максимальных значений со значениями по правилу трёх сигм
Как видно из таблицы, практически во всех случаях разница между реальными и ожидаемыми при нормальном распределении значениями весьма велика (более-менее близкие значения получились только в случае с безработицей, хотя и там наблюдаемый максимум отличается от ожидаемого более чем на 4 пункта – 27,2 против 31,3 при среднем значении переменной в 23,8). Во всех случаях «правило трёх сигм» завышает максимум и занижает минимум (порой уводя его в отрицательные значения, что при данных переменных вообще едва ли возможно). Это говорит о том, что мои данные в целом распределены ненормально.
Коэффициент асимметрии (Skewness) отражает то, насколько асимметрично распределены значения относительно математического ожидания (т.е. среднего значения). Отрицательные значения встречаются у переменных туберкулёза, СПИДа и безработицы – там, где левый хвост распределения длиннее правого (среднее значение ближе к максимуму, чем к минимуму). Положительные – у переменных процентной ставки, уровня убийств, уровня НД на душу населения и охвата образования, т.е. там, где правый хвост распределения длиннее левого (среднее значение ближе к минимуму, чем к максимуму). Это говорит о том, что у первой группы переменных большую часть периода 1994-2013 гг. значения были ниже среднего, а у второй – выше. Наиболее несимметричное распределение – у переменной заболеваемости СПИД (-1,21). Для бинарной переменной commando данный показатель бессмыслен.
Коэффициент эксцесса (Kurtosis) отражает меру остроты пика распределения случайной величины. У всех переменных данный коэффициент положителен, что говорит об остроте пиков распределения всех этих величин. Наибольшие значения – у безработицы и вновь у заболеваемости ВИЧ/СПИД (4,2 и 3,01 соответственно), что говорит о наибольшем перепаде значений в районе пика у этих величин и, следовательно, о наибольшем возрастании и убывании (впрочем, это верно только для уровня безработицы – заболеваемость СПИД является непрерывно возрастающей величиной и имеет наибольшую величину коэффициента эксцесса лишь по техническим причинам).
Тест Харке-Бера – это статистический тест, проверяющий ошибки наблюдений на нормальность их распределения посредством сверки их третьего момента (асимметрия) и четвёртого момента (эксцесс) с моментами нормального распределения, у которого S=0, K=3. Чем ближе распределение ошибок к нормальному, тем меньше статистика Харке—Бера отличается от нуля. Как видно из таблицы 11, показатели статистики Харке-Бера говорят о ненормальном распределении остатков всех переменных (наименьшее, то есть наиболее близкое к нормальному значение – у переменной охвата образования (0,91), наибольшее – у переменной уровня безработицы (5,11)). Впрочем, тест Харке-Бера предназначен для больших выборок, в моей же насчитывается только 20 наблюдений каждой переменной.