

3.3. Вычисление в spss
Для определения силы или направленности связи между номинальными признаками в программе SPSS используются команды, необходимые для расчета критерия Х2 (хи-квадрат) Пирсона. После чего в диалоговом окне «Crosstabs: Statistics / Таблицы сопряженности: Статистики» активируются необходимые команды, которые расположены ниже Х2 (хи-квадрат)-теста и объединены в одну группу – «номинальные» (рис.7.4).
Симметричные
меры
Направленные
меры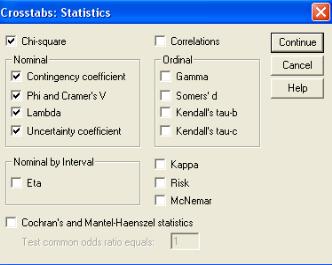


Рис. 7.4. Диалоговое окно «Crosstabs: Statistics / Таблицы сопряженности: Статистики»
После активизации в SPSS необходимых функций, в окне «Output / Вывод» появятся таблицы: симметричные меры (табл.7.3) и направленные меры (табл. 7.4). Рассмотрим их по порядку.
Табл. 7.3 содержит меры, нормирующие критерий Х2 Пирсона и отражающие силу взаимосвязи между признаками. Во втором столбце приводятся значения коэффициентов (Value), в третьем – их значимость (Approx. Sig.).
Таблица 7.3. Результат вычисления симметричных мер связанности для номинальных шкал (фрагмент приложения программы SPSS)
Symmetric Measures / Симметричные меры |
|||
|
|
Значение |
Прибл. значимость |
Nominal by Nominal / Номинальная по номинальной |
Phi (Фи) |
,184 |
,000 |
Cramer's V (V Крамера) |
,184 |
,000 |
|
Contingency Coefficient / Коэффициент сопряженности |
,181 |
,000 |
|
Кол-во валидных наблюдений |
793 |
|
|
Not assuming the a. null hypothesis. / Не подразумевая истинность нулевой гипотезы.
Using the asymptotic standard error assuming the null hypothesis. / Используется асимптотическая стандартная ошибка в предположении истинности нулевой гипотезы.
Табл. 7.4. содержит значения коэффициентов, отражающих не только силу, но и направленность взаимосвязи между признаками.
Таблица 7.4. Результат вычисления направленных мер связанности
для номинальных шкал (фрагмент приложения программы SPSS)
Directional Measures / Направленные меры |
||||||
|
|
|
Значение |
Асимптотическая стдандартная ошибкаa |
Прибл. Tb |
Прибл. значимость |
Nominal by Nominal/ Номинальная по номинальной |
Lambda/ Лямбда |
Symmetric/ Симметричная |
,023 |
,024 |
1,986 |
,224 |
Dependent / Зависимая чувства |
,000 |
,031 |
,066 |
,000 |
||
Dependent / Зависимая пол |
,053 |
,039 |
2,712 |
,224 |
||
Goodman and Kruskal tau / Тау Гудмена и Краскала |
Dependent / Зависимая чувства |
,014 |
,004 |
|
,000c |
|
Dependent / Зависимая пол |
,034 |
,012 |
|
,000c |
||
Uncertainty Coefficient/ Коэффициент неопределенности |
Symmetric / Симметричная |
,017 |
,006 |
2,417 |
,000d |
|
Dependent / Зависимая чувства |
,013 |
,005 |
2,417 |
,000d |
||
Dependent / Зависимая пол |
,025 |
,009 |
2,417 |
,000d |
||
a. Not assuming the null hypothesis. / Не подразумевая истинность нулевой гипотезы. |
||||||
b. Using the asymptotic standard error assuming the null hypothesis. / Используется асимптотическая стандартная ошибка в предположении истинности нулевой гипотезы. |
||||||
c. Based on chi-square approximation./ На основании аппроксимации хи-квадрат |
||||||
d. Likelihood ratio chi-square probability. / Вероятность отношения правдоподобия хи-квадрат. |
||||||
Нас в первую очередь интересует содержание второго и последнего столбцов таблицы, в которых приведены значения критериев и их статистическая значимость. Под таблицей под буквами «а», «b», «с», «d» приводятся некоторые комментарии по произведенным расчетам.
Итак, проинтерпретируем расположенные выше таблицы. На основе данных, приведенных в табл. 7.2 (таблица приводится повторно)
Таблица 7.2. Результат проведения Х2-теста (фрагмент приложения