

Сохранить стандартизированные значения в переменных
Рис. 5.8. Вычисление стандартизированные оценок
в диалоговом окне «Descriptive / Описательные».
Команда Descriptives / Описательные в значительной степени дублирует функции команды Frequencies / Частоты, поскольку вычисляет одномерные статистические характеристики (меры средней тенденции и меры разброса) для выбранных переменных. Наиболее существенной задачей, которую решает данная команда, является вычисление Z-стандартизированных значений. В нижней части главного меню команды находится окно, при выборе которого программа автоматически вычисляет стандартизированные значения для выбранных переменных (рис. 5.8).
После вычислений автоматически создается новая переменная, содержащая в себе стандартизированные значения, и размещается она последней в матрице данных (рис. 5.9).

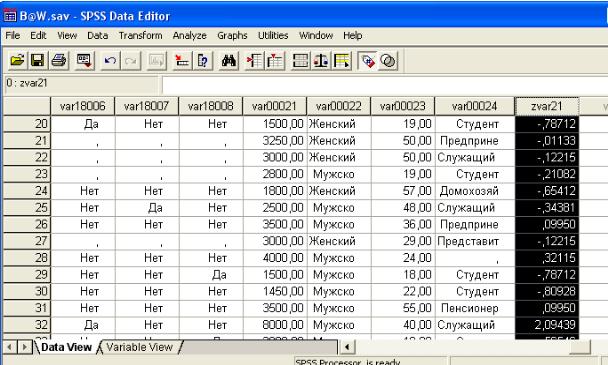
Рис. 5.9. Диалоговое окно «Данные», содержащее новую
переменную стандартизированных оценок
Новая переменная zvar21 представляет собой Z-стандартизированное значение переменной var00021. Использование стандартизированной переменной позволяет сказать, что доход респондента номер 21 приблизительно равен среднему значению по массиву опрошенных. В то время как доход у респондента под номером 32 значительно выше, нежели у среднего респондента.
Использование стандартизированных переменных может быть полезно при сопоставлении показателей, измеренных в различных единицах. Так, например, мы располагаем результатами исследований, проведенных в России и США. У российского респондента А средний доход составляет 9 000 руб. в месяц, у американского респондента В доход равен 2 000 дол. в месяц. Не зная значений средних доходов россиян и американцев, мы не можем их сопоставить и определить, кто из респондентов (А или В) находится выше в своем социальном кругу с точки зрения доходов. Но мы можем ответить на данный вопрос, если сопоставим не исходные объективные данные, а стандартизированные показатели.
16. Таблицы сопряженности.
. Наиболее часто перед социологами ставятся такие задачи, как описание и анализ совместного поведения двух и более переменных. При этом социолог формирует различные модели, например «респонденты, принадлежащие к разным возрастным, профессиональным или доходным группам, различаются по степени удовлетворенностью своей жизнью или политическим предпочтениям». Тем самым, допускается, что существует некоторая переменная (например, принадлежность к определенной социальной группе), которая объясняет поведение других переменных. Таким образом, в этой модели есть и причина и следствие.
В традиционной терминологии объясняющие переменные называются независимыми, а объясняемые переменные – зависимыми. При описании совместного поведения нескольких переменных социолог прибегает к использованию многомерного анализа. Наиболее частым инструментом проверки гипотез о взаимосвязи двух переменных являются таблицы сопряженности.
Таблица сопряженности – это таблица, содержащая частоты совместного проявления значений двух признаков (например, X и Y), измеренных в данной совокупности единиц анализа. В ней строки соответствуют значениям одного признака, столбцы – другого. Иными словами, в таблицах сопряженности отражаются выборочные оценки вероятностных распределений многомерных случайных величин. На основе этой таблицы можно судить о сопряженности (взаимной встречаемости) каких-то значений одних признаков с некоторыми значениями других.
Каждая таблица сопряженности представляет собой численность групп респондентов, на которые подразделяется вся совокупность (т.е. матрицу абсолютных чисел). Кроме того, в таблице располагаются относительные частоты, т.е. доли, которые составляют группы из числа единиц анализа. Они приводятся в виде процентов. Наряду с этими частотами приводятся суммарные частоты по отдельным значениям признаков, а также вспомогательная информация, например по каждому вопросу число респондентов, не ответивших на этот вопрос.
Признаки в таблицах сопряженности – это вопросы анкеты, а
значения признаков – варианты ответов на эти вопросы.
Крайний правый столбец образуют строковые маргинальные суммы (маргиналы по строкам). Последняя строка содержит столбцовые маргинальные суммы.
Например,
нам надо построить таблицу сопряженности для ответов на следующие вопросы:
1. Насколько безопасно Вы чувствуете себя в городе? Оцените по пятибалльной шкале.
Небезопасно
Практически небезопасно.
Затрудняюсь ответить.
Практически безопасно.
Безопасно.
2. Ваш пол?
Мужской
Женский
Для этого в SPSS необходимо воспользоваться следующими командами:
Аnalyze / Анализ →
Discriptive Statistics / Описательная статистика →
Crosstabs / Таблицы сопряженности.
После чего откроется диалоговое окно «Crosstabs / Таблицы сопряженности» (рис. 7.1- для примера),