

Перекодировать в другие переменные
Далее необходимо определить новые значения переменной. Для этого воспользуемся кнопкой «Old and New Values» / Старые и новые значения, после чего откроется новое диалоговое окно (рис. 4.3).
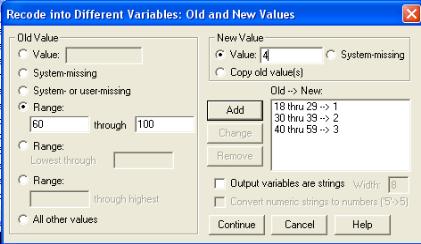
Рис. 4.3. Диалоговое окно « Recode into Different Variables: Old and New Values / Перекодировать в другие переменные: Старые и новые значения»
Здесь необходимо указать старые значения переменной и соответствующие им значения новой переменной. Для этого обратимся к группе значений левой части окна «Old Values / Старое значения», которая дает возможность разного способа обозначения кодов прежней переменной. Так,
Value / Значение позволяет вводить отдельное значение.
System – missing или System – or user – missing / Системное пропущенное / Системное или пользовательское пропущенное позволяет присвоить новое значение пользовательским и системным пропущенным значениям.
Range through / Диапазон указывает замкнутый интервал значений.
Range: Lowest through – диапазон от наименьшего до указанного,
Range: through highest – диапазон от указанного до максимального наблюдаемого, и
All other values – все остальные значения.
В правой части окна указываем пошагово новые значения и нажимаем клавишу «Аdd / Добавить», только после этого старому значению будет присвоено новое. После указания всех вариантов значений надо нажать на клавишу «Continue / Продолжить». В результате выполнения всех команд в Редакторе данных / «Данные» в последнем столбце появится новая переменная, содержащая перекодированные значения. Теперь для удобства работы надо в описании новой переменной обозначить метки ее кодов (см. предыдущие темы).
1.2. Перекодирование в старых переменных.
Если при обработке данных вы уверены, что переменная с первоначальной кодировкой вам больше никогда не потребуется, вы можете перекодировать ее. Однако имейте ввиду, что прежнюю информацию вы потеряете. Для подобного перекодирования можно воспользоваться командами
Transform / Преобразовать →
Recode / Перекодировать →
Into Same Variables / В те же переменные
после чего откроется диалоговое окно
«Recode Into Same Variables / Перекодировать в те же переменные» (рис. 4.4). В нем выбираем переменные для перекодирования и при помощи клавиши
«Old and New Values / Старые и новые значения» попадаем в новое окно (рис. 4.3), где выбираем новые коды. Все действия далее аналогичны ситуации перекодирования с созданием новой переменной.

Рис. 4.4. Диалоговое окно «Recode Into Same Variables /
Перекодировать в те же переменные»
Таким образом, пользуясь возможностями программы по перекодированию, мы можем изменять переменные (любых типов шкал).
Рассмотрим один пример. Предположим, что у нас есть переменная «образование» с 7-ю вариантами ответа.
Ваше образование?
1. Начальное → 1
2. Неполное среднее → 2
3. Полное общее среднее → 2
4. Профессионально-техническое (ПТУ, СПТУ, профессиональный лицей) → 3
5. Среднее специальное (техникум, колледж) → 3
6. Незаконченное высшее → 4
7. Высшее → 4
Нам на ее основе надо создать другую переменную, имеющую 4 варианта ответа.
1. Начальная школа
2. Средняя школа
3. Техникум / ПТУ
4. Институт
При подобном перекодировании мы прибегаем к определенному сжатию информации, поэтому имеет смысл перекодировать с созданием новой переменной. Используем необходимые для этого команды и попадаем в диалоговое окно «Recode into Different Variables / Перекодировать в другие переменные» (рис. 4.2). Здесь наша задача написать новое имя переменой, иначе клавиша «Continue / Продолжить» не будет в дальнейшем активной.
В диалоговом окне «Old and New Values / Старые и новые значения» (рис. 4.3) проводим соответствие между кодами.
Для этого в группе «Old Values / Старое значение» выбираем вариант «Values / Значение», ставим рядом код 1,
к группе «New Values / Новое значение» также выбираем код 1 и подтверждаем нажатием клавиши «Add / Добавить». По условиям задачи код этого варианта ответа не меняется.
Далее можно выбрать вариант «Range through / Диапазон» и указать диапазон кодов от 2 до 3. Значениям этих кодов будет соответствовать код 2-й новой переменной. Диапазону 4–5 соответствует код 3, всем остальным вариантам ответа соответствует код 4. После совершения всех вычислений в диалоговом окне «Редактор данных / Данные» добавится новая переменная.
Таким образом, по своему усмотрению мы можем полностью или выборочно менять коды значений переменных. В некоторых случаях это более удобно, нежели провести пересчет значений переменных.
2. Условный отбор данных. Для того чтобы получить информацию распределения ответов или значения коэффициентов не для всего массива, а отдельной его части (так называемого подмассива), надо отобрать интересующие нас категории, а остальные исключить из обработки.
Иными словами, надо поставить фильтр и отобрать случаи, соответствующие определенным условиям. Для отбора случаев в программе предусмотрены следующие команды:
Data / Данные →
Select Cases / Отобрать наблюдения.
В результате откроется диалоговое окно «Select Cases / Отобрать наблюдения» (рис. 4.6), в котором по умолчанию стоит «All cases / Все наблюдения».
Нам надо активировать клавишу «If / Если».
Для этого выберем функцию (поставить флажок) «If condition is satisfied / Если выполнено условие.
В результате появится новое окно (рис. 4.5), в нем надо определить переменные, на основании которых мы формируем подмассив данных. Например, нас интересуют лишь мужчины в возрасте старше 29 и младше 68 лет.
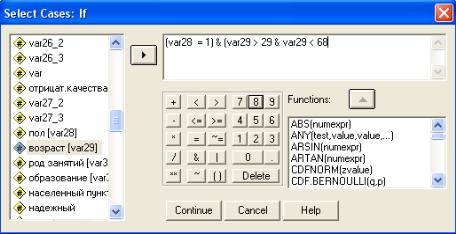
Рис. 4.5. Диалоговое окно для отбора случаев по условию
Как видно на рис. 4.5, в левом поле окна приводится список всех переменных. Нам по условию задачи надо отобрать мужчин определенного возраста. Для этого находим переменную «пол» и при помощи клавиши перемещаем ее в правое верхнее поле. Наша переменная будет отображена в нем в виде имени (var 28). Далее указываем коды тех вариантов ответа, которые нам нужны (в данном случае это 1). В итоге получилось условное выражение var 28 = 1. Однако это не все условия, которые нам надо учесть. Теперь отбираем случаи на основе переменной «возраст». Для этого составим условное выражение var 29 > 29 & var 29 < 68.
Для одновременного выполнения этих условий надо взять их формулы в скобки и поставить между ними знак &. В итоге получится формула (var 28 = 1) & ( var 29 > 29 & var 29 < 68).
После того, как в левом верхнем поле окна будут указаны все условия, нажимаете на клавишу «Continue / Продолжить», а затем «ОК».
После чего программа автоматически отбирает все случаи, соответствующие заданному условному выражению, и исключает для дальнейшей математической обработки не соответствующие условиям. Результат отбора наглядно виден в редакторе данных – номера исключенных случаев перечеркнуты (рис. 4.6).
Мы видим, что условиям нашего примера соответствуют случаи за номерами 1, 8, 10, 11 и 13, остальные исключены. Кроме того, в редакторе данных появилась дополнительная (последняя по счету) переменная «filter_$», также отражающая соответствие случаев заданному условию.

Рис. 4.6. Диалоговое окно «Редактор данных» с отражением
отфильтрованных случаев
Итак, для составления и написания условного выражения вам потребуется использование многих знаков, которые разграничивают или взаимно дополняют несколько условий. Часть из них отражена на клавиатуре диалогового окна (рис. 4.5), расположенной ниже редактора условий. Эти символы обладают разными приоритетами в процессе вычислений (табл. 4.1), поэтому их надо внимательно использовать при составлении условных выражений.
Таблица 4.1. Приоритет переходных операторов
Приоритет |
Оператор |
Значение |
1 |
( ) |
Оператор скобок |
2 |
< |
Меньше |
|
<= |
Меньше или равно |
|
> |
Больше |
|
>= |
Больше или равно |
|
= |
Равно |
|
~= |
Не равно |
3 |
&, and |
Логическое И |
4 |
I, or |
Логическое ИЛИ |
Кроме того, для составления условных выражений можно использовать функции, предлагаемые программой в правом нижнем поле диалогового окна (рис. 4.5). Функции вставляются в поле «Редактор условий / Отобрать наблюдение: Условие» посредством кнопки со стрелкой вверх. В SPSS предусмотрена возможность использования 140 математических функций, однако мы в процессе анализа результатов исследований наиболее часто обращаемся лишь к двум из них.
Это функции RANGE (variable, begin, end) / Диапазон (переменная, начало, конец), и
ANY (variable, val1, val2, ..) / Любой (переменная, значение1, значение 2,…]). В каких ситуациях их уместно применять?
Например, нам для анализа надо отобрать респондентов в возрасте от 18 до 25 лет и от 50 до 65 лет. Используем для отбора функцию RANGE/ Диапазон . Сначала в окно помещаем данную функцию, а затем в скобках помещаем переменную. В итоге наше условное выражение будет выглядеть следующим образом: RANGE (var 29,18,25,50,65). Пробелы между цифрами ставить не надо.
В предыдущем примере мы также могли использовать эту функцию для отбора мужчин в возрасте от 29 до 68 лет. В этом случае условное выражение приняло бы такой вид (var28 = 1) & RANGE (var 29, 29, 68).
При помощи функции ANY/ Любой мы может отбирать случаи, имеющие определенные значения признака. Так, например, нам надо отобрать респондентов, которые имеют доход 4500, 5200 и 7600 рублей. Условное выражение примет вид: ANY (var доход, 4500, 5200, 7600). Программа сама отбирает респондентов, у которых встречается хотя бы одно из этих значений дохода.
Итак, программа SPSS позволяет нам на основе ответов респондентов на вопросы анкеты формировать частные подвыборки и производить статистический анализ по отдельным группам. Причем эти группы мы можем формировать на основе разнообразных условий, диктуемых задачами исследования.
3. Вычисление новых переменных. Помимо перекодирования переменных и отбора определенных случаев в программе SPSS предусмотрена возможность пересчета и вычисления новых переменных.
Для этого надо воспользоваться командами
«Transform / Преобразовать →
«Compute / Вычислить переменную», в результате откроется диалоговое окно для вычислений (рис. 4.9), в котором надо определить имя новой переменной и условия ее вычисления.

Рис. 4.9. Диалоговое окно «Compute / Вычислить переменную»
Для этого в верхнем левом поле «Target Variable / Вычисляемая переменная» указывается имя новой переменной, которой будет присваиваться вычисленное значение. После чего в поле «Numeric Expression / Числовое выражение» вводится выражение применяемой для вычисления итоговой переменной. (Итоговой переменной может быть уже созданная или новая переменная.) После указания числового выражения нажимаем на клавишу ОК, и во вкладке «Данные» появляется дополнительная вычисленная переменная. Как правило, она располагается последней.
Так, например, нам надо пересчитать переменную «потенциальная явка на выборы», имеющую 5 вариантов ответов (1 – буду, 2 – скорее буду, 3 – скорее не буду, 4 – не буду, 5 – затрудняюсь ответить), и сделать из нее трехчленную шкалу (1 – буду, 2 – не буду, 3 – затрудняюсь ответить). Для этого, активизировав диалоговое окно «Compute / Вычислить переменную», вводим численное выражение, на основе которого программа пересчитает нашу переменную. Для построения численного выражения используем функцию ANY, которая позволяет определенным дискретным значениям переменной присваивать другие значения (аналог перекодировки). Для нашего примера численное выражение будет выглядеть следующим образом:
ANY(var 5,1,2)*1+ANY(var 5,3,4)*2+ANY(var 5,5)*3 (рис. 4.9).
Оно означает, что значениям «1» и «2» исходной переменной будет соответствовать значение «1» новой переменной, значения «3» и «4» исходной переменной примут код «2», а значение «5» станет значением «3» в новой пересчитанной переменной.
После ввода численного выражения или формулы для пересчета переменной нажимаем клавишу ОК. В результате всех вычислений в редакторе «Данные» появляется новая переменная с именем «выборы» (имя переменной задается вами самостоятельно), имеющая три варианта ответа. Далее для удобства работы надо в описании переменной ввести метки кодов, т.е. содержательное описание вариантов ответов.
Применение другого логического оператора RANGE дает нам возможность пересчитать количественные переменные в интервальные или порядковые. Так, например, нам надо количественную переменную «возраст» пересчитать в дихотомическую шкалу (18–30 лет и 30 лет и старше). Функция для расчета примет следующий вид:
RANGE (в53,18,29)*1+ RANGE (в53,30,85)*2.
Рассмотрим другой пример вычисления переменной. Мы имеем в качестве исходных переменных var 00056 – «средний доход на 1 человека в семье в месяц» и var 00057 – «количество членов семьи». На их основе нам надо вычислить среднемесячный семейный доход респондентов (назовем новую переменную «доход1»).
В диалоговом окне «Compute / Вычислить переменную» записываем формулу для вычисления новой переменной, она будет иметь следующий вид: var 00056* var 00057 (каждый среднемесячный доход на 1 человека в семье умножаем на количество членов семьи). В редакторе данных появится новая переменная.
Аналогичным образом, внеся изменения в формулу ((var00056*var00057)*12), мы можем посчитать и суммарный годовой доход для каждого респондента.
Вычисление новых переменных мы можем производить не для всех случаев, а лишь тех, что соответствуют определенным условиям. Для этого в диалоговом окне «Compute / Вычислить переменную» нажмем на клавишу «If / Если (условие отбора наблюдений)», появится новое окно, в котором надо ввести условие (рис. 4.12). В данном случае мы поставили условие вычислять суммарный годовой доход лишь для мужчин.

Итак, параметрами функций для вычисления переменных могут быть сами переменные, константы или выражения. Параметры заключаются в круглые скобки и отделяются друг от друга запятыми.
4. Подсчет частоты появления определенных значений. Программа SPSS предоставляет нам возможность подсчитать число появления одного и того же значения переменных для одного случая. Это может пригодиться в следующей ситуации.
Например, в анкету был включен блок вопросов о финансовом поведении: «Вспомните, пожалуйста, какие операции из нижеперечисленных Вам приходилось совершать в течение последних 12 месяцев?
1 – оформлять кредит;
2 – получать на карточку заработную плату (стипендию, пенсию);
3 – расплачиваться за товары и/или услуги при помощи пластиковой карточки и т.д.».
По каждой ситуации предлагалось два варианта ответа – 1– «да» и 2 – «нет». Блок вопросов включал 17 разных ситуаций.
Мы можем на основе этих вопросов вывести индекс «финансовой активности» респондентов, подсчитав количество проведенных финансовых операций. Для этого нам надо сложить все ответы «да» по этому блоку вопросов для каждого респондента. Полученный в итоге численный показатель будет индексом, отражающим финансовую активность.
Для вычисления нам надо воспользоваться командами Transform / Преобразовать → Count / Подсчёт значений в наблюдениях. Откроется диалоговое окно, в котором надо из левого поля в правое при помощи клавиши со стрелкой перенести переменные, участвующие в подсчете (рис. 4.13).
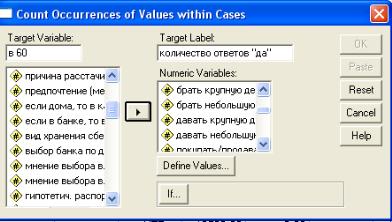
Рис. 4.13. Диалоговое окно
для подсчета частоты встречаемости ответов
Кроме того, надо не забыть в поле «Target Variable / Вычисляемая переменная» указать имя для новой вычисляемой переменной и указать критерии отбора в поле «Target Label / Метка вычисляемой переменной».
В нашем примере ситуация участия в операции отражалась ответом «да», который имел кодовое значение «1». Теперь для расчетов нам надо обозначить те значения, которые программа будет подсчитывать. Для этого нажимаем на клавишу «Define Values / Задать значения».
Открывается новое диалоговое окно (рис. 4.14),

Рис. 4.14. Диалоговое окно для указания подсчитываемых значений
в котором мы можем определить значения переменных, участвующих в подсчете, и подтвердить их ввод клавишей «Add / Добавить».
После всех вычислений в редакторе данных появляется новая переменная, в нашем случае она имеет имя «в 60», которая содержит количество ответов «да» в нашем блоке вопросов (рис. 4.15).
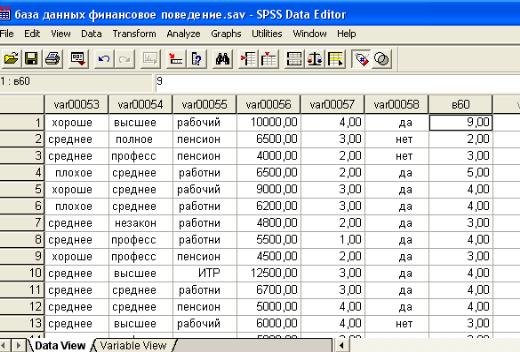
Рис. 4.15. Диалоговое окно «Данные», содержащее новую переменную
Интерпретация получаемых таким образом количественных показателей осуществляется в зависимости от задач исследования и задумок самого исследователя. В нашем примере высокие значения полученного индекса отражают активность респондентов в области финансового поведения. Таким образом, прежде чем приступить к описанию и анализу результатов исследования, мы можем модифицировать
базу данных и корректировать форму их представления