

Чувства
|
Frequency / Частота |
Percent / Процент |
Valid Percent / Валидный процент |
Cumulative Percent / Кумулятивный/ суммарный процент |
|
Valid Валидные |
тревога |
300 |
37,4 |
37,5 |
37,5 |
надежда |
252 |
31,4 |
31,5 |
69,1 |
|
никаких |
153 |
19,1 |
19,1 |
88,2 |
|
спокойствие |
90 |
11,2 |
11,3 |
99,5 |
|
з.о. |
4 |
0,5 |
0,5 |
100,0 |
|
Total / Итого |
799 |
99,6 |
100,0 |
|
|
Missing / Пропущенные |
System / Без ответа |
3 |
0,4 |
||
Total / Итого |
802 |
100,0 |
|||
В табл. 3.3 все варианты ответа упорядочены от наиболее часто встречаемого ответа к наименее распространенному. Флажок около функции «Suppress tables wiht more than ... categories» (Не выводить таблицы с более чем … категориями / Подавлять таблицы, если категорий больше чем) позволяет избежать вывода на экран больших таблиц.
3. Графическое представление поведения переменной. Помимо табличного представления частотных распределений обычно используют и различные методы графического представления, которые хорошо представлены в SPSS.
Диаграммы в качестве метода построения одномерных частотных распределений повышают наглядность полученных закономерностей и могут быть использованы для презентации результатов исследований.
Для построения графиков и диаграмм в диалоговом окне «Frequencies / Частоты» (рис. 3.1.) необходимо нажать на клавишу Charts / Диаграммы.
В результате откроется окно «Frequencies: Charts / Частоты: Диаграммы» (рис. 3.6).
Рис. 3.6. Диалоговое окно «Frequencies: Charts»
Здесь можно задать тип графика и значения, на основе которых будет построена диаграмма. По умолчанию активизирована функция None (нет графика).
В данном диалоговом окне можно построить: столбиковую диаграмму Bar charts, круговую диаграмму Pie charts или гистограмму Histograms.
При построении гистограммы можно одновременно отобразить кривую нормального распределения для определения характера поведения признака, поставив флажок около функции «With normal curve / С нормальной кривой».
В качестве значений графиков могут выступать частоты (в абсолютных числах) или их процентные эквиваленты.
После выбора типа и значений диаграммы надо нажать на клавишу «Continue / Продолжить». После этого в приложении «Output / Вывод» будет построена таблица и диаграмма частотного распределения. Если вы не желаете, чтобы на экран выводилась таблица частотного распределения, то в окне «Frequencies / Частоты» (рис. 3.1) уберите флажок напротив функции «Display Frequency tables / Вывести частотные таблицы».
Самый распространенный метод графического представления одномерных распределений – это гистограмма, или столбиковая диаграмма. Каждый столбик соответствует интервалу значений переменной. Высота столбика отражает частоту попадания наблюдавшихся значений переменной в определенный интервал (рис. 3.7).
Еще один популярный способ графического представления, обычно используемый для номинальных и порядковых шкал, – это круговая диаграмма (рис. 3.8). Каждый сектор круговой диаграммы представляет дискретную категорию переменной. Величина сектора пропорциональна частоте категории для данной выборки.
Тип диаграммы, который следует выбирать для каждого отдельного случая, зависит от эстетических пристрастий и не имеет какого-либо существенного значения.
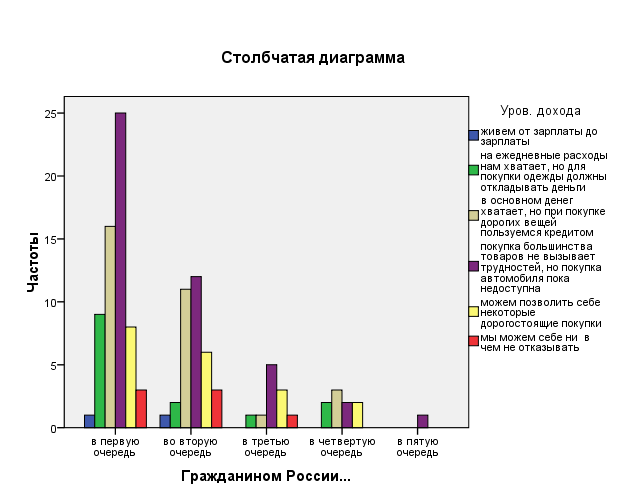
Рис. 3.7. Распределение ответов на вопрос «В какую очередь Вы чувствуете себя гражданином России?» в зависимости от уровня дохода респондентов (в процентах от числа ответивших)
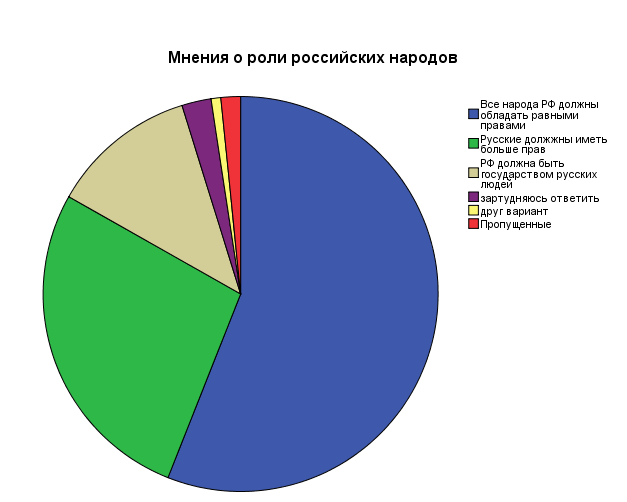
Рис. 3.8. Распределение ответов на вопрос «Какое из мнений о российских народах в России в большей мере соответствует Вашей точке зрения?» (в процентах от числа ответивших).
Помимо построения графиков в программе SPSS предусмотрена возможность их редактирования. Для этого в приложении «Output / Вывод» на поле построенного графика щелкните правой клавишей мыши. В результате откроется следующее меню.
В этом меню, выбрав функцию SPSS Chart Object → Open, откройте окно редактора графиков. Данное окно откроется поверх первоначального графика (рис. 3.9). В нем можно изменить подписи данных, цвет заливки, поставить значения переменной, изменить положение графика в плоскости и т.д.

Рис. 3.9. Диалоговое окно «Редактирование графиков»
Таким образом, программно-аналитический комплекс SPSS позволяет осуществлять не только математическую обработку полученных результатов исследования, но и располагает возможностями для наглядного и удобного их представления.
2. Построение таблиц частотного распределения для многозначных вопросов. Если на один вопрос анкеты предполагается несколько вариантов ответа, то для него составляется несколько переменных (их количество зависит от способа кодировки данных – дихотомического или категориального), и описанная выше процедура построения таблиц частотного распределения (при помощи команд Аnalyze / Анализ → Descriptive statistics / Описательные статистики → Frequencies / Частоты будет неудобна для дальнейшего анализа. Это неудобство связано с тем, что для каждой переменной будет создаваться своя таблица.
Например, один из вопросов анкеты звучит следующим образом:
Что для Вас наиболее важно при возможности выбора города для работы и проживания? (Можно выбрать несколько ответов.)
|
Вариант ответа |
|
Вариант ответа |
0 |
нет ответа, затрудняюсь ответить |
8 |
репутация городских властей |
1 |
низкий уровень преступности |
9 |
возможность гражданского участия в развитии города |
2 |
этно-религиозный состав населения |
10 |
возможности для отдыха |
3 |
высокий уровень благосостояния жителей |
11 |
экологическая ситуация |
4 |
доступность и качество дошкольного и школьного образования |
12 |
стоимость жилья |
5 |
стоимость жизни в городе |
13 |
развитые транспортные сети |
6 |
доступность и качество услуг в здравоохранении |
14 |
развитая торговая система |
7 |
состояние системы общественного транспорта |
15 |
важным является эффективная работа всех сфер |
Для данного вопроса было создано три переменных, кодировка которых осуществлялась категориальным методом. В результате в приложении «Output / Вывод» будет создано три таблицы, соответствующие каждой переменной, отражающие ответы на
этот вопрос (рис. 3.3).
Такой формат вывода таблиц на экран не дает целостного представления о распределении ответов на данный вопрос. Поэтому разработчиками программы SPSS предусмотрена возможность сведения всех значений многозначных вопросов в единую таблицу, содержащую информацию о распределении всех переменных, соответствующих данному признаку.
Таблица для 1-й переменной признака
Что из перечисленного для вас является самым важным |
|||||
|
|
Частота |
Процент |
Валидный процент |
Кумулятивный процент |
Валидные |
низкий уровень преступности |
66 |
28,1 |
31,0 |
31,0 |
этно-религиозный состав населения |
4 |
1,7 |
1,9 |
32,9 |
|
высокий уровень благосостояния жителей |
30 |
12,8 |
14,1 |
46,9 |
|
доступность и качество дошкольного и школьного образования |
5 |
2,1 |
2,3 |
49,3 |
|
стоимость жизни в городе |
19 |
8,1 |
8,9 |
58,2 |
|
доступность и качество услуг в здравоохранении |
17 |
7,2 |
8,0 |
66,2 |
|
состояние системы общественного транспорта |
5 |
2,1 |
2,3 |
68,5 |
|
репутация городских властей |
4 |
1,7 |
1,9 |
70,4 |
|
возможность гражданского участия в развитии города |
1 |
,4 |
,5 |
70,9 |
|
возможности для отдыха |
6 |
2,6 |
2,8 |
73,7 |
|
экологическая ситуация |
13 |
5,5 |
6,1 |
79,8 |
|
стоимость жилья |
17 |
7,2 |
8,0 |
87,8 |
|
развитые транспортные сети |
10 |
4,3 |
4,7 |
92,5 |
|
развитая торговая система |
6 |
2,6 |
2,8 |
95,3 |
|
важным является эффективная работа всех сфер |
10 |
4,3 |
4,7 |
100,0 |
|
Итого |
213 |
90,6 |
100,0 |
|
|
Пропущенные |
нет ответа |
22 |
9,4 |
|
|
Итого |
235 |
100,0 |
|
|
|
Таблица для 2-й переменной признака
что из перечисленного для вас является самым важным |
|||||
|
|
Частота |
Процент |
Валидный процент |
Кумулятивный процент |
Валидные |
низкий уровень преступности |
4 |
1,7 |
2,7 |
2,7 |
этно-религиозный состав населения |
2 |
,9 |
1,4 |
4,1 |
|
высокий уровень благосостояния жителей |
10 |
4,3 |
6,8 |
11,0 |
|
доступность и качество дошкольного и школьного образования |
5 |
2,1 |
3,4 |
14,4 |
|
стоимость жизни в городе |
23 |
9,8 |
15,8 |
30,1 |
|
доступность и качество услуг в здравоохранении |
20 |
8,5 |
13,7 |
43,8 |
|
состояние системы общественного транспорта |
5 |
2,1 |
3,4 |
47,3 |
|
репутация городских властей |
3 |
1,3 |
2,1 |
49,3 |
|
возможность гражданского участия в развитии города |
1 |
,4 |
,7 |
50,0 |
|
возможности для отдыха |
11 |
4,7 |
7,5 |
57,5 |
|
экологическая ситуация |
27 |
11,5 |
18,5 |
76,0 |
|
стоимость жилья |
23 |
9,8 |
15,8 |
91,8 |
|
развитые транспортные сети |
9 |
3,8 |
6,2 |
97,9 |
|
развитая торговая система |
3 |
1,3 |
2,1 |
100,0 |
|
Итого |
146 |
62,1 |
100,0 |
|
|
Пропущенные |
нет ответа |
89 |
37,9 |
|
|
Итого |
235 |
100,0 |
|
|
|
Таблица для 3-й переменной признака
что из перечисленного для вас является самым важным |
|||||
|
|
Частота |
Процент |
Валидный процент |
Кумулятивный процент |
Валидные |
этно-религиозный состав населения |
1 |
,4 |
1,6 |
1,6 |
доступность и качество дошкольного и школьного образования |
1 |
,4 |
1,6 |
3,2 |
|
стоимость жизни в городе |
2 |
,9 |
3,2 |
6,5 |
|
доступность и качество услуг в здравоохранении |
6 |
2,6 |
9,7 |
16,1 |
|
состояние системы общественного транспорта |
3 |
1,3 |
4,8 |
21,0 |
|
возможность гражданского участия в развитии города |
2 |
,9 |
3,2 |
24,2 |
|
возможности для отдыха |
2 |
,9 |
3,2 |
27,4 |
|
экологическая ситуация |
18 |
7,7 |
29,0 |
56,5 |
|
стоимость жилья |
12 |
5,1 |
19,4 |
75,8 |
|
развитые транспортные сети |
10 |
4,3 |
16,1 |
91,9 |
|
развитая торговая система |
5 |
2,1 |
8,1 |
100,0 |
|
Итого |
62 |
26,4 |
100,0 |
|
|
Пропущенные |
нет ответа |
173 |
73,6 |
|
|
Итого |
235 |
100,0 |
|
|
|
Рис. 3.3. Распределение ответов на вопрос «Что для Вас наиболее важно при возможности выбора города для работы и проживания?»
(фрагмент приложения программы SPSS)
Для того, чтобы сформировать класс переменных, следует обратиться к командам Analyze / Анализ → Multiple Response / Множественные ответы → Define Sets / Задать наборы переменных.
В результате откроется окно (рис. 3.4).
В левом поле «Set Definition / Параметры набора» окна содержится перечень всех
переменных. В нем надо выбрать переменные, соответствующие вашему многозначному вопросу, и перенести их при помощи клавиши в правое поле окна «Variables in Set / Переменные в наборе». Затем необходимо выбрать способ формирования новой переменной. Он зависит от метода кодировки.
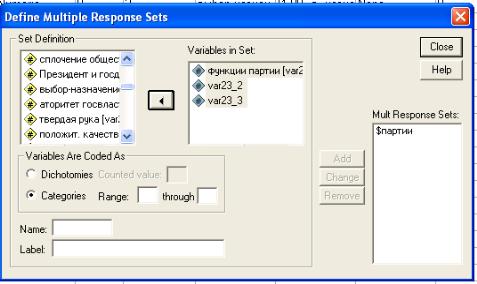
Рис. 3.4. Диалоговое окно «Set Definition / Параметры набора»
Если использовался дихотомический способ, то в разделе «Variables Are Codes As / Переменные кодируются как» выбирается команда Dichotomies / Дихотомии и указывается код выбора ответа. Как правило, это 1, если при вводе данных выбор данного варианта ответа кодировался как 1, а пропуск – как 0.
Если же способ кодировки категориальный, то необходимо выбрать команду Categories и указать Range (т.е. минимальное и максимальное значения кода данной переменной). В нашем примере минимальное значение 0, максимальное – 15 соответствуют варианту «важным является эффективная работа всех сфер».
Кроме того, надо указать имя новой переменной и метку в поле Name / Имя и Label / Метка. После этих процедур следует нажать клавишу Add / Добавить, после чего новая переменная будет внесена в окно «Mult Response Sets / Наборы множественных ответов». Если этого не сделать, то новой виртуальной переменной создано не будет. В диалоговом окне «Define Sets / Задать наборы переменных» можно сформировать несколько переменных, объединяющих ответы на разные вопросы, после чего следует нажать на клавишу Close / Закрыть.
Тем самым мы провели подготовку к построению таблиц частотного распределения для многозначных вопросов. Далее используем команды Analyz / Анализ → Multiple Response / Множественные ответы → Frequencies / Частоты, которые открывают окно (рис. 3.5).

Рис. 3.5. Диалоговое окно «Multiple Response: Frequencies /