

9. Методы анализа одномерных распределений: описание и графическое представление социологических данных, построение таблиц частотного распределения для многозначных вопросов.
1. Построение таблиц частотных распределений для однозначных вопросов. Анализ частотных распределений результатов социологических исследований – всегда первый шаг при обработке собранной информации. Данный анализ не является в строгом смысле анализом данных, т.к. выполняет функции получения общих представлений об изучаемых социальных группах.
Смысл одномерного описательного анализа состроит в том, что перед тем, как приступить к объяснению какого-либо явления, необходимо его описать. Поэтому описание исходных данных – это одна из целей анализа данных. Она, как правило, достигается прежде, чем исследователь приступит к поиску интересующей его закономерности. Описание необходимо для того, чтобы исследователь мог ориентироваться в полученных данных. Результаты социологического массового опроса содержат в себе ответы большого числа респондентов на разнообразные вопросы. Даже в рамках одного вопроса анкеты объем исходной информации достаточно велик для того, чтобы можно было его охватить одним взглядом и просуммировать. Ведь не всегда сначала ясно, какой вид закономерностей «скрывается» за данными или какими признаками эти закономерности должны описываться.
Описание достигается путем простых способов сжатия исходных данных (например, мы используем величину дисперсии для характеристики разброса респондентов по возрасту; вычисляем модальное значение признака «род занятий» интерпретируем как наиболее часто встречающуюся профессию и т.д.).
Именно задачу сжатия информации, компактного ее представления для дальнейшего осмысления и решают методы одномерного описательного анализа.
Совокупность наиболее часто используемых приемов получения закономерностей, описывающих изучаемое множество объектов, называется описывающей или дескриптивной статистикой.
Одномерный описательный анализ решает поставленную задачу тремя различными взаимодополняющими методами.
Построение частотных распределений.
Графическое представление поведения анализируемого признака.
Получение статистических характеристик распределения анализируемой переменной.
Построение частотных распределений. Для того, чтобы получить одномерные частотные распределения, следует использовать команды Аnalyze / Анализ → Descriptive statistics / Описательные статистики → Frequencies / Частоты.
В результате откроется окно (рис. 3.1), в левой части которого содержится список всех переменных. Из этого списка при помощи клавиши надо перенести те переменные, для которых строятся таблицы частотных распределений, в правое поле окна и нажать клавишу «ОК». В результате откроется приложение «Output» / Вывод, содержащее построенные таблицы. Частотные распределения в приложении «Output» / Вывод предстают в следующем виде (табл. 3.1).
Рис. 3.1. Диалоговое окно «Frequencies» / Частоты
Чувства
|
Frequency / Частота |
Percent / Процент |
Valid Percent / Валидный процент |
Cumulative Percent / Кумулятивный/ суммарный процент |
|
Valid Валидные |
Надежда |
252 |
31,4 |
31,5 |
31,5 |
тревога |
300 |
37,4 |
37,5 |
69,1 |
|
спокойствие |
90 |
11,2 |
11,3 |
80,4 |
|
никаких |
153 |
19,1 |
19,1 |
99,5 |
|
з.о. |
4 |
0,5 |
0,5 |
100,0 |
|
Total / Итого |
799 |
99,6 |
100,0 |
|
|
Missing / Пропущенные |
System / Без ответа |
3 |
0,4 |
||
Total / Итого |
802 |
100,0 |
|||
Таблица 3.1. Частотное распределение ответов респондентов на вопрос «Какие чувства Вы испытываете, когда думаете о ближайшем будущем?» (фрагмент приложения программы SPSS)
Данная таблица состоит из пяти столбцов.
В первом из них содержатся варианты ответов (Valid / Валидные) на данный вопрос (в нашем случае это перечень чувств), отображены отсутствующие значения (Missing System) и общее число измеренных случаев или объем выборки (Total / Итого).
Второй столбец, имеющий название Frequency / Частота, отражает то количество респондентов, которые выбрали тот или иной вариант ответа среди всех предложенных. Таким образом, из табл. 3.1 видно, что 252 респондента отметили, что испытывают чувство надежды, 300 – чувство тревоги и т.д., при этом объем выборки составил 802 чел. Но на поставленный вопрос ответили 799 респондентов, т.к. трое пропустили его.
Следует подчеркнуть, что на основе данных, содержащихся в столбце Frequency / Частота, нельзя сделать вывод о том, много или мало респондентов выбрали определенный вариант ответа, поскольку их всегда надо соотносить с общим числом опрошенных.
Процентное соотношение каждой из частот приводится в третьем столбце Percent / Процент. В нем отражается удельный вес каждой категории ответов во всей выборочной
совокупности. Иными словами, – это процент от числа опрошенных респондентов. Так, на основе данных табл. 3.1 можно заключить, что 31,4 % опрошенных испытывают чувство
надежды, 37,4 % респондентов, принимавших участие в опросе, – чувство тревоги.
Четвертый столбец в таблице одномерного частотного распределения Valid Percent / Валидный процент связан с такой характеристикой, как «Пропущенные» и, по сути, отражает частотные соотношения в процентах от числа ответивших. Так, по данным
этого столбца, можно заключить, что чувство тревоги испытывают 37,5 % ответивших на вопрос респондентов.
Пятый столбец Cumulative Percent / Кумулятивный/ накопительный / суммарный процент) указывает сумму процентных соотношений частот по вариантам ответа на вопрос.
Так, 69,1 % респондентов указали, что испытывают чувство тревоги и надежды, 80,4 % респондентов отметили определенное чувство (тревога, надежда или спокойствие). Интерпретация суммарного процента для переменных номинальных не имеет содержательного значения. Кумулятивный процент используется только для признаков, измеренных на уровне не ниже порядкового. Для номинальных шкал он не имеет содержательной интерпретации.
Обратим внимание на то, что в данной таблице варианты ответов «затрудняюсь ответить» и «никакие» рассчитываются наряду с остальными значениями переменной как
равноправные, однако они могут интерпретироваться нами как «уход респондента от ответа» и не иметь для нас содержательного значения. В этом случае мы можем обозначить их как «Отсутствующие значения /Пропущенные «(в описании переменной при помощи функции «Missing / Пропуски»). В результате эти значения переменной будут исключены из расчетов частотных распределений, а, следовательно, данные таблицы изменятся (табл. 3.2).
Таблица 3.2. Частотное распределение ответов респондентов на вопрос «Какие чувства Вы испытываете, когда думаете о ближайшем будущем?» (фрагмент приложения программы SPSS)
|
|
Frequency / Частота |
Percent / Процент |
Valid Percent / Валидный процент |
Cumulative Percent / Кумулятивный/ суммарный процент |
Valid / Валидные |
Надежда |
252 |
31,4 |
39,3 |
39,3 |
тревога |
300 |
37,4 |
46,7 |
86,0 |
|
спокойствие |
90 |
11,2 |
14,0 |
100,0 |
|
Total / Итого |
642 |
80,0 |
100,0 |
||
Missing / Пропущенные |
никаких |
153 |
19,1 |
||
з.о. |
4 |
0,5 |
|||
System / Без ответа |
3 |
0,4 |
|||
Total / Итого |
160 |
20,0 |
|||
Total / Итого |
802 |
100,0 |
|||
Из табл. 3.2 видно, что при большом количестве отсутствующих значений разница между Percent / Процент и Valid Percent / Валидный процент значительно увеличивается.
Так, если среди всех опрошенных удельный вес испытывающих чувство тревоги составляет 37,4 %, то среди ответивших на данный вопрос эта группа респондентов составляет уже 46,7 %. Подобное расхождение в значениях рассмотренных показателей появляется, как правило, при анализе частных подвыборок.
Вопрос о том, какой из показателей – процент от числа опрошенных или процент от числа ответивших, необходимо использовать для выявления социологических закономерностей, является некорректным. Оба эти показателя несут определенную информацию, но их интерпретация существенно различается.
Так, например, в ходе опроса мы выяснили, что за кандидата А собирается голосовать 20 % от числа опрошенных и 40 % от числа ответивших. Оба показателя представляют интерес. Первое число говорит нам о том, что 20 % от общего количества взрослого населения собирается поддержать кандидата А на выборах. В тоже время число 40 % говорит нам о том, сколько процентов может набрать кандидат А в ходе голосования, так как коды пропущенных данных в таких опросах получают респонденты, не собирающиеся участвовать в выборах.
Форматы частотных таблиц. При построении таблиц частотного распределения в SPSS
можно задать определенный формат вывода данных. Для этого в диалоговом окне «Frequencies / Частота» (рис. 3.1) нажмите на клавишу «Format / Формат», расположенную в нижней его части. В результате откроется новое окно (рис. 3.2).
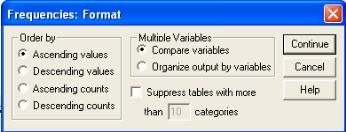
Рис. 3.2. Диалоговое окно «Frequencies / Частота : Format / Формат»
В левой части окна расположена группа команд Order by (Сортировать по / Упорядочить по), где можно выбрать порядок, в котором будут отображены значения в частотной таблице. Здесь возможны следующие варианты:
«Ascending values» (данные располагаются в порядке возрастания значений признака). Эта настойка стоит изначально по умолчанию.
«Descending values» (данные располагаются в порядке уменьшения значений признака).
«Ascending counts» (данные располагаются в порядке возрастания частот).
«Descendin counts» (данные располагаются в порядке уменьшения частот).
Например, при построении таблицы частотного распределения активизируем функцию «Descendin counts» (данные располагаются в порядке уменьшения частот). Таблица будет представлена в следующем виде (табл. 3.3).
Таблица 3.3. Распределение ответов респондентов на вопрос «Какие чувства Вы испытываете, когда думаете о ближайшем будущем?» в порядке уменьшения частот (фрагмент приложения программы SPSS).