

Тема 6.2. Режимы адресации данных памяти
90% работы процессора связано с оперативной памятью. Он берет оттуда данные, обрабатывает их и отсылает обратно в память. Кроме этого, сам процессор имеет собственную память, называемую регистрами. Графически это можно изобразить так:
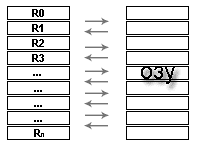
Рис.31 Регистры процессора
где слева регистры процессора R1, R2 … Rn, а справа ячейки памяти. В процессор поступают несколько операндов с которыми надо произвести некоторые действия. Но для того чтобы происходил обмен между процессором и оперативной памятью нужно использоать несколько режимов адресации. Но для начала нужно знать о формате команды. Под форматом команды понимают совокупность размера всех полей и их расположения в команде. Представим себе упрощенный вид команды:
![]()
Рис.32 Упрощенный вид команды
Команда делится на две области: область кода операции и область адресов. Вначале идет код операции (КОП) который говорит, что вообще необходимо делать, а затем идет адрес операнда/операндов с которым/которыми это надо делать. Адресная область может состоять из нескольких частей – это, так называемые многоадресные команды.
Адресная область состоит из трех полей: в первых двух лежат адреса операндов, а в третье будет записан адрес результата действия над операндами.
В двухадресных командах адресная область состоит из двух полей: поле адреса первого операнда и поле адреса второго операнда. Адрес результата действия над операндами будет записан в первое поле.

Рис.33 Адрес результата действия
В одноадресных командах адресная область состоит из одного единственного поля, в котором лежит адрес операнда, а адрес второго операнда и результата совпадает с сумматором. Существуют так же и безадресные команды, которые применяются при работе со стеками. Чаще всего используются двух-, одно- и безадресные команды.
Для того, чтобы процессор нашел нужные операнды, в поле адреса операнда вкладывают … адрес операнда (то есть тот адрес, по которому, обратившись, процессор найдет операнд или, проще говоря, необходимые данные).
Существует несколько типов адресации. Начнем с непосредственной адресации –когда вместо адреса операнда в команде указывается сам операнд (правда, если он представляет целое число). Выбрав из памяти код операции, процессору уже нет необходимости лезть опять в память за самим операндом, ведь он передается вместе с КОП.
![]()
Рис.34 Непосредственная адресация
Но такое не всегда бывает. Если в команде указан полный адрес ячейки, где лежат необходимые данные, то это уже полный или абсолютный тип адресации.
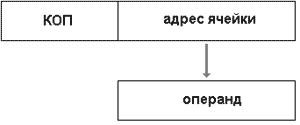
Рис.35 Полный или абсолютный тип адресации
Кроме этого, в поле адреса операнда может быть указан адрес или регистра или ячейки памяти, в которой лежит то же адрес, по которому можно найти ячейку с нужным операндом.
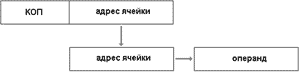
Рис.36 Ячейка с нужным операндом
Такой способ адресации называться косвенным. При косвенной адресации количество ячеек с адресами других ячеек может быть несколько (цепочка).
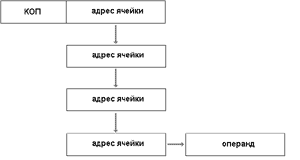
Рис.37 Косвенная адресация
Количество звеньев (или ступеней перехода) называется глубиной косвенной адресации.
Все выше приведенные типы адресации касались одного операнда. А как же быть в случае с несколькими операндами, т.е массивами? Тогда обычно указывается адрес массива и номер (индекс) элемента. Базовый (начальный) адрес указывается в команде. Кроме этого, там же, в команде, есть поле, где указан номер регистра, в котором лежит значение индекса или номер ячейки в массиве относительно начального адреса. Тогда адрес каждой ячейки массива будет получаться из суммы начального адреса и того, что содержит указанный регистр, это называется модификацией адресов. Кроме того, существует тип адресации, когда в регистре лежит начальный адрес. В команде указан адрес этого регистра, а так же записано смещение относительно начального адреса. Все остальные адреса операндов будут получены из суммы адреса и смещения. Такой вот тип адресации называется относительным.
При относительной адресации можно еще и модифицировать адреса. В этом случае адрес будет равен сумме начального адреса плюс смещение плюс содержимое индексного регистра.
Если система использует несколько типов адресации, то в команде обязательно записывается, какой способ будет применен в данный момент, т.е в команде указывается признак адресации в поле признака операции.
Способы организации памяти. Адресная память
Функционально ЗУ любого типа всегда состоят из запоминающего массива, хранящего информацию, и вспомогательных, весьма сложных блоков, служащих для поиска в массиве, записи и считывания (и, если требуется, для регенерации).
Запоминающий массив (ЗМ) состоит из множества одинаковых запоминающих элементов (ЗЭ). Все ЗЭ организованы в ячейки, каждая из которых предназначена для хранения единицы информации в виде двоичного кода, число разрядов которого определяется шириной выборки. Способ организации памяти зависит от методов размещения и поиска информации в ЗМ. По этому признаку различают адресную, ассоциативную и стековую память.
Адресная память
В памяти с адресной организацией размещение и поиск информации в ЗМ основаны на использовании адреса хранения единицы информации, которую в дальнейшем для краткости будем называть словом. Адресом служит номер ячейки ЗМ, в которой это слово размещается. При записи (считывании) слова в ЗМ инициирующая эту операцию команда должна указывать адрес (номер) ячейки, по которому надо произвести запись (считывание).
На рис. 4.2 изображена обобщенная структура адресной памяти.
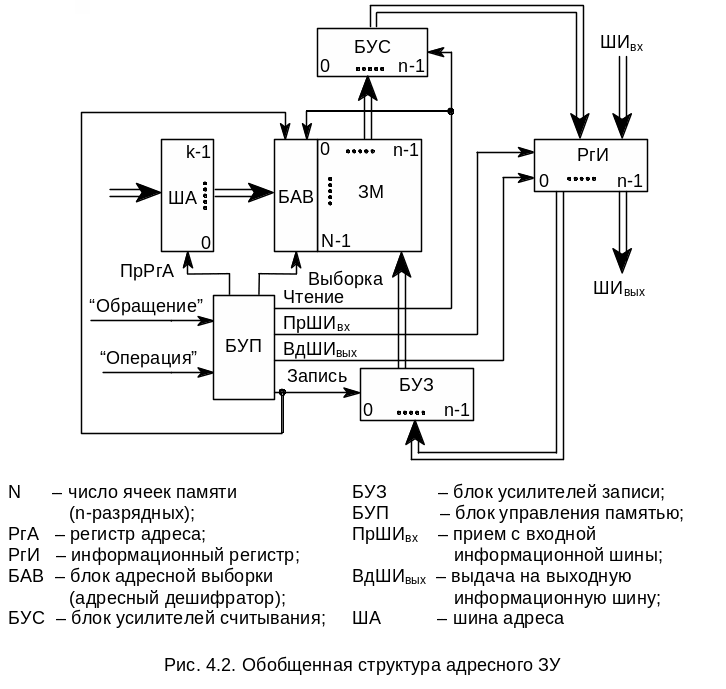
Цикл обращения к памяти инициализируется поступающим в БУП сигналом "Обращение". Общая часть цикла обращения включает в себя прием в РгА с шины адреса (ША) адреса обращения и прием в БУП управляющего сигнала "Операция", указывающего вид запрашиваемой операции (считывание или запись).
Считывание. БАВ дешифрирует адрес и посылает сигнал, выделяющий заданную адресом ячейку ЗМ. В общем случае БАВ может также посылать в выделенную ячейку памяти сигналы, настраивающие ЗЭ ячейки на запись или считывание. После этого записанное в ячейку слово считывается усилителями БУС и передается в РгИ. Затем в памяти с разрушающим считыванием происходит регенерация информации путем записи слова из РгИ через БУЗ в ту же ячейку ЗМ. Операция считывания завершается выдачей слова из РгИ на выходную информационную шину ШИвых.
Запись. Помимо указанной выше общей части цикла обращения происходит прием записываемого слова с входной шины ШИвх в РгИ. Сама запись в общем случае состоит из двух операций – очистки ячейки и собственно записи. Для этого БАВ сначала производит выборку и очистку ячейки, заданной адресом в РгА. Очистка ячейки ЗМ (приведение в исходное состояние) может осуществляться по-разному. В частности, в памяти с разрушающим считыванием очистку можно производить сигналом считывания слова в ячейке при блокировке БУС (чтобы в РгИ не поступила информация). Затем в выбранную ячейку записывается новое слово.
Необходимость в операции очистки ячейки перед записью, так же как и в операции регенерации информации при считывании, определяется типом используемых ЗЭ, способами управления, особенностями электронной структуры БИС памяти, поэтому в полупроводниковых памятях эти операции могут отсутствовать.
БУП генерирует необходимые последовательности управляющих сигналов, инициирующих работу отдельных узлов памяти. Следует иметь в виду, что БУП может быть весьма сложным устройством (своеобразным управляющим контроллером, имеющим собственную кэш-память), придающим БИСу памяти в целом специальные потребительские свойства, такие как многопортовость, конвейерная выдача информации и т.п.
Ассоциативная память
В памяти этого типа поиск информации происходит не по адресу, а по ее содержанию. Под содержанием информации в данном случае понимается не смысловая нагрузка лежащего на хранении в ячейке памяти слова, а содержание ЗЭ ячейки памяти, т.е. побитовый состав записанного двоичного слова. При этом ассоциативный запрос (признак) также представляет собой двоичный код с определенным побитовым составом. Поиск по ассоциативному признаку происходит параллельно во времени для всех ячеек ЗМ и представляет собой операцию сравнения содержимого разрядов регистра признака с содержимым соответствующих разрядов ячеек памяти. Для организации такого поиска все ЗЭ ЗМ снабжены однобитовыми процессорами, поэтому в ряде случаев память такого типа рассматривают как многопроцессорную систему.
Полностью ассоциативная память большого объема является очень дорогостоящим устройством, поэтому для ее удешевления уменьшают число однобитовых процессоров до одного на ячейку памяти. В этом случае сравнение ассоциативного запроса с содержимым ячеек памяти идет последовательно для отдельных разрядов, параллельно во времени для всех ячеек ЗМ.
При очень больших объемах памяти на определенных классах задач ассоциативный поиск существенно ускоряет обработку данных и уменьшает вероятность сбоя в ЭВМ. Кроме того, ассоциативные ЗУ с блоками соответствующих комбинационных схем позволяют выполнить в памяти достаточно сложные логические операции: поиск максимального или минимального числа в массиве, поиск слов, заключенных в определенные границы, сортировку массива и т.д.
Следует отметить, что ассоциативный поиск можно реализовать и в компьютере с обычной адресной памятью, последовательно вызывая записанные в ячейки памяти слова в процессор и сравнивая их с некоторым ассоциативным признаком (шаблоном). Однако при больших объемах памяти на это будет затрачено много времени. При использовании ассоциативной памяти можно, не считывая слов из ОП в процессор, за одно обращение определить количество слов, отвечающих тому или иному ассоциативному запросу. Это позволяет в больших базах данных очень оперативно реализовать запрос типа: сколько жителей области не представило декларацию о доходах и т.п.
В некоторых специализированных ЭВМ ОП или его часть строится таким образом, что позволяет реализовать как ассоциативный, так и адресный поиск информации.

Упрощенная структурная схема ассоциативной памяти, в которой все ЗЭ ЗМ снабжены однобитовыми процессорами, приведена на рис. 4.3.
Первоначально рассмотрим операцию, называющуюся контроль ассоциации. Эта операция является общей для операции считывания и записи, а также имеет самостоятельное значение.
По входной информационной шине в РгАП поступает n-разрядный ассоциативный запрос, т.е. заполняются разряды от 0 до n-1. Одновременно в РгМ поступает код маски поиска, при этом n-й разряд РгМ устанавливается в 0. Ассоциативный поиск производится лишь для совокупности разрядов РгАП, которым соответствуют 1 в РгМ (незамаскированные разряды РгАП). Для слов, в которых цифры в разрядах совпали с незамаскированными разрядами РгАП, КС устанавливает 1 в соответствующие разряды РгСв и 0 в остальные разряды.
Комбинационная схема формирования результата ассоциативного обращения ФС формирует из слова, образовавшегося в РгСв, как минимум три сигнала:
0 – отсутствие в ЗМ слов, удовлетворяющих ассоциативному признаку;
1 – наличие одного такого слова;
2 – наличие более чем одного слова.
Возможны и другие операции над содержимым РгСв, например подсчет количества единиц, т.е. подсчет слов в памяти, удовлетворяющих ассоциативному запросу, и т.п.
Формирование содержимого РгСв и 0, 1, 2 по содержимому РгАП, РгМ, ЗМ и называется операцией контроля ассоциации.
Считывание. Сначала производится контроль ассоциации по признаку в РгАП.
Затем:
0 = 1 – считывание отменяется из-за отсутствия искомой информации;
1 = 1 – считывается в РгИ найденное слово, после чего выдается на ШИвых;
2 = 1 – считывается слово, имеющее, например, наименьший номер среди ячеек, отмеченных 1 в РгСв, после чего выдается на ШИвых.
Запись. Сначала отыскивается свободная ячейка (полагаем, что в разряде занятости свободной ячейки записан 0). Для этого выполняется контроль ассоциации при РгАП=111...10 и РгМ=000...01, т.е. n-й разряд РгАП устанавливается в 0, а n-й разряд РгМ – в 1. При этом свободная ячейка отмечается 1 в РгСв. Для записи выбирают свободную ячейку, например, с наименьшим номером. В нее записывается слово, поступившее с ШИвх в РгИ.
Следует отметить, что на данной схеме не изображены блоки БУП, БУС, БУЗ, которые есть в реальных устройствах. Кроме того, для построения ассоциативной памяти требуются запоминающие элементы, допускающие считывание без разрушения.
Стековая память (магазинная)
Стековая память, так же как и ассоциативная, является безадресной. Стековая память может быть организована как аппаратно, так и на обычном массиве адресной памяти.
В случае аппаратной реализации ячейки стековой памяти образуют одномерный массив, в котором соседние ячейки связаны друг с другом разрядными цепями передачи слов (рис. 4.4). При этом возможны два типа устройств (а, б), принципы функционирования которых различны. Рассмотрим первоначально структуру на рис. 4.4, а.

Запись нового слова, поступившего с ШИвх, производится в верхнюю (нулевую) ячейку, при этом все ранее записанные слова (включая слово в ячейке 0) сдвигаются вниз, в соседние ячейки, номера которых на единицу больше. Считывание возможно только из верхней (нулевой) ячейки памяти. Основной режим – это считывание с удалением. При этом все остальные слова в памяти сдвигаются вверх, в соседние ячейки с меньшими номерами. В такой памяти реализуется правило: последний пришел – первый ушел. Стеки подобного типа принято называть стеками LIFO (Last In – First Out).
В ряде случаев устройства стековой памяти предусматривают также операцию простого считывания слова из ячейки 0 без его удаления и сдвига остальных слов. При использовании стека для запоминания параметров инициализации контроллеров каких-либо устройств ЭВМ обычно предусматривается возможность считывания содержимого любой ячейки стека без его удаления, т.е. считывание содержимого не только ячейки 0.
О первом слове, посылаемом в стек, говорят, что оно располагается на дне стека. О последнем посланном (по времени) в стек слове говорят, что оно находится в вершине стека. Таким образом, ячейка N-1 – дно стека, а ячейка 0 – вершина.
Обычно аппаратный стек снабжается счетчиком стека СчСт, показывающим общее количество занесенных в память слов (СчСт = 0 – стек пустой). При заполнении стека полностью он запрещает дальнейшие операции записи.
Стековый принцип организации памяти можно реализовать не только в специально предназначенных для этого устройствах. Стековая организация данных возможна и на обычной адресной памяти с произвольным обращением (программный стек). Для организации стека LIFO в этом случае необходима еще одна ячейка памяти (регистр), в которой всегда хранится адрес вершины стека и которая называется указателем стека. Обычно в качестве указателя стека используют один из внутренних регистров процессора. Кроме этого, требуется соответствующее программное обеспечение. Принципы стековой организации данных на обычной адресной памяти иллюстрируются схемой на рис. 4.5.
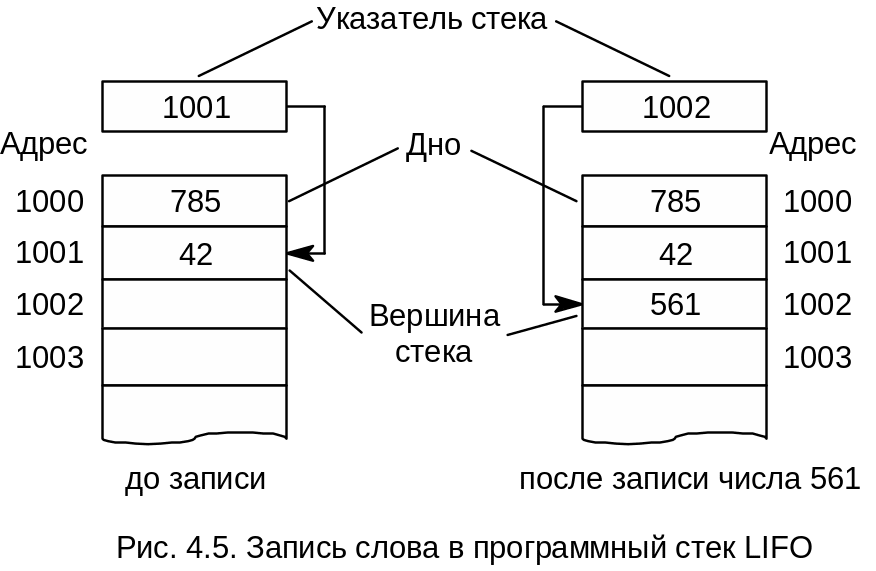
В отличие от аппаратного стека данные, размещенные в программном стеке, при записи нового числа или считывании не перемещаются. Запись каждого нового слова осуществляется в ячейку памяти, следующую по порядку за той, адрес которой содержится в указателе стека. После записи нового слова содержимое указателя стека увеличивается на единицу (см. рис. 4.5). Таким образом, в программном стеке перемещаются не данные, а вершина стека. При считывании слова из стека происходит обратный процесс. Слово считывается из ячейки, адрес которой находится в указателе стека, после чего содержимое указателя стека уменьшается на единицу.
Если вновь загружаемые в стек слова размещаются в ячейках памяти с последовательно увеличивающимися адресами, стек называют прямым. Если адреса последовательно убывают, то – перевернутым. В большинстве случаев используется перевернутый стек, что связано с особенностями аппаратной реализации счетчиков внутри процессора.
Чем удобна такая форма организации памяти? Забегая вперед, можно отметить, что любая команда, выполняемая в процессоре, в общем случае должна содержать код операции (КОП), адрес первого и второго операндов и адрес занесения результата. Для экономии памяти и сокращения времени выполнения машинной команды процессором желательно уменьшить длину команды. Пределом такого уменьшения является длина безадресной команды, т.е. просто КОП. Именно такие команды оказываются возможными при стековой организации памяти, так как при правильном расположении операндов в стеке достаточно последовательно их извлекать и выполнять над ними соответствующие операции.
Помимо рассмотренной выше стековой памяти типа LIFO в ЭВМ используются стековые памяти другого типа, реализующие правило: первый пришел – первый ушел. Стеки подобного типа принято называть стеками FIFO (First In – First Out). Такая стековая память широко используется для организации различного рода очередей (команд, данных, запросов и т.д.). Обобщенная структура аппаратного стека типа FIFO представлена на рис. 4.4, б.
Как и в предыдущем случае, ячейки стековой памяти образуют одномерный массив, в котором соседние ячейки связаны друг с другом разрядными цепями передачи слов. Запись нового слова, поступившего с ШИвх, осуществляется в верхнюю (нулевую) ячейку, после чего оно сразу перемещается вниз и записывается в последнюю по счету незаполненную ячейку. Если стек перед записью был пустой, слово сразу попадает в ячейку с номером N-1, т.е. на дно стека. Считывание возможно только из нижней ячейки с номером N-1 (дно стека). Основной режим – это считывание с удалением. При этом все последующие (записанные) слова сдвигаются вниз, в соседние ячейки, номера которых на единицу больше. При заполнении стека счетчик (СчСт) запрещает дальнейшие операции записи в стек.
Таким образом, в отличие от стека LIFO, в стеке FIFO перемещается не дно, а вершина. Записываемые в стек FIFO слова постепенно продвигаются от вершины ко дну, откуда и считываются по мере необходимости, причем темп записи и считывания определяются внешними управляющими сигналами и не связаны друг с другом.
Программная реализация стека FIFO в настоящем разделе не рассматривается, поскольку на практике используется достаточно редко.
Структуры адресных ЗУ. ЗУ типа 2D
Адресные ЗУ наиболее широко используются в современных ЭВМ для построения самых разнообразных устройств памяти. В процессе эволюции ЭВМ принципы построения и аппаратная реализация данных ЗУ прошли очень большой путь развития от первых ЗУ на электромагнитных реле до современных БИСов памяти емкостью в сотни Мбайт, которые в качестве ЗЭ используют либо разнообразные триггерные схемы на биполярных полупроводниках, либо МОП-структуры. При этом тип используемых ЗЭ влияет на структуру ЗУ. Кроме того, структура ЗУ во многом определяется особенностями его применения в конкретных устройствах ЭВМ. Все это привело к тому, что в процессе развития возникло весьма большое разнообразие структур ЗУ, которые различаются по способу организации, быстродействию, объему, аппаратурным затратам, стоимости.
Ранее отмечалось, что основной частью любой памяти является запоминающий массив (ЗМ), представляющий собой совокупность ЗЭ, соединенных определенным образом. ЗМ называют еще запоминающей матрицей. Каждый ЗЭ хранит бит информации и должен реализовывать следующие режимы работы:
хранение состояния (0 или 1);
выдачу сигнала состояния (считывание);
запись информации (0 или 1).
К ЗЭ должны поступать управляющие сигналы для задания режима работы, а также сигналы при записи. При считывании ЗЭ должен выдавать сигнал о своем состоянии, поэтому любой ЗМ имеет систему адресных и разрядных линий (проводников).
Адресные линии используются для выделения по адресу совокупности ЗЭ, которым устанавливается режим считывания или записи. Число ЗЭ, входящих в эту совокупность, равно ширине выборки. Иными словами, с помощью адресных линий происходит выбор необходимой ячейки памяти. Разрядные линии используются для записи или считывания информации в ЗЭ каждого разряда ячейки памяти.
Адресные и разрядные линии носят общее название линий выборки. В зависимости от числа таких линий, соединенных с одним ЗЭ, различают двух-, трехкоординатные ЗУ и т.д., называемые ЗУ типа 2D, 3D, 2.5D, 2D-M (от слова dimension – размерность), и их разнообразные модификации.
ЗУ типа 2D
Организация ЗУ типа 2D обеспечивает двухкоординатную выборку каждого ЗЭ ячейки памяти. Основу ЗУ составляет плоская матрица из ЗЭ, сгруппированных в 2k ячеек по n разрядов. Обращение к ячейке задается k-разрядным адресом, что дает одну координату. Выделение разрядов производится разрядными линиями записи и считывания, что дает вторую координату. Очень упрощенная структура ЗУ типа 2D представлена на рис. 4.6.
А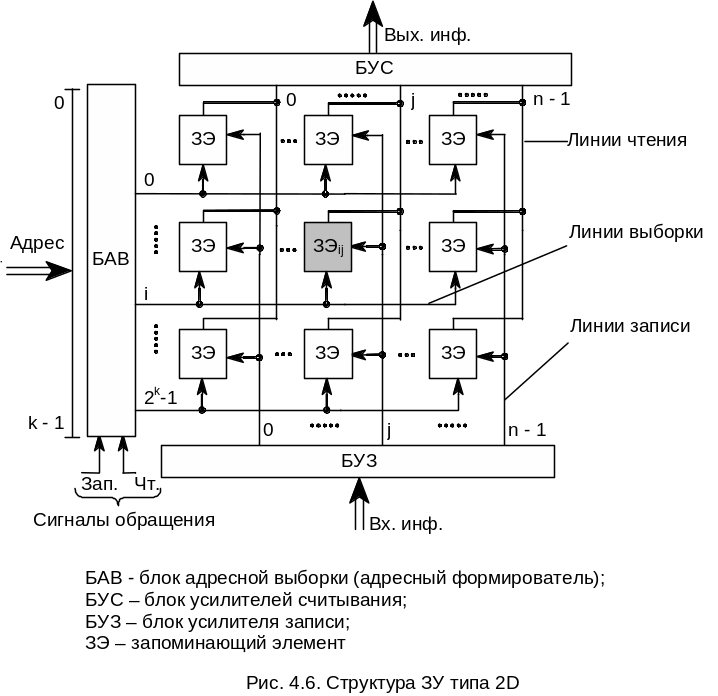 дрес
из k разрядов поступает на блок адресной
выборки БАВ (который называют также
адресным формирователем), управляемый
сигналами Чт и Зап. Основу БАВ составляет
дешифратор с 2k
выходами, который при поступлении на
его вход адреса формирует сигнал для
выбора линии i. В зависимости от сигнала
Чт или Зап БАВ в общем случае выдает
сигнал, настраивающий ЗЭ i-й ячейки (i-й
линии) на чтение либо на запись. Выделение
разряда j в i-м слове (ЗУ серого цвета)
производится второй координатной
линией. При записи по линии j от БУЗ
поступает сигнал, устанавливающий
выбранный для записи ЗЭi,j
в состояние 0 или 1. При считывании на
БУС по линии j поступает сигнал о состоянии
ЗЭi,j.
дрес
из k разрядов поступает на блок адресной
выборки БАВ (который называют также
адресным формирователем), управляемый
сигналами Чт и Зап. Основу БАВ составляет
дешифратор с 2k
выходами, который при поступлении на
его вход адреса формирует сигнал для
выбора линии i. В зависимости от сигнала
Чт или Зап БАВ в общем случае выдает
сигнал, настраивающий ЗЭ i-й ячейки (i-й
линии) на чтение либо на запись. Выделение
разряда j в i-м слове (ЗУ серого цвета)
производится второй координатной
линией. При записи по линии j от БУЗ
поступает сигнал, устанавливающий
выбранный для записи ЗЭi,j
в состояние 0 или 1. При считывании на
БУС по линии j поступает сигнал о состоянии
ЗЭi,j.
Следует иметь в виду, что ЗЭ должны допускать объединение выходов для работы на общую линию с передачей сигналов только от выбранного ЗЭ. Это свойство ЗЭ используется во всех современных ЗУ.
Таким образом, каждая адресная линия выборки ячейки памяти в общем случае передает три сигнала:
выборка при записи;
выборка при считывании;
отсутствие выборки.
Однако во многих современных ЗУ достаточно только двух сигналов – выборка и отсутствие выборки.
Каждая разрядная линия записи передает в ЗЭ записываемый бит информации, а разрядная линия считывания – считываемый из ЗЭ бит информации. Линии записи и считывания могут быть объединены в одну при использовании ЗЭ, допускающих соединение выхода со входом записи. В современных ЗУ широко используются совмещенные функции линий считывания и записи.
ЗУ типа 2D являются быстродействующими и достаточно удобными для реализации. Однако такие ЗУ неэкономичны по объему оборудования из-за наличия дешифратора на 2k выходов. В настоящее время структуры типа 2D используются, в основном, в ЗУ небольшой емкости (не более 1 К).
ЗУ типа 3D
Для построения ЗУ больших объемов используют другую схему и другие типы ЗЭ, которые имеют не один, а два конъюнктивно связанных входа выборки. В этом случае адресная выборка осуществляется только при одновременном появлении двух сигналов. Использование таких ЗЭ позволяет строить ЗУ с трехкоординатным выделением ЗЭ. Итак, ЗУ типа 3D отличается от 2D тем, что к каждому ЗЭ подходят три линии выборки: две координатные и одна разрядная.
Запоминающий
массив ЗУ типа 3D представляет собой
пространственную матрицу, составленную
из n плоских матриц. Каждая плоская
матрица представляет собой ЗМ для
запоминания j-х разрядов всех слов, т.е.
запоминающие элементы для одноименных
разрядов всех хранимых в ЗУ чисел
сгруппированы в квадратную матрицу из
![]() рядов по
ЗЭ в каждом. Это означает, что к записи
или считыванию готов только тот элемент,
для которого сигналы адресной выборки
по координатам X и Y совпали. Для адресной
выборки ЗЭ в плоской матрице необходимо
задать две его координаты в ЗМ.
рядов по
ЗЭ в каждом. Это означает, что к записи
или считыванию готов только тот элемент,
для которого сигналы адресной выборки
по координатам X и Y совпали. Для адресной
выборки ЗЭ в плоской матрице необходимо
задать две его координаты в ЗМ.
Структура матрицы j-го разряда в ЗУ типа 3D представлена на рис. 4.7. Код адреса i-й ячейки памяти разделяется на старшую и младшую части, каждая из которых поступает на свой адресный формирователь. Адресный формирователь БАВ1 выдает сигнал выборки на линию i', а БАВ2 – на линию i''. В результате в ЗМ оказывается выбранным ЗЭ, находящийся на пересечении этих линий (двух координат), т.е. адресуемый кодом i=i' / i'' (ЗЭ серого цвета). Адресные формирователи управляются сигналами Чт и Зап и в зависимости от них выдают сигналы выборки для считывания или для записи. При считывании сигнал о состоянии выбранного ЗЭ поступает по j-линии считывания к БУС (третья координата ЗЭ при считывании). При записи в выбранный ЗЭ будет занесен 0 или 1 в зависимости от сигнала записи в j-й разряд, поступающего по j-й линии от БУЗ (третья координата ЗЭ при записи). Для полупроводниковых ЗУ характерно объединение в одну линию разрядных линий записи и считывания.
Для построения n-разрядной памяти используется n матриц рассмотренного вида. Адресные формирователи здесь могут быть общими для всех разрядных ЗМ.
Запоминающие
устройства типа 3D более экономичны по
оборудованию, чем ЗУ типа 2D. Действительно,
сложность адресного формирователя с m
входами пропорциональна 2m,
отсюда сложность двух адресных
формирователей ЗУ типа 3D, пропорциональная
![]() ,
значительно меньше сложности адресного
формирователя ЗУ типа 2D, пропорциональной
2k.
Поэтому структура типа 3D позволяет
строить ЗУ большего объема, чем структура
2D.
,
значительно меньше сложности адресного
формирователя ЗУ типа 2D, пропорциональной
2k.
Поэтому структура типа 3D позволяет
строить ЗУ большего объема, чем структура
2D.
С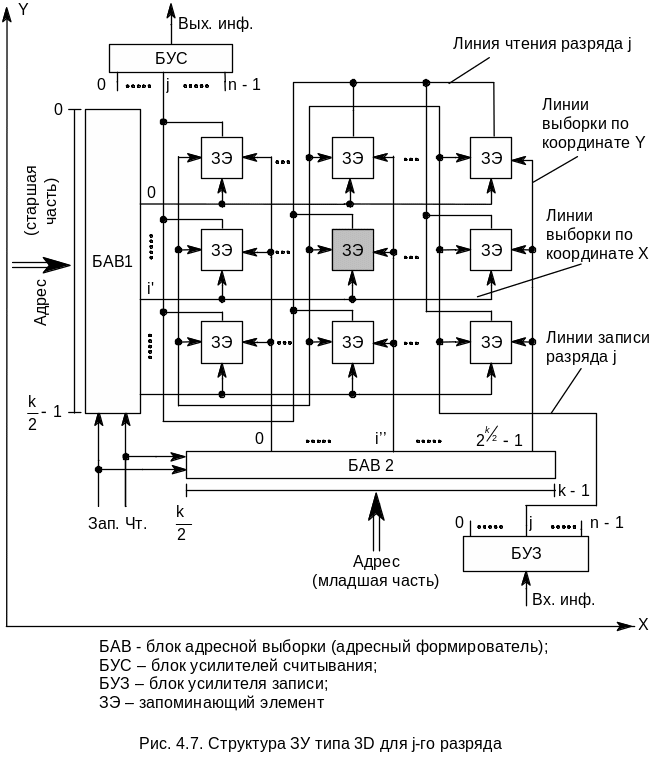 труктура
типа 3D является наиболее удобной для
построения статических ЗУ на многоэмиттерных
биполярных транзисторах.
труктура
типа 3D является наиболее удобной для
построения статических ЗУ на многоэмиттерных
биполярных транзисторах.
Динамическая память
Элемент памяти, микросхема памяти, модуль памяти, графическая память
Динамическая память - DRAM (Dynamic RAM) - получила свое название от принципа действия элемента памяти, хранящего один бит информации. Запоминающим элементом служит конденсатор, являющийся емкостью перехода исток - сток полевого транзистора. При записи логической единицы в элемент памяти конденсатор заряжается, при записи нуля - разряжается. При чтении информации конденсатор тоже разряжается и, если заряд был не нулевым, усилитель считывания устанавливает на выходе единичное значение потенциала, и конденсатор специальной схемой перезаписи снова заряжается до потенциала логической единицы. При отсутствии обращения к элементу динамической памяти со временем, за счет токов утечки, конденсатор разряжается и информация теряется, поэтому такая память требует постоянного периодического перезаряда конденсаторов методом перезаписи каждого элемента (регенерации). Следовательно, память может работать только в динамическом режиме, с постоянным перезарядом конденсаторов ячеек памяти. Этим она принципиально отличается от статической памяти, реализуемой на триггерных ячейках и хранящей информацию без обращений к ней статично, сколь угодно долго при включенном питании. Благодаря относительной простоте ячейки динамической памяти, на одном кристалле удается размещать миллионы ячеек и получать сравнительно недорогую полупроводниковую память, пускай и недостаточно высокого быстродействия, но с умеренным энергопотреблением. Используется динамическая память в качестве оперативной памяти компьютера и оперативной памяти видеоадаптера.
Работа запоминающего элемента динамической памяти
Микросхема динамической памяти состоит из миллионов элементов, каждый из которых хранит всего один бит информации. На физическом уровне элементы памяти объединяются в прямоугольную матрицу, горизонтальные линейки элементов называются строками (ROW), а вертикальные - столбцами (Column). Элементы всей строки матрицы могут считываться в современных микросхемах динамической памяти в буферный регистр - этот набор ячеек принято называть страницей (Page). Из-за высокой интеграции микросхем памяти становится невозможным обратиться к ячейке памяти, установив на шине адреса адрес ячейки памяти полностью. Слишком много разрядов должна иметь эта шина. Поэтому шину адреса делают в два раза уже и устанавливают адрес дважды. Сначала адрес строки, затем адрес столбца. Чтобы различать, установка какой части адреса происходит вводятся дополнительные сигналы управления RAS и CAS. Адрес строки передается по шине адреса и принимается в регистр адреса строки микросхемы памяти по спаду импульса RAS (Row Access Strobe). Адрес колонки передается по этой же шине и принимается в регистр адреса колонки микросхемы памяти по спаду импульса CAS (Column Access Strobe). На пересечении линии строки и колонки находится элемент памяти. Поскольку обращение (запись или чтение) к различным ячейкам памяти обычно происходит в случайном порядке, то для поддержания сохранности данных производится регулярная регенерация (Memory Refresh - "освежение" памяти) - регулярный циклический перебор ячеек памяти с холостыми циклами перезаписи. Регенерация в микросхеме происходит одновременно по всей строке матрицы при обращении к любой из ее ячеек. Если динамическая память используется в видеобуферах графических адаптеров, то специальных циклов регенерации такая память не требует т.к. частота ее чтения для воспроизведения изображения на экране видеомонитора вполне достаточна для сохранения информации при чтении и сопровождающей чтение перезаписи. Частоту регенерации можно определить следующим образом, если ток утечки составляет 0.1 нА, а емкость конденсатора порядка 0,1 пф, время разряда конденсатора на 1 вольт произойдет за время t порядка одной миллисекунды. Если считать такое падение напряжения максимально допустимым, то для выдачи состояния низкого или высокого уровня необходимо осуществлять периодическое восстановление информации (или ее регенерацию) с периодом t ref <=1мс. Таким образом, максимальный период обращения к каждой строке TRF (refresh time) для гарантированного сохранения информации должен быть менее 1мс. Микросхемы динамической памяти строятся на основе биполярных МОП- транзисторов. Элемент динамической памяти на МОП- структурах показан на рис.1. В основе запоминающего элемента лежит один конденсатор С1 и один МОП- транзистор VT1. На схеме конденсатор показан в виде отдельного элемента, хотя реально его функции выполняет емкость затвор-подложка. Транзистор VT2 открывается сигналом ТС=1 и от источника U0 емкость СШ заряжается до напряжения U0.
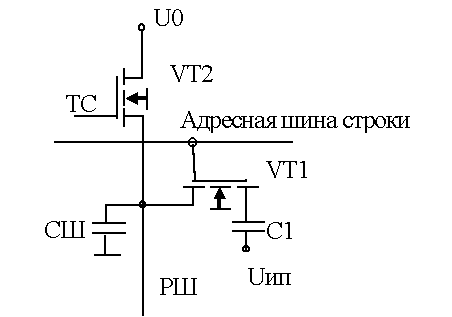
Рис.1. Элемент динамической памяти на МОП- структурах.
При выборке данных транзистор VT1 выполняет функции ключа: при подаче сигнала на шину адреса строки он открывается и соединяет запоминающий конденсатор С1 с шиной столбца РШ (разрядной шиной). Емкость запоминающего конденсатора 0.1-0.2 пф, что значительно меньше емкости конденсатора шины (СШ), поэтому возникает незначительное изменение потенциала шины, которое усиливается при считывании информации высокочувствительными дифференциальными усилителями. На вход дифференциального усилителя подается напряжение разрядной шины и опорное напряжение для определения разности. Опорный элемент построен аналогично запоминающему, он поддерживает опорное напряжение U0. В каждом столбце матрицы памяти расположены усилители, к которым подключаются элементы памяти и элементы, поддерживающие опорное напряжение. Считан может быть сигнал только с одного элемента памяти столбца, ключи остальных элементов в это время закрыты, но открыты все элементы строки. При этом заряды всей строки поступают на усилители и через некоторое время могут быть считаны. Такая операция называется активизацией строки. Сигнал с выхода чувствительного дифференциального усилителя подается на формирующий выходной сигнал триггер-усилитель, выполняющий также функции элемента, который автоматически осуществляет регенерацию информации. Еще раз подчеркнем, что регенерация информации в рассматриваемой схеме производится сразу во всей строке. Считывание информации происходит при при установке сигнала Read на шине управления, при директиве Write происходит запись информации. Пока строка остается активной, возможны считывание или запись и других ячеек памяти. После того, как истекает время активности строки происходит закрытие строки, которое сопровождается подзарядкой (Precharge) элементов памяти строки. Последующее считывание данных этой строки невозможно без ее повторной активизации (установки адреса строки). Микросхема динамической памяти
Главные особенности микросхем динамической памяти заключаются в следующем:
отсутствуют источники для питания элементов запоминающих ячеек;
необходимы логические схемы, обеспечивающие регенерацию информации;
максимально проста схема накопителя, обеспечивающая минимум занимаемой площади;
мала потребляемая мощность, поскольку динамический запоминающий элемент не потребляет тока в отрезки времени, когда к нему не происходит обращение. Для формирования внутренних сигналов, управляющих включением и выключением в определенной последовательности различных узлов микросхемы, в структуре микросхемы предусмотрена схема управления. Входные, выходные и управляющие сигналы микросхемы памяти: RAS (Row Adress Strobe) - строб адреса строки; CAS (Column Adress Strobe) - строб адреса столбца; W/R (запись/чтение); вход данных - DI; выход данных - DO. Микросхема имеет усилители считывания и регенерации в каждом столбце матрицы, регистр адреса, дешифраторы адреса строк и адреса столбцов, устройство управления и устройство ввода и вывода данных. Структура микросхемы приведена на рис.2.
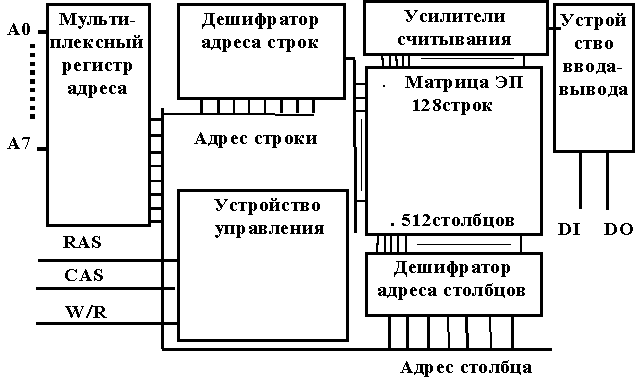
Рис.2. Структура микросхемы динамической памяти
На линиях RAS (row address strobe - строб адреса строки) и CAS (column address strobe - строб адреса столбца) в спокойном состоянии поддерживается высокий уровень сигнала, что означает, что никакой информации на адресных линиях нет и никаких действий, связанных с чтением или записью данных. В случае строчной регенерации, регенерация информации осуществляется путем обращения к каждой строке динамической памяти перебором строчных адресов в любом режиме работы. В современных микросхемах памяти регенерацию производит устройство регенерации, встроенное в микросхему памяти. Нарушение режима регенерации может привести к нарушению логических состояний микросхем памяти. Поэтому в схемах регенерации применяются защитные схемы, поддерживающие истинность логических состояний элементов матрицы микросхемы памяти совместно с генератором циклов регенерации. Микросхема подключается к шине адреса и данных. Линии адреса служат для выбора адреса ячейки памяти, а линии данных - для чтения или записи данных в память. Низкий уровень сигнала W/R готовит микросхему к считыванию состояния шины данных и записи полученной информации в соответствующую ячейку, а высокий, наоборот, заставляет считать содержимое ячейки и установить его на линиях шины данных. Использование одной и той же шины данных для вывода данных и для чтения данных позволяет в два раза уменьшить количество выводов шины данных. Это, как и уменьшение ширины шины адреса позволяет уменьшить размеры микросхемы, а значит, получить более высокие рабочие частоты. Рассмотрим, какие факты мешают повышению рабочей частоты микросхемы памяти: 1. Скорости распространения электрических сигналов ограничены, поэтому длины проводников, подведенных к различным ножкам микросхемы, не должны сильно отличаться друг от друга, иначе сигнал от одного вывода будет опережать сигнал от другого. 2. Длины проводников не должны быть очень велики, задержка распространения сигнала не позволит повысить быстродействие. 3. Любой проводник действует как приемная и как передающая антенна, создавая помехи. Уровень помех резко усиливается с ростом тактовой частоты. 4. Любой проводник обладает электрической емкостью. Чем больше емкость, тем меньше скорость передачи данных. Совмещение выводов шины для вывода и ввода данных увеличивает скорость обмена с памятью, но не позволяет осуществлять чтение и запись одновременно. Интересно, что в первых компьютерах специальная схема приостанавливала (прерывала) работу процессора на время регенерации, для управления процессом регенерации. На рис.2 приведена микросхема асинхронной динамической памяти, в которой разрядность данных - 1 бит. Далее мы узнаем как совершенствовалась память и чем отличается синхронная динамическая память от асинхронной. А сейчас поговорим об организации микросхем памяти и построении модулей памяти. Микросхемы памяти могут иметь и другую организацию. Например, распространенные (2006г.) микросхемы (чипы) синхронной динамической памяти DDR SDRAM фирмы Samsung : K 4 H 5 6 0 8 3 8 E — T C B 3 (рис.3) имеют емкость 36 мегабайт (256 мегабит). Адресуемая ячейка памяти чипа 8 битная.

Рис.3. Микросхема памяти DDR SDRAM фирмы Samsung
Для того, чтобы исключить ожидания при регенерации считанных данных, современные микросхемы памяти имеют несколько матриц. Последовательные обращения к данным при чтении будут происходить без задержек, если последовательные ячейки памяти расположены на разных матрицах. Таким образом можно избежать задержек на регенерацию при чтении последовательных данных. Рассматриваемая нами микросхема имеет 4 матрицы (допускает при построении модуля памяти использование четырех банков памяти).
Организация модуля памяти
Память, устанавливаемая в слоты (разъемы) расширения памяти персонального компьютера или других вычислительных систем, изготавливается в виде отдельных модулей. Модуль - маленькая печатная плата на которой размещены микросхемы памяти. На рис. 4 показан DIMM модуль памяти емкостью 256 мегабайт, построенный на микросхемах (чипах) K 4 H 5 6 0 8 3 8 E — T C B 3 (рис.3). 8 таких чипов устанавливается на одном модуле DDR DIMM и дают его полную емкость в 256 мегабайт.

Рис. 4. DDR DIMM модуль емкостью 256 мегабайт
Абревиатура DIMM (Dual In-Line Memory Module) означает - модуль памяти с двойным выводом контактов. DIMM модули имеют 64-х битные шины адреса и данных. Используя DIMM модули можно устанавливать всего одну плату памяти, так как чередование блоков памяти обеспечивается внутренней структурой микросхем. Организация микросхемы памяти K 4 H 5 6 0 8 3 8 E — T C B 3 8 бит - это разрядность ячейки памяти, следовательно восемь установленных на DIMM модуле микросхем обеспечивают в сумме 64 бита шины данных для всего модуля DDR DIMM. В микросхеме имеется четыре внутренних банка памяти, поэтому и модуль памяти имеет 4 банка памяти. Микросхемы (и модуль) требуют 2,5 вольт питания. DDR (Double Data Rate) - сокращение от Double Data Rate-Synchronous DRAM (синхронная DRAM с двойной скоростью передачи данных), тип синхронной памяти SDRAM. Она осуществляет пересылку данных два раза за такт – по восходящему и нисходящему фронту стробирующего синхросигнала , что удваивает скорость предачи данных. SDRAM (Synchronous DRAM) означает, что это микросхема синхронной динамической памяти, работающая синхронно с частотой работы центрального процессора, в результате чего исключаются режимы ожидания (простоя процессора). Время доступа к данным микросхемы K 4 H 5 6 0 8 3 8 E — T C B 3 составляет 6 нс., т.к. память синхронная, то обращение к данным происходит каждый такт, следовательно это память DDR 333. Она работает на частоте (1/6)109 = 166 МГц , пропускная способность памяти с учетом DDR определится так : ( (2*166) * 64) =21 Гбит/сек., или ((2*166)*8)= 2,6 Гбайт/сек.
Графическая память Для установки на видеокарты используется графическая DDR SGRAM память (рис.4).

Рис. 4. Микросхема графической DDR SGRAM памяти
128-мегабитный чип организация чипа х32 (32 разряда в слове), чип имеет 4 банка внутренней памяти. 2,5 В - напряжение питания чипа. 2,86 нс. - время доступа к данным. Рабочая частота составляет 350 МГц ( частота передачи данных — 700 МГц, т.к. память DDR).
Динамическая память FPM DRAM (Fast Page Mode ), временные диаграммы страничного чте6ния и записи
С увеличением частоты процессора, все более жесткие требования предъявляются к временным характеристикам памяти. В запоминающем устройстве, работавшем с процессором 80386 (16 МГц), время выборки данных соответствовало двум циклам процессора, т.е. составляло 2 х 62,5 нс. = 125 нс. Это означало, что для работы без периодов ожиданий достаточно было иметь запоминающее устройство с временем выборки 100 или даже 120 нс. Однако каждый раз, когда процессор осуществлял выборку данных из динамического запоминающего устройства требовалась перезапись содержимого памяти до того, как ее снова можно будет использовать. Для большинства динамических запоминающих устройств время перезаписи лишь немного меньше, чем время выборки. Кроме того, в динамических запоминающих устройствах требуется периодическая регенерация хранимой в памяти информации. На регенерацию уходит время, составляющее в среднем 6-12% от времени выборки. С учетом указанных обстоятельств фактическое быстродействие динамических запоминающих устройств определялось как время выборки 100 нс. + время перезаписи 90 нс. + дополнительное время на регенерацию. В сумме это составляло более 200 нс. А это означает, что в персональных компьютерах даже на базе микропроцессора 80386 с временем цикла 125 нс. применение динамического запоминающего устройства с временем выборки 100 нс. не позволяло обеспечить работу процессора с памятью без периодов ожиданий. Современные схемы динамической памяти имеют время выборки порядка 5 - 10 нсек., но по прежнему не могут обеспечить работу процессора без периодов ожидания, так как тактовая частота процессоров уже превышает 4 ГГц (длительность такта менее 0,25нсек.). Повышение быстродействия памяти достигается сегодня благодаря совершенствованию технологий и схемных решений. Обеспечение необходимого быстродействия системы процессор - память становится все более важным. Существует несколько способов повышения быстродействия системы процессор - память:
1. Расположить последовательные ячейки памяти в разных банках памяти;
2. Реализовать метод страничной выборки, который заключается в том, что при обращении к памяти задается адрес страницы (строки), а не отдельной ячейки памяти;
3. Организовать синхронную работу памяти и процессора за счет использования внутренней конвейерной архитектуры;
4. Включить в строку динамической памяти встроенный статический КЭШ;
5. Увеличить ширину шины;
6. Повысить тактовую частоту шины и увеличить время в тактах, в течение которого данные доступны для чтения.
При использовании первого метода уменьшение времени обращения к памяти достигается при помощи метода interleaving (чередование), суть которого заключается в том, что в подсистеме памяти организуется последовательное обращение к разным банкам памяти. В системных платах для 386 и 486 процессоров использовался контроль четности. Для выявления одиночной ошибки количество единиц в каждом байте дополнялось до четного значения. Поэтому модули памяти выпускались с дополнительным разрядом шины данных, отведенным для контроля четности. В типичных настольных персональных компьютерах контроль четности оказался избыточным и производители микросхем отказались от такого контроля. Модули DIMM допускают работу с современными процессорами при установке даже нечетного числа модулей, т.к. каждый DIMM модуль может включать в себя несколько банков памяти. В простейшей модели динамического ОЗУ имеются два банка: в одном банке размещены все байты с четными адресами, в другом с нечетными. Периодов ожидания не будет, если процессор выполняет команды, извлекаемые из последовательных адресов памяти. Если программа становится непоследовательной, такая ситуация возникает, например, когда имеют место условные или безусловные переходы, вероятность готовности банка к работе становится равной 50%. При последовательном переборе адресов, когда схема управления памятью находится в режиме ожидания данных, считываемых по следующему адресу памяти из первого банка, она устанавливает адрес данных во втором банке. Следующий адрес может считываться немедленно без периода ожидания. Если микропроцессор считывает 10 последовательных участков памяти, требуется один период ожидания только для первого считывания. В результате, среднее число периодов ожидания на весь цикл считывания будет равно 0,1. Подобная архитектура памяти обеспечивает работу динамического ОЗУ с быстродействующими процессорами, но при этом усложняется устройство управления памятью, что связано с необходимостью организации работы банков. Традиционный разрыв между скоростью работы памяти и процессора сокращается за счет внедрения новых технологий производства СБИС памяти. Долгое время наиболее распространенной была память, работающая в режиме быстрого страничного обмена (Fast Page Mode, или FPM DRAM). Эта память отличается тем, что после выбора строки удерживается сигнал RAS и допускается многократная установка адреса столбца по сигналу CAS, что позволяет организовать блочную передачу данных всей строки матрицы памяти, называемой страницей обмена. Из предыдущего описания работы элемента и микросхемы памяти мы знаем, что столбцы и строки матрицы памяти адресуются при помощи единых адресных линий. В случае квадратной матрицы количество адресных линий сокращается вдвое, но и выбор конкретной ячейки памяти отнимает вдвое больше тактов, ведь номера столбца и строки приходится передавать последовательно. Причем, возникает неоднозначность, что именно в данный момент находится на адресной линии: номер строки или номер столбца? Решение этой проблемы потребовало двух дополнительных выводов, сигнализирующих о наличии столбца или строки на адресных линиях RAS и CAS. Контроллер преобразует физический адрес ячейки памяти в номер строки и номер столбца, а затем посылает первый из них на адресные линии. Дождавшись, когда адресные сигналы стабилизируются, контроллер устанавливает низкий уровень на линии RAS, сообщая микросхеме памяти о наличии информации на линии. Микросхема считывает этот адрес и подает на соответствующую строку матрицы электрический сигнал. Все транзисторы, подключенные к этой строке, открываются и напряжения с конденсаторов подаются на входы чувствительных усилителей. Чувствительный усилитель строки сохраняет полученную информацию в специальном буфере. Когда микросхема завершает чтение строки в буфер и вновь готова к приему информации, контроллер подает на адресные линии номер колонки и, дав сигналам адреса колонки стабилизироваться, устанавливает на линии CAS низкий уровень. Устройство управления микросхемы памяти преобразует номер колонки в смещение ячейки внутри буфера. Остается установить уже подготовленные данные на линиях шины данных. Это занимает еще какое-то время, в течение которого контроллер ждет запрошенную информацию. На финальной стадии цикла обмена контроллер считывает состояние линий данных, cнимает сигналы RAS и CAS, устанавливая высокий потенциал, а микросхема становится недоступной на время восстановительной перезаписи строки и необходимую регенерацию. Задержка между подачей номера строки и номера столбца называется "RAS to CAS delay" ( tRCD). Задержка между подачей номера столбца и получением содержимого ячейки на выходе "CAS delay" ( tCAC), а задержка между чтением последней ячейки и подачей номера новой строки "RAS precharge" (tRP).
Рассмотрим работу микросхемы памяти при чтении/записи одного слова (рис.1). На шине адреса контроллер памяти установил адрес строки, затем сигнал RAS, по перепаду адрес принят микросхемой памяти и контроллер памяти устанавливает адрес столбца на шине адреса, затем сигнал CAS, по которому адрес столбца будет принят микросхемой памяти. В результате будет получен доступ к ячейке памяти, которая находится на пересечении строки и столбца. По сигналу WR/RD данные будут прочитаны, или записаны в ячейку памяти. На установку и прием каждого адреса необходимо 3 такта системной шины. Поэтому доступ к данным возможен только после 6 тактов системной шины.
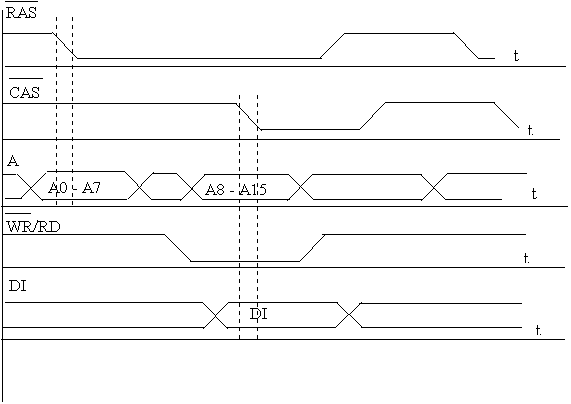
Рис.1. Временная диаграмма режима записи/чтения одного слова (при чтении на линии WR/RD высокий потенциал).
Страничное чтение производится при активизации строки за счет удержания сигнала RAS. Строка остается активной на все время чтения страницы памяти ( четырех последовательно расположенных слов), что увеличивает скорость чтения из памяти. Например цикл чтения в пакетном режиме четырех ячеек памяти типа FPM может выполняться с затратой шести тактов (установка и дешифрация адреса строки, установка и дешифрация адреса столбца) на чтение первого слова и трех тактов на каждое из следующих трех слов. (рис.2).
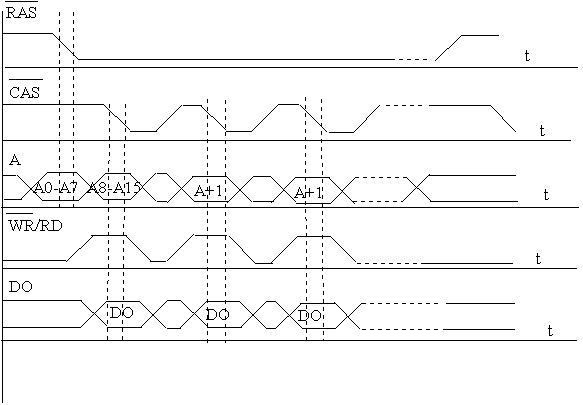
Рис. 2. Временные диаграммы страничного режима записи (чтения).
При работе с обычной DRAM (рис.1) после считывания данных сигнал RAS деактивируется, подготавливая микросхему к новому циклу обмена. В памяти FPM-DRAM контроллер удерживает сигнал RAS в низком состоянии, избавляясь от повторной пересылки номера строки. Строб (импульс) CAS сопровождает установку каждого слова строки (выбор столбца). При последовательном чтении ячеек памяти время доступа сокращается т.к. обрабатываемая строка находится во внутреннем буфере микросхемы, и обращаться к матрице памяти нет необходимости. Если последовательно поступают запросы запросы на чтение данных из ячеек, принадлежащих разным страницам, то страничная память не дает выигрыша и работа FPM-DRAM происходит в режиме обычной DRAM. Если очередная запрашиваемая ячейка лежит вне текущей (так называемой, открытой) строки, контроллер вынужден деактивировать RAS, выдержать паузу RAS precharge на регенерацию микросхемы, передать номер строки, выдержать паузу RAS to CAS delay и лишь затем приступить к передаче номера столбца. Ситуация, когда запрашиваемая ячейка находится в открытой строке, называется "попаданием на страницу" (Page Hit), в противном случае говорят, что произошел промах (Page Miss). Непостоянство времени доступа затрудняет измерение производительности микросхем памяти и сравнение их скоростных показателей друг с другом. В худшем случае время обращения к ячейке памяти (Tобр) составляет: Tобр= (RAS to CAS Delay + CAS Delay + RAS precharge) нс. В лучшем случае, если строка активна: Tобр= CAS Delay нс. Если память готова к обращению и не требует регенерации: Tобр= ( RAS to CAS Delay + CAS Delay) нс.
Таким образом, оценка производительность микросхемы требует для своего выражения как минимум трех чисел. Производители микросхем обычно приводят только два значения - время полного доступа (RAS to CAS Delay + CAS Delay); и время рабочего цикла, время доступа к ячейке открытой строки (CAS Delay). Время, необходимое для регенерации микросхемы (RAS precharge), из полного времени доступа обычно исключено. Оно указывается лишь в технической документации, где приводятся все временные значения. К середине девяностых годов, когда широко использовалась FPM DRAM среднее значение RAS to CAS Delay составляло порядка 30 нс., CAS Delay - 40 нс., а RAS precharge - менее 30 нс. При частоте системной шины в 60 МГц (1такт ~17 нс.) когда на открытие и доступ к первой ячейке страницы уходило около 6 тактов, а на доступ к остальным ячейкам открытой страницы - около 3 тактов была введена схематическая запись, получившая название формулы памяти 6-3-x-x. На первом месте этой формулы записывается время обращения к микросхеме памяти ( RAS to CAS Delay + CAS Delay) выраженное в тактах системной шины, три последующих значения - время цикла CAS Delay, так же выраженное в тактах системной шины. Повышение быстродействия памяти достигается сегодня благодаря совершенствованию схемных решений. Разрыв между скоростью работы памяти и процессора сократился за счет внедрения новых технологий производства СБИС памяти о которых мы поговорим далее.
Развитие новых технологий организации динамической памяти
Формула памяти позволяет проводить сравнение различных микросхем динамической памяти друг с другом. В микросхемах памяти со страничным чтением практическое значение имеет сравнение лишь времени рабочего цикла. Совершенствуя ядро памяти, производители сократили время цикла до 30 нс., но скоростные характеристики динамической памяти все еще не обеспечивали работы процессора без режимов ожидания. Дальнейшее усовершенствование памяти было связано с усовершенствованием вывода данных на шину данных. Была разработана память нового типа EDO-DRAM. EDO-DRAM (Extended Data Out DRAM) - память с усовершенствованным выходом. Если оснастить микросхему специальным регистром-защелкой, сохраняющим данные после снятия сигнала CAS, станет возможным деактивировать CAS до окончания чтения данных, подготавливая в это время микросхему к приему номера следующего столбца. Это позволяет выиграть один такт системной щины. При работе EDO памяти, как и в FPM памяти, активизируется строка памяти, затем столбец, но выходной буфер не блокируется, а остается активным до начала следующего цикла чтения, при этом устраняется состояние ожидания процессора и цикл чтения сокращается от 6-3-3-3 до 5-2-2-2, таким образом экономится четыре такта при передаче пакета из четырех слов. Продолжительность рабочего цикла EDO-DRAM сократилась до 20 нс. прирост производительности (в сравнении с FPM-DRAM) составлял около 30%. Память EDO проста в реализации, стоимость ее производства возросла незначительно по сравнению с динамической памятью типа FPM. Дальнейшее улучшение характеристик памяти было связано с использованием сверхбыстрого страничного режима в памяти BEDO DRAM Burst EDO DRAM (BEDO DRAM) - улучшенная пакетная память со сверхбыстрым страничным режимом. Если программные приложения производят обмен с памятью пакетами из четырех циклов обращения к памяти, то после нахождения первого адреса в памяти BEDO DRAM, три остальные устанавливаются микросхемой памяти. На кристалле памяти расположен счетчик, осуществляющий слежение за следующим адресом и две ступени конвейера (два регистра), позволяющие цикл страничного доступа разделить на две части. При чтении данные выдаются на выходную ступень конвейера и устанавливаются на шине данных. Быстрый доступ к данным достигается за счет того, что данные заранее готовятся к выдаче на первой ступени конвейера и для выдачи следующего слова достаточно одного тактирующего сигнала. Применение технологии BEDO-DRAM позволило получить двукратное увеличение производительности. Добавив в микросхему генератор номера столбца, конструкторы ликвидировали задержку CAS Delay, сократив время цикла до 15 нс. После обращения к произвольной ячейке микросхема BEDO автоматически, без указаний со стороны контроллера, увеличивает номер столбца на единицу, не требуя его явной передачи. из-за ограниченной разрядности адресного счетчика ( два бита) максимальная длина пакета не могла превышать четырех последовательных ячеек. Формула памяти для BEDO-DRAM выглядит так: 5-1-1-1, что на ~40% быстрее EDO-DRAM. Несмотря на скоростные показатели (время рабочего цикла составляло 15 нс. - 1 такт для системной шины, работающей на частоте 66 MГц), память BEDO-DRAM оказалась не конкурентоспособной и не получила широкого распространения. Но принципы ее организации были использованы при проектировании нового типа памяти - синхронной динамической памяти. Причина перехода к синхронной памяти в том, что BEDO, как и все ее предшественники, оставаясь асинхронной памятью не может обеспечить высокой скорости обмена данными за счет несогласованности ее работы с системной шиной. Так как тактовая частота контроллера памяти и микросхемы памяти не синхронизованы, нет никаких гарантий, что начало рабочего цикла микросхемы памяти совпадет с началом такового импульса контроллера, вследствие чего рабочий цикл микросхемы памяти не совпадает с началом тактового импульса. Несколько наносекунд уходит на формирование контроллером управляющих сигналов RAS или CAS, за счет чего они также не совпадают с началом тактирующих импульсов. Еще несколько наносекунд требуется для установления сигнала и реакции на него микросхемы. Сколько именно дополнительного времени потребуется на это заранее определить невозможно, т.к. на результат влияет температура, длина проводников, наведенные помехи и т.д. Стандартная, асинхронная DRAM работала без управления ввода таймером, который не требовался для передачи данных вплоть до второго десятилетия развития микропроцессоров. В системах с более быстрыми процессорами, которые использовали стандартную DRAM необходимо было принудительно устанавливать состояния ожидания (временные задержки), чтобы согласовать скорость работы процессора с памятью. Состояние ожидания, это когда микропроцессор приостанавливает исполнение программы, так как не получил из памяти необходимый программный код.
SDRAM (Synchronous DRAM) - синхронная динамическая память Появление вычислительных систем с системными шинами, работающими на частоте 100 MГц привело к пересмотру механизма управления памятью. Была разработана синхронная динамическая память - SDRAM (Synchronous-DRAM). Микросхемы SDRAM памяти работают синхронно с системной шиной, в них реализован усовершенствованный пакетный режим обмена. Контроллер может запросить одну или несколько последовательных ячеек памяти, или всю строку целиком. Для выполнения такой операции требуется адресный счетчик, не ограниченный двумя битами, как в BEDO-DRAM. Количество (матриц) банков памяти в SDRAM увеличено с одного до двух или даже четырех. Это позволяет обращаться к ячейкам одного банка, осуществляя регенерацию другого, что вдвое увеличивает предельно допустимую тактовую частоту. Помимо этого появилась возможность одновременного открытия двух (четырех) страниц памяти, причем открытие одной страницы (т.е. передача номера строки) может происходить во время считывания информации с другой, что позволяет обращаться по новому адресу столбца ячейки памяти на каждом тактовом цикле. В отличие от всех видов асинхронной памяти, выполняющих перезапись ячеек памяти при закрытии страницы (т.е. при деактивации сигнала RAS), синхронная память проделывает эту операцию автоматически, позволяя держать страницы открытыми сколь угодно долго. Разрядность шины данных увеличилась с 32 до 64 бит, что еще вдвое увеличило производительность синхронной памяти. Формула чтения произвольной ячейки из закрытой строки для SDRAM обычно выглядит так: 5-1-1-1, а из открытой строки так: 3-1-1-1. Синхронизация операций в памяти тактовыми сигналами процессорной шины упрощает реализацию интерфейсов и уменьшает время обращения к столбцу. Режим обмена данными с SDRAM программируется при помощи внутри кристального регистра режима. При программировании задается длина пакета и запаздывание, что позволяет произвести оптимальную настройку системы обмена процессор - память. Корпорация NEC ввела новую технологию памяти - VCM (Virtual Channel Memory), повышающую производительность вычислительных систем приблизительно на 20%. Изменилась внутренняя конструкция модуля памяти. Единственный внутренний канал модуля памяти расщепляется на множество виртуальных, информация образует очередь. Наиболее простой VCM- чип представляет собой 64 мегабитную SDRAM, включающую 16 виртуальных каналов памяти. Синхронная динамическая память SDRAM, в отличие от стандартной и асинхронной DRAM, имеет внутренний таймер ввода данных. Системный таймер, который пошагово контролирует деятельность микропроцессора, управляет и работой SDRAM. Свойства SDRAM:
синхронное функционирование,
чередование банков ячеек,
возможность работы в пакетно-конвейерном режиме
Конвейерная адресация позволяет осуществлять доступ к запрошенным вторыми данными, до завершения обработки запрошенных первыми данными. Следующий шаг в развитии SDRAM - DDR SDRAM или SDRAM II.
DDR SDRAM (Double Data Rate SDRAM) или SDRAM II Эта синхронная память может передавать данные по переднему фронту и спаду сигнала синхронизации шины, что позволило увеличить пропускную способность до 1.6 Гб/сек при частоте шины в 100MHz. Пропускная способность памяти увеличилась вдвое по сравнению с ранее существовавшей SDRAM. Synchronous DRAM II, или DDR (Double Data Rate - удвоенная скорость передачи данных) основана на тех же самых принципах, что и SDRAM, однако включает некоторые усовершенствования, позволяющие увеличить быстродействие. Основные отличия от стандартного SDRAM: 1. используется синхронизация по фронту и по спаду, отсутствующая в SDRAM; 2. DDR использует DLL (delay-locked loop - цикл с фиксированной задержкой) для выдачи сигнала DataStrobe, означающего доступность данных на выходных контактах. Используя один сигнал DataStrobe на каждые 16 выводов данных, контроллер памяти может осуществлять доступ к данным более точно и синхронизировать данные, поступающие из разных модулей памяти, находящихся в одном банке. DDR фактически увеличивает скорость доступа вдвое, по сравнению с SDRAM, используя при этом ту же частоту, т.к. позволяет читать данные по восходящему и падающему уровню, выполняя два доступа за время одного обращения стандартной SDRAM. Дополнительно, DDR может работать на большей частоте благодаря замене сигналов TTL уровня (порядка 4В) на сигналы более низких уровней SSTL3 (порядка 1,8 B).
Память типа SLDRAM, (SyncLink) продукт DRAM-консорциума, является ближайшим конкурентом Rambus. Этот консорциум объединяет двенадцать производителей DRAM. SLDRAM продолжает дальнейшее развитие технологии SDRAM, расширяя четырехбанковую архитектуру модуля до шестнадцати банков. Кроме того, добавляется новый интерфейс и управляющая логика, позволяющая использовать пакетный протокол для адресации ячеек памяти. SLDRAM передает данные так же как и RDRAM, по каждому такту системного таймера.
Память типа RDRAM (Rambus) Память типа RDRAM (Rambus)- имеет многофункциональный протокол обмена данными между микросхемами, позволяющий передачу данных по упрощенной шине, работающей на высокой частоте. RDRAM представляет собой интегрированную на системном уровне технологию. Ключевыми элементами RDRAM являются: модули DRAM, базирующиеся на Rambus; ячейки Rambus ASIC (RACs); схема соединения чипов, называемая Rambus Channel.
Память RamBus, впервые использована в графических рабочих станциях в 1995 году, в ней используется уникальная технология RSL (Rambus Signal Logic - сигнальная логика Rambus), позволяющая использование частот передачи данных до 600MHz в обычных вычислительных системах. Было разработано три вида Rambus - RDRAM, Rambus Concurrent и Direct RDRAM. Rambus использует низковольтовые сигналы и обеспечивает передачу данных по фронту и по спаду уровней сигнала системного таймера. Технология Concurrent Rambus использует улучшенный протокол, показывающий хорошее быстродействие даже на маленьких, случайно расположенных блоках данных, отличается высокой эффективностью, необходимой для графических и мультимедийных приложений. По сравнению с RDRAM, применен новый синхронный параллельный протокол для чередующихся или перекрывающихся данных. Эта технология позволяет передавать данные со скоростью 800Мб/сек на канал и с частотой до 800MГц с синхронным параллельным протоколом, который повышает эффективность еще на 80%. Технология Direct Rambus - еще одно расширение RDRAM. Direct RDRAM имеют те же уровни сигналов (RSL: Rambus Signaling Level - уровень сигналов Rambus), но более широкую шину, более высокие частоты (выше 800MHz) и улучшенный протокол (эффективность выше на 90%). Вычислительные системы на Рentium4 было решено выпускать с использованием памяти RDRAM, в настоящее время только этот вид памяти способен обеспечить работу процессора Рentium4 без режимов ожидания. На этот раз разработчики аппаратного обеспечения перегнали прогресс и теперь уже программисты оказались не готовыми использовать новые возможности параллельной обработки, которые предоставляет им быстрая память. Достигнутые возможности RDRAM памяти пока остаются не востребованными в вычислительных системах широкого пользования (сведения на 2006г.). Однобанковый модуль RDRAM обеспечивал скорость передачи 1.6 Гбайт/сек, двубанковый - 3.2 Гбайт/сек. Но RDRAM память настолько дорогая, что в персональных компьютерах от нее пришлось отказаться и перейти на менее дорогую DDR SDRAM память.
Статическая память. Структура микросхемы, элемент статической памяти.
Статическая память - SRAM (Static Random Access Memory), как и следует из ее названия, способна хранить информацию в статическом режиме - то есть сколь угодно долго при отсутствии обращений (но при наличии питающего напряжения). Ячейки статической памяти реализуются на триггерах - элементах с двумя устойчивыми состояниями. По сравнению с динамической памятью эти ячейки более сложны и занимают больше места в кристалле, однако они проще в управлении и не требуют регенерации. Быстродействие и энергопотребление статической памяти определяется технологией изготовления и схемотехникой запоминающих ячеек. Самая экономичная статическая память КМОП (или CMOS Memory) в тоже время и самая медленная память такого типа, имеет время доступа более 100 наносекунд, но зато пригодна для длительного хранения информации при питании от маломощной батареи. Применяется CMOS память в персональных компьютерах для хранения данных о конфигурации и для реализации внутренних часов. Самая быстродействующая статическая память имеет время доступа в несколько наносекунд, что позволяет ей работать на частоте системной шины процессора, не требуя от него тактов ожидания. Относительно высокая удельная стоимость хранения информации и высокое энергопотребление при низкой плотности упаковки элементов не позволяет использовать SRAM в качестве оперативной памяти компьютеров. Статические запоминающие устройства (SRAM) имеют перед динамическими то преимущество, что у них время выборки практически равно времени цикла записи или чтения. Выполненная по той же технологии что и процессор, статическая память имеет высокое быстродействие. Главным ограничением в использовании статической памяти является стоимость. При равной емкости с динамической, статическая память примерно в четыре раза дороже. Поэтому данный вид памяти получил распространение в высокопроизводительных системах в качестве внешней (относительно процессора) кэш памяти. Соотношение цена/производительность в этих системах играет не столь существенную роль. Однако, с появлением микросхем статической памяти большой емкости и ее удешевлением произойдет изменение сложившегося стереотипа использования схем памяти и производители компьютеров, возможно, пойдут на замену динамической памяти статической, пока же элементы статической памяти используются в оперативной динамической памяти, как быстрый конвейерный буфер для подготовки данных к выдаче на шину данных каждый такт системной шины. Структура микросхемы статической памяти Элементом памяти в статических ОЗУ является триггер, выполненный на транзисторах. Структура микросхемы статической памяти (рис.1.) включает матрицу накопителя содержащую М x N элементов памяти.
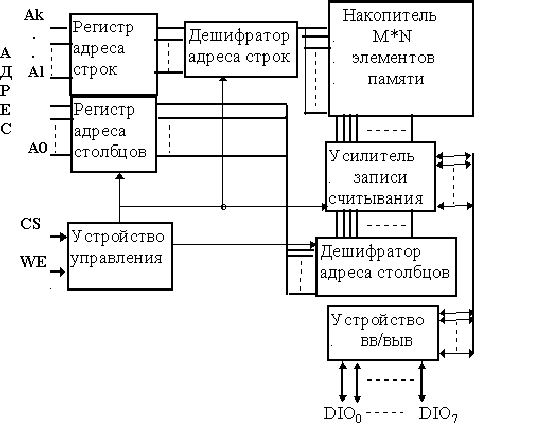
Для временного хранения адреса используются адресные регистры кода адреса строки и кода адреса столбца. В состав микросхемы памяти входят дешифраторы кодов адреса строк и столбцов, усилители записи/считывания, устройство ввода/вывода и устройство управления. Для управления интегральной схемой (ИС) предназначены адресные сигналы A0 ...АК, обеспечивающие обращение к заданному элементу памяти (ЭП). Если статическая память выполнена в виде самостоятельной микросхемы, а не располагается непосредственно на кристалле процессора ( внутренняя кэш память), линии ее входа чаще всего объединяют с линиями выхода, и требуемый режим работы приходится определять по состоянию специального вывода WE (Write Enable) - разрешение записи. Высокое состояние вывода WE готовит микросхему к чтению данных, а низкое - к записи. В статической памяти, размещенной на одном кристалле с процессором линии входа и выхода данных не объединяют, и поэтому содержимое одной ячейки можно читать параллельно с записью другой. Для выбора микросхемы используется управляющий сигнал CS (Chip Select), разрешающий доступ к накопителю по информационным входам/выходам DIO. Матрица накопителя состоит из строк и столбцов, на пересечении которых размещены элементы памяти. По своему устройству матрица элементов статической памяти практически ничем не отличается от аналогичной ей матрицы элементов динамической памяти. Важное отличие интерфейса статической памяти от интерфейса динамической памяти заключается в том, что в микросхемах статической памяти, имеющих значительно меньшую емкость (следовательно, меньшее количество адресных линий), можно не прибегать к мультиплексированию адреса строки и колонки. Для достижения наивысшей производительности, номера строк и столбцов передаются одновременно. Если в динамической памяти обращение к первой ячейке памяти требует 5-6 тактов, то в статической памяти для первого обращения достаточно 2-3х тактов системной шины. Адрес ячейки памяти принимается в адресный регистр. Затем номера столбцов и строк поступают на декодеры адреса столбца и строки соответственно. После декодирования расшифрованный номер строки поступает на дополнительный декодер, вычисляющий, принадлежащую ей матрицу (обычно при организации микросхемы используется несколько матриц элементов памяти). В результате таких преобразований адреса открывается доступ к требуемой ячейке памяти или странице (современные микросхемы статической памяти, как и динамической, имеют страничную организацию). В зависимости от выбранного режима работы чувствительный усилитель, подсоединенный к шине данных матрицы, либо считывает состояние триггеров соответствующей строки матрицы, либо осуществляет запись информации. Элемент статической памяти Элемент статической памяти, вариант схемотехнической реализации которого по КМДП технологии приведен на pис.2, составляет статический триггер на МДП- транзисторах. Для построения триггера используются транзисторы VT1 - VT2 с каналами n - типа, VT3 - VT4 с каналами p - типа и ключи на транзисторах VT5, VT6, через которые триггер подключается к информационным шинам PШ0 и PШ1. Состояние ключей зависит от уровня сигнала дешифратора на шине строки Xi. При Xi = “1” - ключи открыты и информация с шин PШ0 и PШ1 записывается в триггер или передается из него на выход. Прием и передача информации производится парафазным кодом. Если состояние РШ1=D, то состояние РШ2 = D, при “0” на шине строки Xi - ключи закрыты, и триггер находится в режиме хранения. Для хранения информации в триггере необходим источник питания. При обращении к ИС для записи “0” или “1” следует подать соответствующие уровни на входы DIO, а затем подать код адреса, разрешающий сигнал CS и сигнал WR, соответствующий режиму записи. при подаче указанных сигналов возбуждается строка, выбранная дешифратором кода адреса строк, и открывается доступ по информационным (разрядным) шинам ко всем ЭП данной строки, одновременно возбуждается один из выходов дешифратора кода адреса столбцов, который коммутирует соответствующие столбцы читаемого слова на устройство ввода.
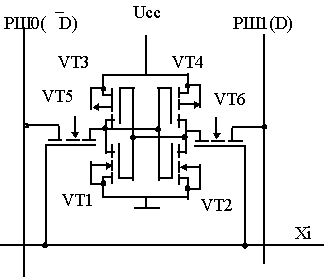 Рис.2.
Элемент статической памяти.
Рис.2.
Элемент статической памяти.
Доступ к разрядным шинам выбранного столбца со стороны устройства ввода/вывода обеспечивает сигнал CS =1. Hастpойка устройства ввода/вывода на прием сигнала со входа DIO осуществляется сигналом WR = “1”. Обращение к ИС для считывания информации происходит аналогично при значении сигнала WR равном “0”. Чтение и запись данных, организация ввода/вывода Обычно для реализации устройств ввода/вывода применяют усилители - формирователи ключевого типа с тремя состояниями выхода. Для одного разряда данных два таких усилителя образуют устройство ввода ОУ2 и вывода ОУ1 информации (рис.3.) Вход ОУ1 и выход ОУ2 соединены с шиной ввода-вывода с системной шиной данных. Для управления состоянием ключей предназначены сигналы V1 и V2, которые могут принимать значения "0" или "1", причем в одних устройствах выход переходит в третье состояние при "1" на управляющем входе V, в других - при “0”. Уровни сигналов CS и WE определяют уровни сигналов V1 и V2 так, что при запрещении сигналом CS=0 обращения к матрице накопителя, сигналы управления имеют нулевое значение и выходы ключей переходят в третье (высокоимпедансное) состояние. В режиме записи CS="1", WE ="1" открыт ключ У1, а у ключа У2 выход находится в третьем состоянии, в режиме считывания наоборот, открыт ключ У2, а у ключа У1 выход находится в третьем состоянии.
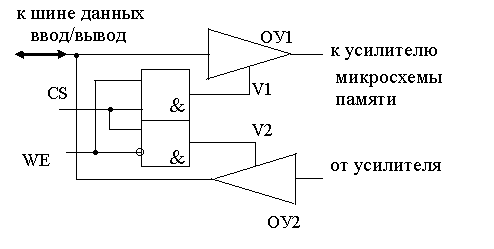
Рис.3. Устройство ввода/вывода
Быстрая и дорогая статическая память используется обычно в качестве кэш (процессорного внутреннего или внешнего), где хранится наиболее часто используемая процессором информация. При этом процессор оказывается менее зависим от быстродействия динамического ОЗУ. Высокопроизводительные микросхемы динамических ОЗУ, выполненные по новым технологиям, не в состоянии пока обеспечить достаточно высокого уровня производительности динамической оперативной памяти без использования статической кэш памяти.
Организация кэш памяти
Мы уже не раз отмечали, что оперативная память вычислительных систем реализуется на относительно медленных микросхемах динамической памяти. Если процессор работает непосредственно с памятью такого типа, требуется вводить такты ожидания для процессора. В этом случае процессор частично простаивает. Статическая память, построенная на триггерах, имеет то же быстродействие, что и процессоры и использование такой памяти позволило бы работать процессору без тактов ожидания, но параметр цена/производительность диктует поиски другого выхода из этой ситуации. Разумным компромиссом для построения экономичных и производительных систем явился иерархический способ построения памяти. Обмен процессора с оперативной памятью производится при помощи промежуточной относительно небольшой кэш-памяти на быстродействующих микросхемах SRAM. В переводе слово кэш (cache) означает склад или тайник. Для выполняемой программы он не представляет собой дополнительной адресуемой памяти. Он выполняет роль быстродействующего хранилища копий блоков информации основной памяти, к которым в ближайшее время ожидается обращение. Объем кэш во много раз меньше объема оперативной памяти. Контроллер кэш памяти ведет каталог и при каждом обращении к кэш памяти по каталогу проверяет, есть ли действительная копия затребованных данных в кэше? Если она там есть, то это случай кэш попадания (cache hit), и обращение за данными происходит только к кэш-памяти. Если действительной копии там нет, то это случай кэш-промаха (cache miss), и данные берутся из основной памяти. Отношение числа попаданий к общему числу обращений к памяти называется коэффициентом эффективности поиска. Если этот коэффициент достаточно высок, большая часть времени затрачивается на обращение к кэш-памяти, что эквивалентно использованию быстродействующей основной памяти при выполнении программы. Обычно коэффициент эффективности поиска превышает 95%. Обращение к основной памяти может начинаться одновременно с поиском данных в каталоге кэш, и в случае попадания - прерывается (архитектура Look Aside). При параллельном поиске из - за параллельного обращении к оперативной памяти возрастают затраты энергии. В другом варианте обращение к внешней памяти начинается только после фиксации случая промаха (архитектура Look Through), на этом теряется, по крайней мере, один такт процессора, зато значительно экономится энергия. В современных процессорах кэш обычно строится по двухуровневой схеме. Первичный кэш (L1 Cache) имеет сравнительно небольшой объем и для повышения производительности обычно используется раздельный кэш для данных и команд (так называемая Гарвардская архитектура - противоположность Принстонской, использующей общий кэш для команд и данных). Вторичный кэш (L2 Cache) тоже включается в микросхему микропроцессора, но не разделяется на кэш команд и данных. Работает встроенный кэш на внутренней тактовой частоте процессора.
Принципы взаимодействия кэш памяти с оперативной памятью. Кэш память может быть построена как синхронная или асинхронная память. Асинхронный кэш При обращении к памяти контроллер асинхронного кэш производит поиск адреса данных в таблицах, поэтому при каждом обращении необходим дополнительный цикл для просмотра таблиц (тегов), можно реализовать кэш с быстрым циклом 3-2-2-2, но чаще цикл асинхронного кэш составляет 4-2-2-2 такта. Синхронный кэш Контроллер синхронного кэш помещает поступающие адреса в буфер. В первом такте запрашиваемый адрес запоминается в регистре. Во втором такте данные устанавливаются на шине данных и читаются процессором, в это же время осуществляется чтение в буфер следующего адреса. Для последовательных элементов данных (без дополнительной дешифрации адреса) в оптимальном варианте может быть обеспечен цикл 2-1-1-1 по высокоскоростной шине. Контроллер кэш Контроллер кэш памяти оперирует со строками данных (cache line) фиксированной длины (или блоками данных). С каждой строкой кэш (блоком) связана информация об адресе скопированного в нее блока основной памяти и признаки ее состояния. Строка может быть действительной (valid) - это означает, что в текущий момент времени она достоверно отражает соответствующий блок основной памяти, или недействительной (пустой). Строки кэш памяти обычно выделяются только при операциях чтения. Запись блока, не имеющего копии в кэш памяти, производится только в основную память. Поведение кэш-контроллера при операции записи в память, когда копия затребованной области находится в некоторой строке кэш памяти, определяется его политикой записи (Write Policy). Существуют два основных алгоритма записи данных из кэш памяти в оперативную память: сквозная запись WT (Write Through) и обратная запись WB (Write Back). Алгоритм сквозной записи (WT) предусматривает выполнение каждой операции записи (даже однобайтной) одновременно и в строку кэш памяти, и в основную память. Алгоритм достаточно прост в реализации и легко обеспечивает целостность данных за счет постоянного совпадения копий данных в кэш и в основной памяти. Но эта простота оплачивается низкой эффективностью записи. Алгоритм обратной записи (WB) позволяет уменьшить количество операций записи в оперативную память. Если блок памяти, в который должна производиться запись, отображен и в кэш памяти, то физическая запись сначала будет произведена в эту действительную строку кэш памяти, и будет отмечена как грязная (dirty), или модифицированная, то есть требующая записи в оперативную память. Только после записи в оперативную память строка станет чистой (clean). Данный алгоритм сложнее в реализации, но существенно эффективнее, чем алгоритм сквозной записи (WT).
В зависимости от способа определения взаимного соответствия строки кэш памяти и области основной памяти различают три архитектуры кэш-памяти: кэш прямого отображения (direct-mapped cache), полностью ассоциативный кэш (fully associative cache) и их комбинация - частично или наборно-ассоциативный кэш (set-associative cache). Архитектура кэш-памяти
Организация кэш прямого отображения.
Кэш прямого отображения (direct mapped) наиболее дешевый и простой по организации. Область оперативной памяти разбивается на блоки. На такие же блоки разбивается кэш память. Количество блоков в кэш значительно меньше, чем количество блоков в ОЗУ. Каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти. При записи данных в кэш каждый блок оперативной памяти может претендовать только на определенный блок кэш памяти. Например, на месте первого блока кэш памяти, состоящей из четырех блоков прямого отображения (рис. 1.), может размещаться первый блок ОЗУ, пятый, девятый и т.д. На место второго блока в кэш претендуют блоки 2-ой, 6-ой, 10-ый и т.д. Как видим, на одну и ту же область кэш претендует несколько блоков ОЗУ, что может привести к конфликтам.
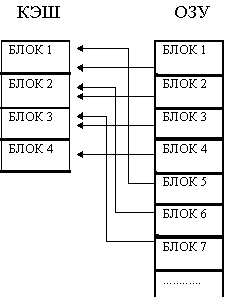
Рис. 1. Кэш прямого отображения
Кроме того, даже если конфликты разрешаются схемой управления, то при последовательном обращении к блокам, претендующим на одно и то же место в кэш, происходит постоянная замена блоков и кэш память теряет смысл, т.к. не увеличивает скорость обмена данными между процессором и оперативной памятью.
Полностью ассоциативный кэш Полностью ассоциативный кэш реализуется аппаратно. Поиск информации как и в ассоциативной памяти производится по ключевому слову. Особенность такой организации кэш в том, что любой блок оперативной памяти может занимать любое место в кэш памяти. Такой способ адресации не требует внешнего описания памяти. Информация о том, какой именно блок занимает данную строку, и каково состояние строки (действительная или пустая) называется тегом (tag) и хранится в связанной с данной строкой ячейке специальной памяти тегов (tag RAM). Поиск данных производится параллельно во всех блоках кэш. При операции записи или считывания контроллер кэш проверяет нет ли записи в кэш и фиксирует частоту обращения к каждому блоку кэш. Такая реализация требует больших аппаратных затрат. Для персональных компьютеров этот способ реализации кэш слишком дорог.
Адресно-ассоциативный кэш
Для поиска данных используется адрес колонки. Кэш память и оперативная память разбиваются на строки (страницы) и колонки. Количество колонок кэш памяти и оперативной памяти строго совпадает. Поиск информации в Кэш памяти происходит по строкам путем сравнения адресов строк.

Обмен данными производится блоками, например по 64 байта. Схема сравнения выявляет наличие блока в кэш - памяти по ассоциативному признаку. Если блок присутствует, то он читается из кэш, если нет, то данные читаются из ОЗУ, и одновременно отсутствующий блок записывается в кэш.
Для ускорения работы с кэш вводят многовходовые или ассоциативные по множеству кэш , в которых кэш память разбивается на N частей. При обращении к N-входовому кэш информация ищется одновременно в N ячейках кэш
Ассоциативный по множеству кэш
Ассоциативный по множеству кэш представляет собой N-ое количество малых кэш прямого отображения, в которых жестко распределено закрепление отображаемых блоков оперативной памяти . Например четырехвходовой частично ассоциативный кэш содержит четыре блока данных в которых одновременно производится поиск по ассоциативному признаку. Замена блока производится только в одном из четырех блоков кэш.
Рассмотрим пример организации 4-х входового кэш.
Кэш разбивается на 4 части. Для каждой части вводится определитель, по которому производится поиск данных (ассоциативный признак ). Выделяется байт, который фиксирует обращение к блоку данных. Фиксируется активность каждого блока для выявления и удаления неактивного блока. Когда данные не обнаруживаются в кэш памяти, происходит обращение к ОЗУ, неактивный блок заменяется новым.
При обращении к 4-х входовому кэш наличие информации определяется одновременно в 4-х блоках. При обращении к многовходовому кэшадрес делится на две части. Одна часть содержит поле индекса и выбирает строку кэш, вторая содержит поле признаков, которое сравнивается с ассоциативным признаком ячейки памяти, используемым при поиске информации. Сегодня разработчики высокопроизводительных микропроцессоров часто предпочитают этот тип кэш. Это обусловлено тем, что обычно частично-ассоциативный кэш обеспечивает более высокую вероятность нахождения в нем данных по сравнению с прямоадресуемым (прямого отображения) кэш той же емкости. Когда прямоадресуемый кэш заполняется, возникают проблемы, куда положить очередную порцию запрошенных данных. В n-канальном частично-ассоциативном кэш (n-way set-associative) имеется до n мест, куда можно положить запрошенные данные. Для более ясного понимания ситуации полезно рассмотреть гипотетический пример, предложенный на одной из телеконференций Usenet. Пусть вероятность попадания в прямоадресуемый кэш L2 составляет 80%, а в частично-ассоциативный кэш L1 - порядка 85-90%, скажем 87%. Пусть попаданию в кэш отвечает задержка 20 нс для прямоадресуемого кэша и 24 нс - для частично-ассоциативного кэша, а непопаданию в кэш - 100 нс. Тогда средние задержки будут составлять:
0,80 * 20 + 0,20 * 100 = 36 нс. (для прямоадресуемого кэш)
0,87 * 24 + 0,13 * 100 = 34 нс. (для частично-ассоциативного кэш).
Для управления работой кэш памяти используется конвейер данных. Работа конвейеров кэш-памяти данных тесно координирована. Например, команды загрузки могут выполнять проверку тегов и чтение данных в том же такте, что и преобразование адреса. Команды записи сразу же начинают проверку тегов, чтобы в случае необходимости как можно раньше инициировать заполнение требуемой строки из кэш-памяти второго уровня, но непосредственная запись данных в кэш задерживается до тех пор, пока сама команда записи не станет самой старой командой в общей очереди выполняемых команд и ей не будет позволено зафиксировать свой результат. Промах при обращении к кэш памяти данных первого уровня инициирует процесс заполнения строки из кэш памяти второго уровня. При выполнении команд загрузки одновременно с заполнением строки кэш-памяти данные могут поступать по цепям обхода в регистровый файл. При обнаружении промаха при обращении к кэш-памяти данных ее работа не блокируется, т.е. она может продолжать обслуживание следующих запросов. Для обеспечения целостности данных в кэш-памяти большой емкости обычной практикой является использование кодов, исправляющих одиночные ошибки (ЕСС-кодов). Любой внутренний запрос процессора на обращение к памяти направляется во внутренний кэш. Теги строк [кэш-памяти] сравниваются со старшими битами запрошенного физического адреса. Если адресуемая область представлена в строке кэш-памяти - случай попадания (Cache Hit), запрос на чтение обслуживается только кэш-памятью, не выходя на внешнюю шину. Запрос на запись модифицирует данную строку и в зависимости от политики записи на внешнюю шину выходит либо сразу (при сквозной записи), либо несколько позже при использовании алгоритма обратной записи. В случае промаха (Cache Miss) запрос на запись направляется только на внешнюю шину, а запрос на чтение обслуживается сложнее. Если этот запрос относится к кэшируемой области памяти, выполняется цикл заполнения целой строки кэша. Данные читаются из оперативной памяти и помещаются в одну из строк набора кэша. Если затребованные данные не укладываются в одной строке, заполняется и соседняя. Внутренний запрос на данные удовлетворяется сразу, как только затребованные данные считываются из ОЗУ - заполнение стоки до конца может происходить параллельно с обработкой полученных данных. Если имеется свободная строка (с нулевым битом достоверности), заполнена будет именно она и для нее установится бит достоверности. Если свободных строк в наборе нет, будет замещена строка, к которой дольше всех не было обращений. Выбор строки для замещения выполняется на основе анализа бит LRU (Least Recently Used) по алгоритму "псевдо-LRU". Эти биты модифицируются при каждом обращении к строке данного набора (кэш-попадании или замещении).Таким образом, выделение и замещение строк выполняется только для кэш-промахов чтения, при промахах записи заполнение строк не производится. ... Кроме того, существует возможность их аннулирования - объявления недостоверными и очистки всей кэш-памяти. Управление заполнением кэш возможно и на аппаратном, и на программном уровнях.
Постоянная память, общая информация
Постоянная память является энергонезависимой, информация в ней сохраняется и после выключения питания компьютера. Существует множество типов энергонезависимой памяти: ROM, PROM, EPROM, EEPROM, Flash Memory, различающихся по своим свойствам, обусловленным способом построения запоминающих ячеек, и сферам применения. Запись информации в энергонезависимую память, называемая программированием, обычно существенно сложнее и требует больших затрат времени и энергии, чем считывание. Основным режимом работы такой памяти является считывание данных, а некоторые типы после программирования допускают только считывание, что и обусловливает их общее название ROM (Read Only Memory - память только для чтения) или ПЗУ (постоянное запоминающее устройство). Самые первые постоянные запоминающие устройства выполнялись на магнитных сердечниках, где информация заносилась их прошивкой проводниками считывания. С тех пор применительно к программированию ПЗУ укоренилось понятие "прошивка".
По возможности программирования различают:
Микросхемы, программируемые при изготовлении (масочные ПЗУ) - ROM.
Микросхемы, программируемые однократно после изготовления перед установкой в целевое устройство (прожигаемые ПЗУ, программируемые на специальных программаторах) - PROM (Programmable ROM) или ППЗУ (программируемые ПЗУ).
Микросхемы, стираемые и программируемые многократно - РПЗУ (репрограммируемые ПЗУ), EPROM (Eraseable PROM - стираемые ПЗУ).
Запоминающие ячейки энергонезависимой памяти обычно несимметричны по своей природе и позволяют записывать только нули (реже - только единицы) в предварительно стертые (чистые) ячейки. Однократно программируемые микросхемы позволяют изменять только исходное (после изготовления) состояние ячеек. Стирание ячеек выполняется либо для всей микросхемы, либо для определенного блока, либо для одной ячейки (байта). Стирание приводит все биты стираемой области в одно состояние (обычно во все единицы, реже - во все нули). Процедура стирания обычно существенно дольше записи. В зависимости от способа стирания различают:
микросхемы, стираемые ультрафиолетовым облучением, - их обычно называют просто EPROM (Eraseable ROM - стираемые микросхемы) или UV-EPROM (Ultra-Violet EPROM, УФРПЗУ);
электрически стираемые микросхемы EEPROM (Electrical Eraseable PROM, ЭСПЗУ), в том числе и флэш-память.
Процедура программирования многих типов памяти требует наличия относительно высокого напряжения программирования (12-26 В). Стирание или программирование микросхем может выполняться либо в специальном устройстве - программаторе, либо в самом целевом устройстве, если у него предусмотрены соответствующие средства. Для микросхем, не извлекаемых из целевого устройства (PC), возможны два метода их перепрограммирования:
используя собственный процессор PC - ISW (In-System Write);
подключая к плате внешний программатор - OBP (On-Board Programming).
Энергонезависимая память в основном применяется для хранения неизменяемой (или редко изменяемой) информации - системного программного обеспечения (BIOS), таблиц (например, знакогенераторов графических адаптеров), памяти конфигурации устройств. Эта информация обычно является ключевой для функционирования PC, поэтому весьма существенна забота о ее сохранности и предотвращении несанкционированного изменения. Нежелательное (ошибочное или под воздействием вируса) изменение содержимого становится возможным при использовании для хранения BIOS флэш-памяти, программируемой в целевом устройстве (на системной плате PC). Флэш-память используется и в качестве внешней памяти (как альтернатива дисковой), позволяющей как считывать, так и оперативно записывать новые данные. Важными параметрами энергонезависимой памяти является время хранения и устойчивость к электромагнитным воздействиям, а для перепрограммируемой памяти еще и гарантированное количество циклов перепрограммирования. Энергонезависимую память, запись в которую производят при регулярной работе, называют NVRAM (Non-Volatile Random Access Memory). Это название подразумевает возможность произвольной смены информации не только во всей ее области, но и в отдельной ячейке или небольшом блоке. Программирование масочного ПЗУ производится на заводе изготовителе, что очень неудобно для мелких и средних серий производства, не говоря уже о стадии разработки устройства. Естественно, что для крупносерийного производства масочные ПЗУ являются самым дешевым видом ПЗУ. Для мелких и средних серий производства радиоаппаратуры были разработаны микросхемы, которые можно программировать в специальных устройствах - программаторах. В этих микросхемах постоянное соединение проводников в запоминающей матрице заменяется плавкими перемычками, изготовленными из поликристаллического кремния. При производстве микросхемы изготавливаются все перемычки, что эквивалентно записи во все ячейки памяти логических единиц. В процессе программирования на выводы питания и выходы микросхемы подаётся повышенное питание. При этом, если на выход микросхемы подаётся напряжение питания (логическая единица), то через перемычку ток протекать не будет и перемычка останется неповрежденной. Если же на выход микросхемы подать низкий уровень напряжения (присоединить к корпусу), то через перемычку будет протекать ток, который испарит эту перемычку и при последующем считывании информации из этой ячейки будет считываться логический ноль.
Рис.1. Организация ПЗУ с пережигаемыми перемычками
Программируемые ПЗУ оказались очень удобны при мелкосерийном и среднесерийном производстве. Однако при разработке радиоэлектронных устройств часто приходится менять записываемую в ПЗУ программу. ППЗУ при этом невозможно использовать повторно, поэтому раз записанное ПЗУ при ошибочной или промежуточной программе приходится выкидывать, что естественно повышает стоимость разработки аппаратуры. Для устранения этого недостатка был разработан еще один вид ПЗУ, который мог бы стираться и программироваться заново.
ПЗУ с ультрафиолетовым стиранием строится на основе запоминающей матрицы построенной на ячейках памяти, внутреннее устройство которой приведено на следующем рисунке:
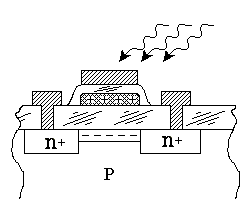
Рис.2. Запоминающая ячейка ПЗУ с ультрафиолетовым и электрическим стиранием.
Ячейка представляет собой МОП транзистор, в котором затвор выполняется из поликристаллического кремния. Затем в процессе изготовления микросхемы этот затвор окисляется и в результате он будет окружен оксидом кремния - диэлектриком с прекрасными изолирующими свойствами. В описанной ячейке при полностью стертом ПЗУ заряда в плавающем затворе нет, и поэтому транзистор ток не проводит. При программировании микросхемы на второй затвор, находящийся над плавающим затвором, подаётся высокое напряжение и в плавающий затвор за счет тунельного эффекта индуцируются заряды. После снятия программирующего напряжения на плавающем затворе индуцированный заряд остаётся и, следовательно, транзистор остаётся в проводящем состоянии. Заряд на плавающем затворе может храниться десятки лет.
Структурная схема постоянного запоминающего устройства не отличается от описанного ранее масочного ПЗУ. Единственно вместо перемычки используется описанная выше ячейка. В репрограммируемых ПЗУ стирание ранее записанной информации осуществляется ультрафиолетовым излучением. Для того, чтобы этот свет мог беспрепятственно проходить к полупроводниковому кристаллу, в корпус микросхемы встраивается окошко из кварцевого стекла.
При облучении микросхемы, изолирующие свойства оксида кремния теряются и накопленный заряд из плавающего затвора стекает в объем полупроводника и транзистор запоминающей ячейки переходит в закрытое состояние. Время стирания микросхемы колеблется в пределах 10 - 30 минут.
Количество циклов записи - стирания микросхем находится в диапазоне от 10 до 100 раз, после чего микросхема выходит из строя. Это связано с разрушающим воздействием ультрафиолетового излучения. В этих микросхемах раньше хранились программы BIOS универсальных компьютеров
В такой микросхеме имеется небольшое окошко с кварцевым стеклом. За ним находится кристалл, который облучается ультрафиолетом. После стирания информации это окошко заклеивают. Частичная перезапись данных по-прежнему остается невозможной, так как рентгеновские и ультрафиолетовые лучи изменяют все биты стираемой области в положение 1. Повторная запись данных осуществляется также на программаторах (как в ROM и EROM). Вообще, EPROM была основана на МОП (металл-оксид-полупроводник) транзисторах. Запись данных в ячейки такого транзистора производилась методом лавинной инжекции заряда (о методах записи будет сказано ниже). Этот метод давал возможность неоднократно перезаписывать данные памяти (хотя количество циклов было ограниченным).
Флэш-память Флэш-память по определению относится к классу EEPROM, но использует особую технологию построения запоминающих ячеек. Стирание во флэш-памяти производится сразу для целой области ячеек (блоками или полностью всей микросхемы). Это позволило существенно повысить производительность в режиме записи (программирования). Флэш-память обладает сочетанием высокой плотности упаковки (ее ячейки на 30% меньше ячеек DRAM), энергонезависимого хранения, электрического стирания и записи, низкого потребления, высокой надежности и невысокой стоимости.
Современная флэш-память имеет время доступа при чтении 35-200 нс, существуют версии с интерфейсом динамической памяти и ... напоминающим интерфейс синхронной статической памяти. Стирание информации (поблочное или во всей микросхеме) занимает 1-2 сек. Программирование (запись) байта занимает время порядка 10 мкс, причем шинные циклы при записи - нормальные для процессора (не растянутые, как для EPROM и EEPROM)."
"Интерфейс микросхем флэш-памяти хорошо сочетается со стандартными сигналами, используемыми в микропроцессорных системах. Внутренние циклы стирания, записи и верификации (проверки) выполняются автономно от шинных циклов внешнего интерфейса, что является существенным преимуществом перед микросхемами EPROM и EEPROM.
"Первые микросхемы флэш-памяти были предложены фирмой Intel в 1988 году и с тех пор претерпели существенные изменения по архитектуре, интерфейсу и напряжению питания. По организации массива различаются микросхемы:
Bulk Erase - стирание возможно только для всего объема.
Boot Lock - массив разделен на несколько блоков разного размера, стираемых независимо. Один из блоков имеет дополнительные аппаратные средства зашиты от стирания и записи.
Flash File - массив разделен на несколько равноправных независимо стираемых блоков обычно одинакового размера, что позволяет их называть микросхемами с симметричной архитектурой SA (Symmetrical Architecture)."
"Микросхемы Boot Lock специально предназначены для хранения BIOS, а привелигерованный блок (Boot Block) хранит минимальный загрузчик, позволяющий загрузить (например с дискеты) и выполнить утилиту программирования основного блока флэш-памяти. В обозначении этих микросхем присутствует суффикс T (Top) или B (Bottom), определяющий положение Boot-блока либо в старших, либо в младших адресах соответственно. Первые предназначены для процессоров, стартующих со старших адресов (в том числе x86, Pentium), вторые - для стартующих с нулевого адреса.
Микросхемы с небольшим размером стираемого сектора кроме BIOS в блоках параметров могут хранить и конфигурационную информацию (ESCD системы PnP, конфигурацию устройств EISA и MCA). Применение микросхем большого объема позволяет кроме BIOS хранить и дополнительный резидентный код, например, в портативных компьютерах во флэш-память может помещаться ядро ОС (MS-DOS), что позволяет экономить энергию за счет сокращения количества обращений к диску. Гибкость системы, обретаемая при использовании флэш-памяти как носителя BIOS, имеет и негативные обратные стороны - возможность повреждения в случае неудачной записи или записи неподходящей версии и появление новой и достаточно благодатной почвы для вирусов, которые могут незаметно переписать код BIOS в своих диверсионных целях. В связи с этим актуальна защита BIOS от несанкционированного изменения.
Микросхемы флэш-памяти выпускаются многими фирмами. Они различаются по организации, интерфейсу, напряжению питания и программирования, методам защиты и другим параметрам. Лидеры в области разработки и производства флэш-памяти - фирмы AMD, Fujitsu Corporation, Intel Corporation и Sharp Corporation летом 1996 года приняли спецификацию CFI (Common Flash Interface), обеспечивающую совместимость разрабатываемого программного обеспечения с существующими и разрабатываемыми моделями флэш-памяти. По устройству чип флэш–памяти отдаленно напоминает микросхему динамической энергозависимой памяти, только вместо конденсаторов в ячейках памяти установлены полупроводниковые приборы — транзисторы. При подаче напряжения на выводы транзистора он принимает одно из фиксированных положений — закрытое или открытое. И остается в этом положении до тех пор, пока на выводы транзистора не будет подан электрический заряд, изменяющий его состояние. Таким образом, последовательность логических нулей и единиц формируется в этом типе памяти подобно ПЗУ — закрытые для прохождения электрического тока ячейки распознаются как логические единицы, открытые — как логические нули. Таким образом, в самом простом случае ячейка Flash состоит из одного полевого транзистора. Элемент включает в себя специальную электрически изолированную область, называемую «плавающим затвором». Этот термин возник из–за того, что потенциал этой области не является стабильным, что позволяет накапливать в ней электроны (именно здесь и хранится вся информация памяти). Выше «плавающего» находится управляющий затвор, который является неотъемлемой частью при процессе записи/стирания данных памяти. Эта область напрямую соединена с линией слов. Перпендикулярно этой линии располагается линия битов, которая соединена со стоком (при записи данных из этой области транзистора появляется поток электронов). Сток разделяется с истоком специальной подложкой, которая не проводит электрический ток.
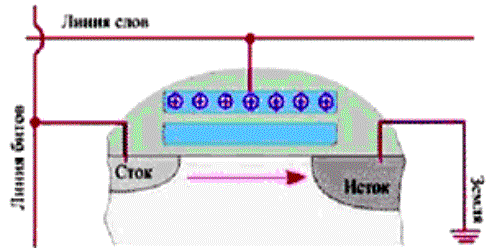
Рис.3. Ячейка Flash памяти
В начале развития Flash каждая ячейка памяти хранила один бит информации и состоила из одного полевого транзистора. Прогресс не стоит на месте, через несколько лет после выпуска чудо–микросхемы были проведены успешные испытания Flash, в которых ячейка хранила уже два бита. Естественно, что на такую память можно было записать в два раза больше информации. В настоящее время уже существуют теоретические разработки памяти с четырехбитными ячейками. Как же устроена такая ячейка? Ведь теоретически наличие заряда в ячейке памяти означает 1, отсутствие 0, остальные значения представить невозможно. Но на самом деле, в микросхеме существует различие величин заряда, которые накапливаются на «плавающем» затворе. Благодаря этому различию, информация в ячейке может быть представлена различными битовыми комбинациями. Величину заряда на затворе можно определить измерением порогового (максимального) напряжения транзистора и по итогам этого измерения представить битовую комбинацию. Перезапись и стирание Flash значительно изнашивает микросхему, поэтому технологии производства памяти постоянно совершенствуются, внедряются оптимизирующие способы записи микросхемы, а также алгоритмы, направленные на равномерное использование всех ячеек в процессе работы. Преимущества флэш-памяти в независимости от наличия или отсутствия электрического питания, в долговременности хранения информации (производители гарантируют сохранность данных на протяжении 10 лет, но на практике должно быть больше) и в высокой механической надежности (в накопителях на базе флэш–памяти нет никаких механических устройств, следовательно, нечему ломаться). Недостатки — в высокой сложности устройства (транзисторы имеют микронные размеры), в невысоком быстродействии (время изменения состояния транзистора больше, чем время заряда–разряда конденсатора) и в относительно высокой стоимости микросхем. Флэш-память быстро прогрессирует. За последние несколько лет появились новые типы микросхем — был осуществлен массовый переход с 5-вольтовой технологии питания на 3,3–вольтовую, были применены новые типы полупроводниковых приборов, разработаны и внедрены в производство механизмы ускорения процедуры записи–чтения информации. Хотя Flash и лидирует на компьютерном рынке, ее могут вытеснить другие новые технологии. Например, новейшая память на кремниевых нанокристаллах. Отличие такой памяти от Flash в следующем: подложка между стоком и истоком состоит из кремниевых нанокристалльных сфер. Такая прослойка предотвращает передачу заряда с одного нанокристалла на другой, повышая таким образом надежность — один дефект не ведет к полному сбою, как в нынешней энергонезависимой памяти на транзисторах с плавающим затвором. Первый в мире работоспособный образец такой памяти был предоставлен компанией Motorola. Ячейки флэш-памяти бывают как на одном, так и на двух транзисторах. В простейшем случае каждая ячейка хранит один бит информации и состоит из одного полевого транзистора со специальной электрически изолированной областью ("плавающим" затвором - floating gate), способной хранить заряд многие годы. Наличие или отсутствие заряда кодирует один бит информации. При записи заряд помещается на плавающий затвор одним из двух способов (зависит от типа ячейки): методом инжекции "горячих" электронов или методом туннелирования электронов. Стирание содержимого ячейки (снятие заряда с "плавающего" затвора) производится методом тунеллирования. Как правило, наличие заряда на транзисторе понимается как логический "0", а его отсутствие - как логическая "1". Современная флэш-память (2006г.) обычно изготавливается по 0,13- и 0,18-микронному техпроцессу. Принцип чтения микросхемы Flash довольно прост и базируется на законах квантовой механики. При извлечении данных из памяти, заряд на “плавающем” затворе отсутствует, а на управляющий затвор подается заряд положительного направления. Под его воздействием между стоком и истоком создается канал трассировки (свободная зона на кристалле транзистора, выделенная для реализации межсоединений ячеек). Все это происходит за счет туннельного эффекта, а данные памяти затем можно считывать с истока.
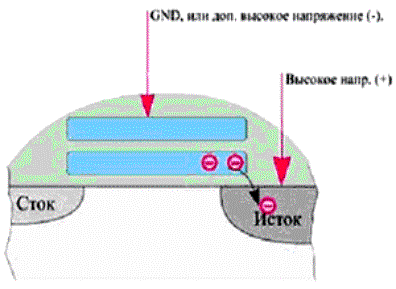
Рис. 4. Чтение данных из ячейки памяти
Если на “плавающем” затворе имеется заряд, то обычного напряжения (которое подается при чтении) недостаточно. Поэтому при записи применяют метод инжекции электронов. Суть его заключается в следующем: на управляющий затвор и исток подается высокое напряжение (причем на затворе оно в два раза выше). Благодаря этому напряжению, электроны способны преодолеть тонкую пленку диэлектрика и попасть на “плавающий” затвор. Такой процесс получил название “инжекция горячих электронов” (термин “горячий” условен, электроны были названы так, потому что обладают высокой энергией, достаточной для преодоления слоя диэлектрика).
Рис.5. Запись данных в ячейку памяти
Чтобы стереть информацию из памяти, достаточно подать высокое положительное напряжение на исток. Под его воздействием отрицательные электроны с “плавающего” затвора (благодаря туннельному эффекту) переходят в область истока. Процесс продолжается до полной разрядки затвора. Ускорить метод туннелирования электронов можно путем подачи дополнительного высокого отрицательного напряжения на управляющий затвор. Эффект туннелирования - один из эффектов, использующих волновые свойства электрона. Сам эффект заключается в преодолении электроном потенциального барьера малой "толщины". Для наглядности представим себе структуру, состоящую из двух проводящих областей, разделенных тонким слоем диэлектрика (обеднённая область). Преодолеть этот слой обычным способом электрон не может - не хватает энергии. Но при создании определённых условий (соответствующее напряжение и т.п.) электрон проскакивает слой диэлектрика (туннелирует сквозь него), создавая ток. Мы рассмотрели простейший случай, когда каждая ячейка Flash хранит один бит информации и состоит из одного полевого транзистора.
Архитектура флэш-памяти и электронных дисков
Организация NOR
Существует несколько типов архитектур (организаций соединений между ячейками) флэш-памяти. Наиболее распространёнными в настоящее время являются микросхемы с организацией NOR и NAND.Название NOR ведет свою родословную от логической операции Not OR (не «или»): если хотя бы один из транзисторов, подключенных к линии битов, включен, то считывается "0". NOR-Ячейки работают сходным с EPROM способом. Каждый транзистор-ячейка подключен к трем линиям: Word Line (линия слов), Select Line (линия выборки) и Bit Line (линия бит). Выборка осуществляется путем подачи высокого напряжения на Word Line, подключенную к затвору, и наблюдения за разницей потенциалов между Select Line (исток) и Bit Line (сток). Если на плавающем затворе находилось достаточное количество электронов, то их отрицательное поле препятствовало протеканию тока между истоком и стоком и напряжение оставалось высоким. Такое состояние полагается в терминах флэш-памяти нулем, в противоположном случае считывается единица. Интерфейс - параллельный. Возможно как произвольное чтение, так и запись. Программирование - методом инжекции "горячих" электронов. Стирание - методом туннеллирования Фаулера-Нордхейма. Преимущества - быстрый произвольный доступ, возможность побайтной записи. Недостатки - относительно медленная запись и стирание.
Организация NAND.
Организация NAND является более выгодной, с точки зрения экономии пространства, способом организации ячеек. Транзисторы подключаются к битовым линиям группами, то есть последовательно. Если все транзисторы группы открыты, включены, Bit Line заземляется, напряжение между ней и Word Line падает до нуля: срабатывает логика Not AND (не «и») - если все элементы равны 1, то выдается 0. Правда, считывание затруднено вследствие падения напряжения на гирлянде транзисторов, однако скорость обращения повышается за счет адресации сразу целой группы битов. При произвольном доступе достоинство превращается в недостаток, и NAND-чипы обычно отличаются от NOR наличием дополнительного внутреннего кэша. Учитывая всё вышесказанное, NAND-память представляет собой наиболее подходящий тип памяти для устройств, ориентированных на блочный обмен: MP3 плееров, цифровых камер и в качестве заменителя жёстких дисков.
Доступ - произвольный, но небольшими блоками, которые можно рассматривать как кластеры жёсткого диска. Интерфейс – последовательный, произвольное чтение и запись невозможны. Не очень подходит для задач, требующих произвольного доступа к данным. Преимущества – запись и стирание информации осуществляются на высокой скорости, размер блока небольшой. Недостатки - относительно медленный произвольный доступ, невозможность побайтной записи, необходимость использовать внутренний кэш. Основные производители - Toshiba, AMD/Fujitsu, Samsung, National, Mitsubishi. Программирование - туннеллированием Фаулера-Нордхейма, в отличие от NOR-памяти. Стирание - туннеллированием Фаулера-Нордхейма, в этом сходство с NOR-памятью.
Развитие технологии флэш-памяти происходит, в основном, в области совершенствования конструкции ячеек. Так, появились варианты с двумя транзисторами: один из пары является обыкновенным транзистором, изолирующим ячейку от Word Line. Благодаря этому удалось избавиться от паразитных перекрестных наводок, возникающих при стирании одной из страниц данных, а также снизить напряжение программирования. Причем второй транзистор занимает совсем немного места, поскольку он лишен функции запоминающего "конденсатора" и большого плавающего затвора. Архитектура флэш-диска. Персональный компьютер, его операционная система MS Windows, «видит» карту флэш–памяти PC card, как обычный сменный накопитель — вроде съемного винчестера. По архитектуре флэш диски (ФД) можно разделить на две большие группы: интеллектуальные, со встроенным микроконтроллером, и без него, то есть неинтеллектуальные. Структурные схемы обоих типов, естественно, имеют общие черты. ФД неинтеллектуального типа содержит интерфейс системной шины, контроллер памяти, генератор напряжения программирования и собственно массив ячеек памяти. Основным узлом является контроллер памяти, работающий под управлением программы FFS и формирующий все внутренние управляющие сигналы. Контроллер чередования позволяет значительно увеличить пиковую скорость записи, что всегда актуально, а для флэш просто необходимо. Он осуществляет попеременный выбор нескольких кристаллов флэш памяти при записи последовательных байт сектора. Выбор осуществляется таким образом, чтобы каждый следующий байт записывался в другой кристалл, т. е. сектор данных распределяется среди нескольких кристаллов, что ускоряет запись в несколько раз. Смысл чередования заключается в том, что запись данных осуществляется параллельно в нескольких корпусах, и соответственно во столько же раз уменьшается суммарное время программирования всего сектора. Однако применение чередования имеет и минусы - увеличение в несколько раз величины блока стирания, что вынуждает FFS интенсивнее проводить сборку мусора. В результате повышаются накладные расходы и возможно уменьшение средней скорости записи и время выполнения команды ввода/вывода. Генератор напряжения VPP (Voltage Programming Pulse) формирует напряжение программирования для флэш-памяти. В современных ФД могут использоваться кристаллы флэш памяти (ФП) с напряжением программирования +5/+12B, хотя существует ФП, которая работает при обоих значениях напряжения. Но скорость записи/стирания при повышенном напряжении значительно выше, чем при пониженном напряжении. Но и энергии потребляется при этом несколько больше. В качестве генератора напряжения программирования обычно используются преобразователи напряжения, так называемые DC/DC-конвертеры. Они имеют вход управления выходным напряжением. Выключенный генератор напряжения программирования обеспечивает дополнительную защиту от несанкционированного изменения содержимого ФП, когда не выполняется операция записи сектора. В некоторых дисках применяются генераторы контрольного кода. Причины и особенности их применения рассмотрим ниже. Упомянем только, что контрольный код можно формировать двумя способами: аппаратно или программно. Первый способ более быстрый, но он увеличивает стоимость диска. При втором способе вся нагрузка по генерации контрольного кода при записи и чтении данных ложится на операционную систему, что требует соответствующих ресурсов, зато это несколько дешевле. Исправление же обнаруженных ошибок в обоих случаях производится операционной системой.
ФД интеллектуального типа отличается наличием встроенного микроконтроллера, который имеет собственные ОЗУ, ПЗУ и выполняет программу FFS. Такой накопитель имеет интерфейс дискового устройства, электрически и логически эмулирующий для центральной системы устройство памяти с интерфейсом IDE или SCSI, и "откликается" на стандартные процедуры BIOS. Его особенностью является то, что весь обмен данными между оперативной памятью и массивом ФП осуществляется только через буферное ОЗУ, а у неинтеллектуальных ФД - непосредственно. При использовании подобной архитектуры загрузка центрального процессора и системной шины минимальна и обусловлена практически только пересылкой сектора данных между ОЗУ системы и буферным ОЗУ. Выполнение программы FFS, пересылка блока данных для массива ФП, сборка мусора, формирование контрольного кода и исправление обнаруженных ошибок скрыты от центрального процессора. Существует еще одно положительное свойство. В этом случае программа FFS не занимает оперативной памяти. Теперь о недостатках. Встроенный контроллер повышает стоимость ФД и, главное, занимает драгоценное место в накопителе. Быстродействие же его, по сравнению с центральным процессором, значительно меньше. Соответственно, и время выполнения команд программы FFS, обнаружение и исправление ошибок медленнее. Во-вторых, вся передача секторов данных осуществляется в два приема с использованием буферного ОЗУ. Последний вопрос архитектуры ФД связан с применением методов сжатия данных. Несколько лет назад этот вопрос был актуальным для жестких дисков, и выход тогда был найден в применении принципа сжатия информации с использованием отдельных утилит либо системных драйверов, обеспечивающих сжатие всех записываемых на диск данных. В последнем случае при чтении данных с диска этот же драйвер обеспечивает восстановление исходных данных в первоначальном виде. Единственный видимый недостаток выражается в некотором замедлении работы с диском, что, однако, быстро компенсируется возрастающей мощностью центральных процессоров. Для флэш-диска вопрос применения сжатия информации является одним из самых актуальных - емкости существующих накопителей недостаточно велики, чего никак нельзя сказать об их стоимости, да и скорость записи данных пока оставляет желать лучшего. Применение сжатия информации, конечно, не увеличит емкость диска, но зато уменьшит достаточно высокую стоимость ее хранения. Существует еще одно, более важное основание для применения сжатия. Это возможность увеличения скорости записи. Конечно, физически скорость записи не изменится. Но если скорость рассматривать как соотношение величины переданной на ФД информации ко времени записи, то, безусловно, она возрастет. Для флэш-диска могут быть реализованы два варианта сжатия. В первом случае сжатие данных производится на уровне сектора, причем уменьшается только количество записываемых в сектор данных, сама же величина сектора остается неизменной. Тогда имеется только выигрыш по скорости записи данных, но не по объему запоминаемой информации. Во втором случае сжатие данных применяется уже на системном, файловом уровне. Это приводит к увеличению и пропускной способности флэш-диска, и количества запоминаемой информации.
Иерархическая структура памяти
В вычислительных устройствах и системах используется разделение памяти на уровни. Каждый уровень служит для согласования менее быстродействующих средств памяти с более быстродействующими. Устройство памяти связанно с процессором системой быстродействующих шин. Скорость передачи данных определяется соотношением скоростных характеристик памяти наиболее высокого и самого низкого уровня. Многоуровневая структура памяти может строится по линейной, центральной, магистральной и смешанной схеме.
Организация памяти однопроцессорных систем
Наиболее распространенной для однопроцессорных систем является схема линейной иерархии памяти.
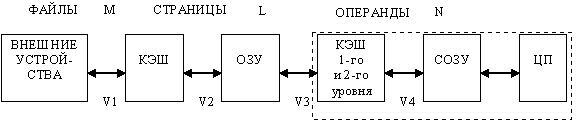
Рис.1. Схема иерархии памяти однопроцессорных систем
Каждый уровень служит для согласования менее быстродействующих устройств памяти с более быстродействующими
КЭШ первого и второго уровней входит в структуру центрального процессора. Обмен данными между процессором и сверхоперативным запоминающим устройством СОЗУ осуществляется словами.
На каждом уровне иерархии необходимо так организовать передачу данных, чтобы общий объем передаваемых в единицу времени данных был равен или превышал запросы процессора.
Пусть M - количество обращений в единицу времени к одному файлу
L - количество обращений в единицу времени к одной странице
N - количество обращений в единицу времени к одному операнду
V1, V2, V3, V4 -- соответственно скорости передачи данных на разных уровнях иерархии памяти.
Значения M, N, L определяются программным обеспечением вычислительной системы и алгоритмом работы программы.
Для согласования скоростей передачи данных необходимо выполнить соотношение:
V4
/ V1
![]() N / M
,
соответственное
согласование должно происходить на
каждой ступени иерархии.
N / M
,
соответственное
согласование должно происходить на
каждой ступени иерархии.
Аппаратная сложность определяется общим количеством программ и общим количеством страниц которое может обслуживать система. С развитием архитектуры компьютера и ростом сложности выполняемых программ возрастает требуемый объем памяти.
Центральная схема иерархии памяти :
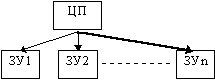
Рис.2. Центральная схема иерархии памяти
Центральная схема иерархии памяти используется, если к процессору подключается несколько внешних запоминающих устройств, требующих автономной работы.
Магистральная схема иерархии памяти
Получила распространение в связи с развитием систем хранения данных, применяется, например для организации RAID системы (матрицы недорогих дисков для хранения информации, организации быстрого доступа, горячей замены неисправного диска)
Рис.3. Магистральная схема иерархии памяти
Смешанная схема иерархии памяти
В этой схеме для передачи данных между процессором и запоминающими устройствами используется дополнительный буфер (кэш), через который производится обмен данными. В этом случае данные для обмена с процессором предварительно записываются в буфер и процессор не теряет времени на ожидание, как при обмене с медленными внешними устройствами.
Рис.4. Смешанная схема иерархии памяти.
Система управления памятью. Организация виртуальной памяти
Система управления памятью должна обеспечить многопрограммный режим работы, используя аппаратные средства распределения оперативной памяти.
Существует два способа распределения памяти : статический и динамический.
При работе в многопрограммном режиме и статическом распределении оперативной памяти выделяется определенная область фиксированной памяти независимо от требований задачи.
При статическом распределении памяти используется статическая адресация, т.е. используется базовый адрес и смещение. При каждой загрузке программы ей назначается базовый адрес в области оперативной памяти.
При динамическом распределении оперативной памяти - выделяется необходимый объем памяти по запросу с учетом потребности задачи. Параллельность процессов обмена и обработки данных приводит к тому, что к оперативной памяти может обращаться несколько устройств (или программ) одновременно, потому требуется организовать очередь обслуживания и использовать концепцию виртуальной памяти. Один из компонентов ядра операционной системы - диспетчер памяти - организует трансляцию виртуальных адресов, используемых программами и другими компонентами ядра, в реальные адреса физической памяти.
Организация виртуальной памяти
Виртуальная память (Virtual Memory) представляет собой программно-аппаратное средство расширения пространства памяти, предоставляемой программе в качестве оперативной. Эта память физически реализуется в оперативной и дисковой памяти под управлением соответствующей операционной системы. Требуется так организовать работу процессора с дисковой памяти, чтобы возникала иллюзия работы только с оперативной памятью.
Виртуальное пространство памяти разбито на страницы фиксированного размера, а в физической оперативной памяти в каждый момент времени присутствует только часть из них. Остальные страницы хранятся на диске, откуда операционная система может "подкачать" их в физическую память, предварительно выгрузив на диск часть неиспользуемых в данный момент модифицированных страниц. Обращение процессора к ячейке виртуальной памяти, присутствующей в физической памяти, происходит обычным способом. Если же затребованная область в данный момент не отображена в физической памяти, процессор вырабатывает исключение (внутреннее прерывание), по которому операционная система программно организует замещение страниц, называемое свопингом (Swapping). Виртуальную память поддерживают процессоры, работающие в защищенном режиме, начиная с 80286, но реально ее широко стали использовать только в операционных системах и оболочках для 32-разрядных процессоров (80386 и далее). Максимальный объем виртуальной памяти определяется размером файла подкачки (Swap File), выделяемом на жестком диске для нужд виртуальной памяти.
Общепринятая в настоящее время концепция виртуальной памяти появилась в те далекие времена, когда вычислительные системы, научившись выполнять одну программу стали переходить на новый режим работы - работу в многозадачном (мультипрограммном) режиме. Концепция виртуальной памяти позволила решить целый ряд актуальных вопросов организации вычислений. Встал вопрос о том, как разделить между разными задачами небольшой объем оперативной памяти, чтобы каждая задача выполнялась также, как она выполнялась бы в однопрограммном режиме и как управлять при этом распределением памяти. К этому времени у программистов уже накопился опыт выполнения задач, программный код которых не помещался в слишком маленькую оперативную память. Программистам пришлось делить такие программы на части и затем выполнять части программы независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из нее под управлением программы пользователя. Система организации виртуальной памяти освободила программистов от этой работы. Она автоматически управляет обменом между двумя уровнями иерархии памяти: основной памятью и внешней (дисковой) памятью. В многопрограммном режиме работы компьютер выполняет множество задач, каждой из которых отводится свое адресное пространство в оперативной памяти. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память делит физическую память на блоки и распределяет их между различными задачами. При этом обеспечивается иллюзия того, что каждая задача и в самом деле исполняется на машине с огромным количеством реальной оперативной памяти. Системы виртуальной памяти можно разделить на два класса: системы с фиксированным размером блоков, называемых страницами, и системы с переменным размером блоков, называемых сегментами. Очевидно, что для реализации возможности автоматического выделения памяти каждой задаче в процессе ее выполнения (динамически), необходимо обеспечить эту возможность аппаратно. Для того, чтобы программа могла действительно воспользоваться виртуальной памятью (иллюзией очень большого количества реальной оперативной памяти) требуется еще и поддержка программного обеспечения. Задача управления виртуальной памятью возлагается на операционную систему. Различные операционные системы по разному решают вопросы управления памятью. Попробуем получить общее представление о работе виртуальной памяти. Механизмы управления памятью решают две главные задачи:
Трансляцию виртуального адресного пространства процесса на физическую память. Это позволяет ссылаться на конкретные адреса физической памяти потокам процесса, работающим в виртуальном адресном пространстве.
Подкачку части содержимого памяти с диска, когда потоки пытаются задействовать больший объем физической памяти, чем тот, который имеется в наличии, и выгрузку страниц обратно по мере необходимости. Виртуальная память может использовать страничную и сегментную адресации. При использовании страничной адресации в специальные сегментные регистры процессора загружаются селекторы, базовые адреса которых равны нулю, а размер сегмента составляет 4 Гбайта. И хотя для микропроцессора механизм сегментной адресации продолжает работать, основным механизмом формирования адреса становится страничная адресация. Такая модель памяти и называется плоской (FLAT). Логическая адресация в такой модели определяется только смещением. Для программиста область памяти, адресуемая смещением, находится в полном распоряжении. Это и есть логический адрес, который преобразуется операционной системой в физический.
Страничный механизм является составной частью системы виртуальной памяти. Страничное преобразование позволяет сохранить линейность адресов для прикладных программ, несмотря на то, что их работающие страницы располагаются в оперативной памяти в произвольном порядке. Программы работают со своим адресным пространством, так словно у каждой из них есть своя собственная линейно адресуемая оперативная память. Применительно к виртуальной памяти различают три адресных пространства: логическое, линейное и физическое.
Логический адрес формируется при обращении к виртуальному адресному пространству. Блок сегментации транслирует логический адрес в линейный. Физический адрес образуется после преобразования линейного адреса блоком страничной переадресации. И так, выполняемая программа загружается в оперативную память не целиком, а отдельными страницами (рис1.). Страница с которой работает процессор называется активной.
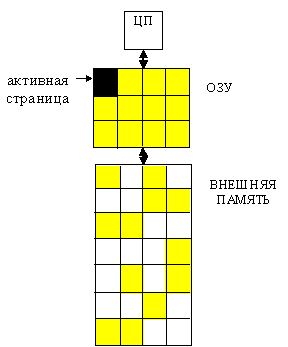
Рис.1. Отражение страниц дискового пространства на пространство оперативной памяти.
В случае динамического распределения памяти (по запросу программы), адрес содержит номер виртуальной страницы и номер слова в странице. Для защиты памяти от записи и чтения другими процессами необходима соответствующая схема трансляции адреса, которая разрешает доступ к данной области памяти только определенной задаче. Соответствие между физическим положением данных в памяти и адресом существует только для основной (оперативной) памяти, виртуальная память использует всю иерархическую структуру памяти как непрерывно адресуемую. Для переадресации используется глобальная ( GDT) и локальная (LDТ) таблицы переадресации.
Динамическая трансляция виртуального адреса в реальный
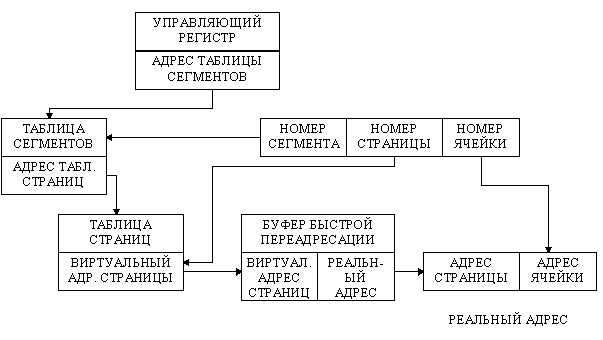
Рис.2. Преобразование виртуального адреса
Рассмотрим систему переадресации с сегментацией памяти (рис2.). В глобальной таблице компьютера хранятся сведения о нахождении таблицы сегментов каждой задачи. Адрес таблицы сегментов для выполняемой задачи загружается в управляющий регистр. По адресу таблицы и номеру сегмента виртуального адреса определяется адрес таблицы страниц. По адресу таблицы страниц и номеру страницы виртуального адреса определяется адрес страницы в таблице страниц (виртуальный адрес, который преобразуется в реальный в буфере быстрой переадресации). Из буфера быстрой переадресации считывается реальный адрес страницы. Полный реальный адрес равен реальному адресу страницы плюс номер ячейки памяти (смещение в странице). Если разбиение на сегменты не используется, то для трансляции логического адреса используется двухуровневая таблица страниц. Виртуальный адрес интерпретируется как совокупность 3 элементов: указателя каталога страниц, указателя таблицы страниц и указателя слова на странице. У каждого процесса (каждой задачи) есть один каталог страниц, который содержит адреса всех таблиц страниц для данного процесса. Указатель каталога страниц применяется для поиска каталога, из каталога определяется указатель таблицы страниц для данного процесса, по указателю таблицы страниц находится нужная таблица, из которой читается адрес, содержащий указатель для требуемой страницы (ее физический адрес). Остается определить реальный адрес данных, расположенных на этой странице. Указатель слова позволяет найти конкретный адрес на физической странице. Но что делать, если количество страниц во всех линейных адресных пространствах выполняемых процессов превышает объем оперативной памяти и поэтому невозможно поставить в соответствие каждой из них свою страницу реальной памяти? Для решения этой проблемы дополнительно ведется учет присутствия страницы в физической памяти (вводится дескриптор страницы где предусмотрен флаг (бит) реального присутствия страницы в оперативной памяти). Наличие такого бита позволяет отметить часть страниц, непомещающихся в физической памяти, как временно отсутствующие. Если происходит обращение к такой странице, то процессор формирует прерывание. Получив прерывание по отсутствию страницы, операционная система может записать одну из присутствующих в памяти страниц на диск и отметить ее как временно отсутствующую во всех адресных пространствах, в которых она была видна. На освободившееся место с диска считывается та страница, из-за которой произошло прерывание. Заполняются все таблицы, по которым ведется поиск данной страницы и в дескрипторе страницы устанавливается флажок ее реального присутствия в оперативной памяти. После возврата из программы - обработчика прерывания процессор повторит попытку доступа к памяти, но теперь нужная страница уже отмечена как присутствующая и прерывания не произойдет. Если вновь потребуется та страница, которая была записана на диск, то снова произойдет прерывание, ведь эту страницу пометили как временно отсутствующую в памяти. В ответ на это прерывание на диск будет перемещена еще какая-нибудь страница, а на ее место с диска будет загружена требуемая. Этот процесс называется страничным обменом или свопингом (paging или swapping). Страницы, помещаемые на диск хранятся в специальном файле, файле подкачки (swap-файле). Взаимодействие с файлом подкачки происходит значительно медленнее, чем с оперативной памятью компьютера, поэтому оптимизация работы с этим файлом зачастую дает возможность увеличить скорость работы системы памяти. Теоретически, наиболее оптимальным считается объем файла подкачки, превышающий объем установленной на компьютере оперативной памяти примерно в два раза. Если страница не изменялась с момента последнего считывания с диска, то при ее замене другой страницей нет необходимости повторно записывать ее на диск. Можно просто пометить ее как отсутствующую. Для слежения за изменением страницы современные процессоры поддерживают еще один флаг в дескрипторе страницы. Другой важный флаг, который поддерживается аппаратурой процессора - это флаг обращения. Он устанавливается всегда, когда происходит обращение к странице на чтение или запись. Операционная система может время от времени просматривать страничные таблицы, проверять и сбрасывать этот бит, выявляя те страницы, которые часто используются программами.
Для того, чтобы уменьшить количество дисковых операций, операционная система использует ту или иную стратегию страничного обмена. Оптимальная стратегия состоит в том, чтобы возвращать на диск ту страницу, которая дольше всего не понадобиться программам. Одной из лучших стратегий страничного обмена является LRU (Least Recently Used). Алгоритм LRU предполагает, что на диск надо переносить ту страницу, которая дольше всего не использовалась. Существуют и более сложные алгоритмы, но обычно они базируются на LRU. В некоторых случаях операционная система заранее знает, что определенные страницы, которые сейчас находятся на диске, понадобятся ей (или прикладным программам) в ближайшее время. Тогда она может заранее перенести их в оперативную память, не дожидаясь прерываний по отсутствию страницы. Такая операция называется страничной предвыборкой (page prefetch). Аналогичный прием может быть использован и для записи на диск пассивных страниц раньше, чем будет затребовано место, занимаемое этой страницей.
Распределение памяти.
С развитием вычислительной техники и ростом разрядности системной шины изменялась система адресации и доступное процессору адресное пространство. Логическая структура памяти персонального компьютера обусловлена особенностями системы адресации процессоров семейства Ix86. Процессоры 8086/88 имели доступное адресное пространство 1 Мбайт (20- битная шина адреса). Эти процессоры использовали сегментную модель памяти, унаследованную и следующими моделями в реальном режиме. Согласно этой модели исполнительный (линейный) адрес вычисляется по формуле Addr = Seg + Offset, где Seg и Offset - содержимое сегментного и адресного регистров. Таким образом, обеспечивался доступ к адресному пространству Addr = 00000 - FFFFFh при помощи пары 16-битных регистров. Заметим, что при Seg = FFFFh и Offset = FFFFh данная формула дает адрес 10FFEFh, но ввиду 20-битного ограничения на шину адреса эта комбинация в физической памяти указывает на 0FFEFh. Таким образом, адресное пространство как бы сворачивается в кольцо с небольшим "нахлестом". Начиная с процессора 80286, шина адреса была расширена до 24 бит, а впоследствии (386DX, 486 и выше) до 32 и 36 (у процессоров P6), 64 разряда имеет шина адреса у современных процессоров. В реальном режиме процессора, применяется сегментная модель памяти и формально доступен лишь 1 Мбайт памяти. Однако выяснилось, что в работе процессоров 80286 в реальном режиме (режим эмуляции работы процессора 8086) была обнаружена ошибка. Единица в бите A20, которая отбрасывалась в процессорах 8086/88, теперь попадала на шину адреса, и в результате максимально доступный линейный адрес в реальном режиме достиг 10FFEFh. Появилась возможность использовать в реальном режиме дополнительные 64 К байт оперативной памяти. В эту область (100000h - 10FFEFh), названную "высокой памятью" - High Memory Area (HMA), стали помещать часть операционной системы. Для обеспечения полной совместимости с процессором 8086/88 в схему персонального компьютера ввели вентиль линии A20 шины адреса - GateA20, который либо пропускает сигнал от процессора, либо принудительно обнуляет линию A20 системной шины адреса. Более старшие биты такой "заботы" не требуют, поскольку переполнение при суммировании 16-битных компонентов адреса по данной схеме до них не распространяется. Управление этим вентилем подключили к свободному программно-управляемому выходному биту 1 контроллера клавиатуры 8042, ставшего стандартным элементом архитектуры персонального компьютера. Предполагалось, что этим вентилем часто пользоваться не придется, но оказалось, что переключение вентиля в многозадачных ОС, часто переключающих процессор между защищенным режимом и реальным режимом контроллером клавиатуры выполняется слишком медленно. Появились методы быстрого переключения вентиля, специфичные для различных реализаций системных плат (например, через порт 92h). Кроме того, иногда использовали и аппаратную логику быстрого декодирования команды на переключение бита, поступающую к контроллеру клавиатуры. Для определения способа переключения в утилиту CMOS Setup ввели соответствующие параметры, позволяющие выбрать между стандартным, но медленным способом и менее стандартизованным, но быстрым, в зависимости от используемого программного обеспечения. Для упрощения внешних схем в процессоры, начиная с 486, ввели и вентиль GateA20 с соответствующим внешним управляющим выводом. 32-разрядные процессоры позволили организовать режим, называемый "большим реальным", в котором инструкции выполняются как в реальном, но доступны все 4 гигабайта памяти (для 32- разрядного адреса). Этот режим стали использовать в игровых программах, целиком захватывающих все ресурсы компьютера. Основную часть адресного пространства занимает оперативная память. Объем установленной оперативной памяти определяется тестом POST при начальном включении компьютера, начиная с младших адресов. Натолкнувшись на отсутствие памяти (ошибку), тест останавливается на достигнутом и сообщает системе объем реально работающей памяти. Распределение памяти персонального компьютера, непосредственно адресуемой процессором Распределение памяти персонального компьютера, непосредственно адресуемой процессором (рис.1), представляется следующим образом.
00000h-9FFFFh - Conventional (Base) Memory, 640 Кбайт - стандартная (базовая) память, доступная DOS и программам реального режима.
A0000h-FFFFFh - Upper Memory Area (UMA), 384 Кбайт - верхняя память, зарезервированная для системных нужд. В ней размещаются области буферной памяти адаптеров (например, видеопамять) и постоянная память (BIOS с расширениями).
Память выше 100000h - Extended Memory - дополнительная (расширенная) память, непосредственно доступная только в защищенном (и в "большом реальном") режиме для компьютеров с процессорами 286 и выше. В ней выделяется область 100000h-10FFEFh - высокая память, HMA, - единственная область расширенной памяти, доступная 286+ в реальном режиме при открытом вентиле Gate A20.
Область памяти выше первого мегабайта будем называть дополнительной памятью. Ее объем у современных компьютеров указывается строкой Extended Memory xxxxx Kbyte в таблице, выводимой после прохождения теста POST, и в меню стандартной конфигурации CMOS Setup. Вышеприведенное разделение памяти актуально только для приложений и операционных систем реального режима типа MS-DOS. Для ОС защищенного режима доступна вся оперативная память.
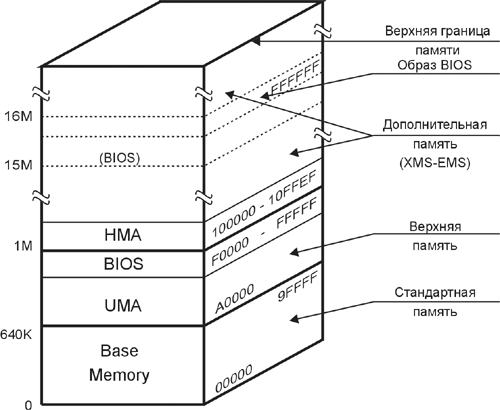 Рис.1.
Распределение памяти PC
Рис.1.
Распределение памяти PC
Для компьютеров класса AT-286 с 24-битной шиной адреса верхняя граница оперативной памяти определялась- FDFFFFh (максимальный размер 15,9 Мбайт). Область FE0000h-FFFFFFh - область ПЗУ BIOS (ROM BIOS Area), обращение к этой области эквивалентно обращению к ROM BIOS по адресам 0E0000h-0FFFFFh. Для 386+ процессоров и 32-битной шины адреса теоретическая верхняя граница - 4 Гбайт, а для P6 - 64 Гбайт (36-битная шина адреса), для современных процессоров верхней границы практически не существует. В компьютерах с 32-разрядной шиной адреса образ BIOS дополнительно проецируется в адреса FFFE0000h-FFFFFFFFh. Реально современные системные платы позволяют установить до 512-2048 Мбайт ОЗУ, для серверных платформ это не предел. Обращение по адресам, превышающим границу установленной оперативной памяти (или максимально возможного объема), транслируется на шину PCI, которая имела 32-битную адресацию ( теперь 64- битную). Компьютеры, использующие режим системного управления SMM (System Management Mode), имеющийся у большинства процессоров последних поколений, имеют еще одно адресное пространство памяти - SMRAM. Это адресное пространство доступно процессору только в режиме обработки прерывания от системы управления SMI. Память SMRAM может представлять собой часть физической оперативной памяти, или может быть реализована и специальной микросхемой энергонезависимой памяти. Ее размер может варьироваться в диапазоне от 32 Кбайт (минимальные потребности SMM) до 4 Гбайт. SMRAM располагается, начиная с адреса SMIBASE (по умолчанию 30000h), и распределяется относительно адреса SMIBASE следующим образом.
FE00h-FFFFh (3FE00h-3FFFFh) - область сохранения контекста (распределяется, начиная со старших адресов по направлению к младшим). По прерыванию SMI сохраняются почти все регистры процессора, но сохранение регистров FPU ( АЛУ с плавающей точкой) не производится.
8000h (38000h) - точка входа в обработчик (SMI Handler).
0-7FFFh (30000h-37FFFh) - свободная область.
Стандартная память - Conventional Memory
Стандартная память является самой дефицитной в PC, когда речь идет о работе в среде операционных систем типа MS-DOS. На ее небольшой объем (типовое значение 640 Кбайт) претендуют и BIOS, и ОС реального режима, а остатки отдаются прикладному ПО. Стандартная память распределяется следующим образом:
00000h-003FFh - Interrupt Vectors - векторы прерываний (256 двойных слов);
00400h-004FFh - BIOS Data Area - область переменных BIOS;
00500h-00xxxh - DOS Area - область DOS;
00xxxh-9FFFFh - User RAM - память, предоставляемая пользователю (до 638 Кбайт); при использовании PS/2 Mouse область 9FC00h-9FFFFh используется как расширение BIOS Data Area, и размер User RAM уменьшается.
Верхняя память - UMA
Верхняя память имеет области различного назначения, которые могут быть заполнены буферной памятью адаптеров, постоянной памятью или оставаться незаполненными. Раньше эти "дыры" не использовали из-за сложности "фигурного выпиливания" адресуемого пространства. С появлением механизма страничной переадресации (у процессоров 386 и выше) их стали по возможности заполнять "островками" оперативной памяти, названными блоками верхней памяти UMB (Upper Memory Block). Эти области доступны DOS для размещения резидентных программ и драйверов через драйвер EMM386, который отображает в них доступную дополнительную память. Стандартное распределение верхней памяти выглядит следующим образом (рис. 2).
A0000h-BFFFFh - Video RAM, 128 Кбайт - видеопамять (обычно используется не полностью).
C0000h-DFFFFh - Adapter ROM, Adapter RAM, 128 Кбайт - резерв для адаптеров, использующих собственные модули ROM BIOS или (и) специальное ОЗУ, разделяемое с системной шиной.
E0000h-EFFFFh - свободная область, 64 Кбайт, иногда занятая под System BIOS.
F0000h-FFFFFh - System BIOS, 64 Кбайт - системная BIOS.
FD000h-FDFFFh - ESCD (Extended System Configuration Data) - область энергонезависимой памяти, используемая для конфигурирования устройств Plug and Play.
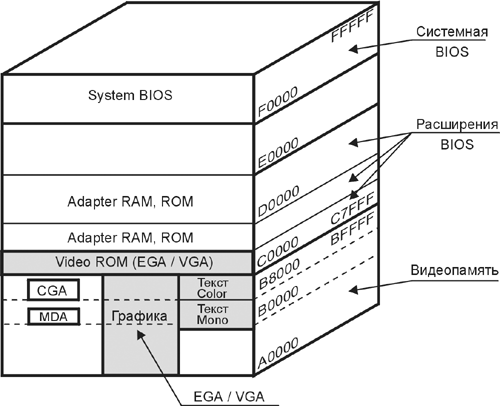 Рис.
2. Распределение верхней памяти (UMA)
Рис.
2. Распределение верхней памяти (UMA)
В области UMA практически всегда присутствует графический адаптер. Также распространенным потребителем UMA являются расширения ROM BIOS, расположенные на платах дисковых контроллеров и микросхемы удаленной загрузки (Boot ROM) на платах адаптеров ЛВС. Обычно они занимают область C8000h - CBFFFh/C9FFFh/C8FFFh (для дисковых контроллеров), но могут и перемещаться при конфигурировании адаптеров. Размер области, занимаемой системной ROM BIOS, колеблется от 8 Кбайт у PC/XT до 128 Кбайт, однако разумное значение - 64 Кбайт. Большая область использовалась "на радостях" от появления микросхем ROM и флэш-памяти объемом 1 Мбит (128К x 8), но при этом размер доступной UMA сократился. Тогда стали микросхемы того же (и большего) объема отображать только на область F0000h-FFFFFh (64 Кбайт), а иногда и меньшую. Это оказалось возможным, поскольку не все содержимое микросхемы ROM BIOS должно быть доступно одновременно. Таким способом удалось примирить интересы пользователей UMB с необходимостью расширения объема BIOS, связанной с усложнением технических средств.
Теневая память - Shadow ROM и Shadow RAM
В области верхней памяти UMA обычно располагаются устройства с медленной памятью: системная BIOS (System ROM BIOS), расширения BIOS на графическом адаптере (Video ROM BIOS), на контроллерах дисков и интерфейсов (Adapter ROM), ПЗУ начальной загрузки на сетевой карте (Boot ROM), видеопамять (Video Memory Buffer). Они, как правило, реализованы на 8- или 16-битных микросхемах с довольно большим временем доступа. Обращение к полноразрядному системному ОЗУ выполняется гораздо быстрее. Для ускорения обращений к памяти этих устройств применяется теневая память (Shadow Memory) - подмена ее системным ОЗУ. Теневая память появилась на развитых моделях AT-286, где она была реализована аппаратно. Процессоры класса 386+ позволили реализовать ее программно, с помощью страничной переадресации. Затенение ОЗУ и ПЗУ устройств выполняется по-разному. При инициализации теневого ПЗУ (Shadow ROM) содержимое затеняемой области копируется в ОЗУ, и при дальнейшем чтении по этим адресам подставляется ОЗУ, а запись в эту область блокируется. При использовании теневого ОЗУ (Shadow RAM) запись производится одновременно в физическую память затеняемой области и в системное ОЗУ, наложенное на эту область. При чтении затененной области обращение идет только к системной памяти, что происходит гораздо быстрее. Особенно велик эффект от затенения видеопамяти старых графических адаптеров, которая по чтению была доступна только во время обратного хода развертки, и процессору приходилось долго ждать этого момента. Однако затенение областей разделяемой памяти, модифицируемых со стороны адаптеров, недопустимо - эти изменения не будут восприняты процессором. К разделяемой относится буферная память сетевых адаптеров, видеопамять адаптеров с графическими сопроцессорами (акселераторами). Из этого следует, что затенение видеопамяти было применимо только к примитивным графическим картам, и то не во всех режимах. Обычно теневая память включается через CMOS Setup отдельными областями размером по 16 Кбайт или более крупными, и для каждой области указывают режим затенения (Shadow ROM или Shadow RAM). На современных системных платах затенение области системной BIOS выполняется всегда, на старых платах затенением этой области можно было управлять. Затенение BIOS видеоадаптера (Video BIOS Shadowing) для работы в среде Windows с "родными" драйверами графического адаптера может и не давать прироста производительности. Все программные настройки, влияющие на объем доступной памяти, кроются в файлах CONFIG.SYS и AUTOEXEC.BAT, размещенных в корневом каталоге загрузочного диска. Резидентные драйверы (русификаторы клавиатуры, экрана и принтера, драйвер мыши) по умолчанию обычно загружаются в стандартную память. Увеличение физического объема оперативной памяти в ряде случаев может привести к неожиданному снижению производительности компьютера. Это возможно, когда системная плата (или процессор со вторичным кэшем) не способна кэшировать весь объем ОЗУ. У многих системных плат для процессоров Pentium кэшируются только первые 64 Мбайт ОЗУ; у первых процессоров Pentium II кэшировались только 512 Мбайт. Память, выходящая за размеры кэшируемой области, конечно же доступна, но ее производительность гораздо ниже кэшируемой. ОС Windows 9x распределяет память, начиная с верхней границы доступной памяти, причем наверх попадает ее ядро, скорость работы которого существенна для работы многих приложений. Если после увеличения ОЗУ ядро попадает в некэшируемую область, можно наблюдать снижение производительности.
Как операционная система использует память? Рассмотрим использование памяти операционной системой Windows. Оперативная память, к которой непосредственно может обратиться процессор образует адресное пространство. 32-разрядное адресное пространство в процессорах 80386 и старше делится на страницы памяти размером 4 Кб каждая. Управление каждой из этих страниц осуществляется независимо от других. Реальное (физическое) адресное пространство доступно только ядру (основным программам) операционной системы и программам драйверам (обеспечивающим управление работой внешних устройств), лишь они могут непосредственно обратиться к физической памяти. Другие компоненты системы и все прикладные программы работают в виртуальных адресных пространствах, с виртуальными адресами.
Все виртуальное адресное пространство программ делится на четыре области. Первая область занимает диапазон адресов от нуля до 4 Мб и недоступна для программ управляемых Windows. Здесь располагаются адреса подпрограмм обработки прерываний, программы ДОС и драйверы внешних устройств.
Область от 4 Мб до 2 Гб является рабочим пространством программ. Каждой программе отводится свое адресное пространство.
Третий гигабайт используется как виртуальное адресное пространство, общее для всех программ и для системы. В эту область Windows загружает свое графическое ядро, а также динамические библиотеки. Фактически эти модули находятся в реально имеющейся физической памяти в области гораздо меньших адресов, но нужен механизм, дающий программам возможность обращаться к системным модулям. Виртуализация памяти и является таким механизмом.
Четвертый гигабайт (адреса C0000000-FFFFFFFF) также является общим для всех программ и для системы. В него система загружает свое ядро, драйверы и другие модули, работающие на уровне ядра (если такие модули имеются в системе). В этом адресном пространстве выделяется также область памяти, используемая дисковой кэш памятью (VCACHE). В этом же гигабайте находятся адреса памяти (реальные, а не виртуальные) тех устройств ввода-вывода, которым предоставляется возможность прямого доступа к памяти. Модуль VCACHE впервые появился в Windows 3.11 для рабочих групп, вышедшей в 1993 году. В первой IBM PC, выпущенной в 1980 году, стояло 64 Кб ОЗУ, а в 1993 году нормой были компьютеры с четырьмя мегабайтами оперативной памяти. В 2006 обычной стала память 256 - 512 Мб.
Под кэш жесткого диска было выделено линейное виртуальное адресное пространство и затем средствами диспетчера памяти содержимое кэш отображалось на реально используемую физическую память. Поэтому на этапе загрузки системы часть адресного пространства в четвертом гигабайте резервируется под использование дисковой кэш памятью. Размер этой части зависит от версии операционной системы, от некоторых характеристик оборудования и от количества оперативной памяти, установленной в компьютере. Еще одно использование четвертого гигабайта - обеспечение доступа к памяти устройств. По-прежнему прямая запись осталась наиболее быстрым способом обращения к устройству, только адреса памяти устройств были вынесены из первого мегабайта в конец адресуемой области, в тот же самый четвертый гигабайт. В четвертом гигабайте выделяется адресное пространство и для виртуальных машин ДОС, в которых выполняются программы для ДОС. При этом возникает необходимость в двойной переадресации: когда программа обращается к адресу в первом мегабайте, вместо него подставляется соответствующий адрес виртуальной машины (в четвертом гигабайте), а поскольку этот адрес виртуальный, то происходит вторая переадресация - на адрес физической памяти, в котором находится нужная страница виртуальной машины. Такова плата за поддержку старых программ. Впрочем, на деле накладные расходы оказываются невелики. Влиять на использование адресов памяти устройствами операционная система, как правило, не может - эти адреса в большинстве случаев зафиксированы самим оборудованием.
Распределение памяти при загрузке Windows. Самый первый этап - загрузка ДОС. Затем из нее запускается ядро Windows - VMM.VXD. Этот файл содержит много модулей, и один из них - диспетчер виртуальных машин (именно он управляет распределением памяти) по своей структуре является обычной программой для ДОС. Но только по структуре и только для того, чтобы его можно было запустить из ДОС. После своего запуска он переводит процессор в защищенный режим и использует ДОС преимущественно как драйвер различных устройств, в первую очередь диска и видеоадаптера. Затем диспетчер виртуальных машин начинает загружать в память другие модули (драйверы), находящиеся в файле VMM.VXD, драйверы, на которые есть ссылки в реестре или в файле system.ini, а также затребованные ранее загруженными программами для ДОС. Но тут возникает порочный круг. Чтобы загрузить драйвер в память, ему эту память надо выделить, а при выделении памяти - сделать соответствующие пометки в таблице страниц. А чтобы выделить место для таблицы страниц, нужно предварительно выполнить распределение памяти. Поэтому диспетчер виртуальных машин выполняет распределение в два приема: вначале выделяется небольшая гарантированно имеющаяся область памяти, в которую загружаются тела драйверов. В ней также строится таблица страниц. На втором этапе, собственно инициализации, анализируются требования драйверов к памяти и им выделяются виртуальные адреса в четвертом гигабайте. Если при загрузке Windows включить создание протокола загрузки, то в нем (файл bootlog.txt) эти стадии отчетливо видны. Сначала идут пары сообщений Loading и LoadSuccess для каждого драйвера, затем выполняется инициализация диспетчера виртуальных машин и драйверов. Современные драйверы дисплея, как правило, состоят из двух частей - ядра, выполненного в виде драйвера виртуального устройства (vxd) и основной части, выполненной в виде динамически загружаемых библиотек. Когда грузится ядро системы, загружается и ядро видеоадаптера. Оно обычно обеспечивает реализацию только базовых функций видеоадаптера, приблизительно на уровне адаптера VGA, поэтому вполне обходится соответствующей областью адресов в первом мегабайте или, в добавление к нему, небольшим участком памяти, занимаемым адаптером в верхних адресах четвертого гигабайта. При выполнении инициализации памяти диспетчер виртуальных машин выделяет ядру видеоадаптера запрошенную им область. Диспетчер памяти отводит незанятые участки под адресное пространство кэш жесткого диска (VCACHE). Затем запускается графическое ядро Windows, а с ним - и полный драйвер видеоадаптера. Этот драйвер инициализирует всю функциональность видеоадаптера, и в используемой адаптером зоне адресов начинает существовать физическое устройство.
Задание.
Определите, как распределяется оперативная память в вашей вычислительной системе.
Откройте <Пуск>/<Настройка>/<Панель управления>/<Система>.
Запишите все сведения о системе.
Определите, на какой вкладке можно определить состояние системы (запишите эти данные),
Рассмотрите свойства файловой системы (какие устройства здесь рассматриваются? Запишите эти данные).
Обратите особое внимание на вкладку <Виртуальная память>. Запишите, какие возможности Вы имеете для настройки системы виртуальной памяти .
Нажмите комбинацию кнопок <ctrl>/ <alt>/ <del>.
Запишите какие задачи решаются в системе. Определите объем страницы для вашей системы.
Видеопамять
В растровых дисплейных системах видеопамять организована в виде прямоугольного массива точек. Элемент видеопамяти, стоящий на пересечении конкретных строки и столбца видеопамяти, хранит значение яркости и/или цвета соответствующей точки. Отображаемая на экране часть видеопамяти называется экранным буфером (буфером регенерации или экранной битовой картой). Регенерация изображения осуществляется последовательным построчным сканированием экранного буфера.
Так как каждый элемент видеопамяти определяет один элемент отображения размером в точку на экране монитора, то каждая точка экран (и соответствующий ей элемент видеопамяти) обозначаются термином пиксел (pixel - picture element).
Задача системы вывода изображений (видеоконтроллера) состоит в циклическом построчном просмотре экранного буфера от 25 до 100 раз в секунду. Адреса видеопамяти генерируются синхронно с координатами растра и содержимое выбранных пикселов используется для управления цветом и интенсивностью луча. Общая организация системы вывода изображений приведена на рис.1.
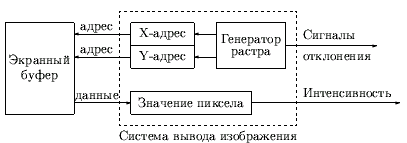
Рис.1. Экранный буфер и система вывода изображения
Генератор растровой развертки формирует сигналы отклонения и управляет адресными X и Y регистрами, определяющими следующий элемент буфера регенерации.
В идеальном случае время, требуемое для регенерации экранного буфера, должно быть много меньше, чем время, необходимое для манипуляций с данными, что позволит быстро обновлять или двигать изображение. Это означает, что усилители отклонения и усилитель, управляющий интенсивностью луча, должны быть очень широкополосными, чтобы обеспечить требуемую скорость передачи данных между экранным буфером и системой вывода изображения.
Частота регенерации для графических дисплейных систем среднего разрешения лежит в пределах 50 Мгц, а для систем высокого разрешения достигает 100-125 Мгц, с явной тенденцией к частотам более 125 Мгц в последнее время. При таких частотах таймирование регенерации экранного буфера становится важной задачей при проектировании подсистемы графического вывода. Так ка обычная DRAM память не обеспечивает времени доступа, подходящего для существующих мониторов высокого разрешения, то регенерация видеопамяти на таких частотах требует ее специальной организации. Пример организации видеопамяти, построенной на обычной динамической памяти с произвольным доступом (DRAM) приведен на рис. 2.

Рис. 2. Регенерация экранного буфера, построенного на обычной динамической памяти (DRAM)
В такой системе регенерация экранного буфера видеопамяти осуществляется с помощью параллельно-последовательного преобразования. Выполняя регенерацию, видеоконтроллер выставляет адрес слова, требуемое слово данных видеопамяти (обычно 16-32-64 бита) затем трансформируется в последовательный видеопоток (videostream) с помощью внешнего сдвигового регистра под контролем аппаратуры регенерации. На рис.2 показана реализация регенерации экранного буфера для системы с одним слоем. Системы регенерации со многими слоями требуют такого же количества (16-32-64) битовых слов, подлежащих регенерации и параллельно-последовательных сдвиговых регистров, что и число битовых слоев видеопамяти.
Если частота регенерации экранного буфера составляет порядка 100 Мгц, то такое параллельно-последовательное преобразование уменьшает требования к частоте тактирования параллельно считываемого слова из экранного буфера видеопамяти до 6.25 Мгц, что требует времени доступа порядка 160 нс. При такой организации видеопамяти манипуляции с данными и обновление экрана должны происходить во времена межстрочного и межкадрового интервалов, когда регенерации не происходит. Таким образом, узкое место для обычной DRAM памяти в качестве видеопамяти в графических дисплейных системах вытекает из двух противоречивых требований:
для растровых дисплейных систем должна осуществляться постоянная регенерация экранного буфера видеопамяти, что требует считывания выводимой на экран монитора графической информации с периодическим, жестко заданным циклом;
с другой стороны, требуется время для обновления больших массивов данных видеопамяти со стороны собственно аппаратуры генерации изображений, работающей, как правило, в цикле чтение-модификация-запись.
Доступные в настоящее время DRAM устройства даже с наиболее быстрыми режимами доступа не обеспечивают быстрого чтения их содержимого для поддержки требуемого ритма регенерации, оставляя крайне мало времени графическому процессору для модификации изображения. Таким образом, ограниченная полоса пропускания DRAM памяти ограничивает доступ аппаратуры формирования изображений к данным видеопамяти на время значительных периодов регенерации экранного буфера. Проблема усложняется по мере увеличения экранного буфера из-за возрастания числа отображаемых пикселов для мониторов высокого разрешения или при увеличении числа битов на пиксел в системах с большим количеством отображаемых цветов.
Для решения этой проблемы разработаны различные архитектуры видеопамяти, включая двухпортовую видеопамять, двойное буферирование и др.
Однако лучшее решение этой проблемы достигается за счет применения нового типа DRAM памяти, получившей название VRAM (Video Random Accses Memory), например. Texas Instrument 4161, разработанной специально для использования в качестве памяти изображения в растровых дисплейных система. Структурная схема подобной памяти приведена на рис.3.
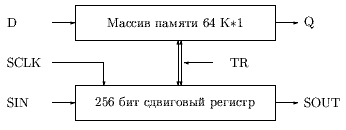
Рис. 3. Структурная схема VRAM памяти
Эта видеопамять содержит 2 порта, обеспечивая независимый доступ со стороны видеоконтроллера для регенерации и аппаратуры формирования изображений - графических процессоров. VRAM фактически представляет собой обычную DRAM память, которая была "внутренне" модифицирована посредством добавления сдвигового регистра. D и Q - это обычные входы и выходы порта с произвольной выборкой. Сигнал TR активируется на время передачи данных между сдвиговым регистром и видеопамятью. Сигналы SIN и SOUT - последовательные вход и выход сдвигового регистра, а сигнал SCLK - последовательный вход, управляющий сдвиговым регистром. Сдвиговый регистр загружается параллельным потоком в 256 бит из массива памяти за один цикл регенерации экрана. Длительность этого цикла не длиннее, чем стандартный цикл памяти. Обычно сдвиговый регистр загружается 1 раз во время обратного хода луча. Когда обратный ход заканчивается, на вход SCLK подается сигнал, вызывая сдвиг данных на последовательном выходе SOUT.
На рис.3 показан модуль видеопамяти объемом 64 Кбайт. Видеопамять объемом 256 Кбайт может быть построена из 4 модулей по 64 Кбайт (рис.4).
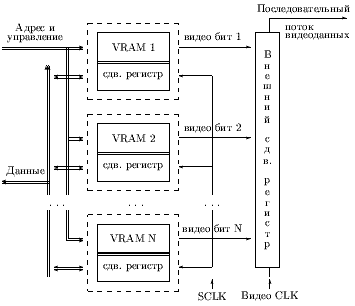
Рис. 4. Структурная схема многослойной VRAM памяти
В этом случае выходы SOUT от нескольких VRAM модулей подаются на параллельные входы внешнего сдвигового регистра, последовательный выход (CLK) которого тактируется со скоростью вывода точек (видеопотока битов), требуемой для регенерации экрана монитора.
В видеопамяти с такой организацией время на регенерацию экранного буфера (отображения на экран монитора) составляет менее 1.5% времени доступа. В системах же с обычной DRAM памятью время на регенерацию экрана составляет от 40% до 60% времени доступа.
Таким образом, применение VRAM обеспечивает практически полное время доступа для модификации данных видеопамяти, так как на одну строку сканирования растра требуется одна загрузка сдвигового регистра. Следовательно, в то время как предварительно загруженные видеоданные "выталкиваются" из сдвигового регистра в канал графического вывода, одновременно может осуществляться произвольный доступ к видеопамяти со стороны графических процессоров для модификации изображения.
ПРИНЦИПЫ ОРГАНИЗАЦИИ ВВОДА / ВЫВОДА ИНФОРМАЦИИ В МИКРОЭВМ
Вводом/выводом (ВВ) называют передачу данных между ядром ЭВМ, включающим в себя процессор и ОП, и периферийными устройствами (ПУ).
Система ВВ – это единственное средство общения ЭВМ с внешним миром. Ее возможности в серийных ЭВМ представляют собой один из важнейших параметров, определяющих выбор машины для конкретного применения.
Несмотря на разнообразие ПУ, в настоящее время разработано несколько стандартных способов их подключения к ЭВМ и программирования ВВ. Существует три режима ВВ:
Программный ВВ (нефорсированный).
ВВ по прерыванию (форсированный).
Прямой доступ к памяти (ПДП).
Реализация ВВ в каждом из этих режимов отличается программно-аппаратными затратами и, самое важное, скоростью выполнения операций обмена и непроизводительными затратами времени процессора. Суть каждого из трех режимов состоит в следующем.
Программный ВВ. Инициирование и управление ВВ осуществляет процессор по командам прикладной программы. ПУ играют пассивную роль и только сигнализируют о своем состоянии, в частности о готовности к операциям ВВ.
ВВ по прерыванию. Операции ВВ инициирует ПУ, генерируя сигнал запроса прерывания, при этом процессор переключается на подпрограмму обслуживания данного ПУ, вызвавшего прерывание. В результате выполнения подпрограммы (обработчика) осуществляется обмен данными. Действия, выполняемые обработчиком, определяются пользователем, а непосредственно операциями ВВ управляет процессор.
Таким образом, как при программном ВВ, так и при ВВ по прерываниям операциями обмена управляет процессор, поэтому очень часто эти два варианта обмена не разделяют и рассматривают их как программный ВВ. В англоязычной литературе – Programmed Input/Output (PIO). Однако в настоящем курсе эти варианты обмена рассматриваются отдельно.
Прямой доступ к памяти. Процессор в передаче данных не участвует. Он отключается от системной магистрали, а все операции обмена данными идут под управлением специального управляющего устройства – контроллера ПДП. Этот режим используется для быстродействующих ПУ, когда пропускной способности процессора недостаточно.
Следует отметить, что общие принципы организации систем прерывания уже рассмотрены в гл. 6. Организация систем ПДП подробно рассмотрена в гл. 11. Ниже рассматривается простейший случай организации радиальных систем прерывания и ПДП для микроЭВМ на базе МП КР580, поэтому материал настоящего раздела частично перекрывается с материалом, изложенным в гл. 6 и в гл. 11.