

Вопросы по дисциплине «Информационные системы и технологии»
Понятие информационной системы, информационной технологии. Соотношение понятий ИС и ИТ.
Информационная технология - процесс различных операций и действий над данными. Все процессы преобразования информации в информационной системе осуществляются с помощью информационных технологий.
Информационная система - среда, составляющими элементами которой являются компьютеры, компьютерные сети, программные продукты, базы данных, люди, различного рода технологические и программные средства и т.д.
Таким образом, информационная технология является более емким понятием, чем информационная система. Реализация функций информационной системы невозможна без знаний ориентированной на нее информационной технологии. Информационная технология может существовать и вне сферы информационной системы.
Классификация ИС по функциональному признаку, по сфере функционирования объекта, по видам процессов управления, по связи с производством, по уровню в системе государственного управления.
По функциональному признаку:
Производственная
Маркетинговая
Финансовая
Кадровая
По сфере функционирования объекта:
ИС промышленности;
ИС сельского хозяйства;
ИС транспорта;
ИС связи и т.д.
По видам процессов управления:
ИС управления технологическими процессами
ИС управления организацинно-технологическими процессами
ИС организационного управленияИнтегрированные ИС
Корпоративные ИС
ИС научных исследований
Обучающие ИС
По связи с производством:
По уровню в системе государственного управления:
Федеральные ИС
территориальные (региональные) ИС
муниципальные ИС
Основополагающие принципы создания ИС.
Принцип системности позволяет подойти к объекту как к единому целому; выявить многообразные типы связей между элементами; установит направление производственно-хозяйственной деятельности системы и реализуемые ею функции. Подход предполагает проведение микро- и макроанализа.
Принцип развития – ИС создается с учетом возможности постоянного пополнения и обновления системы и видов ее обеспечений.
Принцип комплексности, обеспечение ИС связностью проектирования отдельных элементов и всего объекта в целом на всех стадиях.
Принцип совместимости обеспечивает взаимодействия ИС различных видов, уровней в процессе их совместного функционирования.
Принцип стандартизации и унификации предполагает применение типовых, унифицированных и стандартизированных элементов функционирования ИС.
Принцип эффективности заключается в достижении рационального соотношения между затратами на создание ИС и целевым эффектом.
Принцип первого руководителя предполагает закрепление ответственности при создании системы за лицом отвечающим за ввод в действие и функционирование ИС.
Принцип новых задач - поиск постоянных расширений возможностей системы.
Принцип автоматизации информационных потоков и документооборота - комплексное использование технических средств на всех стадиях прохождения информации.
Принцип автоматизации проектирования имеет целью повысить эффективность самого процесса проектирования и создания ИС на всех уровнях деятельности.
Охарактеризуйте CASE-технологии.
Computer - aided software/system engineering
Case средства поддерживают процессы создания и сопровождения ИС включая анализ и формулировку требований, проектирование прикладного ПО и БД, генерацию кода, тестирования документирования, обеспечение качества, конфигурационное управление и управление проектом.
Основные этапы и модели ЖЦ ПО.
Жизненный цикл программного обеспечения (ПО) — период времени, который начинается с момента принятия решения о необходимости создания программного продукта и заканчивается в момент его полного изъятия из эксплуатации[1]. Этот цикл — процесс построения и развития ПО.
основные этапы жизненного цикла программного обеспечения:
анализ требований,
проектирование,
кодирование (программирование),
тестирование и отладка,
эксплуатация и сопровождение.
Модели:
Водопадная (каскадная, последовательная) модель
Водопадная модель жизненного цикла (англ. waterfall model) была предложена в 1970 г. Уинстоном Ройсом. Она предусматривает последовательное выполнение всех этапов проекта в строго фиксированном порядке. Переход на следующий этап означает полное завершение работ на предыдущем этапе. Требования, определенные на стадии формирования требований, строго документируются в виде технического задания и фиксируются на все время разработки проекта. Каждая стадия завершается выпуском полного комплекта документации, достаточной для того, чтобы разработка могла быть продолжена другой командой разработчиков.
Этапы проекта в соответствии с каскадной моделью:
Формирование требований;
Проектирование;
Реализация;
Тестирование;
Внедрение;
Эксплуатация и сопровождение.
Итерационная модель
Альтернативой последовательной модели является так называемая модель итеративной и инкрементальной разработки (англ. iterative and incremental development, IID), получившей также от Т. Гилба в 70-е гг. название эволюционной модели. Также эту модель называют итеративной моделью и инкрементальной моделью[4].
Модель IID предполагает разбиение жизненного цикла проекта на последовательность итераций, каждая из которых напоминает «мини-проект», включая все процессы разработки в применении к созданию меньших фрагментов функциональности, по сравнению с проектом в целом. Цель каждой итерации — получение работающей версии программной системы, включающей функциональность, определённую интегрированным содержанием всех предыдущих и текущей итерации. Результат финальной итерации содержит всю требуемую функциональность продукта. Таким образом, с завершением каждой итерации продукт получает приращение — инкремент — к его возможностям, которые, следовательно, развиваются эволюционно. Итеративность, инкрементальность и эволюционность в данном случае есть выражение одного и того же смысла разными словами со слегка разных точек зрения[3].
По выражению Т. Гилба, «эволюция — прием, предназначенный для создания видимости стабильности. Шансы успешного создания сложной системы будут максимальными, если она реализуется в серии небольших шагов и если каждый шаг заключает в себе четко определённый успех, а также возможность «отката» к предыдущему успешному этапу в случае неудачи. Перед тем, как пустить в дело все ресурсы, предназначенные для создания системы, разработчик имеет возможность получать из реального мира сигналы обратной связи и исправлять возможные ошибки в проекте»[4].
Подход IID имеет и свои отрицательные стороны, которые, по сути, — обратная сторона достоинств. Во-первых, целостное понимание возможностей и ограничений проекта очень долгое время отсутствует. Во-вторых, при итерациях приходится отбрасывать часть сделанной ранее работы. В-третьих, добросовестность специалистов при выполнении работ всё же снижается, что психологически объяснимо, ведь над ними постоянно довлеет ощущение, что «всё равно всё можно будет переделать и улучшить позже»[3].
Спиральная модель.
Спиральная модель (англ. spiral model) была разработана в середине 1980-х годов Барри Боэмом. Она основана на классическом цикле Деминга PDCA (plan-do-check-act). При использовании этой модели ПО создается в несколько итераций (витков спирали) методом прототипирования.
Каждая итерация соответствует созданию фрагмента или версии ПО, на ней уточняются цели и характеристики проекта, оценивается качество полученных результатов и планируются работы следующей итерации.
На каждой итерации оцениваются:
риск превышения сроков и стоимости проекта;
необходимость выполнения ещё одной итерации;
степень полноты и точности понимания требований к системе;
целесообразность прекращения проекта.
Важно понимать, что спиральная модель является не альтернативой эволюционной модели (модели IID), а специально проработанным вариантом. К сожалению, нередко спиральную модель либо ошибочно используют как синоним эволюционной модели вообще, либо (не менее ошибочно) упоминают как совершенно самостоятельную модель наряду с IID[3].
Отличительной особенностью спиральной модели является специальное внимание, уделяемое рискам, влияющим на организацию жизненного цикла, и контрольным точкам. Боэм формулирует 10 наиболее распространённых (по приоритетам) рисков:
Дефицит специалистов.
Нереалистичные сроки и бюджет.
Реализация несоответствующей функциональности.
Разработка неправильного пользовательского интерфейса.
Перфекционизм, ненужная оптимизация и оттачивание деталей.
Непрекращающийся поток изменений.
Нехватка информации о внешних компонентах, определяющих окружение системы или вовлеченных в интеграцию.
Недостатки в работах, выполняемых внешними (по отношению к проекту) ресурсами.
Недостаточная производительность получаемой системы.
Разрыв в квалификации специалистов разных областей.
В сегодняшней спиральной модели определён следующий общий набор контрольных точек[5]:
Concept of Operations (COO) — концепция (использования) системы;
Life Cycle Objectives (LCO) — цели и содержание жизненного цикла;
Life Cycle Architecture (LCA) — архитектура жизненного цикла; здесь же возможно говорить о готовности концептуальной архитектуры целевой программной системы;
Initial Operational Capability (IOC) — первая версия создаваемого продукта, пригодная для опытной эксплуатации;
Final Operational Capability (FOC) –— готовый продукт, развернутый (установленный и настроенный) для реальной эксплуатации.
Охарактеризуйте RAD-технологии. Основные принципы методологии RAD.
RAD технологии быстрого создания приложений
В основе лежит использование спиральной модели ЖЦ ПО
RAD технологии- процесс разработки ПО содержащей 3 элемента.
небольшую команду программистов 2-10 человек
короткий но тщательно проработанный график. 2-6 месяцев
повторяющийся цикл при котором разработчики по мере того как приложения начинает обретать форму запрашивают и реализуют в продукте требования полученный через взаимодействие с заказчиком
ЖЦ ПО по методологии RAD состоит из фаз
1. Анализа и планирования требований.
2. Проектирование
3. Построение
4. Внедрение
Принципы методологии RAD
1. Разработка приложения итерациями
2. Необязательность полного завершения работ на каждом этапе ЖЦ
3. Обязательно вовлечение пользователей в процесс разработки
4. Необходимое определение case средств обеспечивающих целостность проекта.
5. Использование генераторов кода.
6. Применение средств управления конфигурации облегчающих внесение изменений в проект и сопровождение готовой программы.
И т.д.
Структурный метод разработки ПО. Основные виды моделей (диаграмм), используемых в структурном анализе.
Структурный метод разработки ПО.
Сущность структурного подхода к разработке АИС заключается в её декомпазиции на автоматизируемые функции: система разбивается на функциональные подсистемы которые в свою очередь делятся на подфункции, подразделяемые на задачи и т.д.
Процесс разбивки продолжается до конкретных процедур
Модели(диаграммы)
Модели и соответствующие функциональные диаграммы
SADT (structured analysis and design technique) -
DFD (data flow diagrams) - диаграммы потоков данных
ERD (Entity relationship diagrams) - диаграмма сущность связь
STD (state transition diagrams)- диаграмма переходов состоянии
Методология SADT (IDEF0).
Методология SADT представляет собой совокупность методов, правил и процедур, предназначенных для построения функциональной модели объекта какой-либо предметной области. Функциональная модель SADT отображает функциональную структуру объекта, т.е. производимые им действия и связи между этими действиями.
Основные элементы этой методологии основываются на следующих концепциях:
графическое представление блочного моделирования.
строгость и точность.
Выполнение правил SADT требует достаточной строгости и точности, не накладывая в то же время чрезмерных ограничений на действия аналитика. Правила SADT включают:
ограничение количества блоков на каждом уровне декомпозиции (правило 3-6 блоков);
связность диаграмм (номера блоков);
уникальность меток и наименований (отсутствие повторяющихся имен);
синтаксические правила для графики (блоков и дуг);
разделение входов и управлений (правило определения роли данных).
отделение организации от функции, т.е. исключение влияния организационной структуры на функциональную модель.
Методологию IDEF0 можно считать следующим этапом развития хорошо известного графического языка описания функциональных систем SADT (Structured Analysis and Design Technique).
Целью методики является построение функциональной схемы исследуемой системы, описывающей все необходимые процессы с точностью, достаточной для однозначного моделирования деятельности системы.
В основе методологии лежат четыре основных понятия: функциональный блок, интерфейсная дуга, декомпозиция, глоссарий.
Функциональный блок (Activity Box) представляет собой некоторую конкретную функцию в рамках рассматриваемой системы. По требованиям стандарта название каждого функционального блока должно быть сформулировано в глагольном наклонении (например, "производить услуги"). На диаграмме функциональный блок изображается прямоугольником (рис.1). Каждая из четырех сторон функционального блока имеет свое определенное значение (роль), при этом:
• верхняя сторона имеет значение "Управление" (Control);
• левая сторона имеет значение "Вход" (Input);
• правая сторона имеет значение "Выход" (Output);
• нижняя сторона имеет значение "Механизм" (Mechanism).
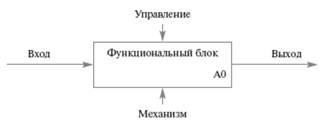
Рис.1
Интерфейсная дуга (Arrow) отображает элемент системы, который обрабатывается функциональным блоком или оказывает иное влияние на функцию, представленную данным функциональным блоком. Интерфейсные дуги часто называют потоками или стрелками.
С помощью интерфейсных дуг отображают различные объекты, в той или иной степени определяющие процессы, происходящие в системе. Такими объектами могут быть элементы реального мира (детали, вагоны, сотрудники и т.д.) или потоки данных и информации (документы, данные, инструкции и т.д.).
Декомпозиция (Decomposition) является основным понятием стандарта IDEF0. Принцип декомпозиции применяется при разбиении сложного процесса на составляющие его функции. При этом уровень детализации процесса определяется непосредственно разработчиком модели.
Декомпозиция позволяет постепенно и структурировано представлять модель системы в виде иерархической структуры отдельных диаграмм, что делает ее менее перегруженной и легко усваиваемой.
Последним из понятий IDEF0 является глоссарий (Glossary). Для каждого из элементов IDEF0 — диаграмм, функциональных блоков, интерфейсных дуг — существующий стандарт подразумевает создание и поддержание набора соответствующих определений, ключевых слов, повествовательных изложений и т.д., которые характеризуют объект, отображенный данным элементом. Этот набор называется глоссарием и является описанием сущности данного элемента. Глоссарий гармонично дополняет наглядный графический язык, снабжая диаграммы необходимой дополнительной информацией.
Диаграммы потоков данных (DFD). Нотации, используемые для изображения DFD. Основные компоненты DFD.
Диаграммы потоков данных (DFD)
Такая диаграмма состоит из трех типов узлов: узлов обработки данных, узлов хранения данных и внешних узлов, представляющих внешние по отношению к используемой диаграмме
источники или потребители данных. Дуги в диаграмме соответствуют потокам данных, передаваемых от узла к узлу. Они помечены именами соответствующих данных. Описание процесса,
функции или системы обработки данных, соответствующих узлу диаграммы, может быть представлено диаграммой следующего уровня детализации, если процесс достаточно сложен [1, 53].
Для изображения диаграмм потоков данных традиционно используют два вида нотаций: нотации Йордана и Гейна — Сарсона (табл. 3.4).
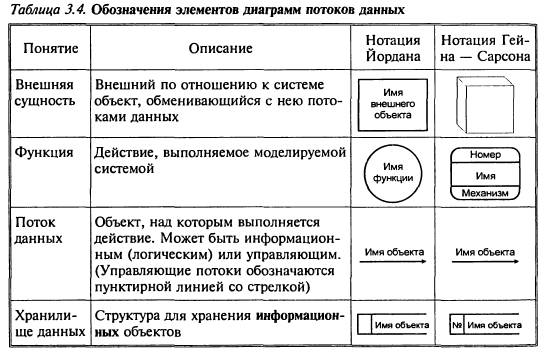
Основными компонентами диаграмм потоков данных являются:
• внешние сущности;
• системы и подсистемы;
• процессы;
• накопители данных;
• потоки данных.
Методология IDEF1.
Предназначение стандарта IDEF1
Стандарт IDEF1 был разработан как инструмент для анализа и изучения взаимосвязей между информационными потоками в рамках коммерческой деятельности предприятия. Целью подобного исследования является дополнение и структуризация существующей информации и обеспечение качественного менеджмента информационными потоками. Необходимость в подобной реорганизации информационной области как правило возникает на начальном этапе построения корпоративной информационной системы, и методология IDEF1 позволяет достаточно наглядно обнаружить "черные дыры" и слабые места в существующей структуре информационных потоков. Применение методологии IDEF1, как инструмента построения наглядной модели информационной структуры предприятия по принципу "Как должно быть" позволяет решить следующие задачи:
Выяснить структуру и содержание существующих потоков информации на предприятии
Определить какие проблемы, выявленные в результате функционального анализа и анализа потребностей, вызваны недостатком управления соответствующей информацией.
Выявить, информационные потоки, требующие дополнительного управления для эффективной реализации модели.
С помощью IDEF1 происходит изучение существующей информации о различных объектах в области деятельности предприятия. Характерно то, что IDEF1-модель включает в рассмотрение не только автоматизированные компоненты, базы данных и соответствующую им информацию, но также и реальные объекты, такие как сами сотрудники, кабинеты, телефоны и т.д. Миссия методологии IDEF1 состоит в том, чтобы выявить и четко постулировать потребности в информационном менеджменте в рамках коммерческой деятельности предприятия.
Однако основной целью использования методологии IDEF1 все же остается исследование движения потоков информации и принципов управления ими на начальном этапе процесса проектирования корпоративной информационно-аналитической системы, которая будет способствовать более эффективному использованию информационного пространства. Наглядные модели IDEF1 обеспечивают базис для построения мощной и гибкой информационной системы.
Основные преимущества IDEF1
Методология IDEF1 позволяет на основе простых графических изображений моделировать информационные взаимосвязи и различия между:
Реальными объектами
Физическими и абстрактными зависимостями, существующими среди реальных объектов
Информацией, относящейся к реальным объектам
Структурой данных, используемой для приобретения, накопления, применения и управления информацией.
Одним из основных преимуществ методологии IDEF1 является обеспечение последовательного и строго структурированного процесса анализа информационных потоков в рамках деятельности предприятия. Другим отличительным свойством IDEF1 является широко развитая модульность, позволяющая эффективно выявлять и корректировать неполноту и неточности существующей структуры информации, на всем протяжении этапа моделирования.
Концепции моделирования IDEF1
Методология IDEF1 разработана как инструмент для исследования статического соответствия вышеуказанных областей и установления строгих правил и механизмов изменения объектов информационной области при изменении соответствующих им объектов реального мира.
Терминология и семантика IDEF1
Методология IDEF1 разделяет элементы структуры информационной области, их свойства и взаимосвязи на классы. Центральным понятием методологии IDEF1 является понятие сущности. Класс сущностей представляет собой совокупность информации, накопленной и хранящейся в рамках предприятия и соответствующей определенному объекту или группе объектов реального мира. Основными концептуальными свойствами сущностей в IDEF1 являются:
Устойчивость. Информация, имеющая отношение к той или иной сущности постоянно накапливается.
Уникальность. Любая сущность может быть однозначно идентифицирована из другой сущности.
Каждая сущность имеет своё имя и атрибуты. Атрибуты представляют собой характерные свойства и признаки объектов реального мира, относящихся к определенной сущности. Класс атрибутов представляет собой набор пар, состоящих из имени атрибута и его значения для определенной сущности. Атрибуты, по которым можно однозначно отличить одну сущность от другой называются ключевыми атрибутами. Каждая сущность может характеризоваться несколькими ключевыми атрибутами. Класс взаимосвязей в IDEF1 представляет собой совокупность взаимосвязей между сущностями. Взаимосвязь между двумя отдельными сущностями считается существующей в том случае, класс атрибутов одной сущности содержит ключевые атрибуты другой сущности. Каждый из вышеописанных классов имеет свое условное графическое отображение, согласно методологии IDEF1.
На рис. приведен пример IDEF1 – диаграммы. На ней представлены две сущности с именами “Отдел” и “Сотрудник” и взаимозвязь между ними с именем “работает в”. Имя взаимосвязи всегда выражается в глагольной форме. Если же между двумя или несколькими объектами реального мира не существует установленной зависимости, то с точки зрения IDEF1, между соответсвующими им сущностями взаимосвязь также отсутствует.

Моделирования данных. ER-модель. Элементы ER-модели.
Моделирование данных
Цель моделирования данных - состоит в обеспечении разработчика АИС концептуальной схемой БД форме одной модели или нескольких локальных моделей которые могут быть отображены в систему БД. Наиболее распространенным средством моделирования данных являются диаграммы сущность-связь
Модель «сущность-связь» (англ. “Entity-Relationship model”), или ER-модель, предложенная П. Ченом[1] в 1976 г., является наиболее известным представителем класса семантических (концептуальных, инфологических) моделей предметной области. ER-модель обычно представляется в графической форме, с использованием оригинальной нотации П. Чена, называемой ER-диаграмма, либо с использованием других графических нотаций (Crow's Foot, Information Engineering и др.).
Основные преимущества ER-моделей:
наглядность;
модели позволяют проектировать базы данных с большим количеством объектов и атрибутов;
ER-модели реализованы во многих системах автоматизированного проектирования баз данных (например, ERWin).
Основные элементы ER-моделей:
объекты (сущности);
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна.
атрибуты объектов;
Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности
связи между объектами.
Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями.
Ключи, связи, суперклассы и подклассы в ER-модели.
Ключ – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся.
Выделяют уникальные ключи (потенциальные ключи) и неуникальные. Значение уникального ключа не может встретиться у двух экземпляров сущности. Оно указывает на один и только один экземпляр (НомерСтудбилета, НомерАудитории). Значение неуникального ключа указывает на множество экземпляров (ФамилияПреподавателя = Иванов указывает на всех Ивановых, преподающих в ВУЗе).
Ключом может быть не любой атрибут сущности. Например, ДатаНайма или Должность преподавателя вряд ли могут использоваться для идентификации преподавателей.
Связь – это характеристика отношений между двумя или более сущностями.
Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой.
Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.
Множество сущностей, включающих разные подклассы, которые необходимо представить в модели данных, называется Суперклассом.
Подкласс – это множество сущностей, играющих самостоятельную роль и принадлежащих некоторому суперклассу.
В некоторых случаях множество сущностей может иметь несколько разных подклассов. Например, для типа сущности Сотрудник отдельные экземпляры этой сущности можно классифицировать как: Управляющий, Секретарь и Торговый_агент. Иначе говоря, сущность Сотрудник можно рассматривать как суперкласс для подклассов Управляющий, Секретарь и Торговый_агент. Связь между суперклассом и любым его подклассом называется связью "суперкласс/подкласс". Например, связь Сотрудник/Управляющий является связью типа "суперкласс/подкласс".
Связь между суперклассом и подклассом относится к типу "один к одному" (1:1).
Существуют две причины введения суперклассов и подклассов:
Не допустить повторное описание близких по смыслу понятий.
Включается больше семантической информации, привычной для понимания.
Кратность связей в ER-модели.
Кратностью (multiplicity) называется характеристика, указывающая, сколько атрибутов класса сущности с данной ролью может или должно участвовать в каждом экземпляре связи какого-либо вида.
Наиболее распространенным способом задания кратности роли связи является прямое указание конкретного числа или диапазона. Например, указание «1» говорит о том, что каждый класс с данной ролью должен участвовать в некотором экземпляре данной связи, причем в каждом экземпляре связи может участвовать ровно один объект класса с данной ролью. Указание диапазона «0..1» говорит о том, что не все объекты класса с данной ролью обязаны участвовать в каком-либо экземпляре данной связи, но в каждом экземпляре связи может участвовать только один объект. Поговорим о кратностях подробнее.
Типичными, самыми распространенными кратностями в системах проектирования баз данных являются следующие кратности:
1) 1 – кратность связи на соответствующем ее конце равна единице;
2) 0… 1 – такая форма записи означает, что кратность данной связи на соответствующем своем конце не может превышать единицы;
3) 0… ? – такая кратность расшифровывается просто «много». Любопытно, что, как правило, «много» означает «ничего»;
4) 1… ? – такое обозначение получила кратность «один или более».
Реляционная модель данных. Отношение, атрибут, домен, реляционные ключи.
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка.
На реляционной модели данных строятся реляционные базы данных.
Реляционная модель данных включает следующие компоненты:
Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление).
Отношение – это плоская таблица, состоящая из столбцов и строк.
Атрибут – именованный столбец отношения.
Домен – набор допустимых значений одного или нескольких атрибутов.
Реляционные ключи. Потенциальным ключом K в отношении R называется атрибут или совокупность атрибутов, которые единственным образом идентифицирует кортеж отношения. Ключ K обладает следующими свойствами: а) уникальность; б) неприводимость(из ключа К нельзя вычеркнуть ни один атрибут без потери свойств уникальности). В каждом отношении должен быть хотя бы 1 потенциальный ключ. Потенциальный ключ состоящий из 1 атрибута называется простым, из нескольких - составным. Первичным ключом отношения R называют один из ключей потенциальных выбранных для уникальной идентификации кортежей внутри отношения. Если в отношении имеется несколько потенциальных ключей при выборе первичного ключа предпочтение следует отдавать простым числовым ключам. Альтернативным ключом отношения R называют потенциальный ключ не выбранный в качестве первичного. Если все потенциальные ключи отношения состоят из длинных текстовых атрибутов, то в отношение искусственно добавляется атрибут типа который содержит номера строк. Этот атрибут будет суррогатным первичным ключом. Он используется только в целях упрощения связей между таблицами. Внешним ключом отношения R называется атрибут или совокупность атрибутов соответствующая первичному ключу основного отношени
Нормализация отношений. Понятие и цель нормализации. Функциональные зависимости. Аксиомы Армстронга.
Нормализация отношений – это формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных.
Е.Коддом выделены три нормальные формы отношений и предложен механизм, позволяющий любое отношение преобразовать к третьей (самой совершенной) нормальной форме.
Нормализация - это разбиение таблицы на две или более, обладающих лучшими свойствами при включении, изменении и удалении данных.
цель нормализации базы данных - устранение избыточности и дублирования информации. В идеале при нормализации надо добиться, чтобы любое значение хранилось в базе в одном экземпляре, причем значение это не должно быть получено расчетным путем из других данных, хранящихся в базе.
Функциона́льная зави́симость — концепция, лежащая в основе многих вопросов, связанных с реляционными базами данных, включая, в частности, их проектирование. Математически представляет бинарное отношение между множествами атрибутов данного отношения и является, по сути, связью типа «один ко многим». Их использование обусловлено тем, что они позволяют формально и строго решить многие проблемы.