

12.2 Динамические массивы.
Наряду с обычными, статическими массивами, можно использовать динамические массивы, в которых не определено число элементов на этапе компиляции. Синтаксис объявления динамического массива, в целом, схож и синтаксисом объявления статического массива, кроме указания диапазона индексов.
array of <тип элемента>
Пример объявления динамического массива
var a: array of integer;
Фактически динамические массивы, как и длинные строки, являются указателями, но в отличие от длинных строк память для динамических массивов необходимо выделять самостоятельно использую процедуру SetLength.
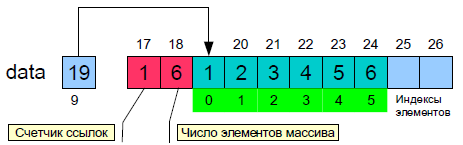
Перед использованием динамического массива следует установить его длину с помощью процедуры SetLength имеющую следующий синтаксис
procedure SetLength(var S; NewLength: Integer)
гдеS – динамический массив;
NewLength – новая длина массива (число элементов).
После использования массив можно удалить из памяти с помощью функции Finalize(S) или SetLength(S, 0). Следует помнить, что динамические массивы всегда начинаются с нулевого индекса. Верхнюю границу динамического массива можно определить с помощью функции High(S).
Возможно также создание динамических многомерных массивов, например.
var a:array of array of Double; //двумерный массив
выделить память под многомерный массив можно различными способами например с помощью процедуры SetLength
SetLength(a, 3, 4); //массив 3x4 элемента
После выполнения этой подпрограммы в памяти будет создана следующая структура
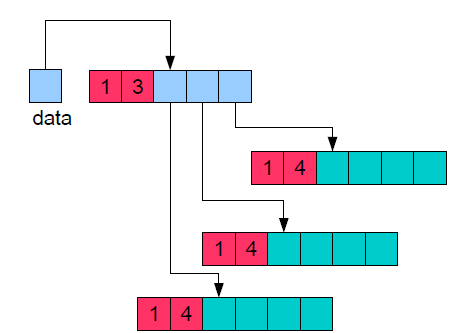
Видно, что фактически создается массив из указателей, каждый из которых, указывает на одномерный массив. Это дает возможность создавать матрицы (таблицы) со строками переменной длины.
Следует отметить, что при изменении размеров массива значения элементов массива не теряются, т. е. если уменьшить размер массива со 100 элементов до 50, то первые 50 элементов останутся неизменными. Но следует помнить, что при увеличении массива элементы будут добавляться в конец массива и их содержимое не предсказуемо.
Динамические массивы, в отличие от длинных строк, не используют технологию подсчета ссылок, поэтому, для того чтобы выполнить операцию присвоения (получить копию) необходимо использовать стандартную функцию Copy имеющую следующий синтаксис.
function Copy(S; Index, Count: Integer): array;
гдеS – копируемый массив;
Index – индекс начиная с которого необходимо осуществить копирование;
Count – число копируемых элементов.
Для динамических массивов существует укороченная версия этой функции, без указания индекса и числа копируемых элементов
function Copy(S): array;
11. Динамические структуры данных. Связные списки. Вставка и удаление узлов.
Динамическими структурами данных называют структуры данных размер и количество элементов которых может изменяться во время работы программы. Существует большое количество динамических структур данных. Примером таких структур могут служить связные списки и деревья. Рассмотрим одну из наиболее распространенных структур данных – связные списки.
11.1 Односвязные списки. Структура. Особенности обработки.
Односвязный список представляет собой цепочку элементов, называемых узлами. При этом каждый элемент (узел) содержит указатель, указывающий на следующий элемент (узел) в этом списке
Для получения доступа ко всем элементам списка достаточно знать первый узел списка, от которого, путем переходов по ссылкам можно обойти все остальные узлы.
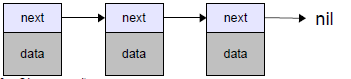
В отличие от массива, узлы списка могут располагаться в различных (не смежных) участках памяти, а их порядок определяется ссылками. Недостатком списка является большое количество обращений к памяти при выборе элемента списка, как следствие меньшее быстродействие при чтении списка, а также больший занимаемый объём, за счет хранения ссылок. Достоинством списка является простота и высокая скорость вставки или удаления элемента из списка.
Создание односвязного списка
Для описания односвязного списка достаточно задать его первый узел, называемый головой списка.
var HeadNode:PslNode;
Если HeadNode содержит nil значит списка еще нет. Таким образом, односвязный список создается следующим образом
var HeadNode:PslNode = nil;
Вставка и удаление элементов в односвязном списке
Для односвязного списка существует только один вариант вставки нового узла в список – вставка после указанного узла списка.
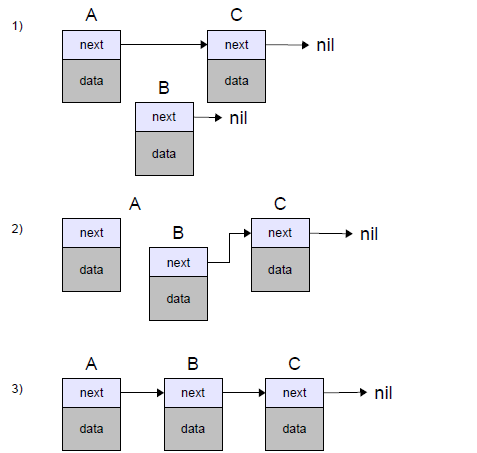
Пошаговый алгоритм удаления узла из односвязного списка

Прохождение односвязного списка реализуется с помощью очень простого алгоритма:
•вводится текущий узел;
•текущему узлу присваивается первый узел списка;
•далее производится переход от узла к узлу с помощью указателей next. При этом для каждого узла может вызываться некоторая подпрограмма обрабатывающая данные содержащиеся в узле;
•процесс останавливается при достижении указателя nil.