

МІНІСТЕРСТВО ОСВІТИ І НАУКИ УКРАЇНИ
Національний аерокосмічний університет ім. М.Є. Жуковського
“Харківський авіаційний інститут”
Кафедра комп’ютерних систем та мереж
Титульный лист заполняется на украинском языке
Остальная часть отчета может быть как на украинском, так и на русском
Розрахунково-графічна робота № 2
з дисципліни “Теорія інформації та кодування”
Метод арифметичного кодування
ХАІ.503.535.14В.050102, 1105079 ПЗ
Виконав студент гр. 535Б Сабельніков І.В.Фамилия И.О.
15.04.2014
(підпис, дата)
Перевірив канд.т.н., доцент
(науковий ступінь, вчене звання, посада)
Брежнєв Є.В.
(підпис, дата) (П.І.Б.)
Харків 2014
Постановка задачи Тема работы: Сжатие текстовой информации методом арифметического кодирования. Задание:
Закодировать арифметическим кодом произвольное сообщение на русском языке (с учетом пробелов). Число символов сообщения приведено ниже для каждого варианта.
Случайным образом задать вероятностное распределение всех символов сообщения.
Вариант |
Среднее число символов текста |
14. |
125 |
Для выполнения обоих задания должен быть разработан проект.
Проект должен обеспечивать вывод результатов:
- сообщение для кодирования, число символов в нем, вероятности появления символов;
- пошаговую реализацию алгоритма кодирования;
- арифметический код в двоичном и числовом виде.
Письменный отчет должен содержать:
Титульный лист. (Название РГР. Фамилия, имя, отчество, номер группы исполнителя, дата сдачи.)
Все требуемые математические соотношения для вычислений.
Распечатку текстов подпрограмм.
Выводы содержат сравнительный анализ методов Хаффмана и арифметического кодирования.
Реализация метода
Так как описание метода не требуется, приступим сразу к его реализации.
В первую очередь, всплывает проблема хранения интервалов. На каждом шаге алгоритма появляются все новые и новые цифры после запятой, и очень скоро тип Double (64 бита) уже не справляется с кодированием.
Нужно
обеспечить огромную точность. Для этого
будем представлять числа в виде дробей,
причем в знаменателе будет находится
число, которое является степенью двойки.
Например, интервал
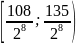 .
Это обеспечит легкое преобразование в
двоичный вид, а также избавит нас от
необходимости использовать тип с
плавающей запятой.
.
Это обеспечит легкое преобразование в
двоичный вид, а также избавит нас от
необходимости использовать тип с
плавающей запятой.
При возрастании длины текста будет возрастать числитель. Возникает необходимость хранить большие числа целого типа. С этой задачей справится класс BigInteger, который присутствует в языках C# и Java. Этим и обусловлен выбор данных объектно-ориентированных языков.
Теперь
нужно определить, как мы будем находить,
какой именно знаменатель нам нужно
подставлять, чтобы обеспечить дальнейшее
однозначное декодирование. Худшим
вариантом для алгоритма является текст,
который состоит из символов, имеющих
наименьшую вероятность. Для этого
выберем этот "наихудший" символ и
возведем его вероятность в степень
длины текста. Например, длина текста k
= 20, а вероятность появления символа
p('ф')
= 0.002. Тогда искомая величина равна
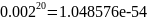 . Потом переворачиваем данную дробь,
получаем 9.5367431640625e+53. И последним шагом
округляем полученное число в большую
сторону к степени двойки. Для нашего
примера это будет
. Потом переворачиваем данную дробь,
получаем 9.5367431640625e+53. И последним шагом
округляем полученное число в большую
сторону к степени двойки. Для нашего
примера это будет
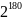 .
Теперь наш стартовый диапазон представлен
в виде
.
Теперь наш стартовый диапазон представлен
в виде
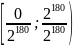 .
При этом знаменатели не изменяются во
время выполнения алгоритма, этому
подвержены только числители.
.
При этом знаменатели не изменяются во
время выполнения алгоритма, этому
подвержены только числители.
И
последнее замечание. Чтобы работать с
вероятностями вида 0.002, лучше их умножить
на 1000, перевести в BigInteger,
произвести требуемые умножения и
деления, а потом не забыть разделить на
1000. При этом появляется новое ограничение:
вероятности можно задавать с точностью
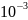 (или
любой другой, но все равно фиксированной).
(или
любой другой, но все равно фиксированной).