

4. Линейные структуры данных
Массивы
Массив – это линейная структура данных фиксированного размера с произвольным доступом по номеру элемента (по индексу). Обычно массивы хранятся в виде последовательного списка.
Каждый элемент массива идентифицируется одним или несколькими индексами. Индекс – это целое число, значение которого определяет позицию соответствующего элемента в массиве и используется для доступа к этому элементу. Отдельные элементы массива могут изменяться, т.е. для массива возможен режим корректировки. Общее число элементов массива всегда остается неизменным, следовательно, для массива не возможны операции добавления и удаления.
В однородных массивах все элементы являются данными одного и того же типа и имеют одинаковый формат. Массивы, элементами которых являются данные различных типов, называются неоднородными.
В зависимости от числа индексов, идентифицирующих каждый элемент, различают одномерные и многомерные массивы.
Одномерный массив называется вектором.
Вектор А = А(1), А(2), ….,А(I),….,А(N) – это последовательность элементов (записей), размещенных в смежных ячейках памяти.
Под вектор транслятор выделяет область памяти в соответствии с объявлением массива в программе. Адрес первого байта, выделенного транслятором для первого элемента вектора, называется адресом базы вектора. Адрес любого i – го элемента вычисляется транслятором по следующей формуле:
Loc (Ai) = L0 + C (i-1)
Здесь loc – от англ. location – определение местоположения, L0 - адрес базы вектора, С – число байтов, выделенных для хранения одного элемента вектора.
При обращении к элементу вектора в программе задается значение его индекса i. Транслятор по формуле определяет адрес хранения А(i) и читает этот элемент из памяти.
Представление вектора в памяти не зависит от того, как он описывается в языке программирования. При любом описании это представление будет одинаковым.
Двумерный массив называется матрицей. Каждый элемент матрицы определяется двумя индексами.
При хранении в памяти матрица представляется в виде эквивалентного вектора. При этом матрица может храниться в памяти как «строка строк» или как «строка столбцов». В первом случае матрица 3*3
А (1,1) А (1,2) А (1,3)
А (2,1) А (2,2) А (2,3)
А (3,1) А (3,2) А (3,3)
при размещении в памяти будет представлена в виде следующего вектора:
А (1,1) А (1,2) А (1,3) А (2,1) А (2,2) А (2,3) А (3,1) А (3,2) А (3,3)
Хранение элементов матрицы в таком виде называется хранением по строкам. Адрес матричного элемента А (i, j) в этом случае определяется выражением
Loc (А i,j ) = L0 + c m (i - 1) + c (j - 1),
где m – число столбцов.
Такое размещение принято в языках программирования ПЛ/1, Паскаль.
В другом случае, когда матрица хранится как "строка столбцов", ее элементы разместятся в памяти по столбцам в следующем порядке:
А (1,1) А (2,1) А (3,1) А (1,2) А (2,2) А (3,2) А (1,3) А (2,3) А (3,3)
Такое размещение матрицы в памяти принято в Фортране.
В общем случае массив может иметь любую размерность. Для n-мерного массива указывается число размерностей, а также верхняя и нижняя границы диапазона изменения индексов.
Стек
Стек – линейная структура данных переменного размера с ограниченным доступом.
Особенность стековой структуры состоит в том, что доступ к его элементам, включение и исключение элементов возможны только с одного конца структуры – с вершины стека. На ячейку, находящуюся в вершине стека, всегда установлен указатель вершины стека.
Записать новый элемент можно только в вершину стека, в ту ячейку, на которую установлен указатель вершины. Прочитать из стека можно только тот элемент, который также находится в вершине стека и на который установлен указатель вершины.
Элемент, на который установлен указатель вершины, называется текущим. Указатель вершины всегда содержит информацию о позиции текущего элемента в стеке. Прочитанный элемент считается удаленным из стека.
Информация в стеке обрабатывается по принципу "последним пришел – первым ушел", так как первым будет прочитан тот элемент стека, который включался в стек последним. Структуру стека часто называют структурой типа LIFO (Last In – First Out).
Для хранения стека можно использовать как последовательное, так и связанное представление данных в памяти.
При последовательном представлении под стек резервируется блок памяти, внутри которого стек растет и сокращается. Указатель вершины стека можно размещать в одной из ячеек выделенного блока или в отдельной переменной памяти.
Можно организовать стек с изменяемым указателем вершины или с неизменным указателем вершины.
Рассмотрим стек с изменяемым указателем вершины.
Пусть указатель вершины хранится в переменной вне стека. Когда стек пуст, указатель вершины равен нулю. Перед включением каждого нового элемента указатель вершины увеличивается на 1 и устанавливается на свободную ячейку, в которую и будет записан вновь пришедший элемент. Этот элемент становится текущим. После выполнения нескольких операций включения стек может оказаться переполненным.
П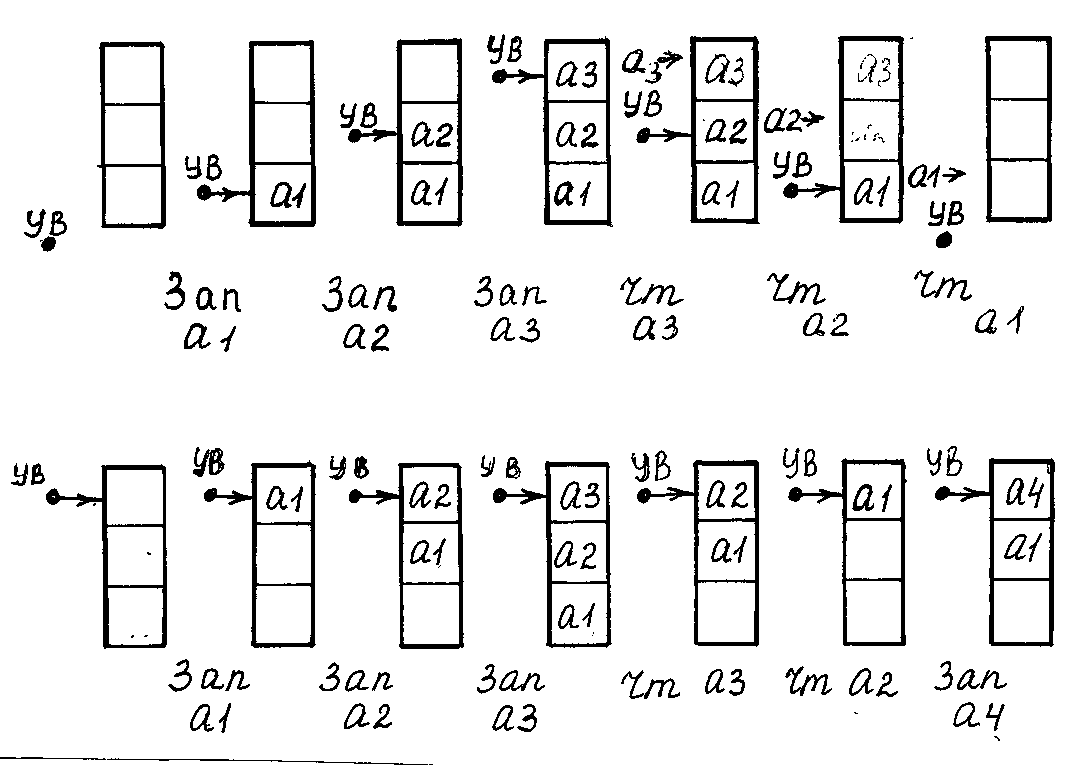 ри
выполнении операции чтения
читается содержимое той ячейки, на
которую установлен указатель вершины.
После чтения
текущего элемента
указатель вершины уменьшается на 1,
прочитанный элемент становится
недоступным и считается исключенным
из стека. После выполнения подряд
нескольких операций чтения стек может
оказаться пустым. Обычно операции записи
и чтения чередуются.
ри
выполнении операции чтения
читается содержимое той ячейки, на
которую установлен указатель вершины.
После чтения
текущего элемента
указатель вершины уменьшается на 1,
прочитанный элемент становится
недоступным и считается исключенным
из стека. После выполнения подряд
нескольких операций чтения стек может
оказаться пустым. Обычно операции записи
и чтения чередуются.
Можно организовать стек так, что значение указателя вершины будет неизменным. Тогда указатель вершины всегда будет указывать на одну и ту же ячейку, находящуюся в вершине стека. Здесь будет размещаться текущий элемент. Именно из этой ячейки читается элемент стека. В эту же ячейку будет записываться новый элемент.
Перед включением элемента ячейка, на которую установлен указатель вершины, должна быть пустой. Поэтому все имеющиеся в стеке элементы должны передвинуться так, чтобы освободить эту текущую ячейку. Операцию включения в стек часто называют «проталкиванием».
Читается из стека текущий элемент. После чтения текущего элемента все остальные элементы стека передвигаются так, чтобы стереть прочитанный элемент, так как этот элемент должен быть исключен из стека. Операцию чтения часто называют «выталкиванием».
На рисунке изображены стек с изменяемым указателем вершины и стек с неизменным указателем вершины.
Недостаток последовательного представления стека состоит в том, что всегда остается опасность переполнения стека, когда весь зарезервированный под стек участок памяти окажется заполненным.
При связанном представлении стека нет необходимости резервировать память под стек, так как все элементы стека размещаются в любых свободных ячейках памяти и связываются между собой указателями. Указатель вершины указывает на ячейку с текущим элементом. Вновь включаемый элемент размещается в любой свободной ячейке, на которую устанавливается указатель вершины. Ячейка с новым элементом включается в связанный список элементов стека. При чтении элемента указатель вершины изменяется так, чтобы прочитанный элемент оказался исключенным из связанного списка.
Структура стека используется в тех случаях, когда требуется быстрое выполнение операций чтения и записи без оценки содержательного смысла данных. Такие задачи являются типичными для трансляторов (вычисление алгебраических выражений) и для операционных систем (обработка прерываний, обработка вызовов подпрограмм).
Очередь
Очередь – линейная структура данных переменного размера с ограниченным доступом. Доступ к элементам очереди осуществляется по указателю начала очереди и указателю конца очереди.
Чтение элементов начинается с начала (с головы) очереди. Указатель начала (УН) указывает на элемент, который будет читаться первым. Прочитанный элемент исключается из очереди.
Включение элементов возможно только в конец (в хвост) очереди. Указатель конца (УК) всегда установлен на свободную ячейку, следующую за последним элементом очереди. В эту ячейку включается новый элемент.
Данные в такой структуре обрабатываются в порядке их поступления по принципу «первым пришел – первым ушел». Структуру очереди называют структурой типа FIFO (First In – First Out).
В памяти очередь можно хранить, используя как последовательное, так и связанное представление.
При последовательном представлении под очередь, также как и под стек, резервируется блок памяти, внутри которого очередь может расти и сокращаться.
Новый элемент записывается в ячейку, на которую установлен указатель конца. После выполнения операции записи указатель конца изменяется на 1 и перемещается на следующую свободную ячейку. Когда в результате включения новых элементов указатель конца достигает последней ячейки зарезервированного блока, в нее записывается последний элемент и очередь оказывается переполненной.
Читается из очереди элемент, на который установлен указатель начала. После выполнения операции чтения указатель начала изменяется на 1, передвигаясь к концу очереди, и устанавливается на следующий элемент очереди. Прочитанный элемент оказывается исключенным из очереди. Когда указатель начала совпадет с указателем конца (УН=УК), очередь окажется пустой.
После выполнения операций чтения в начале очереди появляются свободные ячейки, в которые можно записывать новые элементы. Поэтому когда в процессе записи указатель конца достиг конца зарезервированного блока, его можно «перебросить» на начало очереди и продолжат запись в освободившиеся ячейки. Когда указатель конца (после его «переброски») догонит указатель начала (УК=УН), очереди окажется переполненной.
Указатель начала в процессе чтения также может быть «переброшен», если после переброски указателя конца выполнялись операции записи в очередь. Когда указатель начала окажется равным указателю конца – очередь пуста.
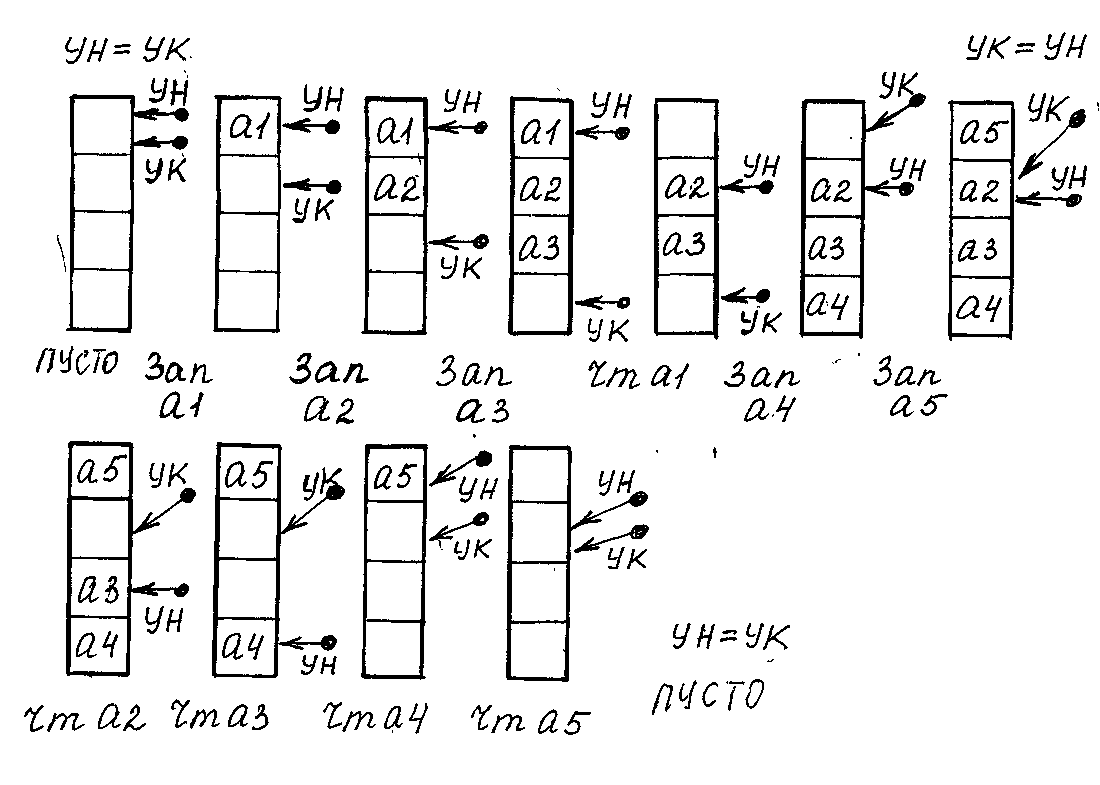
Возможны и другие способы организации очереди. Так очередь может иметь неизменным один из указателей. Тогда при выполнении операций записи-считывания потребуется перемещение элементов очереди.
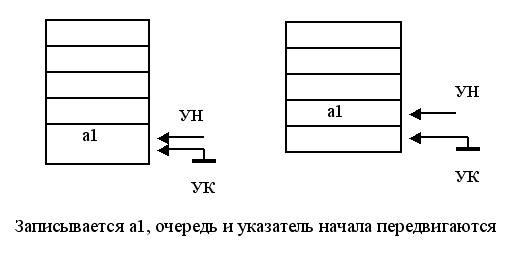
При неизменном указателе начала после операции чтения вся очередь, вместе с указателем конца, передвигается на одну ячейку к началу очереди. Прочитанный элемент стирается. Запись в очередь происходит по указателю конца, после чего указатель конца перемещается на свободную ячейку. Очередь при этом не передвигается.
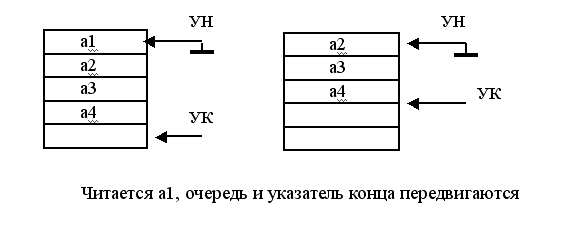
При неизменном указателе конца очередь, вместе с указателем начала, передвигается после выполнения каждой операции записи. В результате этого освобождается ячейка, на которую постоянно установлен указатель конца. Чтение происходит по указателю начала. После выполнения операции чтения указатель начала передвигается, очередь при этом не передвигается.
При связанном представлении очереди предварительного резервирования памяти не требуется. Записи, образующие очередь, размещаются в любых свободных ячейках памяти и связываются между собой указателями. Такая очередь может расти неограниченно. При включении и исключении элементов необходимо изменять указатели так, чтобы поддерживался связанный список элементов очереди. Кроме того, потребуется изменение значений указателей начала и конца очереди.
Структура очереди используется для решения различных задач, в которых обработка данных должна выполняться в порядке их поступления.
Структура очереди широко используется в ОС ЭВМ. Так, например, управление заданиями в вычислительных системах с разделением времени является традиционным примером использования очереди. В таких системах много пользователей одновременно работают с общим ресурсом системы, например, с центральным процессором. Программы пользователей, ожидающие выполнения, образуют очередь. Выбранный способ организации очереди и установленная дисциплина ее обслуживания во многом определяют эффективность функционирования такой системы.
Таблица
В рассмотренных ранее структурах данных читаться и обрабатываться может лишь тот элемент, к которому структура обеспечивает доступ посредством индекса или указателе вершины. В процессе доступа никак не анализируется содержимое полей записей.
В большинстве задач обработки информации обращение должно осуществляться к записи об объекте, обладающем вполне определенными свойствами. В таких случаях в процессе доступа необходимо анализировать содержимое того или другого поля записи. Читаться должна лишь запись с определенным значением указанного поля. Такой доступ, называемый доступом по ключу, реализуется в табличных структурах данных.
Таблица – это линейная структура данных с произвольным доступом по ключу записи. В зависимости от способа хранения таблицу можно рассматривать как структуру фиксированного или переменного размера.
Таблица состоит из строк и одного или более столбцов. Строки таблицы – это записи об объектах предметной области. Столбцы таблицы – это поля записей, содержащие значения свойств объектов. Каждый столбец имеет имя соответствующего свойства.
Доступ к элементам (записям) таблицы осуществляется по ключу, т.е. по заданному значению одного или нескольких полей. На обработку подается (например, выводится на экран) запись, содержащая заданное значение ключевого поля.
В зависимости от задачи обработки в качестве ключа могут использоваться те или иные поля. Ключ, состоящий из одного поля, называется простым, ключ, состоящий из нескольких полей, называется составным.
Среди всех полей может существовать такое поле, значения которого уникальным образом идентифицируют каждую запись таблицы. Такое поле называется первичным (основным, главным) ключом таблицы.
Для хранения таблиц используется как последовательное, так и связанное представление данных в памяти.
При последовательном представлении таблица хранится в виде последовательного списка и обладает всеми недостатками последовательного списка (см. рис. из этой лекции). Записи таблицы располагаются одна за другой в заранее зарезервированном блоке памяти. Такие таблицы легко составлять и дополнять. Новые записи добавляются в конец таблицы, на это требуется минимальное время. Однако поиск в таких таблицах длителен. В процессе поиска последовательно просматриваются все записи таблицы, начиная с первой, и анализируется значения их ключевого поля. Просмотр происходит до тех пор, пока не будет найдена нужная запись, или пока, после просмотра всей таблицы, не будет выработан сигнал отсутствия нужной записи.
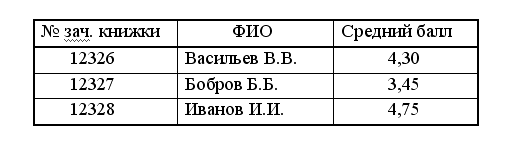
Обычно таблицы упорядочиваются в соответствии с каким-либо принципом, например, по возрастанию значений ключевого поля или по частоте обращения к записям. В том случае таблица хранятся в виде упорядоченного последовательного списка.
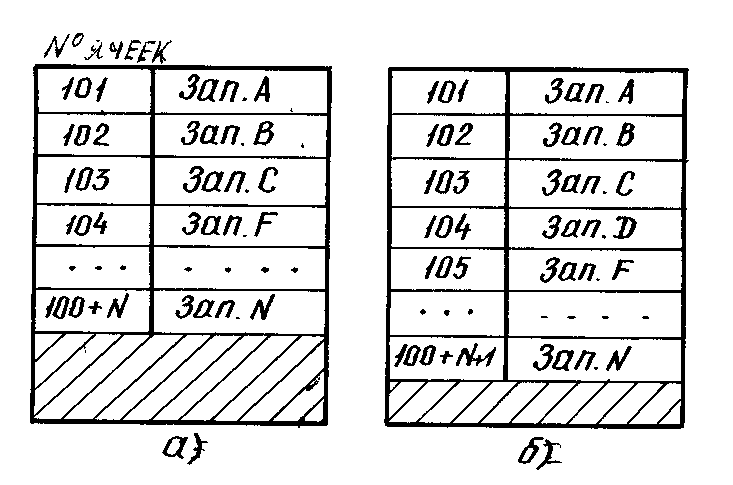
В таких таблицах поиск может быть существенно ускорен за счет использования специальных методов.
Однако ведение упорядоченной таблицы усложняется и сопровождается рядом дополнительных процедур. Так, например, для включения в упорядоченную таблицу новой записи надо определить место, которое должна занять эта запись в соответствии со значением своего ключа. Соответствующая ячейка памяти должна быть освобождена, для чего следующие записи передвигаются на одну ячейку, т.е. часть таблицы перезаписывается.
Пусть в таблицу, упорядоченную по алфавиту, содержащую записи Зап.А, Зап.В, Зап.С и Зап.F, …, Зап.N надо включить Зап. D. Эту запись необходимо физически разместить вслед за записью С в ячейке 104. Для этого все последующие записи необходимо передвинуть в сторону больших адресов. Таким образом, таблицу придется перезаписывать всякий раз с приходом новой записи. При удалении записи таблицу также придется перезаписывать.
Хранение таблиц в виде упорядоченного последовательного списка выгодно тогда, когда предельный размер таблицы заранее известен, а задачи обработки данных требуют частого обращения к данным (частых поисков), но редкого добавления и удаления данных.
Упорядоченную таблицу можно хранить в виде связанного списка. Ведение динамически изменяющейся таблицы при этом не требует выполнения процедур перезаписи. Однако поиск в такой таблице возможен лишь последовательным просмотром записей в порядке, определяемом указателем. Ускоренный поиск в таких таблицах невозможен. Под указатели расходуется дополнительная память.
Для хранения таблиц часто используют смешанный (последовательно-связанный) способ хранения.
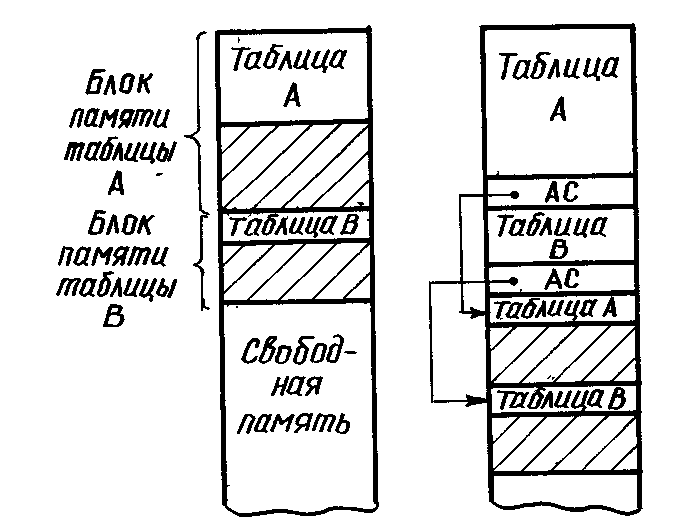
При создании таблицы записи размещаются последовательно в зарезервированном блоке памяти (Табл. А и Табл. В). По мере роста Таблицы А, после того как выделенный под нее блок окажется заполненным, для табл. А выделяется новый блок памяти. Он связывается указателем с первым блоком. После заполнения Таблицы В под нее также выделяется новый блок памяти. Такие таблицы могут расти как угодно долго.
Для хранения таблиц часто используется способ, основанный на преобразовании ключа записи в адрес ее хранения. При этом обеспечивается самый быстрый – прямой - доступ к записям.
Если все N записей таблицы имеют разные значения ключа Ki и найдена функция f(Ki) , такая, что для любого 0 < I <= N f(Ki) принимает целое значение от 0 до m, то значение f(Ki) можно рассматривать как адрес ячейки памяти, в которой и размещается запись с ключом Ki . Функция f(Ki) - это функция преобразования (функция расстановки). Доступ к любой записи осуществляется путем непосредственного вычисления по значению ключа адреса хранения этой записи. Время поиска в таких таблицах минимально и определяется, в основном, временем вычисления функции f(Ki) .
В роли адреса табличного элемента может выступать его порядковый номер; индекс элемента массива, в котором хранится запись; номер записи файла, в которой размещается табличный элемент.
Табличная структура – это удобная, привычная и весьма распространенная форма представления данных. Таблицы широко используются в трансляторах операционных систем. В таких таблицах хранятся, например, символы входного языка и коды их внутреннего представления, идентификаторы переменных и адреса их хранения и т.п. На табличном представлении данных основаны реляционные базы данных.