

Градiєнтний алгоритм навчання
t+1 iтерацiя
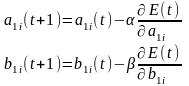
- розмiр кроку.





Застосування мгуа до аналізу фінансових показників Теоретичні відомості
Метод групового урахування аргументів в задачах прогнозування та ідентифікації
Постановка задачі:
Задана
множина вихідний даних
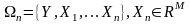 ,
де
– кількість змінних, а
,
де
– кількість змінних, а
 – кількість реалізацій спостереження.
Необхідно за допомогою нечіткого МГУА
синтезувати рівняння регресії
– кількість реалізацій спостереження.
Необхідно за допомогою нечіткого МГУА
синтезувати рівняння регресії
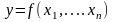 ,
адекватне вихідній множині даних, при
чому отримана модель повинна бути
найменшою складності.
,
адекватне вихідній множині даних, при
чому отримана модель повинна бути
найменшою складності.
Основні принципи і загальна схема методу
Метод групового урахування аргументів (МГУА) був запропонований наприкінці 60-х – початку 70-х академіком А.Г.Івахненко (Інститут кібернетики НАН України) .
Цей метод використовує ідеї самоорганізації і механізми живої природи – схрещування (гібридизацію) і селекцію (добір).
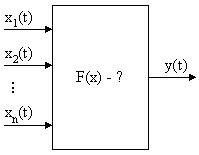
Рис. 6.1 Загальна схема задачі ідентифікації моделі
Нехай
є вибірка з
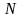 спостережень
вхідних векторів Х(і)
та вихідних Y(i):
спостережень
вхідних векторів Х(і)
та вихідних Y(i):

За результатами спостережень треба визначити F(x). Причому структура моделі F(x) невідома.
Найбільш повна залежність між входами X(i) і виходами Y(i) може бути представлена за допомогою узагальненого полінома Колмогорова-Габора.
Нехай
є вибірка
 ,
тоді такий поліном має вигляд:
,
тоді такий поліном має вигляд:

де
всі коефіцієнти
 не відомі.
не відомі.
При побудові моделі (при визначенні значень коефіцієнтів) в якості критерію якості, використовується критерій регулярності (точності):

Нам
треба знайти таку модель, для якої
 .
.
Розглянемо основні принципи та ідеї МГУА.
Принцип
множинності моделей:
існує множина моделей на даній вибірці,
що забезпечують нульову помилку
(достатньо підвищувати ступінь полінома
моделі). Тобто, якщо є N
вузлів інтерполяції, то можна побудувати
ціле сімейство моделей, кожна з яких
при проходженні через експериментальні
точки буде давати нульову помилку
 .
.
Як
правило, ступінь нелінійності беруть
не вище ,
якщо
– кількість реалізацій вибірки.
,
якщо
– кількість реалізацій вибірки.
Позначимо
через
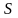 –
складність моделі (визначається числом
членів полінома Колмогорова-Габора).
–
складність моделі (визначається числом
членів полінома Колмогорова-Габора).
Значення
помилки
 залежить
від складності моделі. Причому в міру
росту складності спочатку вона буде
падати, а потім зростати. Нам же потрібно
вибрати таку оптимальну складність,
при якій помилка буде мінімальна. Крім
того, якщо враховувати дію перешкод, то
можна виділити наступні моменти:
залежить
від складності моделі. Причому в міру
росту складності спочатку вона буде
падати, а потім зростати. Нам же потрібно
вибрати таку оптимальну складність,
при якій помилка буде мінімальна. Крім
того, якщо враховувати дію перешкод, то
можна виділити наступні моменти:
При різному рівні перешкод залежність від складності S буде змінюватися, зберігаючи при цьому загальну спрямованість (мається на увазі, що з ростом складності вона спочатку буде зменшуватись, а потім – зростати).
При збільшенні рівня перешкод величина
 буде
зростати.
буде
зростати.З ростом рівня перешкод величина
 буде зменшуватись (оптимальне значення
складності буде зміщатися вліво).
Причому
буде зменшуватись (оптимальне значення
складності буде зміщатися вліво).
Причому
 ,
якщо рівень перешкод не нульовий (див.
Рис. 6.2).
,
якщо рівень перешкод не нульовий (див.
Рис. 6.2).
Рис. 6.2. Залежніст значення помилки від складності моделі
Теорема неповноти Геделя: У будь-якій формальній логічній системі мається ряд тверджень і теорем, які не можна ні спростувати, ні довести, залишаючись у рамках цієї системи аксіом.
У даному випадку ця теорема означає, що вибірка завжди неповна.
Один зі способів подолання цієї неповноти – принцип зовнішнього доповнення. В якості зовнішнього доповнення використовується додаткова вибірка (перевірочна), точки якої не використовувалися при навчанні системи (тобто при пошуку оцінок значень коефіцієнтів полінома Колмогорова-Габора).
Пошук найкращої моделі здійснюється в такий спосіб:
Уся вибірка поділяється на навчальну і перевірочну:

На навчальній вибірці
 визначаються значення
визначаються значення
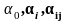 .
.На перевірочній вибірці
 відбираються кращі моделі.
відбираються кращі моделі.
Вхідний
вектор має розмірність N
 .
.
Принцип свободи вибору (неостаточності проміжного рішення):
Для кожної пари
 та
та
 будуються часткові описи (усього
будуються часткові описи (усього
 )
виду:
)
виду:
або
 ,
,
 (лінійні);
(лінійні);або
 ,
(квадратичні).
,
(квадратичні).
Визначаємо коефіцієнти цих моделей по МНК, використовуючи навчальну вибірку. Тобто знаходимо
 .
.Далі на перевірочній вибірці для кожної з цих моделей шукаємо оцінку

(де
 - дійсне вихідне значення в k-тій
точці перевірочної вибірки;
- дійсне вихідне значення в k-тій
точці перевірочної вибірки;
 - вихідне значення в k-тій
точці перевірочної вибірки відповідно
до s-тієї
моделі) і визначаємо F
кращих
моделей.
- вихідне значення в k-тій
точці перевірочної вибірки відповідно
до s-тієї
моделі) і визначаємо F
кращих
моделей.
Обрані
 подаються на другий ряд. Шукаємо
подаються на другий ряд. Шукаємо
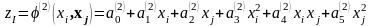
Оцінка
тут така ж, як на першому ряді. Добір
кращих здійснюється знову так само, але
 .
.
Процес конструювання рядів повторюється доти, поки середній квадрат помилки буде падати. Коли на шарі m одержимо збільшення помилки , то припиняємо.

Рис. 6.3. Синтез структури МГУА
Якщо
часткові описи квадратичні і число
рядів полінома
,
то одержуємо, що ступінь полінома
 .
.
На відміну від звичайних методів статистичного аналізу, при такому підході можна одержати досить складну залежність, навіть маючи коротку вибірку.
Існує
проблема:
на першому ряді можуть відсіятися деякі
перемінні
 і
,
котрі впливають на вихідні дані.
і
,
котрі впливають на вихідні дані.
У
зв'язку з цим запропонована така
модифікація: на другому шарі подавати
 і
,
тобто:
і
,
тобто:
 .
.
Це важливо при більшому рівні перешкод, щоб забезпечити незміщеність моделей.
Виникає два критерії добору кращих кандидатів часткових описів, які передаються на певному шарі на наступний ряд (шар) .
Критерій регулярності (точності)



Критерій незміщеності.
Беремо
усю вибірку, поділяємо на дві частини
R= +
+
Перший
експеримент:
-
навчальна вибірка,
-перевірочна;
визначаємо виходи моделі
 ,
i=1..R
,
i=1..R
Другий
експеримент:
-
навчальна вибірка,
-перевірочна;
визначаємо виходи моделі
 ,
i=1..R
,
i=1..R
і порівнюємо. Критерій незміщеності:

Чим
менше
 ,
тим більше незміщеною є модель.
,
тим більше незміщеною є модель.
Такий критерій визначається для кожного часткового опису першого рівня і потім знаходиться для рівня в цілому для F кращих моделей
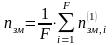
У
ряді варіантів F=1.
Те ж саме на другому шарі обчислюємо
 .
.
І процес селекції здійснюється доти, поки цей критерій не перестане зменшуватися, тобто до досягнення умови

Метод групового врахування аргументів (МГУА) базується на задаванні правил ускладнення моделі, системі опорних функцій, критеріях селекції та методу регуляризації, згідно зовнішнім критеріям. ЕОМ проводить генерацію моделей-претендентів, селекцію згідно зовнішнім критеріям та відсів моделей, що не пройшли селекцію. В зв’язку з чим основну структуру алгоритму самоорганізації можна навести у такому вигляді:
попередня обробка спостережень з урахуванням системи обраних опорних функцій (скорочується кількість претендентів);
генерація множини моделей-претендентів;
обчислення критеріїв селекції, що є зовнішніми доповненнями, та пошук моделі оптимальної складності.
Головна ідея МГУА полягає в наступному: стверджується, що для задачі однократного прогнозу доцільно знизити точність визначення оцінок коефіциентів рівняння регресії, але за рахунок цього придати йому більшу регулярність. Тому нашою метою в цій задачі є не мінімізація помилок на вже відомих вузлах інтерполяції, а мінімізація помилок на нових точках, які ми в момент синтезу рівняння регресії ще не мали. Розглянемо полиноміальні алгоритми методу групового урахування аргументу. Послідовність вихідних даних ділиться на перевірочну та навчальну. Як визначено вище – M – кількість вузлів інтерполяції; m — кількість членів повного поліному регресії. При m>M розв'язок можливо отримати тільки за допомогою МГУА.
Нехай
повний опис об'єкту задається деякою
залежністю
 .
Замінимо цей вираз декількома рядами
часткових описів.
.
Замінимо цей вираз декількома рядами
часткових описів.
Перший ряд селекції:

Другий ряд селекції:

Різноманітні
алгоритми МГУА розрізняються по виду
функції часткового опису .
В даній роботі розглядаються три види
часткових описів:
.
В даній роботі розглядаються три види
часткових описів:
лінійний
частковий опис –
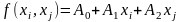
неповний квадратичний частковий опис –

квадратичний частковий опис – а
 ,
,
де
 – нечітке число.
– нечітке число.
З
ряду в ряд селекції за допомогою порогових
відборів передається тільки деяка
кількість самих регулярних або незміщених
змінних. Звичайно ця кількість однакова
на всіх рядах селекції, та дорівнює
 .
.
Правило зупинки селекції: ряди селекції нарощуються до тих пір, доки критерій незміщеності розв'язків зменшується, така кількість називається свободою вибору. Для запобігання індуциту селекцію при досягненні мінімуму необхідно зупинити.
Зовнішні критерії оптимальності
При селекції моделей в нашій роботі використовувались критерії регулярності та незміщеності. Загальним для сформульованих нижче критеріїв є те, що вони використовуються як зовнішні доповнення, тобто визначаються на основі перевірочної вибірки та в значній мірі відповідають вимозі відтворюваності результату.
Реалізація
вибірки
ділиться на реалізацію навчальної
вибірки
 ,
за допомогою якої оцінюються параметри
моделі, та реалізацію перевірочної
вибірки
,
за допомогою якої оцінюються параметри
моделі, та реалізацію перевірочної
вибірки
 ,
за допомогою якої відбувається вибір
придатної моделі. Критерій регулярності
визначає середньоквадратичне відхилення
моделі на перевірочній вибірці:
,
за допомогою якої відбувається вибір
придатної моделі. Критерій регулярності
визначає середньоквадратичне відхилення
моделі на перевірочній вибірці:
 .
.
Якщо виходити з того, що при постійному комплексі умов добра апроксимація в минулому гарантує добру апроксимацію в найближчому майбутньому, то критерій регулярності можна рекомендувати для короткострокового прогнозу, тому що розв'язок, отриманий на нових реалізаціях, дає лише невелике відхилення вихідних даних. При цьому в процесі селекції можуть бути загубленими важливі змінні, вплив яких, одначе, непрямо буде урахований через інші змінні.
Критерій незміщеності (несуперечності) моделі. В його основу закладений той факт, що для одного об'єкту досліджень по різним вибіркам даних, отриманих від нього при інших рівних умовах, повинні бути отримані близькі моделі, що визначають поведінку об'єкту.
Критерій можна записати наступним чином:
 ,
,
де
 – розміри першої та другої підвибірок
даних відповідно,
– розміри першої та другої підвибірок
даних відповідно,
 – значення прогнозу першої та другої
моделі відповідно до всіх точок вибірок.
– значення прогнозу першої та другої
моделі відповідно до всіх точок вибірок.
В даній роботі для відсіву моделей на ітерації селекції використовувався критерій, що являє собою опуклу комбінацію критерію несуперечності та регулярності у наступному вигляді:
 ,
,
де - вагових коефіціент, 01.
Переваги метода МГУА
Можна відновити невідому довільно складну залежність по обмеженій вибірці. Число невідомих параметрів моделі може бути більше, ніж число точок навчальної послідовності.
Можливість адаптації параметрів моделі при одержанні нових даних експериментів. (Закрема використовуючи РМНК)