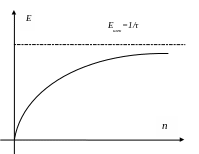
7 Сурет. Бір операцияны бес тактіде орындайтын тізбекті құрылғының
көмегімен С=А+В қосындысын есептеу
Конвейерлік өңдеу
Алдыңғы мысалда, бір қосу операциясын орындау үшін, құрылғы бес тактіге бұғатталып басқа ешқандай жұмыс орындамаған болатын. Бұның тиімділігі бар ма және енгізілетін массив элементтерінің барлығын өңдеу процесін одан да тиімді ұйымдастыруға бола ма?

8 Сурет. Бір операцияны әрбірі бес тактіде орындайтын екі бірдей тізбекті
құрылғының көмегімен С=А+В векторларын қосу
Бұл сұраққа жауап беру үшін нақты сандардың компьютерде берілуін еске түсіруіміз керек. Мұнда әрбір сандар жұбын қосу микрооперациялар тізбегі түрінде орындалады, ретін салыстыру, ретін теңестіру, мантиссаларын қосу, нормализациялау т.б. Жақсы жағы: әрбір енгізілген сандар жұбын өңдеу процесінде микрооперация бір рет қана және әруақытта бір тәртіппен бірінен кейін бірі іске қосылады. Бұл, бірінші микрооперация өз жұмысын орындап нәтижесін екіншісіне бергеннен кейін, ағымдағы жұпты өңдеу үшін бұдан ары оның қажеті болмайды, яғни ол, құрылғыға енгізілуді күтіп тұрған келесі аргументтер жұбын өңдеуді бастай алу мүмкіндігі бар деген сөз.
Осы айтылғандарды ескере отырып, құрылғының келесі түрде құрастырылуын қарастырайық. Әрбір микрооперацияны құрылғының жеке бөлігінде белгілеп алып, оларды орындалу тәртібі бойынша орналастырамыз. Алғашқы уақыт мезетінде енгізілген мәндер өңдеу үшін бірінші бөлікке келіп түседі. Бірінші микрооперация орындалғаннан кейін, бірінші бөлік өз жұмысы нәтижесін екінші бөлікке береді де, өзі өңдеуге жаңа жұпты алады. Осылайша, енгізілген аргументтер өңдеудің барлық этапынан өткеннен кейін, құрылғыдан шығарда операцияның орындалу нәтижесі алынады.
Есептеуді ұйымдастырудың осындай тәсілі – конвейерлік өңдеу деп аталады. Құрылғының әрбір бөлігі конвейердің баспалдағы, ал жалпы баспалдақтар саны – конвейер ұзындығы деп аталады. Нақты сандарды қосу операциясын орындау үшін әрқайысы бір тактіде қосылатын бес баспалдақтан тұратын конвейерлік құрылғы жобаланған болсын делік. Конвейерлік құрылғының бір операцияны орындау уақыты барлық конвейер баспалдақтарының қосылу уақыттарының қосындысына тең. Бұл екі санды қосу операциясы бес тактіде орындалады, яғни алдыңғы тізбекті құрылғы жағдайындағы осындай операцияның орындалу уақытымен бірдей деген сөз.
Енді екі массивті қосу процесін қарастырайық (9 сурет). Алғашында, бірінші парды қосу нәтижесі бес тактіден кейін алынады. Бірақ мұнда, бірінші пармен бірге бір мезетте басқа элементтердің де бөлшектік өңдеуден өткенін байқаймыз. Конвейерлік құрылғыда әрбір келесі тактіде кезектегі элементтер қосындысы пайда болады. Сонымен, барлық операцияны орындауға тізбекті құрылғыны пайдаланғанда 500 такті қажет етілсе, конвейерлік құрылғыда 104 такт қажет етіледі.
Шамамен жалпы жағдайда да осындай болады. Егер конвейерлік құрылғы l баспалдақты қамтыса, және әрбір баспалдақ бір бірлік уақытында қосылса (срабатывает), онда бұл құрылғының n байланыссыз (независимый) операцияны өңдеу уақыты l+n-1 бірлікті құрайды. Егер де бұл құрылғыны монопольді режимінде пайдаланса (тізбекті сияқты), онда өңдеу уақыты l×n-ге тең болады. Нәтижесінде, мәліметтерді конвейерлік өңдеуді пайдалану есебінен n-нің үлкен мәндері үшін l есе үдеу аламыз.

9 сурет. Конвейерлік құрылғының көмегімен С = А+В векторларының
қосындысын есептеу. Конвейердің бес баспалдағының
әрбірі бір тактіде іске қосылады
Мұндағы «скалярлық», «векторлық» және «конвейерлік» эпитеттерін пайдалану жиі шатасуға әкеліп соқтырады, себебі, олардың көбі мағынасы жақын «өңдеу», «команда» және «құрылғы» ұғымдары үшін де қолданылады. Скалярлық команда деп, барлық аргументі тек қана скаляр шама болатын команданы айтады. Егер команданың кемінде бір (хотя бы один аргумент) аргументі вектор болатын болса, онда мұндай қоманданы векторлық команда деп атайды. Мысалы, Сray C90 компьютерінің командалар жүйесінде екі нақты санды S1 және S2 қосып, нәтижесін S3 –ке енгізітін Ascal скалярлық командасы бар S3: Ascal S1,S2 → S3. Сонымен қатар, бір мезгілде скаляр командамен бірге екі векторды қосып, нәтижесін үшіншісіне V3 енгізетін Avekt командасы қарастырылған: AvektV1, V2 → V3.
Түскен команданың кодына байланысты (Ascal немесе Avekt) процессор операнданы скаляр адрестері ретінде немесе вектор бастамасы адресі ретінде интерпретациялайды.
Скаляр
және конвейерлік құрылғылар арасындағы
айырмашылықты біз жоғарыда талдап
өттік. Кейбір жағдайларда, процессор
архитектурасына деректер векторларын
өңдеу үшін ғана бағытталған векторлық
құрылғылар енгізіледі. Мысалы, Сray C90
компьютерінде бүтін сандарды қосудың
тек скаляр командаларын
![]() ғана орындайтын
ғана орындайтын
![]() конвейерлік құрылғысы да және бүтін
санды қосудың векторлық командаларын
конвейерлік құрылғысы да және бүтін
санды қосудың векторлық командаларын
![]() ғана орындауға арналған конвейерлік
құрылғысы
ғана орындауға арналған конвейерлік
құрылғысы
![]() да бар. Айта кетсек, бұл компьютерде (
және
бүтін санды командаларынан ерекше)
нақты сандарды қосу командалары Ascal
және
Avekt
бір құрылғыда
да бар. Айта кетсек, бұл компьютерде (
және
бүтін санды командаларынан ерекше)
нақты сандарды қосу командалары Ascal
және
Avekt
бір құрылғыда
![]() орындалады.
орындалады.
Жоғарыда қарастырып кеткендей, конвейерлік құрылғы бір тактіде қосылатын l баспалдақтан тұрсын. n элементтен тұратын екі векторды бір векторлық команда көмегімен немесе осы векторлар элементтерін қосатын қатарынан n скалярлық командаларды орындау арқылы қосуға болады. Егер n скалярлық командалар осындай құрылғыда бірінен кейін бірі орындалатын болса, онда жалпы заңдарға сәйкес олар l+n-1 тактіде өңделген болар еді.
Ал енді осы екі векторды қосу үшін векторлық командаларды пайдаланатын болсақ жоғарыдағы формулаға тағы бір элемент қосылады: σ+l+n-1, мұндағы σ – векторлық команданы иницализациялау үшін қажетті уақыт. Негізінде, векторлық команданы орындау, сегментациялауды қолдау немесе векторлық команданы иницализациялау кезінде ғана болмаса басқалай қосымша іс-әрекеттерді қажет етпейді десе де болады. Әрине, формуладан көріп тұрғанымыздай n шамасы, яғни элементтер саны аса көп болмаған жағдайда сәйкес векторлық командаларды векторлық емес скаляр режимде орындаған тиімді екені айқын.
Формуладағы σ да l-де n–нің мәніне тәуелсіз, сондықтан, кіріс векторларының ұзындығы артқан сайын конвейерлік өңдеудің тиімділігі арта түседі. Егер өңдеудің тиімділігі ретінде орындалған операциялар санының n оның орындалу уақытына t қатынасына тең конвейерлік құрылғының нақты өнімділігін Е алатын болсақ, онда өнімділіктің кіріс векторына тәуелділігі келесі қатынаспен анықталады:
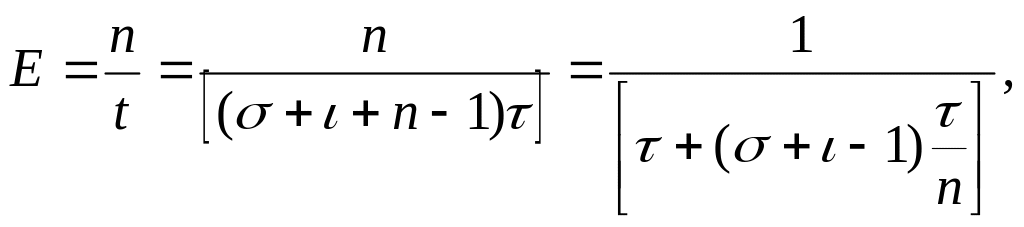
мұндағы τ – компьютердің жұмыс тактісі уақыты.
Төмендегі 10 - суретте осы тәуелділік график түрінде келтірілген.