

30 Сурет. Cray t3e компьютерінің коммуникациялық торы
Бұл әрбір тораптың алты тікелей көршілері бар дегенді білдіреді және де тораптардың қайда орналасқанына байланыссыз: параллелепипед ішінде, қабырғасында, қырында немесе төбесінде.
Коммуникациялық желіні мұндай тәсілмен ұйымдастырудың көп артықшылықтары бар, олардың ішінен екеуін атап кетелік. Біріншіден, бұл бұзылған байланыстарды айналып өту үшін альтернативті маршрут таңдау мүмкіндігі. Екіншіден, әртүрлі ПЭ өзара қатынасы кезінде шекаралық тораптардың жылдам байланысы және тордағы орын ауыстырулардың кішігірім орта саны.
Екі торап арасындағы әрбір элементарлық байланыс – бұл деректерді берудің екі бірбағытталған каналдары, ол қарама-қарсы бағыттарда деректерді бір мезгілде алмастыруға мүмкіндік туғызады. Cray T3E-1200Е моделінде тораптар арасындағы деректерді жіберудің максимал жылдамдығы 480 Мбайт/с, аппараура деңгейіндегі латенттігі 1 мкс көп емес.
Коммуникациялық желі Х, У, Z бағыттарындағы тораптардың желілік маршрутизаторларын жалғастыратын үшөлшемді торды құрайды. Екі А және В тораптары арасындағы деректермен алмасу үшін маршрут таңдау келесі түрде жүргізіледі. А төбесінен шыға отырып кезектегі транзиттік торап пен В төбесінің координатасы Х өлшемі бойынша қашан теңескенше, желілік мапшрутизаторлар алғашында Х өлшемі бойынша ығысуды орындайды. Онан кейін осындай процедура У бойынша, соңында Z бойынша орындалады (32 сурет). Ығысу оң да теріс те бола алатындықтан, бұл механизм желі бойынша орын ауыстырулар санын минимумдауға және бұзылған байланыстарды айналып өтуге көмектеседі. Желілік маршрутизаторлар әрбір үш өлшем Х, У, Z бойынша деректерді бір мезгілде параллель тасымалдауға болатындай етіп жобаланған.
Компьютер архитектурасындағы қызықты ерекшеліктердің бірі барьерлік синхрондауды аппаратық қолдау болып табылады. Барьер – ол бағдарламадағы нүкте, әрбір процесс осы нүктеге жетісімен, қашан қалған процесстер осы барьерге жеткенінше күтуі тиіс. Сонан кейін ғана, яғни барлық процестер барьерге жеткенде ғана процесстердің бәрі жұмыстарын ары қарай жалғастыра алады. Синхрондаудың бұл түрі бағдарламаларда жиі пайдаланылады, бірақ оны бағдарламалау жүйесінің құралдарымен іске асыру үлкен шығындарға алып келеді. Ал аппаратурада барьерлерді қолдау бұл шығындарды минимумдауға мүмкіндік береді.
Әрбір ПЭ колдау схемаларында бірнеше кіріс және шығыс синхрондау регистрлері қарастырылған. Бұл регистрлердің әрбір разряды барьерді іске асыратын өзінің тәуелсіз өрімдерімен жалғастырылған. Синхрондаудың барлық өрімі бірдей, ал олардың жалпы саны компьютердің конфигурациясына байланысты. Әрбір өрім құрылғының екі типі негізінде екілік ағаш қағидасы бойынша тұрғызылады (31 сурет). Бір құрылғылар логикалық көбейтуді (&) іске асырса, басқалары кірісті өзінің екі шығысына («1-2») қайталауды орындайды. Соңғы құрылғының шығысы (&) бірінші қайталау құрылғысының «1-2» кірісі болады. Қайталау құрылғысы алынған мәндерді өз өрімімен барлық ПЭ таратып және оларды шығыс регистрінің сәйкес разрядына жазып отырады.
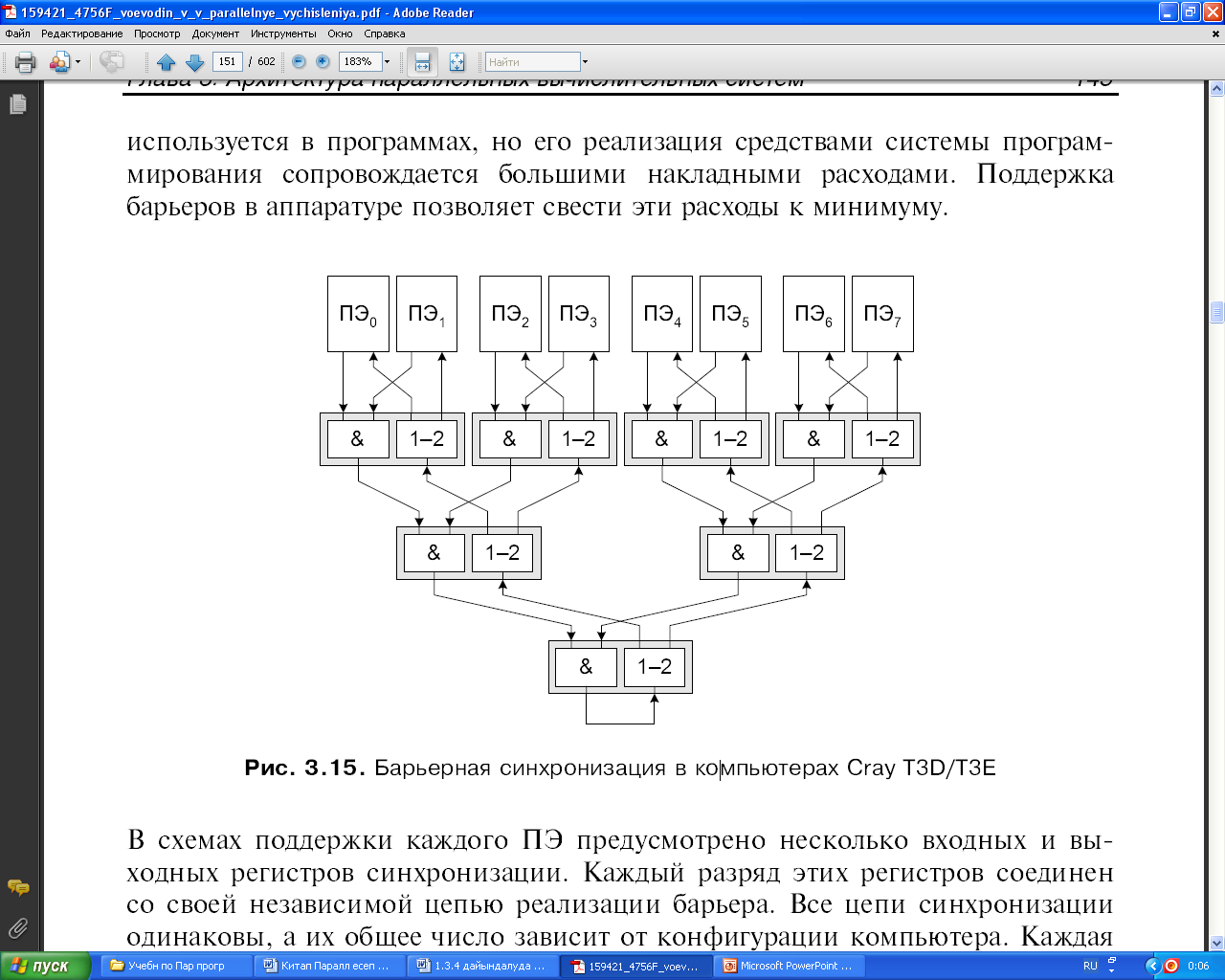
31 Сурет. Cray т3d/t3e компьютерлеріндегі барьерлі синхрондау
Бір өрімнің жұмысын қарастырайық. Алғашқыда әрбір ПЭ кіріс және шығыс регистрінің сәйкес разряды нөлге тең. Процессорлық элементтің шығыс разрядында «бірдің» пайда болуы барлық процесстердің барьерге жеткендігінің белгісін береді. Процесс барьерге жетісімен сәйкес ПЭ кіріс регистрінің разряды бірге өзгертіледі. Кезкелген құрылғының шығысында (&) «бір» тек сол жағдайда ғана пайда болады, егер екі кірісте де бірлік болса. Егер қандай да бір процесс әлі барьерге жетпесе, онда осы ПЭ кірісіндегі нөл логикалық көбейту құрылғыларының өрімімен өтеді және соңғы құрылғының (&) шығысында нөлді анықтайды. Бұдан шығары: әрбір ПЭ шығыс разрядтарында да нөлдер болады. Соңғы процесс қалай өзінің кіріс разрядына бірді жазса, солай соңғы құрылғының (&) шығысында бірлік пайда болады және қайталау құрылғылары өрімімен әрбір ПЭ шығыс разрядтарына жеткізіледі. Шығыс разрядының мәні бойынша әрбір процесс қалған барлық процесстердің барьерлік синхрондау нүктесіне жеткенін біледі.
Қарастырылып жатқан компьютерлерде бұл өрімдер басқаша да пайдаланылады. Егер схемада барлық логикалық көбейту құрылғыларын логикалық қосу құрылғыларымен алмастыратын болсақ, онда «Эврика» механизмін іске асыратын өрім алынады. Кезкелген логикалық қосу құрылғысының шығысында «бір» сол жағдайда пайда болады, егер бір оның кірісінің кемінде қандай да біреуінде бар болса ғана. Яғни, қалай бір ПЭ өзінің кіріс регистріне бірді жазып алса, берілген ПЭ қандай да оқиғаның орын алғанын білдіріп, бұл бір барлық ПЭ таратылады. Бұл қарастырылған механизмнің қолданылу аймағының бірі – іздеу есептері.
Cray T3E немесе IBM SP типті дәстүрлі суперкомпьютерлерден басқа, таратылған жадылы компьютерлер класы соңғы жылдары есептеу кластерлері есебінен белсенді түрде кеңеюде. Айта кету керек, компьютерлік әдебиетте «кластер» ұғымы әртүрлі мағынады қолданылады. Мысалы, «кластерлік» технология деректер базасы серверлерінің немесе Web-серверлер сенімділігі және олардың жұмыс істеу жылдамдығын арттыру үшін пайдаланылады. Бұл жерде біз есептеу сипатындағы есептерді шешуге бағытталған кластерлер туралы айтатын боламыз.
Классикалық суперкомпьютерлер әрқашанда өздерінің үлкен өлшемдерімен, жоғары өнімділіктерімен, үлкен жадысымен және де өте қымбат бағаларымен ерекшеленеді. Әрине, бұл түсінікті де, керемет бірегей шешімдер мен рекордтты көрсеткіштерге ие бұл машиналар арзан тұруы мүмкін емес те. Бірақ-та, соңғы уақыттағы электроникадағы прогресс айтарлықтай өзгерістер енгізуде. Өткен ғасырдың 90-шы жылдары әлем рыногында қымбат емес және өте тиімді микропроцессорлар мен коммуникациялық шешімдер пайда болды. Жаппай өндірістің құрамдас бөліктерінен суперкомпьютерлерді құрастырудың нақты мүмкіндіктері ұсынылды. Бұл өз кезегінде, параллель компьютерлердің дамуындағы жеке бағыттардың бірі болатын кластерлік есептеу жүйелерінің өмірге келуіне септігін тигізді.
Қысқаша айтар болсақ, есептеу кластері дегеніміз бір есепті шешуге арналған қандай да бір желі аймағында біріктірілген компьютерлер жиыны (32 сурет). Әдетте есептеу тораптары ретінде рынокта қолжетімді бірпроцессорлы компьютерлер, екі немесе төрт процессорлы SMP-серверлері пайдаланылады. Әрбір торап операциялық жүйенің өз көшірмесінің басқаруымен жұмыс істейді. Мұндай операциялық жүйелер ретінде көбіне стандартты ОЖ: Linux, Windows NT, Solaris және т.б. пайдаланылды. Тораптардың құрамы және қуаты бір кластер аймағында да өзгеруі мүмкін, ал ол біртекті емес жүйелерді құрастыруға мүмкіндік береді. Нақты коммуникациялық ортаны таңдау көптеген факторлармен анықталады: шешілетін есептер класының ерекшеліктері, қаржылық қолжетімділік, кластердің одан ары кеңейтілу қажеттілігінің туындауы және т.б. Кластер конфигурациясына арнайы компьютерлерді, мысалы, файл-серверді енгізу мүмкіндігі бар. Әрине, Интернет арқылы кластерге қашықтан қатынас мүмкіндігі де ескерілген.
