§1.3.1 Параллель компьютерлер және жүйелер классификациясы
Кез-келген ЭЕМ-да есептеу нәтижесіне қол жеткізу үшін қолданылатын стандартты схема:
мақсат құру;
модельдеу;
алгоритм дайындау;
бағдарлама дайындау;
тестілеу және түзетулер енгізу;
нәтижені талдау,
2-5 пункттерінің қайталанатын этаптарының қажеттілігінше математикалық моделін жасау;
бағдарламаның қорытындысын әзірлеу екені белгілі.
Параллель есептеу спецификасын ескерсек, бұл схемаға тағы 4 пункт енгізу қажет болады:
Ақпараттық талдау – есептің алгоритмін, алгоритм графының көмегімен ондағы параллельділіктің қолданылуын анықтауға зерттеу;
процесті параллель тарату (қанша процесті қанша процессорға бөлуін анықтайды);
параллель бағдарламаны құрастыру;
параллель бағдарламаның тиімділігін бағалау:
тиімді бағдарламалау алгоритмін таңдау;
ол алгоритмді қолданып, жүйелік бағдарлама жасау;
жүйелі бағдарламалардың жұмыс уақытын өлшеу;
таңдалған жүйелік алгоритмді қолданып, параллельді бағдарлама жасау;
алынған бағдарламаның тиімділігін арттыру (әр түрлі көлемді деректерде);
алынған нәтиже бойынша сәйкес алгоритмді және параллель бағдарламаның ең тиімдісін таңдау;
Сонымен, әрбір дербес компьютерлер үшін маңызы зор, ал параллель компьютерлерде, кезкелген есепті шешу процесіне қатысты ерекше мәнге ие келесі этаптарды айта кетсе болады:
есептің қойылуы;
оның шешу әдісін таңдау;
оның алгоритмін дайындау;
бағдарламалау технологиясын таңдау;
бағдарламаны құрастыру;
қандай да бір компьютерде бағдарламаны орындау.
Әрине, бұл этаптардың бәрі де қрапайым компьютерлер үшін де маңызды, бірақ параллель есептеу машиналарын пайдалануда олар ерекше мәнге ие болады. Кезкелген параллель компьютер – фантастикалық нәтижелерге қол жеткізуге мүмкіндік беретін өте мұқият дайындалған есептеу жүйесі. Мұндай компьютерлер өте үлкен өнімділікпен жұмыс істеу үшін арнайы жобаланады. Бірақ, параллель компьютерлер кезкелген бағдарламада бірдей өнімділікпен жұмыс істей алмайды. Егер бағдарлама құрылымы компьютер архитектурасының ерекшеліктеріне сәйкес келмесе, онда оның өнімділігі міндетті түрде төмендейді.
Бұл сәйкессіздік есепті шешудің кезкелген этапында пайда болуы мүмкін. Егер қандай да бір қадамда біз компьютердің ерекшелігін ескермеген болсақ, онда бағдарламадан үлкен өнімділікті күту бекер болмақ. Негізінде, векторлы-конвейерлік компьютерге немесе таратылған жадылы есептеу кластеріне бағытталуды көп жағдайда есепті шешу әдісі анықтайды. Бір жағдайда бағдарламада ішкі циклдарды векторлау қажет болса, ал келесі бір жағдайларда бағдарламаның жекелеген фрагменттерін параллельдеу жайын ойластыру керек. Бағдарламаның аталған қасиеттері ондағы есептеу әдістерінің қасиеттерімен анықталады. Егер таңдалған әдісте бұндай қасиеттер болмаса, онда олар бағдарламада да болмайды, яғни үлкен өнімділікке де қол жеткізу мүмкін емес деген сөз.
Қазіргі уақытта шектік өнімділігі рекордты көрсеткіштерімен компьютерлерді құрастыру оншалықты қиыншылықтар тудыра қоймайды. Алайда сол компьютерлерді тиімді пайдалану тәсілдерін ұсыну әлдеқайда күрделі екені белгілі, себебі мұнда жоғарыда аталған тізбектегі барлық алдыңғы этаптарын да ескеру керек болады.
Заман ағымына сәйкес параллель есептеу жүйелері өте үлкен қарқынмен даму үстінде.
Есептеу кластерлерінің пайда болуы, көп жерлерде параллель есептеулерге қол жеткізді. Егер ертеректе параллель компьютерлер үлкен арнайы центрлерде тұрса, ал қазір кластерлер шағын зертханаларда да орналасуы мүмкін. Дәстүрлі суперкомпьютерлерге қарағанда кластерлік шешімдердің бағасы да анағұрлым төмен. Оларды құрастыру үшін әдетте кәдімгі процессорлар, стандартты желілік технологиялар және еркін таратылымдағы бағдарламалық қамтама пайдаланылады. Әрине, бұл бірінші тілек, ал екіншісі – осы салаға қатысты минимум құрылғылар мен білім болса, онда жеке дербес параллель жүйе құрастыруға аса принципиалды кедергілер болмайды.
Интернет. Интернет – бір-бірімен байланыс каналдары және бірегей қабылдау, мәліметтерді беру стандарттары арқылы өзара байланысқан компьютерлер мен компьютерлік желілерінің жиынтығы. Ол деген жер шарын қамтып жатқан ауқымды бүкіләлемдік ақпарат жүйесі болып отыр. Енді осы бір желіге біріктірілген миллиондаған компьютерлерді бір ғана есепті шешу үшін пайдаланса қалай болар еді? Әрине, онда бүгінгі күні пайдаланудағы барлық суперкомпьютерлердің шектік өнімділіктерінің қосындысынан да өнімділігі көп жоғары болатын ең қуатты параллель компьютер алған болар едік.
Уақыт өте келе, кезкелген пайдаланушыға ауқымды бүкіләлемдік желіге шығуға мүмкіндік беретін Интернет әрбір квартираға да жететіні анық. Онда ауқымды бүкіләлемдік есептеу желісіне де қосылу мүмкіндігін аламыз. Егер сізге қандай да бір есептеу жүргізу керек болса, онда сіз желіге қосылып, онда тапсырма бере де және нәтижесін ала да аласыз және сіздің тапсырмаңыздың қайда, қалай өңделгені маңызды емес, сіз оны білмеуіңіз де мүмкін. Осыдан келіп бүкіл дүние жүзі бойынша сансыз көп есептеу ресурстарын қамтитын метакомпьютерлерді құрастыру идеялары туындайды.
Параллель есептеу жүйелерін құруда қызықты идеялар өте көп. Компьютерлер құрамына әртүрлі есептеу тораптары көптеп енгізілуде. Осындай құрылғылар жиынының үйлесімді жұмыс істеуін ұйымдастыру да өз алдына күрделі мәселелердің бірі. Ішкі үйлесімділікпен қатар кезкелген параллель компьютердің нақты есептерді шешу инструменті екенін де естен шығармаған жөн.
Сонымен, алдыңғы параграфтардан параллель есептеу жүйелерін ұйымдастыру тәсілдерінің әртүрлі және қаншалықты көп екенін көріп отырмыз. Бұл жерде векторлы-конвейерлік компьютерлер, массивті-параллель және матрицалық жүйелер, арнайы процессорлар, кластерлер, көпағынды архитектуралы компьютерлер және т.б. көптеген есептеу машиналарын айта кетеміз. Егер осы аталғандарды толық сипаттау үшін, жадыны ұйымдастыру, процессорлар арасындағы байланыс топологиясы, жекелеген құрылғылар жұмысының синхрондылығы немесе операцияларды орындау тәсілі сияқты маңызды параметрлер туралы мәліметтерді қосатын болсақ, онда түрлі архитектуралар саны шексіз көбейген болар еді.
Неге параллель архитектуралар саны өте көп? Олар бір-бірімен қалай байланысты? Әрбір архитектураны қандай негізгі факторлар сипаттайды? Бұл сұрақтардың жауабын есептеу жүйелері архитектурасын классификациялау [23] арқылы алуға болады. Бұл бағыттағы жұмыстар өткен ғасырдың 60-шы жылдарының соңында М. Флин ұсынған (қазіргі уақытта да пайдаланылуда) классификацияның бірінші нұсқасынан кейін басталды. Олардың барлығы дерлік М. Флин классификациясына толықтырулар және түзетулер енгізу, қандай да бір жүйеге келтіру бағытында алынды.
Қазіргі уақытта әртүрлі параметрлерге, белгілерге негізделген параллель есептеу машиналарының классификациялары көп [10]. Оларға М. Флин (1966 ж.), Р. Хокни, Т. Фенг (1972 ж.), Дж. Шор (1973), В. Хендлер, Л. Шнайдер (1988 ж.), Д. Скилликорн (1989 ж.), С. Дазгуп (1990 ж.) және т.б. классификацияларын жатқызуға болады.
Бұл кітапта біз М. Флин және Р. Хокни классификацияларына ғана тоқталамыз.
М. Флин (M. Flynn) классификациясы.
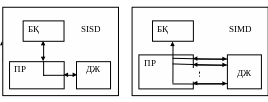
Флин классификациясы ағын түсінігіне негізделеді. Ағын - процессорда өңделетін командалар немесе деректер тізбегі. Командалар мен деректер ағымы санына байланысты Флин архитектураны 4 класқа бөледі. Біріншісі, SISD (Single Instruction stream/Single Date stream) – командалардың жеке ағыны және деректердің жеке ағыны (21 сурет). Бұл суретте келесі белгілеулер пайдаланылған: ПР – бір немесе бірнеше процессорлық элементтер, БҚ – басқарушы құрылғы, ДЖ – деректер жадысы. Бұл класқа классикалық тізбекті машиналар немесе басқаша айтқанда фон-Нейман типті машиналар жатады, мысалы, PDP-11 немесе VAX 11/780. Мұндай машиналарда командалардың бір ағыны ғана болады, барлық командалар кезекпен бірінен кейін бірі өңделеді (орындалады) және әрбір команда бір скалярлық операцияны көрсетеді. Бұл класқа командаларды өңдеу жылдамдығын және арифметикалық операцияларды орындау жылдамдығын жоғарылату үшін конвейерлік өңдеу қолданылуы мүмкін: мысалы, скалярлық функционалды құрылғыларымен CDC 6600 және конвейерлік CDC 7600 машиналары кіреді.
Екінші класс – SIMD (Single Instruction stream/Multiple Date stream) - командалардың жеке ағыны және деректердің көптеген ағыны (23 сурет). Алдыңғы, яғни SISD класынан айырмашылығы, мұндай архитектураларда векторлық командалар енетін командалардың бір ағыны сақталады. Ал бұл өз кезегінде бірден көптеген берілгендермен, мысалы, вектор элементтерімен, бір арифметикалық операцияны орындауға мүмкіндік береді. Векторлық операцияларды орындау тәсілі арнайы айтылмайды, сондықтан вектор элементтерін өңдеу процессорлық матрица арқылы, мысалы, ILLIAC IV – тегі сияқты немесе конвейер көмегімен, мысалы, Cray-1 машинасындағы сияқты жүргізілуі мүмкін.