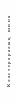18 Сурет. Процессорлардың байланыс топологияларының нұсқалары
а)решетка, б)тор в)толық байланыс г)гиперкуб
Алғашқы гиперкуб архитектуралы көппроцессорлы есептеу жүйелерінің бірі болып саналған COSMIC Cube компьютері 1983 жылы Калифорния технологиялық институтында Intel 8086/8087 микропроцессорлары негізінде құрастырылған. 1985 жылы Intel фирмасы алғашқы өндірістік гиперкуб жасап шығарды. Бұл тораптық процессорлар ретінде 80286/80287 сериялы микропроцессорларды пайдаланған iPSC (Intel Personal Supercomputer) компьютері еді. Нақ осы жылы 1024 торапқа дейін құрайтын, NCUBE Corporation фирмасының коммерциялық NCUBE/ten гиперкубы жарық көрді.
Жекелеген компьютерлерде гиперкуб басқа типті архитектуралар комбинациясында қолданылды. Thinking Machines фирмасының Connection Machine сериялы машиналарында 216 дейінгі қарапайым тораптар пайдаланылды. Осы компьютердің бір кристалында, бірімен бірі байланысқан 16 торап орналасқан, ал 212 осындай кристалдар 12-өлшемді гиперкубқа біріктірілген.
Енді ортақ және таратылған жадылы компьютерлердің ерекшеліктеріне қайта оралайық. Көріп отырғанымыздай, екі кластың да өз артықшылықтары бар, бірақ та олар біртіндеп оның кемшіліктеріне де айналуы мүмкін. Ортақ жадылы компьютерлер үшін параллель бағдарламалар құру қиындық тудырмайды, бірақ олардың максималды өнімділігі көбіне процессорлардың кішігірім санымен шектеледі. Ал таратылған жадылы компьютерлер үшін барлығы керісінше. Осы екі кластың артықшылықтарын біріктіруге бола ма? Мүмкін бағыттардың бірі – NUMA (Non Uniform Memory Access) архитектуралы компьютерлерді жобалау.
Неліктен ортақ жадылы компьютерлер үшін параллель бағдарламаларды жазу жеңіл? Себебі, бірыңғай адрестік кеңістік бар, қолданушыға мәлімет алмасу үшін процестер арасында хабар жіберуді ұйымдастырумен айналысып қажеті жоқ.
Егер қолданушылар бағдарламалары компьютердің барлық біріккен физикалық жадысына, ортақ адрестік жады деп қарайтын механизм құрылса онда барлығы көп жеңіл болар еді.
Өткен ғасырдың 70-ші жылдарының соңында бірінші NUMA –компьютерін құрастырған, Cm* жүйесін құрастырушылар осы жолмен жүрген. Бұл компьютер бір-бірімен кластер аралық шиналар арқылы байланысқан кластерлер жиынынан тұрады.
Әрбір кластер өзара локальді шиналар (19-сурет) арқылы байланысқан процессор, жады контроллері, жады модулі, кейбір енгізу/шығару құрылғыларын өзіне біріктіреді. Егер процессорға оқу немесе жазу операциясын орындау қажет болса, ол өзінің жады контроллеріне қажетті адреспен сұраныс жібереді. Контроллер адрестің үлкен разрядтарын талдау арқылы, қажетті мәліметтердің қай модульде сақтаулы екенін анықтайды. Егер адрес локальді болса, онда сұраныс локальді шинаға қойылады, кері жағдайда, қашықтағы кластер үшін арналған сұраныс кластер аралық шина арқылы жіберіледі. Бұл режимде жадының бір модулінде сақталатын бағдарлама жүйенің кез-келген процессорында орындалады. Жалғыз ғана айырмашылық – орындалу жылдамдығында. Барлық локальді сілтемелер қашықтағыларына қарағанда тез өңделеді. Сондықтан бағдарлама сақталған кластер процессоры оны басқа процессорларға қарағанда бірнеше есе жылдамырақ орындайды.
Осы ерекшелігіне қарай мұндай компьютерлер класы – жадыға біртекті емес қатынас компьютерлері деп аталады. Осы мағынада, классикалық SMP - компьютерлері UMA (Uniform Memory Access) архитектурасымен қамтылған, ондағы әрбір процессор кез келген жады модуліне бірдей қатынас жасауы қамтамасыз етілген деп айтылады.
Локальді
шина
Локальді
жады
Жады контроллері