

9. Описание процедур, необходимых для подсчета коэффициента ранговой корреляции Спирмена.
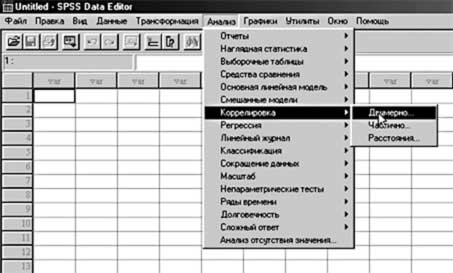
Рисунок 32.
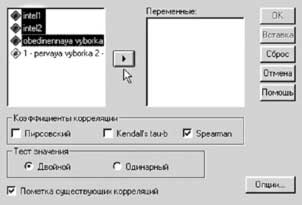
Рисунок 33.
Как показано на рисунке 32, после нажатия соответствующей последовательности кнопок и строк раскрывающихся списков ( «Анализ» - «Корреляция» - «Двумерно» ), на экране появится окно корреляции, представленное на рисунке 33. Как видно из рисунка, это окно является типовым для SPSS, и содержит следующие возможности:
- выбор путем установки флажков типов корреляции (нас интересует ранговая корреляция Спирмена);
- кнопка «Опции» откроет окно, позволяющее определять пропущенные значения 1) как пары кейсов, 2) как список кейсов; в случаях линейной корреляции будут доступны статистики: среднее и среднеквадратическое отклонение;
- выбор способа расчета («двухвостый» метод точнее);
- Флажок, предлагающий помечать ЗНАЧИМЫЕ (а не «существующие», как написано вследствие, опять-таки плохого перевода) корреляции. (Flag significant correlations). Это полезная опция, позволяющая в файле вывода относительно легко отличать значимые корреляции, которые на пятипроцентном уровне значимости помечаются одной звездочкой (*), а на однопроцентном уровне значимости - двумя звездочками (**).
Может произойти так, что при создании файла данных для последующей обработки методом ранговой корреляции, вы ошибетесь, и создадите много переменных с двумя значениями, вместо того, чтобы создать две переменных со многими значениями. Так бывает когда исследователь, скажем, сравнивает профиль испытуемого с групповым профилем, а по ошибке принимает за переменные, например, шкалы MMPI. В результате будет много переменных, у которых окажется всего лишь по два значения, относящихся к испытуемому и к средне-групповому показателю. Такая ошибка исправляется следующим образом: в верхней строке окна программы SPSS выбираем кнопку «Данные», затем строку «Перемещение» появившегося раскрывающегося списка. (В других версиях программы – «Транспозиция», «Transposition»). В появившемся типовом окне выбираем переменные, которые следует «развернуть под прямым углом», и нажимаем «OK». После этого то, что было переменными в прежнем файле, станет значениями в новом, вновь созданном программой, и наоборот. Этот файл можно отдельно сохранить, что не повлияет на состояние исходного файла. Естественно, что все сказанное применимо только к переменным, содержащим численные значения.
После того, как вы все-таки получили файл вывода результатов, окажется, что он представляет собой таблицу, в которой и по вертикали и по горизонтали представлены все переменные, которые были обработаны, то есть, шапки столбцов и строк представляют собой одинаковый перечень всех таких переменных. Машина выдает коэффициент корреляции для всех сочетаний переменных, включая корреляцию переменной с самой собой. Это наглядно видно по коэффициентам корреляции, равным единице, расположенным по диагонали, соединяющей левый верхний и правый нижний угол таблицы. Отсюда следует, что при анализе результатов можно смело изучать лишь половину таблицы, отделенную этой диагональю – вторая будет ее точной копией.
Каждая ячейка файла вывода содержит сведения:
- коэффициент корреляции;
- уровень значимости;
- объем выборки.