

БД
Распределенные бд. Понятие о трехуровневой архитектуре бд.
В настоящее время очень много различных локальных сетей, всё больше информации передается между компьютерами и остро встает задача согласованности данных, хранящихся и обрабатывающихся в разных местах, но логически связанных друг с другом. И вот встают задачи, связанные с параллельной обработкой транзакций, т.е. последовательности операций над БД, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние. То есть нам нужна СУБД, с которой в один момент времени могут работать (изменять, удалять, добавлять данные) сразу несколько пользователей. И такая СУБД и называется распределенной. Она основана на технологии клиент-сервер. То есть физически БД хранится на сервере, а пользователи на клиентских местах обращаются к ней через сеть посредством специального клиентского компьютерного обеспечения.
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказались предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) Трехуровневая система организации БД, изображена на рисунке:
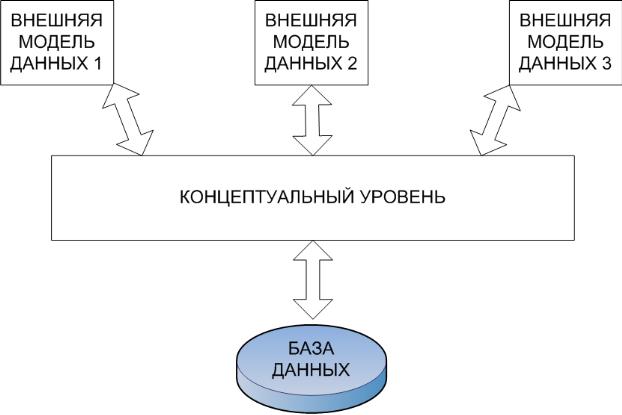
Уровень внешних моделей – самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведении об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведении используются в подсистеме отдела кадров.
Концептуальный уровень – центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной БД. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась БД. Как любая модель, концептуальная модель отражает только существенные, с точки зрении обработки, особенности реального мира.
Физический уровень – собственно данные, расположенные в файлах или страничных структурах, расположенных на внешних носителях информации.
Эта структура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же БД. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной БД.
Выделение концептуального уровня позволило разработать аппарат централизованного управления БД.
Доп. Вопрос. Какие программы мы изучали. Rational Rose, Microsoft SQL server, Data Modeler
2.Агрегатные функции. Предложения group by, having.
В запросе может выполняться обобщение как отдельных значений, так и групп значений. Это делается с помощью агрегатных функций, которые выводит единственное значение для целой группы столбцов. К агрегатным функциям относятся:
COUNT – определяет количество строк, выбранных запросом
SUM – вычисляет арифметическую сумму всех выбранных значений данного столбца
AVG – среднее значение
MAX – наибольшее значение
MIN – наименьшее значение
Для SUM и AVG – только числовые столбцы. Для COUNT, MIN и MAX допустимы любые типы данных.
Например:
1. SELECT SUM (amt)
FROM Orders; - считает сумму всех заказов
2. SELECT COUNT(*)
FROM Customers; - считает количество строк в таблице
Предложение GROUP BY позволяет выделить из отдельного столбца подмножество значений и применить к нему агрегатную функцию. Предположим, нужно найти самый крупный заказ, полученный каждым продавцом. GROUP BY позволяет сгруппировать запросы по значению snum, а затем вычислить MAX дл каждой группы:
SELECT snum, MAX (amt)
FROM Orders
GROUP BY snum;
Для фильтрации таких групп используется предложение HAVING. В нём задаются критерии, по которым из результата исключаются определенные группы.
Предположим, что в предыдущем примере нужно вывести сведения только о тех покупках, стоимость которых составляет больше 3000.
SELECT snum, MAX (amt)
FROM Orders
GROUP BY snum
HAVING MAX (amt) > 3000;
Доп. Вопрос. Какие функции работают только с числовыми данными а какие и с символьными
Для SUM и AVG – только числовые столбцы. Для COUNT, MIN и MAX допустимы любые типы данных.
Символ А это минимум. Символ Я максимум.