

If a (умова a) then do в
оператор В буде виконаний, якщо умова А справедлива у всіх ПЕ. Для коректного включення/відключення процесорних елементів КМП повинен знати результат перевірки умови А у всіх ПЕ. Така інформація передається в КМП по однонаправленій шині результату. У системі СМ-2 ця шина названа GLOBAL. У системі МРР для тієї ж мети організована структура, звана деревом SUM-OR. Кожен ПЕ розміщує вміст свого однорозрядного регістра ознаки на вході дерева, яке за допомогою операції логічного складання комбінує цю інформацію і формує слово результату, використовуване в КМП для ухвалення рішення.
13.3 Архітектура матричних комп’ютерних систем
У матричних SIMD-системах поширення набули два основні типи архітектурної організації масиву процесорних елементів.
У першому варіанті (рис.13.5), відомому як архітектура типу “процесорний елемент - процесорний елемент” (“ПЕ-ПЕ”):
- N процесорних елементів (ПЕ) зв’язані між собою мережею з’єднань;
- кожен ПЕ - це процесор з локальною пам’яттю;
- процесорні елементи виконують команди, що надходять з КМП по шині широкомовної розсилки, і обробляють дані що зберігаються в їх локальній пам’яті або поступають з КМП;
- обмін даними між процесорними елементами проводиться по мережі з’єднань, тоді як шина введення/виведення служить для обміну інформацією між ПЕ і пристроями введення/виведення;
- для трансляції результатів з окремих ПЕ в контроллер масиву процесорів служить шина результату;
- завдяки використанню локальної пам’яті апаратні засоби КС даного типу можуть бути побудовані дуже ефективно. У багатьох алгоритмах дії по пересилці інформації здебільшого локальні, тобто відбуваються між найближчими сусідами. З цієї причини архітектура, де кожен ПЕ пов’язаний тільки з сусідніми, дуже популярна. Як приклади обчислювальних систем з даною архітектурою можна згадати MasPar MP-1, Connection Machine CM-2, GF11, DAP, МРР, STARAN, PEPE, ILLIAC IV.
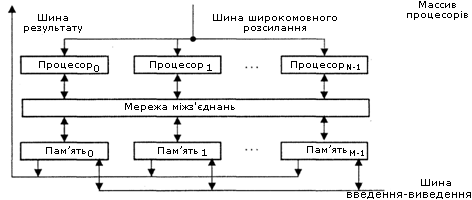
Рисунок 13.5 – Архітектура типу “процесорний елемент - процесорний елемент”
Другий вид архітектури – “процесор-пам’ять” (рис.13.6). В такій конфігурації двонаправлена мережа з’єднань зв’язує N процесорів з М модулями пам’яті. Процесори управляються КМП через широкомовну шину. Обмін даними між процесорами здійснюється як через мережу, так і через модулі пам’яті. Пересилка даних між модулями пам’яті і пристроями введення/виведення забезпечується шиною введення/ виведення. Для передачі даних з конкретного модуля пам’яті в КМП служить шина результату. Прикладами КС з розглянутою архітектурою можуть служити Burroughs Scientific Processor (BSP), Texas Reconfigurable Array Computer (TRAC).
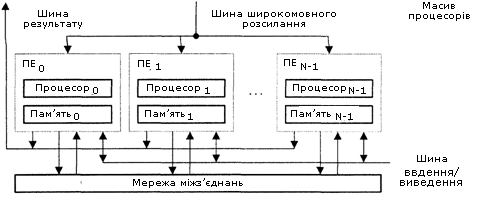
Рисунок 13.6 – Архітектура типу “процесор-пам’ять”
13.4 Структура процесорного елементу в матричній кс
У більшості матричних SIMD-систем як процесорні елементи застосовуються прості RISC-процесори з локальною пам’яттю обмеженої місткості.
Наприклад, кожен ПЕ системи MasPar MP-1 складається з чотирьохрозрядного процесора з пам’яттю місткістю 64 Кбайт. У системі МРР використовуються однорозрядні процесори з пам’яттю 1 кбіт кожен, а в СМ-2 процесорний елемент є однорозрядний процесор з 64 Кбіт локальної пам’яті. Завдяки простоті ПЕ масив може бути реалізований у вигляді однієї надвеликої інтегральної мікросхеми (НВІС). Це дозволяє скоротити число зв’язків між мікросхемами і, отже, габарити КС. Так, одна НВІС в системі СМ-2 містить 16 процесорів (без блоків пам’яті), а в системі MasPar MP-1 НВІС складається з 32 процесорів (також без блоків пам’яті). У системі МР-2 є видимим тенденція до застосування складніших мікросхем, зокрема 32-розрядних процесорів з 256 Кбайт пам’яті в кожному.
Невід’ємними компонентами ПЕ (рис.13.7) в більшості обчислювальних систем є:
- арифметико-логічний пристрій (АЛП);
- регістри даних;
- мережевий інтерфейс (МІ), який може включати в свій склад регістри пересилки даних;
- номер процесора;
- регістр прапора дозволу маскування (F);
- локальна пам’ять.
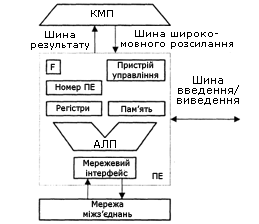
Рисунок 13.7 – Структура матричного процесорного елемента
Процесорні елементи, керовані командами, що поступають по широкомовній шині з КМП, можуть вибирати дані з своєї локальної пам’яті і регістрів, обробляти їх в АЛП і зберігати результати в регістрах і локальній пам’яті. ПЕ можуть також обробляти ті дані, які поступають по шині широкомовної розсилки з КМП. Крім того, кожен процесорний елемент має право отримувати дані з інших ПЕ і відправляти їх в інші ПЕ по мережі з’єднань, використовуючи для цього свій мережевий інтерфейс. У деяких матричних системах, зокрема в MasParМР-1, елемент даних з ПЕ-джерела можна передавати в ПЕ-приймач безпосередньо, тоді як в інших, наприклад в МРР, - дані заздалегідь повинні бути розміщені в спеціальний регістр пересилки даних, що входить до складу мережевого інтерфейсу. Пересилка даних між ПЕ і пристроями введення/виведення здійснюється через шину введення/виведення КС. У ряді систем (MasParMP-1) ПЕ підключені до шини введення/виведення за допомогою мережі з’єднань і каналу введення/виведення системи. Результати обчислень будь-який ПЕ видає в КМП через шину результату.
Кожному з N ПЕ в масиві процесорів привласнюється унікальний номер, званий також адресою ПЕ, яка є цілим числом від 0 до N- 1. Щоб вказати, чи повинен даний ПЕ брати участь в загальній операції, в його складі є регістр прапора дозволу F. Стан цього регістра визначають сигнали управління з КМП, або результати операцій в самому ПЕ, або і ті та інші спільно.
Ще однією істотною характеристикою матричної системи є спосіб синхронізації роботи ПЕ. Оскільки всі ПЕ отримують і виконують команди одночасно, їх робота жорстко синхронізується. Це особливо важливо в операціях пересилки інформації між ПЕ. У системах, де обмін проводиться з чотирма сусідніми ПЕ, передача інформації здійснюється в режимі “регістр- регістр”.