

Контрольні запитання
1 Які комп’ютерні системи називають систоличними?
2 Які комп’ютерні системи називають комп’ютерними системами з наддовгими командами?
3 Які комп’ютерні системи називають комп’ютерними системами з явним паралелізмом команд?
4 Які комп’ютерні системи називають комп’ютерними системами з обробкою за принципом хвильового фронту?
5 Які комп’ютерні системи називають комп’ютерними системами на базі трансп’ютерів?
Лекція № 17 структури комп’ютерних систем з фіксованою системою зв’язків
17.1 Системи з фіксованою структурою з серійних мікропроцесорів
MPP-системи з серійних мікропроцесорів роблять можливим збереження традиційного стилю програмування. Принциповим обмеженням продуктивності цих обчислювальних систем служить сам характер функціонування процесора. Фази “вибірка команди”, “дешифрування команди”, “вибірка операндів” представляють собою “накладні витрати” на власне необхідну користувачу дію – “виконання команди”. Продуктивність втрачається прямо, якщо фази виконання команди реалізуються послідовно з мінімальними витратами устаткування, або опосередковано шляхом збільшення витрат апаратури на суміщення фаз різних команд, як у сучасних мікропроцесорах. Однак при цьому зростає об’єм обладнання мікропроцесора, а, отже, зменшується сумарна кількість процесорів однокристальної обчислювальної системи, викликаючи відповідне зменшення продуктивності. У однокристальних векторно-конвеєрних процесорах вплив розглянутого фактора обмеження продуктивності знижується, але не виключається повністю.
17.2 Спеціалізовані системи з фіксованою структурою
Важливість вирішення деяких актуальних завдань виправдовує побудову спеціалізованих обчислювальних систем. В якості яскравого представника цього класу систем можна вказати систему GRAPE - 6, призначену для вирішення завдання взаємодії N тіл. Існуюча конфігурація GRAPE - 6 включає 2048 спеціалізованих конвеєрних мікропроцесорів, кожний з яких має 6 конвеєрів, що використовуються для обчислення гравітаційної взаємодії між частинками. GRAPE - 6 являє собою кластер, утворений з 16 вузлів, об’єднаних комутатором Gigabit Ethernet. Кожен вузол складається з ПК на базі мікропроцесора AMD Athlon XP-1800+, функціонуючого під управлінням ОС Linux, і 4 спеціалізованих плат, об’єднаних між собою і платами сусідніх вузлів спеціальними каналами. На кожній платі встановлюється 32 спеціалізованих кристала GRAPE-6.
Теоретична пікова продуктивність GRAPE - 6 - 63,4 трлн.оп ./ с. На реальній задачі з моделювання формування зовнішніх планет сонячної системи досягнута продуктивність 29500000000000 оп. / с. Для порівняння, кластер Green Destiny, який при вирішенні на 220 універсальних мікропроцесорах завдання N тіл, що моделює формування Галактики з використанням 200 млн. часток, показує продуктивність 38,9 млрд. оп. / с.
Контрольні запитання
Лекція № 18
СТРУКТУРИ КОМП’ЮТЕРНИХ СИСТЕМ
З РЕКОНФІГУРОВАНОЮ СИСТЕМОЮ ЗВ’ЯЗКІВ
Високопродуктивні РКС доцільно будувати за принципом модульного нарощування з однотипних базових модулів. Базові модулі, з одного боку вносять конструктивні обмеження, а з іншого боку повинні зберігати в повній мірі всі концептуальні особливості архітектури реконфігурованих систем. Для проблемно- орієнтованих РКС визначальним може стати вимога обов’язкової реалізації в межах базового модуля базових підграфів даної проблемної області. При цьому базовий модуль може бути конструктивно реалізований на одній або кількох друкованих платах.
Відповідно до розробленої концепції, базовий модуль на основі ПЛІС несе в собі всі характерні ознаки завершеної реконфігурованої системи. Типова компоновка базового модуля на основі ПЛІС показана на рис.18.1.
Основні обчислювальні можливості базового модуля зосереджені в обчислювальному полі, яке містить деяку множину ПЛІС великої ступені інтеграції. В обчислювальному полі створюються конвеєрно-паралельні обчислювальні структури і контролери розподіленої пам’яті для управління блоками розподіленої пам’яті, які необхідні для вирішення поставлених завдань. При цьому самі блоки розподіленої пам’яті виконуються не на ресурсах обчислювального поля, а на типових мікросхемах статичних або динамічних ОЗУ необхідного обсягу і швидкодії. Контролер базового модуля (КБМ) виконує функції управління і контролю всіх систем базового модуля. На базовому модулі розташовуються також і допоміжні підсистеми: синхронізації, електроживлення та охолодження.
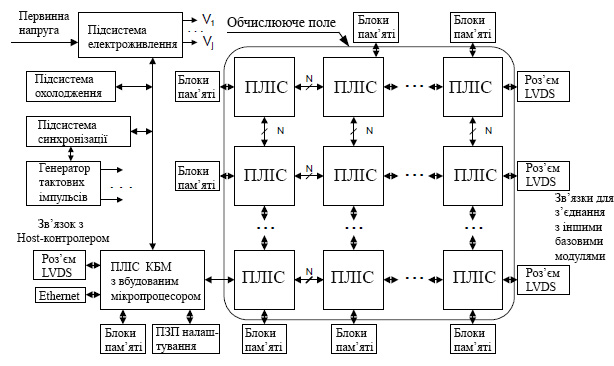
Рисунок 18.1 – Структура базового модуля реконфігурованої системи на основі ПЛІС
Центральне місце в організації обчислювального процесу відводиться контролерам розподіленої пам’яті (КРП). КРП працюють з фрагментами паралельної програми, які завантажені в їх блоки пам’яті. Виконуючи паралельну програму, КРП беруть участь в налаштуванні елементарних процесорів на виконання необхідних операцій і в створенні необхідних каналів зв’язку між ними, тим самим реалізуючи в межах базового модуля мультиконвеєрну обчислювальну структуру, яка відповідає базовому підграфу завдання.
Одна частина контролерів розподіленої пам’яті, виконуючи фрагменти паралельної програми, організовує і синхронізує потоки даних, що подаються в обчислювальні структури. Інша частина контролерів виконує функції прийому результатів обчислень.
Для створення ефективних обчислювальних структур в межах базового модуля необхідно оптимальне співвідношення кількості ПЛІС, кількості блоків розподіленої пам’яті і їх обсягу. Для різних завдань, що вирішуються на РКС, це співвідношення відрізняється. У той же час для структурної реалізації обчислень не вимагається запам’ятовування множини проміжних даних, так як вони передаються для подальшої обробки в наступні ступені конвеєрного обчислювача без проміжного запам’ятовування. Це знижує вимоги до загального обсягу пам’яті в базовому модулі. Для структурної реалізації обчислень більш критичною є кількість блоків розподіленої пам’яті, а не обсяг кожного блоку або загальний обсяг пам’яті. Крім розподіленої пам’яті, реалізованої на типових мікросхемах ОЗП, при створенні обчислювальних структур широко використовується внутрішньокристальна пам’ять ПЛІС.
Принцип модульного нарощування дозволяє збільшити продуктивність РКС при збільшенні кількості базових модулів. При цьому забезпечується можливість організації ресурсонезалежного і відмовостійкого програмування. Завдання може бути вирішене на будь-якій конфігурації обчислювальної структури. Вихід з ладу одного або декількох базових модулів не спричиняє припинення рішення задачі і необхідність її повної перетрансляціі, а лише трохи сповільнює процес вирішення.