

16.4 Комп’ютерні системи з явним паралелізмом команд
Подальшим розвитком ідеї VLIW стала нова архітектура IA-64 - сумісна розробка фірм Intel і Hewlett-Packard (IA - це абревіатура від Intel Architecture). У IA-64 реалізований новий підхід, відомий як обчислення з явним паралелізмом команд (EPIC, Explicitly Parallel Instruction Computing), що є вдосконаленим варіантом технології VLIW. Першим представником даної стратегії став мікропроцесор Itanium компанії Intel. Корпорація Hewlett-Packard також реалізує даний підхід в своїх розробках.
В архітектурі IA-64 передбачається наявність в процесорі 128 64-розрядних регістрів загального призначення (PЗH) і 128 80-розрядних регістрів з плаваючою комою. Крім того, процесор IA-64 містить 64 однобітових регістра предикатів.
Формат команд в архітектурі IA-64 показаний на рис.16.6.
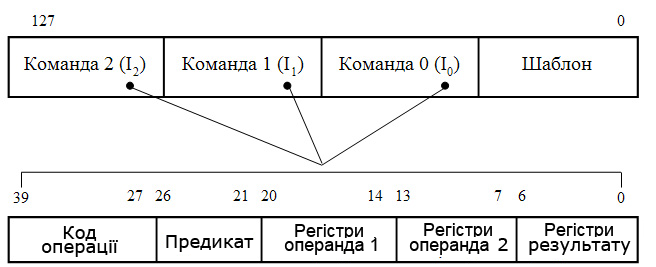
Рисунок 16.6 – Формат наддовгої команди в архітектурі IA-64
Команди упаковуються (групуються) компілятором в наддовгу команду - зв’язку (bundle) завдовжки в 128 розрядів. Зв’язка містить три команди і шаблон, в якому указуються залежності між командами (чи можна з командою I0 запустити паралельно I1, або ж I1 повинна виконуватися тільки після I0), а також між іншими зв’язками (чи можна з командою I2 із зв’язки S0 запустити паралельно команду I3 із зв’язки S1).
Перерахуємо всі варіанти складання зв’язки з трьох команд:
- I0 ║ I1 ║ I2 - команди виконуються паралельно;
- I0 & I1 ║ I2 - спочатку I0, потім виконуються паралельно I1 і I2;
- I0 ║ I1 & I2 - паралельно обробляються I0 і I1, після них - I2;
- I0 & I1 & I2 - команди виконуються в послідовності I0, I1, I2 .
Одна зв’язка, що складається з трьох команд, відповідає набору з трьох функціональних блоків процесора. Процесори IA-64 можуть містити різну кількість таких блоків, залишаючись при цьому сумісними за кодом. Завдяки тому, що в шаблоні вказана залежність і між зв’язками, процесору з N однаковими блоками з трьох ФБ відповідатиме наддовга команда з N х 3 команд (N зв’язок). Тим самим забезпечується масштабованість IA-64.
Поле кожної з трьох команд в зв’язці складається з п’яти полів:
- 13-розрядного поля коду операції;
- 6-розрядного поля предикатів, що зберігає номер одного з 64 регістрів предиката;
- 7-розрядного поля першого операнда (першого джерела), де указується номер регістра загального призначення або регістра з плаваючою комою, в якому міститься перший операнд;
- 7-розрядного поля другого операнда (другого джерела), де указується номер регістра загального призначення або регістра з плаваючою комою, в якому міститься другий операнд;
- 7-розрядного поля результату (приймача), де указується номер регістра загального призначення або регістра з плаваючою комою, куди повинен бути занесений результат виконання команди.
Предикація - це спосіб обробки умовних розгалужень. Якщо в початковій програмі зустрічається умовне розгалуження (за статистикою через кожні 6 команд), то команди з різних гілок позначаються різними регістрами предиката (команди мають для цього відповідні поля), далі вони виконуються спільно, але їх результати не записуються, поки значення регістрів предиката (РП) не визначені. Коли обчислюється умова розгалуження, РП, якій відповідає “правильній” гілці, встановлюється в 1, а інший - в 0. Перед записом результатів процесор перевіряє поле предиката і записує результати тільки тих команд, поле предиката яких указує на РП з одиничним значенням.
Предикати формуються як результат порівняння значень, що зберігаються в двох регістрах. Результат порівняння (“Істина” або “Брехня”) заноситься в один з РП, але одночасно з цим в другій РП записується інверсне значення отриманого результату. Такий механізм дозволяє процесору ефективніше виконувати конструкції типа IF-THEN-ELSE.
Логіка видачі команд на виконання складніша, ніж в традиційних процесорах типу VLIW, але набагато простіша, ніж у суперскалярних процесорів з неврегульованою видачею. Особливостями архітектури EPIC є:
- велика кількість регістрів;
- масштабованість архітектури до великої кількості функціональних блоків, тобто система команд, що спадково масштабується (Inherently Scaleable Instruction Set);
- явний паралелізм в машинному коді. Пошук залежностей між командами здійснює не процесор, а компілятор;
- предикація - команди з різних гілок умовної пропозиції забезпечуються полями предикатів (полями умов) і запускаються паралельно;
- попереднє завантаження - дані з повільної основної пам’яті завантажуються наперед.