

Мультикомп’ютерна кс
Рівні комплексування у мультикомп’ютерних КС
Для побудови обчислювальних систем необхідно, щоб елементи або модулі, комплексуємі в систему, були сумісні.
Поняття сумісності має три аспекти: апаратний або технічний, програмний і інформаційний.
Технічна (Hardware) сумісність припускає, що ще в процесі розробки апаратури забезпечуються наступні умови:
- апаратура, що підключається одна до одної, повинна мати єдині стандартні, уніфіковані засоби з’єднання: кабелі, число проводів в них, єдине призначення проводів, роз’єми, адаптери, плати і т.д.;
- параметри електричних сигналів, якими обмінюються технічні пристрої, теж повинні відповідати один одному: амплітуди імпульсів, полярність, тривалість і т.д.;
- алгоритми взаємодії (послідовності сигналів по окремих проводах) не повинні вступати в суперечність один з одним.
Останній пункт тісно пов’язаний з програмною сумісністю. Програмна сумісність (Software) вимагає, щоб програми, що передаються з одного технічного засобу в інший (між ЕОМ, процесорами, між процесорами і зовнішніми пристроями), правильно розумілись і виконувались іншим пристроєм.
Якщо пристрої, що обмінюються, ідентичні друг, другу, то проблем зазвичай не виникає. Якщо взаємодіючі пристрої відносяться до одного і того ж сімейства ЕОМ, але з’єднуються різні моделі (наприклад, ПК на базі i286 і Pentium), то в таких моделях сумісність забезпечується “від низу до верху”, тобто раніше створені програми можуть виконуватися на пізніших моделях, але не навпаки. Якщо з’єднувана апаратура має абсолютно різну систему команд, то слід обмінюватися початковими модулями програм з подальшою їх трансляцією.
Інформаційна сумісність комплексуємих засобів припускає, що передані інформаційні масиви однаково інтерпретуватимуться з’єднуваними модулями КС. Повинні бути стандартизовані алфавіти, розрядність, формати, структура і розмітка файлів, томів і т.д.
На рис.15.10 передбачені наступні рівні мультиплексування:
- прямого управління (процесор - процесор);
- загальної оперативнї пам’яті;
- комплексуємі канали введення/виведення;
- пристроїв управління зовнішніми пристроями (УВУ);
- загальних зовнішніх пристроїв.
На кожному з цих рівнів використовуються спеціальні технічні і програмні засоби, що забезпечують обмін інформацією.
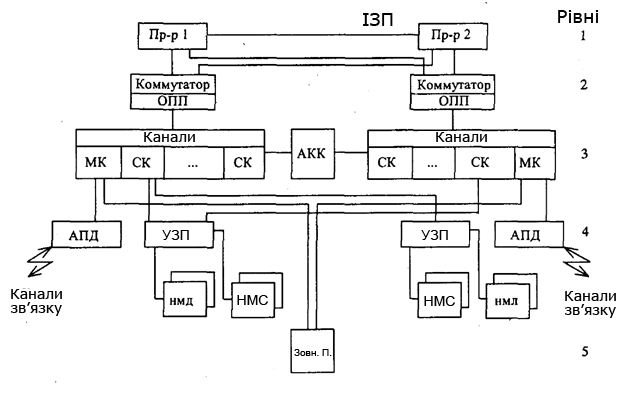
Рисунок 15.10 – Рівні і засоби комплексування
15.4 Кластерні кс
Кластер є системою з декількох комп’ютерів (що в більшості випадків серійно випускаються), що мають загальний ресурс, який розділяється, для зберігання спільно оброблюваних даних (зазвичай набір дисків або дискових масивів) і об’єднаних високошвидкісною магістраллю (рис.15.11).

Рисунок 15.11 – Кластерна КС
Як правило, в кластерних системах не забезпечується єдина ОС для роботи загального набору додатків на всіх вузлах кластера. Тобто кожен комп’ютер - це автономна система з окремим екземпляром ОС і своїми, що належать тільки їй системними ресурсами. Додаток, запущений на ньому, може бачити тільки загальні диски або окремі ділянки пам’яті. На вузлах кластера працюють спеціально написані додатки, які паралельно обробляють загальні набори даних. Таким чином, кластерне ПЗ – це лише засіб для взаємодії вузлів і синхронізації доступу до загальних даних. Кластер як паралельна система формується на прикладному рівні, а не на рівні ОС (рис.15.12).
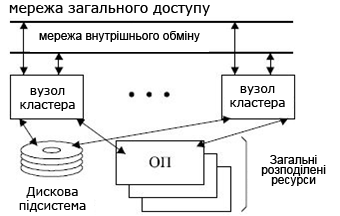
Рисунок 15.12 – Структура кластера
В даний час такі системи мають дві основні області застосування: паралельні сервери баз даних і високонадійні обчислювальні комплекси. Ринок паралельних СУБД і є основний ринок кластерів додатків. Високонадійні комплекси є групою вузлів, на яких незалежно один від одного виконуються деякі важливі додатки, що вимагають постійної, безперервної роботи. Тобто в такій системі на апаратному рівні фактично підтримується основний механізм підвищення надійності - резервування. Вузли знаходяться в так званому "гарячому" резерві, і кожний з них у будь-який момент готовий продовжити обчислення при виході з ладу якого-небудь вузла. При цьому всі додатки з вузла, що відмовив, автоматично переносяться на інші машини комплексу. Така система також формально є кластером, хоча в ній відсутня паралельна обробка загальних даних. Ці дані зазвичай монопольно використовуються виконуваними в рамках кластера додатками і повинні бути доступні для всіх вузлів.
Кластерні системи володіють наступними перевагами:
- абсолютна масштабованість;
- нарощування в процесі експлуатації;
- висока надійність;
- зниження співвідношення ціна/продуктивність.
Широко поширеним засобом для організації міжсерверної взаємодії є бібліотека MPI що підтримує мови C і Fortran. Вона використовується наприклад, в програмі моделювання погоди MM5.
Solaris надає програмне забезпечення Solaris Cluster, яке служить для забезпечення високої доступності і безвідмовності серверів. Для OpenSolaris існує реалізація під назвою OpenSolaris HA Cluster.
У GNU/Linux популярні декілька програм:
- G distcc, MPICH і ін. - спеціалізовані засоби для розпаралелювання роботи програм;
- G Linux Virtual Server, LINUX-HA - вузлове ПО для розподілів запитів між обчислювальними серверами;
- H MOSIX, openMosix, Kerrighed, OPENSSI - повнофункціональні кластерні середовища, вбудовані в ядро автоматично розподіляють завдання між однорідними вузлами. OPENSSI, openMosix і Kerrighed створюють середовище єдиної операційної системи між вузлами.
Компанією Microsoft випускається HA-кластер для операційної системи Windows. Windows Compute Cluster Server 2003 (CCS), випущений в червні 2006 року розроблений для високотехнологічних додатків, які вимагають кластерних обчислень. Програмний продукт розроблений для розгортання на множині комп’ютерів, які з’єднуються в кластер для досягнення потужностей суперкомп’ютера. Кожен кластер на Windows Compute Cluster Server складається з одної або декількох управляючих машин, що розподіляють завдання і декілька підлеглих машин, що виконують основну роботу. У листопаді 2008 був представлений Windows HPC Server 2008, покликаний замінити Windows Compute Cluster Server 2003.
Робота будь-якої багатомашинної системи визначається двома головними компонентами: високошвидкісним механізмом зв’язку процесорів і системним програмним забезпеченням яке надає користувачам і додаткам прозорий доступ до ресурсів всіх комп’ютерів, що входять в комплекс. До складу засобів зв’язку входять програмні модулі які займаються розподілом обчислювального навантаження, синхронізацією обчислень і конфігурацією системи. Якщо відбувається відмова одного з комп’ютерів комплексу, його завдання можуть бути автоматично перепризначені і виконані на іншому комп’ютері. Якщо в склад мультикомп’ютерної системи входять декілька контроллерів зовнішніх пристроїв, то у разі відмови одного з них, інші контроллери автоматично беруть на себе його роботу. Таким чином, досягається висока відмовостійкість комплексу в цілому.
Крім підвищення відмовостійкості, багатомашинні системи дозволяють досягти високої продуктивності рахунок організації паралельних обчислень. В порівнянні з мультипроцесорними системами можливості паралельної обробки в мультикомп’ютерних системах обмежені: ефективність розпаралелювання різко знижується, якщо паралельно виконувані завдання тісно зв’язані між собою по даним. Це пояснюється тим, що зв’язок між комп’ютерами мультикомп’ютерної системи менш тісний, чим між процесорами в мультипроцесорній системі, оскільки основний обмін даними здійснюється через загальні периферійні пристрої. Говорять, що на відміну від мультипроцесорів, де використовуються сильні програмні і апаратні зв’язки, в мультикомп’ютерних системах апаратні і програмні зв’язки між оброблювальними пристроями є слабкішими.
Топологія кластерних пар
При створенні кластерів з великою кількістю вузлів можуть застосовуватися найрізноманітніші топології (лінійні, кільця, деревовидні, зіркоподібні і ін.). Розглянемо топології, характерні для найбільш поширених “малих” кластерів, що складаються з 2-4 вузлів.
Топологія кластерних пар знаходить застосування при організації дво- або чотиривузлових кластерів.
Вузли групуються попарно (рис.15.13). Дискові масиви приєднуються до обох вузлів пари, причому кожен вузол має доступ до всіх дискових масивів своєї пари. Один з вузлів є резервним для іншого.
Чотиривузлова кластерна “пара” є простим розширенням двовузлової топології. Обидві кластерні пари з погляду адміністрування і настройки розглядаються як єдине ціле.
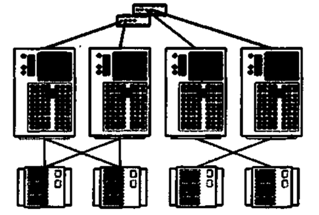
Рисунок 15.13 – Топологія “чотиривузлова кластерна пара”
Топологія з рис.15.13 підходить для організації кластерів з високою готовністю даних, але відмовостійкість реалізується тільки в межах пари, оскільки її пристрої зберігання інформації не мають фізичного з’єднання з іншою парою.
Приклад: організація паралельної роботи СУБД Informix XPS.
Топологія “N+1” дозволяє створювати кластери з 2,3 і 4 вузлів (рис.15.14).
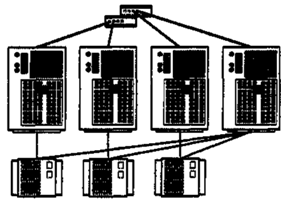
Рисунок 15.14 – Топологія “N+1”
Кожен дисковий масив підключаються тільки до двох вузлів кластера. Дискові масиви організовані по схемі RAID 1. Один сервер має з’єднання зі всіма дисковими масивами і служить як резервний для решти (основних або активних) всіх вузлів. Резервний сервер може використовуватися для підтримки високого ступеня готовності в парі з будь-яким з активних вузлів.
Топологія рекомендується для організації кластерів високої готовності. У тих конфігураціях, де є можливість виділити один вузол для резервування, ця топологія сприяє зменшенню навантаження на активні вузли і гарантує, що навантаження вузла, що вийшов з ладу, буде відтворено на резервному вузлі без втрати продуктивності. Відмовостійкість забезпечується між будь-яким з основних вузлів і резервним вузлом
Аналогічно топології “N+1”, топологія “NxN” (рис.15.15) розрахована на створення кластерів з 2, 3 і 4 вузлів, але на відміну від першої володіє більшою гнучкістю і масштабованістю.
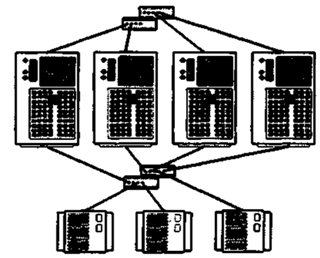
Рисунок 15.15 – Топологія “N+N”
Тільки у цій топології всі вузли кластера мають доступ до всіх дискових масивів, які, у свою чергу, будуються за схемою RAID 1 (з дублюванням). Масштабованість проявляється в простоті додавання до кластера додаткових вузлів і дискових масивів без зміни з’єднань в існуючій системі.
Топологія дозволяє організувати каскадну систему відмовостійкості, при якій обробка переноситься з несправного вузла на резервний, а у разі його виходу з ладу - на наступний резервний вузол і т.д. Кластери з топологією “NxN” забезпечують підтримку додатку Oracle Parallel Server, що вимагає з’єднання всіх вузлів зі всіма системами зберігання інформації. В цілому топологія характеризується кращою відмовостійкістю і гнучкістю в порівнянні з іншими рішеннями.
У топології з повністю роздільним доступом кожен дисковий масив з’єднується тільки з одним вузлом кластера (рис.15.16).
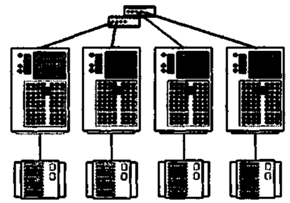
Рисунок 15.16 – Топологія з повністю роздільним доступом
Топологія рекомендується тільки для тих додатків, для яких характерна архітектура повністю роздільного доступу, наприклад для вже згадуваної СУБД Informix XPS.
Кластер Beowulf
Першим в світі кластером, є кластер, створений під керівництвом Томаса Стерлінга і Дона Бекера в науково-космічному центрі NASA, - Goddard Space Flight Center - літом 1994 року. Кластер названий на честь героя скандинавської саги, що володів, за переказами, силою тридцяти чоловік. Кластер складався з 16 комп’ютерів на базі процесорів 486DX4 з тактовою частотою 100 MHz. Кожен вузол мав 16 Mb оперативної пам’яті. Зв’язок вузлів забезпечувався трьома мережевими адаптерами, що паралельно працювали на швидкості 10 Mbit/s. Кластер функціонував під управлінням операційної системи Linux, використовував GNU-компілятор і підтримував паралельні програми на основі MPI. Процесори вузлів кластера були дуже швидкими в порівнянні з пропускною спроможністю звичайної мережі Ethernet, тому для балансування системи Дон Бекер переписав драйвери Ethernet під Linux для створення дубльованих каналів і розподілу мережевого трафіку.
В даний час під кластером типа Beowulf розуміється система, яка складається з одного серверного вузла і одного або більше клієнтських вузлів, сполучених за допомогою Ethernet або деякої іншої мережі. Це система, побудована з готових промислових компонентів, що серійно випускаються, на яких може працювати ОС Linux, стандартних адаптерів Ethernet і комутаторів. Вона не містить специфічних апаратних компонентів і легко відтворна. Серверний вузол управляє всім кластером і є файл-сервером для клієнтських вузлів. Він також є консоллю кластера і шлюзом в зовнішню мережу. Великі системи Beowulf можуть мати більш за один серверний вузол, а також, можливо, спеціалізовані вузли, наприклад консолі або станції моніторингу. В більшості випадків клієнтські вузли в Beowulf пасивні. Вони конфігуруються і управляються серверними вузлами і виконують тільки те, що наказано серверним вузлом.
Кластер AC3 Velocity Cluster
Кластер AC3 Velocity Cluster, встановлений в Корнельськом університеті (США) став результатом спільної діяльності університету і консорціуму AC3 (Advanced Cluster Computing Consortium), утвореного компаніями Dell, Intel, Microsoft, Giganet і ще 15 виробниками ПЗ з метою інтеграції різних технологій для створення кластерної архітектури для учбових і державних установ.
Склад кластера:
- 64 чотирипроцесорних сервера Dell PowerEdge 6350 на базі Intel Pentium III Xeon 500 MHz, 4 GB RAM, 54 GB HDD, 100 Mbit Ethernet card;
- 1 восьмипроцесорний сервер Dell PowerEdge 6350 на базі Intel Pentium III Xeon 550 MHz, 8 GB RAM, 36 GB HDD, 100 Mbit Ethernet card.
Чотирипроцесорні сервери змонтовані по вісім штук на стійку і працюють під управлінням ОС Microsoft Windows NT 4.0 Server Enterprise Edition. Між серверами встановлено з’єднання на швидкості 100 Мбайт/c через Cluster Switch компанії Giganet.
Завдання в кластері управляються за допомогою Cluster ConNTroller, створеного в Корнельськом університеті. Пікова продуктивність AC3 Velocity складає 122 GFlops при вартості в 4 - 5 разів менше, ніж у суперкомп’ютерів з аналогічними показниками.
На момент введення в лдію (літо 2000 року) кластер з показником продуктивності на тесті LINPACK в 47 GFlops займав 381-й рядок списку Top 500.
Кластер NCSA NT Supercluster
У 2000 році в Національному центрі суперкомп’ютерних технологій (NCSA - National Center for Supercomputing Applications) на основі робочих станцій Hewlett-Packard Kayak XU РС workstation був зібраний ще один кластер, для якого як операційна система була вибрана ОС Microsoft Windows. Розробники назвали його NT Supercluster.
На момент введення в дію кластер з показником продуктивності на тесті LINPACK в 62 GFlops і піковою продуктивністю в 140 GFlops займав 207-й рядок списку Top 500.
Кластер побудований з 38 двопроцесорних серверів на базі Intel Pentium III Xeon 550 MHz, 1 Gb RAM, 7.5 Gb HDD, 100 Mbit Ethernet card. Зв’язок між вузлами здійснювався через мережу Myrinet.
Програмне забезпечення кластера:
- операційна система - Microsoft Windows NT 4.0;
- компілятори - Fortran77, C/C++;
- рівень передачі повідомлень заснований на HPVM.
В даний час в списку Top 500 самих високопродуктивних систем кластери складають більше 80% (417 позицій).