

7.3. Технологии доступа к деловым ресурсам Интернета
Интернет, являясь глобальной телекоммуникационной сетью, предоставляет возможность доступа к большому количеству информационных ресурсов. По некоторым оценкам, объем Интернет-ресурсов превышает 50 млн веб-сайтов и 10 млрд веб-страниц [25].
Под веб-страницей понимается электронный документ, который может содержать информацию в различном формате в виде текста, изображения, звука и т.д. Веб-сайт является совокупностью веб-страниц, связанных по смыслу или ссылками. В наиболее благоприятном случае пользователь знает адрес сайта. Адрес он может получить различными способами: из книг, справочников, периодических изданий, рекламных проспектов и других источников.
Основной проблемой, с которой сталкивается пользователь при работе в Интернете, является обнаружение необходимых ему информационных ресурсов.
Поиск необходимых сведений в Интернете осуществляется либо при помощи поисковых машин (search engine), либо каталогов (directory). Но и здесь пользователь сталкивается с проблемой выбора, так как в 2001 г. количество поисковых машин в Интернете превысило 2000 [18].
На практике часто оба типа информационных поисковых систем представлены на одном веб-сервере. Эти веб-серверы так же принято называть порталами. Портал представляет собой веб-сайт, организованный как системное многоуровневое объединение разных ресурсов и сервисов.
Мы будем рассматривать поисковые машины и каталоги отдельно в виду принципиальных различий в организации их работы.
Поисковые машины
Задача поисковых машин — найти документы в Интернете по запросу пользователя. Поисковые системы состоят из трех основных частей.
Робот/Паук — программа, которая систематически посещает веб-страницы, считывает и индексирует полностью или частично их содержимое и далее следует по найденным ссылкам. Полученная информация заносится в базу данных поисковой машины.
Поисковая база данных Индекс представляет собой гигантское хранилище, которое содержит опеределенным образом организованные данные: индексы, ссылки на веб-страницы и другую дополнительную информацию.
Поисковая программа, которая в соответствии с запросом пользователя перебирает индексы в поисках соответствующей информации и выдает результаты поиска в виде ранжированного списка найденных веб-документов. Место в списке определяется тем, насколько полно тот или иной документ отвечает критериям, указанным в запросе пользователя.
Принципы работы паука, организации индекса, поисковой программы в поисковых машинах, как правило, различаются. Поэтому запрос по одним и тем же выражениям в разных поисковых машинах обычно дает разные результаты.
Программа поиска отыскивает страницы, которые соответствуют формальным требованиям запроса. Чтобы определить последовательность, в которой отобранные страницы будут представлены пользователю, применяется алгоритм ранжирования. В интересах пользователя документы, наиболее соответствующие потребностям пользователя, должны быть помещены первыми в списке результатов. Поисковые системы используют различные алгоритмы ранжирования, однако основные принципы определения соответствия документов запросу следующие:
количество слов запроса в текстовом содержимом документа;
тэги, в которых эти слова располагаются;
местоположение искомых слов в документе;
удельный вес искомых слов в общем количестве слов документа;
время — как долго страница находится в базе поискового сервера;
индекс цитируемости — как много ссылок на данную страницу идет с других страниц, зарегистрированных в базе поисковой машины.
Однако эффективность работы поисковых машин ограничивается четырьмя существенными факторами.
1.Топология Интернета такова, что поисковые машины могут просматривать не больше трети всех сайтов в Интернете.
В 2000 г. специалисты компаний AltaVista,IВМ и Compag исследовали ресурсы и гиперсвязи существующего информационного пространства WWW. Просмотрев с помощью поисковых средств AltaVista свыше 600 млн веб-страниц и 1,5 млрд ссылок, размещенных на этих страницах, они пришли к выводу, что исследуемое пространство состоит из следующих компонентов:
центральное ядро — эго тесно связанные между собой вебстраницы, с каждой из которых можно попасть на любую другую (27%);
отправные страницы. В них могут быть ссылки, ведущие к ядру, но из ядра к отправным страницам попасть нельзя (22%);
конечные веб-страницы, к которым можно прийти по ссылкам из ядра, но к ядру от них попасть нельзя (22%);
полностью изолированные от центрального ядра страницы, имеющие ссылки либо на конечные веб-страницы, либо ссылки с отправных веб-страниц (22%);
веб-страницы, не пересекающиеся с остальными ресурсами Интернета (7%).
Исследования показали, что при увеличении общего объема информационных ресурсов Интернета установленные отношения компонентов остаются прежними. Проведенный анализ позволяет сделать вывод о том, что информационное простран ство Интернета является достаточно сложным и неоднородным. К отдельным ресурсам Интернета поисковые машины не имеют доступа.
2.Глубина индексирования веб-сайтов. Большинство поисковых машин индексируют только определенное количество документов на одном веб-сайте.
3."Невидимый Интернет" (скрытый). "Видимая" часть сайтов — это та часть, которая обрабатывается поисковыми системами и индексируется. "Невидимая" часть — это та часть сайта, которая не предназначена для обработки поисковыми системами. Американская фирма BrightPlanet разработала программное обеспечение по исследованию "невидимой" части сайтов. Полученные результаты показывают, что число документов "невидимой" части более чем в 500 раз превышает число документов, относящихся к "видимой" части [25].
К невидимому Интернету в первую очередь относятся ресурсы, для доступа к которым требуется пароль или регистрация, профессиональные базы данных, а также различные форматы предоставления информации. Например, только с недавнего времени поисковые машины начали индексировать информацию в PDF-формате.
Лидирующие позиции по количеству проиндексированных веб-страниц занимают поисковые машины Google, AltaVista (рис. 7.2).
При работе с поисковыми машинами большое значение имеет язык запросов, так как единственным инструментом поиска становится полнотекстовый поиск по ключевым словам.
В большинстве поисковых систем доступен набор поисковых операторов. Наиболее распространены операторы, реализующие логические условия "И" (AND), "ИЛИ" (OR), "НЕ" (NOT), "РЯДОМ" (NEAR). Эти условия пишутся на английском языке и имеют символьные сокращения. Символьное обозначение поисковых операторов и возможности их использования значительно различаются в поисковых машинах. Оператор близости в чистом виде практически не присутствует (в AltaVista оператор NEAR задает поиск слов запроса в пределах 10 слов, в Lycos — в пределах 25), обычно он обозначается числом в окружении каких-либо специальных символов.
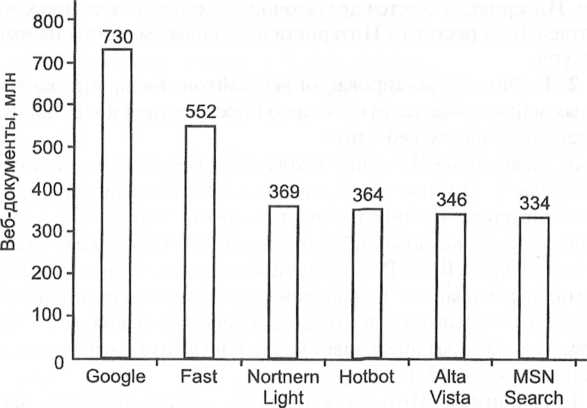
Рис. 7.2. Количество проиндексированных веб-страниц поисковыми машинами, млн веб-документов
Источник: Захаров В. П. Информационные ресурсы (документальный поиск). - СПб.: Санкт-Петербургский гос. ун-т, 2002. - С. 145.