

Стратегии поддержания ссылочной целостности.
Основные стратегии поддержания ссылочной целостности
Существуют две основные стратегии поддержания ссылочной целостности.
RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к нарушению ссылочной целостности.
CASCADE (КАСКАДНОЕ ИЗМЕНЕНИЕ) - Разрешить выполнение операции, но внести необходимые изменения в других отношениях так, чтобы не допустить нарушение ссылочной целостности и сохранить все имеющиеся связи.
Технологии распределенных бд и тиражирования (репликации) бд.
Распределенная база данных — это набор отношений, хранящихся в разных узлах компьютерной сети и логически связанных таким образом, чтобы составлять единую совокупность данных.
Распределенная база данных предполагает хранение данных на нескольких узлах сети, обработку данных и их передачу между этими узлами в процессе выполнения запросов. Разбиение данных в распределенной базе данных может достигаться путем хранения различных таблиц на разных компьютерах или хранения разных фрагментов одной таблицы на разных компьютерах. Для пользователя (или прикладной программы) не должно иметь значения, каким образом распределены данные между компьютерами. Работа с распределенной базой данных должна осуществляться так же, как и с централизованной.
Тиражирование данных (Data Replication - DR) - это асинхронный перенос изменений объектов исходной базы данных (source database) в БД, принадлежащим различным узлам распределенной системы. Функции DR выполняет специальный модуль СУБД - сервер тиражирования данных, называемый репликатором (replicator). Его задача - поддержка идентичности данных в принимающих базах данных (target database) данным в исходной БД. Сигналом для запуска репликатора служит срабатывание некоторого правила.
Принципиальная характеристика тиражирования данных заключается в отказе от физического распределения данных. Суть DR состоит в том, что любая база данных (как для СУБД, так и для работающих с ней пользователей) всегда является локальной; данные размещаются локально на том узле сети, где они обрабатываются; все транзакции в системе завершаются локально.
Билет № 7
Иерархическая и сетевая модели данных.
Иерархическая модель данных — представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья).
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Структурированный язык запросов SQL. История развития. Стандарты. Диалекты. Типы команд.
Структурированный язык запросов SQL(Structured Query Language) - это язык, разработанный корпорацией IBM в 1970 году. Он фактически стал стандартом в качестве языка реляционных баз данных. Cлужащий IBM доктор Е.Ф.Кодд предложил язык SQL (называвшийся тогда SEQUEL - Structured English Query Language, структурированный английский язык запросов), как средство извлечения информации из реляционной базы данных, модель которой он разработал в 1970 г.
В настоящее время SQL представляет собой не просто язык запросов, а наиболее распространенный язык управления реляционными базами данных типа клиент-сервер. Основное достоинство SQL заключается в том, что он унифицирован: стандартный набор инструкций SQL можно использовать в любой системе управления базами данных, которая поддерживает SQL. Именно язык SQL является стандартом для работы с реляционными СУБД. SQL стал единственным языком баз данных клиент-сервер. Сервер баз данных (нижний уровень) отвечает за хранение данных. Приложения-клиенты (верхний уровень) добавляют или обновляют данные. Кроме того, приложение генерирует инструкции SQL. При регулярной работе с базами данных знание SQL обязательно. Это также относится к разработчикам, которым требуется создавать приложения с определяемыми пользователем запросами. Создание современных информационных систем представляет собой сложнейшую задачу, решение которой требует применения специальных методик и инструментов. Неудивительно, что в последнее время среди системных аналитиков и разработчиков значительно вырос интерес к CASE (Computer-Aided Software/System Engineering) - технологиям и инструментальным CASE-средствам, позволяющим максимально систематизировать и автоматизировать все этапы разработки программного обеспечения.
Такими категориями (типами) команд являются:
DDL (Data Definition Language — язык определения данных);
DML (Data Manipulation Language — язык манипуляций данными);
DQL (Data Query Language — язык запросов к данным);
DCL (Data Control Language — язык управления данными);
команды администрирования данных;
команды управления транзакциями.
Билет № 8
Реляционная модель данных.
Реляционная модель данных объекты и связи между ними представляет в виде таблиц, при этом связи тоже рассматриваются как объекты. Все строки, составляющие таблицу в реляционной базе данных, должны иметь первичный ключ. Все современные средства СУБД поддерживают реляционную модель данных.
Эта модель характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
1. Каждый элемент таблицы соответствует одному элементу данных.
2. Все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип и длину.
3. Каждый столбец имеет уникальное имя.
4. Одинаковые строки в таблице отсутствуют;
5. Порядок следования строк и столбцов может быть произвольным.
SQL: Команды определения данных (DDL).
Язык определения данных (DDL). Это та часть SQL, которая используется
для создания (полного определения) базы данных, изменения ее структуры
и удаления базы после того, как она становится ненужной
Билет № 9
Многомерная, постреляционная, объектно-ориентированная модели данных.
Многомерный подход к представлению данных в базе появился практически одновременно с реляционным, но реально работающих многомерных СУБД (МСУБД) до настоящего времени было очень мало. С середины 90-х годов интерес к ним стал приобретать массовый характер.
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Это означает, что информация в таблице представляется в первой нормальной форме. Существует ряд случаев, когда это ограничение мешает эффективной реализации приложений.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования. Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними состоит в методах манипулирования данными.
SQL: Команды манипулирования данными (DML).
Язык манипулирования данными (DML). Он предназначен для поддержки
базы данных. С помощью этого мощного инструмента можно точно указать,
что именно нужно сделать с данными, находящимися в базе, — добавить, из-
менить или извлечь.
Билет № 10
Трехуровневая архитектура представления данных ANSI/SPARC.
В данном случае для нас наиболее важным моментом в этих и последующих разработках является идентификация трех уровней абстракции, т.е. трех различных уровней описания элементов данных. Эти уровни формируют трехуровневую архитектуру, которая охватывает внешний, концептуальный и внутренний уровни, как показано на рис. 5.6. Цель трехуровневой архитектуры заключается в отделении пользовательского представления базы данных от ее физического представления
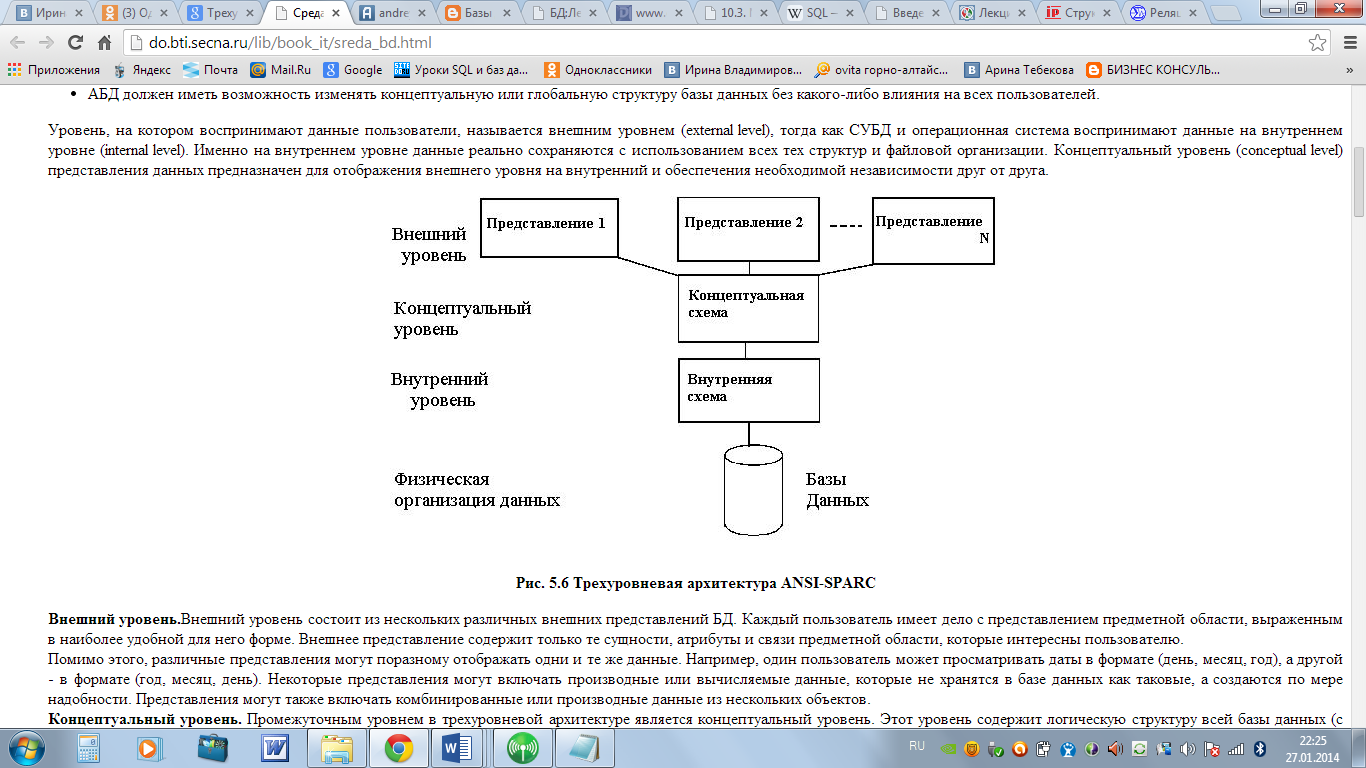
Внешний уровень.Внешний уровень состоит из нескольких различных внешних представлений БД. Каждый пользователь имеет дело с представлением предметной области, выраженным в наиболее удобной для него форме. Внешнее представление содержит только те сущности, атрибуты и связи предметной области, которые интересны пользователю.
Помимо этого, различные представления могут поразному отображать одни и те же данные. Например, один пользователь может просматривать даты в формате (день, месяц, год), а другой - в формате (год, месяц, день). Некоторые представления могут включать производные или вычисляемые данные, которые не хранятся в базе данных как таковые, а создаются по мере надобности. Представления могут также включать комбинированные или производные данные из нескольких объектов.
Концептуальный уровень. Промежуточным уровнем в трехуровневой архитектуре является концептуальный уровень. Этот уровень содержит логическую структуру всей базы данных (с точки зрения АБД). Фактически, это полное представление требований к данным, которое не зависит от любых соображений относительно способа их хранения. На концептуальном уровне представлены следующие компоненты: все сущности, их атрибуты и связи; накладываемые на данные ограничения; семантическая информация о данных; информация о мерах обеспечения безопасности и поддержки целостности данных.
Концептуальный уровень поддерживает каждое внешнее представление, в том смысле, что любые доступные пользователю данные должны содержаться (или могут быть вычислены) на этом уровне. Однако этот уровень не содержит никаких сведений о методах хранения данных.
Внутренний уровень. Внутренний уровень описывает физическую реализацию базы данных и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. Он содержит описание структур данных и организации отдельных файлов, используемых для хранения данных в запоминающих устройствах. На этом уровне осуществляется взаимодействие СУБД с методами доступа операционной системы с целью размещения данных на запоминающих устройствах, создания индексов, извлечения данных и т.д. На внутреннем уровне хранится следующая информация: сведения о распределении дискового пространства для хранения данных и индексов; описание подробностей сохранения записей (с указанием реальных размеров сохраняемых элементов данных); сведения о размещении записей; сведения о сжатии данных и выбранных методах их шифрования.
БД в локальных сетях. Архитектуры файл-сервер и клиент-сервер.
Билет № 11
Целостность данных. Ограничения целостности.
Це́лостность ба́зы да́нных (database integrity) — соответствие имеющейся в базе данных информации её внутренней логике, структуре и всем явно заданным правилам. Каждое правило, налагающее некоторое ограничение на возможное состояние базы данных, называется ограничением целостности (integrity constraint). Примеры правил: вес детали должен быть положительным; количество знаков в телефонном номере не должно превышать 25; возраст родителей не может быть меньше возраста их биологического ребёнка и т.д.
В реляционной модели данных определены два базовых требования обеспечения целостности:
целостность ссылок
Ссы́лочная це́лостность (англ. referential integrity) — необходимое качество реляционной базы данных, заключающееся в отсутствии в любом её отношении внешних ключей, ссылающихся на несуществующие кортежи.
Требование целостности по ссылкам состоит в следующем:
для каждого значения внешнего ключа, появляющегося в дочернем отношении, в родительском отношении должен найтись кортеж с таким же значением первичного ключа.
Пусть, например, даны отношения ОТДЕЛ (N_ОТДЕЛА, ИМЯ_ОТДЕЛА) и СОТРУДНИК (N_СОТРУДНИКА, N_ОТДЕЛА, ИМЯ_СОТРУДНИКА), в которых хранятся сведения о работниках предприятия и подразделениях, где они работают. Отношение ОТДЕЛ в данной паре является родительским, поэтому его первичный ключ "N_отдела" присутствует в дочернем отношении СОТРУДНИК. Требование целостности по ссылкам означает здесь, что в таблице СОТРУДНИК не может присутствовать кортеж со значением атрибута "N_отдела", которое не встречается в таблице ОТДЕЛ. Если такое значение в отношении ОТДЕЛ отсутствует, значение внешнего ключа в отношении СОТРУДНИК считается неопределенным.
целостность сущностей. (однозначность и непротиворечивость)
Вполне очевидно, что если данное требование не соблюдается (т.е. кортежи в рамках одного отношения не уникальны), то в базе данных может хранится противоречивая информация об одном и том же объекте. Поддержание целостности сущностей обеспечивается средствами системы управления базой данных (СУБД). Это осуществляется с помощью двух ограничений:
при добавлении записей в таблицу проверяется уникальность их первичных ключей
не позволяется изменение значений атрибутов, входящих в первичный ключ.
Схема обмена данными при работе с БД.
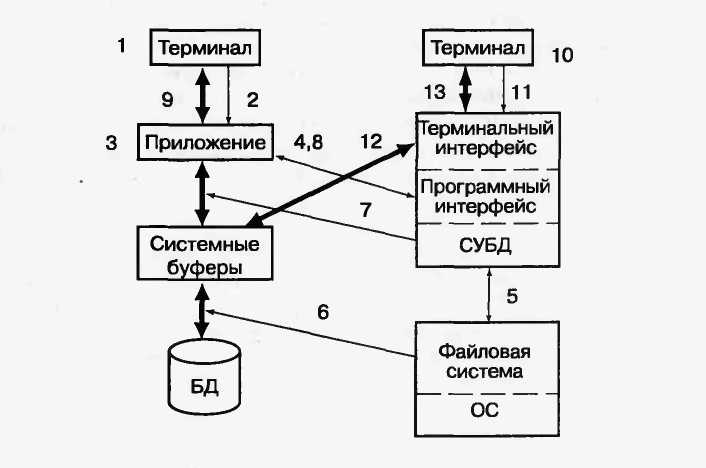
Пользователь терминала (1) в процессе диалога с приложением формулирует запрос (2) на выборку некоторых данных из БД.
Приложение (3) на программном уровне средствами языка манипулирования данными формулирует запрос (4), с которым обращается к СУБД.
Используя свои системные управляющие блоки и таблицы, СУБД с помощью словаря данных определяет местоположение требуемых данных и обращается (5) за ними к ОС.
Программы методов доступа файловой системы ОС считывают (6) из внешней памяти искомые данные и помещают их в системные буферы СУБД.
Преобразуя полученные данные к требуемому формату, СУБД пересылает их (7) в соответствующую область программы и сигнализирует (8) о завершении операции каким-либо образом (например, кодом возврата).
Результаты выбора данных из базы приложение (3) отображает (9) на терминале пользователя (1).
В случае работы пользователя в диалоговом режиме с СУБД (без приложения) цикл взаимодействия пользователя с БД упрощается. Его можно представить следующими этапами:
Пользователь терминала (10) формулирует на языке запросов СУБД, например QBE, по связи (11) требование на выборку некоторых данных из базы.
СУБД определяет местоположение требуемых данных и обращается (5) за ними к ОС, которая считывает (6) из внешней памяти искомые данные и помещает их в системные буферы СУБД.
Информация из системных буферов преобразуется (12) к требуемому формату, после чего отображается (13) на терминале пользователя (10).
Напомним, что описанная схема поясняет, как функционирует СУБД с одним пользователем на отдельной ПЭВМ.
Билет № 12