

Визначте характеристики доступних вам багатопроцесорних машин.
Для розв’язання завдань побудови інформаційного товариства й підняття рівня наукових досліджень в Національному технічному університеті України «Київський політехнічний інститут» створено центр суперкомп’ютерних обчислювань на базі кластерної обчислювальної системи.
Стисла характеристика кластерної обчислювальної системи:
Обчислювальний вузол (Dual Core) 168 шт.: |
2*3,2 ГГц |
|
4 Гбайт ОЗП |
Архівна пам'ять: |
20 Тбайт |
Кластерна пам'ять: |
12 Тбайт |
Пікова продуктивність системи: |
2 Тфлопс |
Внутрішня і зовнішня пропускна здатність: |
До 2 Гбайт/с |
Скільки процесорів на вашій машині, і які їх робочі частоти?
На моїй машині один двох-ядерний процесор Intel Core2 Duo T6600, його робоча частота 2*2,2 ГГц.
Наскільки великий розмір кеш-пам’яті багатопроцесорних машин, як вона організована? Який час доступу?
В багатопроцесорних системах використовується кеш третього рівня він найменш швидкодіючий, але він може бути дуже значного розміру – більше 24 Мбайт. У багатопроцесорних системах перебуває в загальному користуванні і призначений для синхронізації даних різних L2.
Сучасна типова ієрархія пам'яті має наступну структуру:
регістри 64 - 256 слів з часом доступу 1 такт процесора;
кеш 1 рівня – 8К слів з часом доступу 1 - 2 такти;
кеш 2-го рівня - 256К слів з часом доступу 3 - 5 тактів;
основна пам'ять - до 4Гіга слів з часом доступу 12 - 55 тактів.
Як організовано сполучну мережу?
Один із способів подолати обмеження пропускної здатності однієї загальної шини полягає у використанні більш складної сполучної мережі, подібної мережі, що зв'язує процесори в мультипроцесорних системах. Матричний комутатор являє собою сполучну мережу, що складається з 2Л/Гшин, що з'єднують N вхідних портів з JV вихідними портами, як показано на рис. 11.
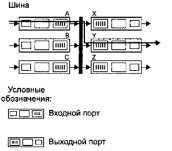
Рис 11
Прибуває на вхідний порт пакет переміщається по горизонтальній шині до перетину з вертикальною шиною, що веде до потрібного вихідного порту. Якщо провідна до вихідного порту вертикальна шина вільна, пакет переноситься у вихідний порт. Якщо в даний момент вертикальна шина вже використовується для передачі пакета в той же самий вихідний порт з іншого вхідного порту, тоді пакет блокується і ставиться в чергу вхідного порту.
Як з'єднувальні мережі між вхідними і вихідними портами також пропонувалося використовувати комутаційні блоки Delta і Omega. У комутаторах сімейства Cisco 12000 застосовується сполучна мережа, що забезпечує пропускну здатність до 60 Гбіт/с. одна з сучасних тенденцій у пристрої сполучної мережі полягає в тому, що IP-дейтаграма змінної довжини фрагментується на клітинки фіксованої довжини, які потім маркуються і комутуються через сполучну мережу. На вихідному порту з цих осередків відновлюється вихідна дейтаграма. Осередки фіксованої довжини і внутрішня маркування істотно спрощують і прискорюють комутацію пакета через сполучну мережу.