

По степени интеграции ядер и устройств
1.1.Слабоинтегрированные ядра в рамках нескольких кристаллов: в рамках 1 корпуса CPU находится несколько отдельных кристаллов CPU. Достоинства подхода: не нужно делать дополнительные сокеты на материнской плате. Недостаток: связь с внешним миром разделяема всеми 4 CPU.
1.2.Слабоинтегрированные ядра в рамках 1 кристалла. Достоинства: совмещение части служб для нескольких процессоров, что приводит к снижению энергозатрат и увеличению управляемости.
Недостатки: связь с внешним миром разделяема всеми CPU.
1.3.Процессоры средней интеграции ядер. Значимая часть устройств совмещена или разделяется ядрами (cash, контроллеры памяти, прерываний и т.д.)
1.4.Процессоры с ядрами высокой(плотной) интеграции. Большая часть устройств, в том числе исполнительных может разделяться ядрами.
2. По однородности ядер
2.1.Однородные. 2.2.Неоднородные (Однородность/неоднородность может быть как аппаратная, так и функциональная).
3. По связям между ядрами
3.1.Связь с помощью общей памяти (Общий кэш 2-ого уровня) (Intel).
3.2.Связь с помощью коммутаторов (связь с помощью коммутаторов в рамках процессора) (AMD, Cell).
3.3.Без связей.
Intel
выбрала путь симметричных мультипроцессорных
систем с шинной архитектурой.  Шина
является узким местом, на шину нельзя
поставить много процессоров, 4 – максимум.
Достоинством такого решения является
простота.
Шина
является узким местом, на шину нельзя
поставить много процессоров, 4 – максимум.
Достоинством такого решения является
простота.
Схема процессора Pentium M.

MC- Micro Core, микроядро. В него входят APIC, Pipeline, L1.
APIC – Advanced Programmable Interrupt Controller.
Pipeline – конвейер.
L1 – кэш первого уровня; L2 – кэш второго уровня
B I
– Bus
Interface
– контроллер шины
I
– Bus
Interface
– контроллер шины
GART – графическая адресная таблица – матрица в которой происходит преобразование графических адресов в линейное представление оперативной памяти.
DMA – контроллер прямого доступа к памяти
MemC – контроллер памяти
Подход фирмы AMD.
Взаимодействие происходит через линии системной шины HyperTransport. Системы с коммутатором.
Особенности:
1) У каждого процессора своя память
2) взаимодействие с устройствами и другими процессорами осуществляется через линки шины HyperTransport. У каждого процессора три таких линка.
3) На кристалле полностью интегрированы северный мост и контроллер памяти.

SRI – System request interface – системный интерфейс запросов. SRI отслеживает все запросы, как от каждого ядра, так и от внешних устройств, в т.ч. от внешних. Также он служит барьером между чипсетом и ядрами, позволяет оградить процессор от лишней работы, например, прохождения передач данных.
CB – Cross Bar – система коммутации. Это система типа NUMA, логически память общая. Работа с кэшем: 1) используется протокол когерентности MOESI, 2) Кэш L2 другого ядра представляется как кэш L3, 3) кэш другого процессора представляется как кэш L4.
Достоинства и недостатки подходов Intel и AMD.
До последнего времени предпочтительным считался подход AMD.
Шинная организация (Intel):
+ простота и дешевизна
+ пропускная способность интерфейса шины прямо пропорциональна числу ядер
+ теоретическая пропускная способность интерфейса к памяти прямо пропорциональна числу ядер, т.к. доступ к памяти осуществляется через системный интерфейс шины
+ наличие общего кэша в Core2 Duo обеспечивает:
1) хорошую сбалансированность нагрузки на кэш второго уровня
2) отсутствие необходимости обеспечения когерентности
3) возможность наращивания
+ поскольку нет интегрированного контроллера памяти, процессоры Intel не зависимы от типа памяти.
- ограничение пропускной способности системной шины
- необходимость создания нового сокета для каждого нового процессора
- осложняется доступ к кэшу второго уровня из-за конфликтов по доступу, т.к. кэш общий.
AMD:
+ интегрированность NB и MC дает след. эффект:
1) меньшее число сокетов
2) быстрота доступа к NB
3) NB работает на частоте процессора
- Трудности с обновлением памяти, т.к. встроенный контроллер памяти поддерживает только один тип памяти и этот же тип поддерживается на уровне сокета
- ограничение пропускной способности контроллера памяти
- более сложная технология (большой процент брака в продукции).
Intel: расположение двух двухъядерных процессоров на одном кристалле и подключение их к системной шине.
AMD: переход от ядра К8 к К10. Появление общего кэша 3го уровня.
Достоинства и недостатки подходов Intel и AMD.
До последнего времени предпочтительным считался подход AMD.
Шинная организация (Intel):
+ простота и дешевизна
+ пропускная способность интерфейса шины прямо пропорциональна числу ядер
+ теоретическая пропускная способность интерфейса к памяти прямо пропорциональна числу ядер, т.к. доступ к памяти осуществляется через системный интерфейс шины
+ наличие общего кэша в Core2 Duo обеспечивает:
1) хорошую сбалансированность нагрузки на кэш второго уровня
2) отсутствие необходимости обеспечения когерентности
3) возможность наращивания
+ поскольку нет интегрированного контроллера памяти, процессоры Intel не зависимы от типа памяти.
- ограничение пропускной способности системной шины
- необходимость создания нового сокета для каждого нового процессора
- осложняется доступ к кэшу второго уровня из-за конфликтов по доступу, т.к. кэш общий.
AMD:
+ интегрированность NB и MC дает след. эффект:
1) меньшее число сокетов; 2) быстрота доступа к NB; 3) NB работает на частоте процессора
- Трудности с обновлением памяти, т.к. встроенный контроллер памяти поддерживает только один тип памяти и этот же тип поддерживается на уровне сокета
- ограничение пропускной способности контроллера памяти
- более сложная технология (большой процент брака в продукции).
Процессоры альянса STI (STI – Sony, Toshiba, IBM).
Процессор Cell, развитие направления PowerPC. Идеология кластеризации процессорных ядер. Содержит 9 процессорных ядер, эти ядра не однородные (не одинаковые). 1 ядро - PPE (Power Processor Element), 8 ядер – SPE (Sinergetic Processor Element).

EIB – Element Interconnect Bus – системная шина MIC – Memory Interconnect Controller
BIC – Bus Interconnect Controller LM – Local Memory
REG – векторные регистры
SIMD – устройство SIMD-операций (FPU – операции с плавающей точкой, IU – операции с фиксированной точкой).
У ядра PPE есть свой кэш первого и второго уровня, поддерживается режим Simultaneous MultiThreading. PPE выполняет скалярные операции и управляет ядрами SPE. SPE – специальные ядра для выполнения векторных операций. В них 128-битный операнд разделяется на четыре 32-битных слова. LM – программно доступная память (256 Кб). Шина EIB состоит из четырех колец по 128 разрядов (два кольца по часовой и два кольца против). В каждом пакете может использоваться до трех колец. Процессор Cell применим для: научных расчетов, графических расчетов, в бытовой технике, для построения ускорителей.
Билет №20. Современные многоядерные процессоры. Способы повышения производительности многоядерных процессоров. Процессоры фирмы INTEL, SUN и альянса STI. |
Пути повышения производительности микропроцессоров.
1)сокращение времени выполнения каждой команды в отдельности; 2) увеличение числа обрабатываемых данных в единицу времени; 3) конвейеризация.
(1) – Повышение тактовой частоты процессора.
(2) – Увеличение IPC (Instructions per Circle).
(3) – Увеличение объема обработанных данных.
(1):
1.1.Сокращение выполнения каждой отдельной команды;
1.2.Конвейеризация выполнения команд. В 2001 г. настал кризис этого направления, т.к. технология не позволяла производить улучшения, а в длинных конвейерах опасен их простой.
(3): Получило развитие в векторных и матричных процессорах, также устройства стали внедряться в обычные скалярные процессоры. Проблема состоит в том, что не все операции являются векторными.
(2): Наиболее востребованное в наше время направление. Здесь имеется в виду не только количество команд в каждый конкретный цикл, но и усредненное значение в течение некоторого промежутка времени.
Увеличение IPC подразумевается на
- ILP (instruction level parallel)
- TLP (thread level parallel)
ILP – увеличение числа инструкций, выполняемых за такт процессора:
суперскалярная обработка (выбор из памяти нескольких команд). Инструкции могут выбираться либо самостоятельно процессором: для этого в процессоре должен быть анализатор внутреннего параллелизма программного кода, либо все это отдается компилятору (VLIW).
Спекулятивное внеочередное выполнение команд. Выбор процессором команд, для которых имеются ресурсы для выполнения.
TLP – разделяется на несколько подходов:
Крупнозернистый (course grained)
Тонкозернистый (fine grained) (CMT-chip multi threading (SUN))
SMT (simultaneous multi threading) – одновременная многонитевая обработка.
СМР (chip multiprocessing) - многопроцессорная обработка на кристалле.
(1): В рамках одного процесса запускается несколько нитей, каждая из которых обрабатывает свой поток команд. Здесь в процессоре появляются дополнительные устройства, позволяющие хранить контекст нескольких нитей (дублирование РОН’ов, стека и проч.). Работа идет в режиме разделения времени: сокращение времени на переключение контекстов.
(2): Каждой нити выделяется один такт. В CMT как бы понижается частота работы отдельной нити (fCPU/n, где n – число нитей). Это очень полезно для северных систем. Происходит маскирование простоев (на обращение к памяти, cash и прочее).
(3): Одновременное выполнение нитей, но здесь происходит не циклическое переключение нитей, а переключение по мере необходимости (нет ресурсов) или по истечению кванта времени. Вершиной подхода SMT Является технология HTT (hyper threading technology). Эта технология отличается тем, что в 1 такт могут выполняться инструкции разных нитей: в рамках одного физического CPU. (Разделение аппаратных ресурсов между нитями).
(4): Многопроцессорность на уровне кристалла. В рамках одного процессора создается несколько процессорных ядер, каждое из которых представляется, с т.з. ОС и пользователя, как отдельный процессор и может выполнять потоки команд как отдельный процессор.
Intel выбрала путь симметричных мультипроцессорных систем с шинной архитектурой. Шина является узким местом, на шину нельзя поставить много процессоров, 4 – максимум. Достоинством такого решения является простота.
Схема процессора Pentium M.
MC- Micro Core, микроядро. В него входят APIC, Pipeline, L1.
APIC – Advanced Programmable Interrupt Controller.
Pipeline – конвейер.
L1 – кэш первого уровня; L2 – кэш второго уровня
BI – Bus Interface – контроллер шины
GART – графическая адресная таблица – матрица в которой происходит преобразование графических адресов в линейное представление оперативной памяти.
DMA – контроллер прямого доступа к памяти
MemC – контроллер памяти
Шинная организация (Intel):
+ простота и дешевизна
+ пропускная способность интерфейса шины прямо пропорциональна числу ядер
+ теоретическая пропускная способность интерфейса к памяти прямо пропорциональна числу ядер, т.к. доступ к памяти осуществляется через системный интерфейс шины
+ наличие общего кэша в Core2 Duo обеспечивает:
1) хорошую сбалансированность нагрузки на кэш второго уровня
2) отсутствие необходимости обеспечения когерентности
3) возможность наращивания
+ поскольку нет интегрированного контроллера памяти, процессоры Intel не зависимы от типа памяти.
- ограничение пропускной способности системной шины
- необходимость создания нового сокета для каждого нового процессора
- осложняется доступ к кэшу второго уровня из-за конфликтов по доступу, т.к. кэш общий.
Многоядерные процессоры SUN
Процессор Ultra Sparc T1 (Niagara)
8-ядерный процессор.

FPU – float point unit.
CCX – cash crossbar.
L2 – КЭШ 2-ого уровня.
B0-B3-блок ввода/вывода.
МС- memory controller.
Каждое ядро работает в режиме simultaneous multi threading. В каждом из них имеется контекст из 4 потоков, следовательно, с точки зрения логики, имеется 32 логических процессора. Переключение между потоками занимает 1 такт, в 1 такт ядро может выполнять только 1 поток. Fтактовая=1,2 ГГц.
Достаточно высокая производительность процессора:
- за 1 такт выполняются операции 8 потоков;
- короткий конвейер (8 тактов) – не сильно сказывается простой.
- переключение потоков позволяет скрыть промахи CASH.
Специально для этих процессоров были разработаны серверы для обработки множества запросов.
Процессоры альянса STI (STI – Sony, Toshiba, IBM).
Процессор Cell, развитие направления PowerPC. Идеология кластеризации процессорных ядер. Содержит 9 процессорных ядер, эти ядра не однородные (не одинаковые). 1 ядро - PPE (Power Processor Element), 8 ядер – SPE (Sinergetic Processor Element).
EIB – Element Interconnect Bus – системная шина MIC – Memory Interconnect Controller
BIC – Bus Interconnect Controller LM – Local Memory
REG – векторные регистры
SIMD – устройство SIMD-операций (FPU – операции с плавающей точкой, IU – операции с фиксированной точкой).
У ядра PPE есть свой кэш первого и второго уровня, поддерживается режим Simultaneous MultiThreading. PPE выполняет скалярные операции и управляет ядрами SPE. SPE – специальные ядра для выполнения векторных операций. В них 128-битный операнд разделяется на четыре 32-битных слова. LM – программно доступная память (256 Кб). Шина EIB состоит из четырех колец по 128 разрядов (два кольца по часовой и два кольца против). В каждом пакете может использоваться до трех колец. Процессор Cell применим для: научных расчетов, графических расчетов, в бытовой технике, для построения ускорителей.
Вопрос №21. Высокопроизводительные мультипроцессорные сервера. Требования, предъявляемые к серверам. Ультрапортовая (UPA) архитектура. Пример реализации UPA-архитектуры.
Высокопроизводительные серверы и требования к ним:
Серверы представляют собой специализированные высокопроизводительные компьютеры, предназначенные для выполнения определенных сервисных функций и/или вычислений в сетевой среде. Ниже перечислены основные требования, предъявляемые к серверам.
1). Высокая производительность. Сервер является вычислительным устройством, на которое "сваливается" большое количество задач.
2). Расширяемость (наращиваемость). Данное требование означает, что система должна быть построена по модульному принципу, поддерживать возможность создания необходимых конфигураций и их последующего наращивания.
3). Масштабируемость. Система должна обладать хорошей линейностью характеристик (практически линейный рост производительности тех или иных ресурсов при увеличении их числа).
4). Возможность установки и поддержки большого объема памяти. Серверы должны обладать большими ресурсами памяти (как оперативной, так и внешней. Чем шире возможности сервера в части поддержки различных типов памяти, тем шире спектр его применений.
5). Наличие большого количества поддерживаемых интерфейсов ввода-вывода.
6). Надежность, готовность, обслуживаемость (Reliability, Availability, Serviceability - RAS) как составляющие высокой доступности (работоспособности) серверов. Поясним смысл этих понятий.
Архитектура UPA – Ultra Portal Architecture.
Обеспечение высокой производительности процессора UltraSPARC-1 потребовало создания гибкой масштабируемой архитектуры межсоединений. UPA представляет собой спецификацию, описывающую логические и физические интерфейсы порта системной шины, и требования, накладываемые на организацию межсоединений. К этим портам подключаются все устройства системы. UPA может поддерживать большое количество системных портов(32, 64, 128 и т.д.) и включает четыре типа интерфейса. Главное устройство UPA может включать физически адресуемую когерентную кэш-память, на размер которой в общем случае не накладывается никаких ограничений. Интерфейс подчиненного устройства получает транзакции чтения/записи от главных устройств UPA, поддерживая строгое упорядочивание транзакций одного и того же класса главных устройств, а также транзакций, направляемых по одному и тому же адресу устройства. Порт UPA может быть только подчиненным. Двумя другими дополнительными интерфейсами порта UPA являются источник и обработчик прерываний.
Архитектура UPA легко адаптируется для работы почти с любой конфигурацией системы С от однопроцессорной до массивно-параллельной.
Особенности: Все устройства, кроме памяти подключаются к специальным UPA-портам, которых теоретически может быть бесконечное множество. Эти порты подсоединяются к трем устройствам: коммутатору данных, коммутатору адресов, и системному контроллеру. С другой стороны к этим устройствам подсоединяются модули памяти, которых теоретически может быть бесконечно много.

DPC – Datapath Crossbar
DC – Datapath Control
SC&AC – System Control & Address Crossbar
Передача данных происходит в конвейерном порядке. Адрес следующего пакета выставляется еще при передаче данных предыдущего.
Особое внимание следует обратить на основное отличие UPA от других технологий, которое состоит в том, что шины UPA-адреса и UPA-данных имеют свои собственные коммутаторы, и, значит, могут иметь разную топологию. Все используемые в архитектуре шины имеют соединения типа "точка-точка". Данная особенность архитектуры определяет ее быстродействие, поскольку такой тип соединения характеризуется малой длиной линий и небольшой нагрузкой на них, что позволяет поднять частоту передачи данных до величин порядка 100 МГц. Правда, необходимо оговориться, что на самом деле UPA допускает подключение к шинам до четырех устройств (в основном это касается шин адреса), и в этом смысле утверждение о соединениях "точка-точка" не совсем корректно. Однако такие подключения используются в основном при реализации шин устройств ввода-вывода; что же касается процессорных модулей, то их на одной шине располагается не более двух.
Серия SUN Fire. Здесь рассматриваем сервер SUN Fire 15K. Сервер Sun Fire 15K - сервер масштаба крупного вычислительного центра, поддерживающий 5-ое поколение технологии Dynamic System Domains (Gen5). Сервер состоит из однотипных модулей.
Вопрос №22. Ультрапортовая (UPA) архитектура. Серверы SUN с UPA-архитектурой. Конфигурация сервера SUN Fire 15K. Назначение доменов в сервере SUN Fire 15K.
Архитектура UPA – Ultra Portal Architecture.
Обеспечение высокой производительности процессора UltraSPARC-1 потребовало создания гибкой масштабируемой архитектуры межсоединений. UPA представляет собой спецификацию, описывающую логические и физические интерфейсы порта системной шины, и требования, накладываемые на организацию межсоединений. К этим портам подключаются все устройства системы. UPA может поддерживать большое количество системных портов(32, 64, 128 и т.д.) и включает четыре типа интерфейса. Главное устройство UPA может включать физически адресуемую когерентную кэш-память, на размер которой в общем случае не накладывается никаких ограничений. Интерфейс подчиненного устройства получает транзакции чтения/записи от главных устройств UPA, поддерживая строгое упорядочивание транзакций одного и того же класса главных устройств, а также транзакций, направляемых по одному и тому же адресу устройства. Порт UPA может быть только подчиненным. Двумя другими дополнительными интерфейсами порта UPA являются источник и обработчик прерываний. Архитектура UPA легко адаптируется для работы почти с любой конфигурацией системы С от однопроцессорной до массивно-параллельной.
Особенности: Все устройства, кроме памяти подключаются к специальным UPA-портам, которых теоретически может быть бесконечное множество. Эти порты подсоединяются к трем устройствам: коммутатору данных, коммутатору адресов, и системному контроллеру. С другой стороны к этим устройствам подсоединяются модули памяти, которых теоретически может быть бесконечно много.
DPC – Datapath Crossbar
DC – Datapath Control
SC&AC – System Control & Address Crossbar
Передача данных происходит в конвейерном порядке. Адрес следующего пакета выставляется еще при передаче данных предыдущего.
Особое внимание следует обратить на основное отличие UPA от других технологий, которое состоит в том, что шины UPA-адреса и UPA-данных имеют свои собственные коммутаторы, и, значит, могут иметь разную топологию. Все используемые в архитектуре шины имеют соединения типа "точка-точка". Данная особенность архитектуры определяет ее быстродействие, поскольку такой тип соединения характеризуется малой длиной линий и небольшой нагрузкой на них, что позволяет поднять частоту передачи данных до величин порядка 100 МГц. Правда, необходимо оговориться, что на самом деле UPA допускает подключение к шинам до четырех устройств (в основном это касается шин адреса), и в этом смысле утверждение о соединениях "точка-точка" не совсем корректно. Однако такие подключения используются в основном при реализации шин устройств ввода-вывода; что же касается процессорных модулей, то их на одной шине располагается не более двух.
Серия SUN Fire. Здесь рассматриваем сервер SUN Fire 15K. Сервер Sun Fire 15K - сервер масштаба крупного вычислительного центра, поддерживающий 5-ое поколение технологии Dynamic System Domains (Gen5). Сервер состоит из однотипных модулей.
Конфигурация:
- архитектура - Superscalar SPARC 9. От 4 до 106 процессоров UltraSPARC III. Тактовая частота 1,05 и 1,2 ГГц. Защита ECC.
- кэш-память - 64Кб для данных, 32 Кб для команд, контроль четности. Вторичная - 8 Мб.
- платы память/процессор - до 18 плат процессор/память Uniboard - на каждой размещается 4 процессора и до 32 Гб памяти, что обеспечивает общий объем памяти до 576 Гб на систему.
- I/O - до 72 PCI-слотов для ввода/вывода, использующих 18 каналов, с поддержкой «горячей замены», 36 слотов на 66 МГц, 36 слотов на 33 МГц.
- межкомпонентное соединение - Sun Fireplane с тактовой частотой 150 МГц, 10,8 Гб/с в установившемся режиме, продублированный коммутатор с выделенными магистралями для данных, адресов и ответов (контролирующих прохождение транзакций).
- системный контроллер - 2 дублированных системных контроллера. Автоматическая система восстановления контроллеров, функций управления и часов системных контроллеров, без необходимости приостановки работы.
Назначение доменов.
Достоинства доменной структуры:
1) позволяет разграничить функциональность серверов
2) позволяет разграничить коллективы пользователей
3) обеспечение отказоустойчивости – отказ одного домена не приводит к отказу всего сервера
4) выделение ресурса под какую-либо определенную задачу
5) позволяет снять нагрузку с Centerplane
Вопрос №23. Кластерные вычислительные системы(КВС). Сравнения КВС с другими системами. Обобщенная структура и классификация КВС. Планирование и выполнение задач в КВС.
Это многопроцессорные (многомашинные) ВС с распределенной памятью, в которой процессорные модули представляют собой законченные вычислительные узлы со своей памятью, а в качестве коммуникационной системы используется локальная сеть. Кластеры представляют собой единый вычислительный ресурс.
Сравнение КВС с другими системами:
1). В отличие от мультикомпьютерной сети, кластеры представляют единый вычислительный ресурс.
2). Вычислительный кластер – это совокупность компьютеров, объединенных в рамках некоторой сети для решения одной задачи.
3). Кластерная вычислительная система – это массово-параллельная ВС, построенная из самостоятельных модулей, использующая по возможности универсальные аппаратные и программные решения с использованием локальной сети в качестве коммуникационной системы. КВС – частный случай MPP.
Обобщенная структура.

SV or WS – Сервер/Рабочая станция
Accelerator – ускоритель (может отсутствовать). Обычно множество процессоров (матричных) или графическая плата.
Основное в кластерной системе являются узлы (Node1,…NodeN). Они состоят из двух или одной части. Первая часть – это сервер или рабочая станция (SV or WS), вторая часть акселератор или ускоритель. Это часть может отсутствовать. Иначе если требуется более высокая производительность в сервер или рабочую станцию вставляются ускорительные платы (на ПМЛ, на процессоре SELL, графическая плата). Ускоритель - это специализированная плата, которая вставляется в слот и на ней ставятся специальный процессоры, чаще это множество процессоров и основной сервер узла обращается к этой плате для каких-то вычислений.
Классификация кластерных систем.
по назначению:
вычислительные кластеры – которые предназначены для решения больших задач, вычислений.
кластеры обработки информации – они часто встречаются в мощных вычислительных центрах, они например, принимают со всей страны много запросов, которые обслуживают.
кластеры обслуживания запросов – например, для работы с БД. Это например, поисковые машины – google (год назад было 10 000 узлов).
по составу:
кластер рабочих станций (ПК)
кластеры сервера
кластер специализированных вычислительных модулей.
по управлению:
централизованное управление
распределенное управление
по организации:
одноуровневые
многоуровневые (гиперкластеры). Узлами являются кластеры.
по используемым аппаратным и программным ресурсам:
Гомогенные – с однородными узлами. Это когда все узлы одинаковые. В МЭИ на кафедре такой кластер.
Гетерогенные - кластеры с неоднородными узлами.
Гетерогенность бывает:
По производительности узлов
По архитектуре узлов (структуре). Один может быть на Интел, другой на Спартк.
По использованию в узлах ОС. Один на Линукс, другой Виндовс.
По назначению или используемым ресурсам. Один специализируется на одном виде задач (доп. Ресурс БД), другой на другом (доп. Ресурс – ускоритель).
по вычислительным узлам
однопроцессорные
многопроцессорные (многоядерные) с общей памятью
по структуре используемых связей
одна сеть или несколько сетей
одноуровневые сети или иерархические сети
по технологиям: однородные или неоднородные сети
по назначению: сети с общим или специализированным назначением
по используемым сетевым технологиям
универсальные сети, такие как Gigabit Ethernet, Fast Ethernet.
Специализированные сети. Среди них SCI (Смотреть выше кластер МГУ) Myrinet, Infiniband.
по топологии связи
с общей шиной, с коммутатором, решеткой, кольцо, тор, сеть (в метакомпьютерах)
по используемому программному обеспечению
универсальное
стандартное специализированное
просто специальное
по организации взаимодействия параллельных ветвей ПО
В гомогенных кластерах:
однородное – имеем дело на лабах все процессы работают у нас с MPI.
неоднородное одноранговое – смотрят где выполняются разные ветви, если на разных но используют MPI. Иначе сочетают MPI OPENMP
неоднородное иерархическое – разбивают программу на блоки. Например, в рамках одной – используют MPI, в рамках другой используют, например средства почтовых ящиков, или другое, крупного плана на уровне распределения файлов.
В гетерогенных кластерах (особенности):
однородное по стандарту, неоднородное по реализации.
неоднородное по стандарту и реализации.
Комментарий: Если узлы КВС представляют собой самостоятельные ЭВМ, но работают под общим управлением и пользователю вся система представляется как одна ЭВМ, то такой кластер называется метакомпьютером.
Планирование и выполнение задач.

Показано, каким образом осуществляется управлений ей. Очередь ОЗ – это очередь запросов. Чаще всего в кластере бывает две очереди запросов:
ОЗ высокоприоритетных задач (короткая очередь)
ОЗ низкоприоритетных задач (длинная очередь).
Очереди поступают на диспетчер запросов. Он отслеживает систему очередей. Далее запрос идет на планировщик, он получается задачу о состоянии и далее он планирует загрузку узлов и далее размещает задачи по ядрам, по процессорам, по памяти, по жестким дискам. Менеджер ресурсов – отслеживает состояние.
При планировании учитываются следующие параметры:
1). Требуемые каждой задачей ресурсы;
2). Доступные свободные ресурсы;
3). Топология задачи;
4). Топология системы;
5). Распределение нагрузки на вычислители;
6).Связанность ветвей в рамках каждой задачи
7). Латентность и пропускная способность каналов.
Вопрос №24. Кластерные вычислительные системы(КВС). Обобщенная структура. Схемы обеспечения устойчивости в КВС. Кластер МЭИ. Структура узла кластера МЭИ.
Это многопроцессорные (многомашинные) ВС с распределенной памятью, в которой процессорные модули представляют собой законченные вычислительные узлы со своей памятью, а в качестве коммуникационной системы используется локальная сеть. Кластеры представляют собой единый вычислительный ресурс.
Обобщенная структура.
SV or WS – Сервер/Рабочая станция
Accelerator – ускоритель (может отсутствовать). Обычно множество процессоров (матричных) или графическая плата.
Основное в кластерной системе являются узлы (Node1,…NodeN). Они состоят из двух или одной части. Первая часть – это сервер или рабочая станция (SV or WS), вторая часть акселератор или ускоритель. Это часть может отсутствовать. Иначе если требуется более высокая производительность в сервер или рабочую станцию вставляются ускорительные платы (на ПМЛ, на процессоре SELL, графическая плата). Ускоритель - это специализированная плата, которая вставляется в слот и на ней ставятся специальный процессоры, чаще это множество процессоров и основной сервер узла обращается к этой плате для каких-то вычислений.
Схемы обеспечения отказоустойчивости КВС.
Существует несколько видов резервирования. При отсутствии сигналов сердцебиения от узла, другие узлы берут на себя функции этого узла. Отказ узла обнаруживается по отсутствию сигнала сердцебиения и по адекватности этого сигнала
Системы доступа к вторичной памяти. Есть варианты по размещению вторичной памяти.
1) У каждого узла вторичная память.

2) В случае отказа работоспособный узел обслуживает обе памяти.

3) У группы узлов одна вторичная память.
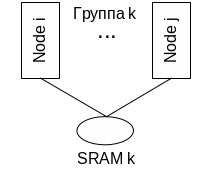
4) Система когерентности вторичной памяти – у каждого узла есть копия вторичной памяти. Это эффективно с точки зрения обеспечения устойчивости, как узла, так и самой вторичной памяти.

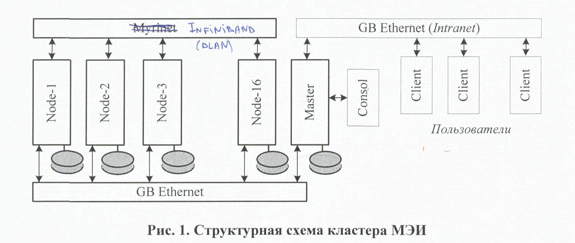
Кластер МЭИ.
Сеть InfiniBand – это сеть DLANs. 16 узлов. Т.к. нулевой адрес в сети не используется, поэтому решили нумеровать с 1 до 16. Сеть GB Ethernet она совмещает в себе сети ввода-вывода и управления-диагностики. У кластера имеется управляющий узел – Master. Внешняя сеть это Intranet MPEI. Имеется консоль при сервере.
Рис. 2. Структурная схема вычислительного а) и управляющего б) узлового кластера. По сути это тот же сервер. Но у одного двуядерный процессор Opteron 275, у другого два одноядерных. Два блока памяти по 2 гб, управляющего – 8 Гб. У каждого узла свой NB, Организация NUMA. Сама организация называет это SUMA (быстра УМА). Обе совмещены шинами HT.
Рис. 3. Структурная схема сервера Sun Fire X4100.
Видно что каждый процессор подсоединен каналом к 4ем слотам памяти. Прямая связь 8Гб/с и два линка НТ – один.
Моторола – сервисный процессор.


Вопрос 25. Метакомпьютинг и Grid системы. Особенности метакомпьютеров Grid типа, концепция, требования к выполняемым программам. |
Метакомпьютерные системы – это многомашинные вычислительные системы, работающие с единой системой управления и представляющиеся пользователю как одна машина (единый ресурс).
Т.е. имеются некоторые ресурсы, сеть и т.д. Поверх всего этого ставится ПО, которое позволяет разбросанным ресурсам работать как единой системе.
Кластер – частный случай подобной системы.
Коллаидер – мэи принимало участие. Настоящий пример grid.
Управление метакомпьютерной системой бывает:
Централизованное
Децентрализованное согласованное
ВИДЫ GRID-СИСТЕМ
1) Настольный суперкомпьютер – это система, обеспечивающая удаленный доступ к мощному вычислительному ресурсу

Ставится ПО такое, что пользователь может воспользоваться любым ресурсом, на котором хочет решить свою задачу.
2) Распределенный интеллектуальный инструментальный комплекс.
В сети создается специальная система, которая объединяет специальные ресурсы.
3) Сетевой суперкомпьютер.
Задачи распараллеливаются на все имеющиеся ресурсы (кластеры, серверы, ПК и др.) (Филатов занимался разработкой таких систем). Ресурсы входящие в сеть, становятся узлами глобальное мета-компьютерной системы.

ОСОБЕННОСТИ МЕТА-КОМПЬЮТЕРА GRID:
- Обладает огромными ресурсами (в теории неограниченными);
- Является распределенным по своей природе; - Может динамически менять конфигурацию;
- Неоднороден(почти по всем параметрам);
- Объединяет ресурсы различных организаций;
КОНЦЕПЦИЯ, ТРЕБОВАНИЯ К ВЫПОЛНЯЕМЫМ ПРОГРАММАМ
- Адаптивность к платформам;
- Адаптивность к производительности узлов(компонентов);
- Адаптивность к пропускной способности каналов и маршрутизации;
- Адаптивность к распределенности информационных ресурсов, в том числе баз данных;
- Безопасность ресурсов и программ;
- Реконфигурируемость;
- Отказоустойчивость;
Для грида – Рис. 3. В каждой компоненты имеются процессорные узлы, память собственная. 1ый блок – ЛП_ЛМР – локальный планировщик и локальный менеджер ресурсов. ЛПД – локальный планировщик данных. Удаленные данные, когда для работы требуются данных находящиеся на другой компоненте.
Система управлением ресурсами в Grid-систамах.


Вопрос №26. Массивно-параллельные (MPP) вычислительные системы, их сравнение с системами других классов. Вычислительные системы семейства IBM Blue Gene. Параметры систем IBM Blue Gene/L и IBM Blue Gene/P. Узел системы IBM Blue Gene/P.
MPP – massive parallel system – создается массив вычислительных узлов, каждый из которых имеет свои процессоры и свои собственные блоки памяти. Память организована по принципу NORMA (no remote memory access) – физически и логически распределенная память.
Сложность программирования. Хорошая масштабируемость программ.
Очень хорошая масштабируемость.
Очень хорошая наращиваемость.
Хорошая решаемость слабо связных масштабируемых задач и плохая решаемость сильно связных задач.
Высокая себестоимость, т.к. эти системы эксклюзивные. Высокая себестоимость ПО.
Сравнение трёх типв NORMA систем:
|
MPP |
Cluster |
Grid |
1 |
(-) При создании программ необходимо учитывать специализацию ВС (+) Использ. спец. пакетов. |
(+) Самое простое (относительно) программирование. |
(+) В теории подготовка ПО автоматизирована. (-) Трудн. с эффективным планированием. |
2 |
(+,-) Масштабируемость ограничена топологией |
(+) Масштабируемость слабо ограничена |
(+) Масштабируемость неограничена |
3 |
(+,-) Наращиваемость ограничена параметрами компонентов системы |
(+) Наращиваемость слабо ограничена |
(+) Наращиваемость и реконфигурируемость неограниченна |
4 |
(+,-) Хорошо выполняются задачи, под которые специализирована система |
(+,-) Хорошо выполняются слабосвязанные задачи |
(-) Эффективность для каждого класса сильно зависит от текущей КС |
5 |
(-) Системы содержат много эксклюзивных компонентов и ПО что повышает их стоимость |
(+) Системы собираются из серийных компонентов с серийным ПО |
(+,-) Определяется стоимостью дополнительного ПО |
Системы типа IBM BlueGene. Их 3 разновидности:
1.IBM BlueGene /L - реальнодействующая система. Только она была в полностью конфигурации собрана. Производительность в полной конфигурации 367 TF. Три года (2004-2007) первый номер в списке Тор500.
2.IBM BlueGene /P – реальнодействующая система. По своей конфигурации более мощная, но в полном объеме нигде в мире не организована. Производительность в полной конфигурации 1002.7 TF.
3.IBM BlueGene /C – самая мощная по конфигурации. (около 3PF)
Параметры системы IBM Blue Gene/L
1. Относится к MPP системам кластерного типа.
2. Производительность в полной конфигурации составляет 367 TF, в расширенной 596 TF.
3. Имеет 65526 вычислительных однопроцессорных узлов (Compute Node), каждый процессор имеет 2 ядра с архитектурой IBM PowerPC 440.
4. Система может иметь до 4096 узлов ввода-вывода (I/O Node) и коммуникационные схемы.
5. Узлы системы построены по принципу SoC (Sistem on Chip). Вычислительные узлы и узлы вв/выв реализованы микросхемой BLC (Blue Gene/L Compute) ASIC, а коммуникационные схемы микросхемами BLL (Blue Gene/L Link) ASIC.
6. Конструктивно система состоит из следующих иерархических компонентов:
- BLC ASIC и BLL ASIC
- Compute Card (два BLC + RAM 256MB) и I/O Card (два BLC + RAM 512MB)
- Node Card (16 Compute Card + 0-2 I/O Card), Link Card (24 BLL) и Service Card
- Midplane (16 Node Card + 4 Link Card + 1 Service Card)
- Rack (два Midplane)
- IBM Blue Gene/L в целом (до 64 Rack в полной конфигурации)
7. Шесть сетей:
Внутренние сети – в них участвую вычислительные узлы.
1 – сеть для двух точечных передач (организована по принципу 3D тора)
2 – загрузки узлов и коллективных передач (организована по принципу дерева)
3 – сеть прерываний и барьерной синхронизации (по принципу дерева)
4 – сеть JTAG. Сеть диагностики и управления.
Внешние:
1. - функциональная (Gigabit Ethernet, осуществляет загрузку системы м ввод-вывод)
– диагностики и управления (Gigabit и Fast Ethernet, связана с JTAG)
Параметры системы IBM Blue Gene/P
6. Конструктивно система состоит из следующих иерархических компонентов:
- Chip. (13.6 GF) Основной компонент системы 4-ядерный чип. Частота отдельного ядра 850 MГц.
- Compute Card. Один чип припаян к процессорной карте вместе с памятью DRAM (40 штук). Объем памяти 2 или 4 ГБ.
- Node Card (435 GF) (32 Compute Card (2 ряда по 16) + 0-2 I/O Card),
- Rack (14 TF) (32 Node Card). Хотя, наверное, тоже делится на 2 Midplane.
- IBM Blue Gene/P (1 PF) (72 Rack в полной конфигурации)

Узел содержит четыре PowerPC 450 процессора с 2-мя или 4-мя ГБ общей RAM.
Обычно все четыре ядра используются для вычислений либо в двойном режиме (DUAL mode, 2 задачи по 2 thread, 2 ядра выполняют главный thread), режиме виртуального узла (VN mode, может быть запущено 4 раздельных процесса), либо в режиме симметричной многопроцессорной обработки(SMP, одно ядро выполняет главный thread, всего четыре thread (по количеству ядер)).
Сети:
- 6 соединений с торообразной сетью на скорости 3,4 Гбит/с на линк; - 3 подключения к сети коллективных передач (6,8 Гбит/с на линк); - 6 соединения с сетью прерываний и барьерной синхронизации (3,5 Гбит/с на линк) - 1 соединение с сетью управления (JTAG)
- 10 GB Ethernet
- external DDR2 DRAM bus
Вопрос №27. Вычислительные системы семейства IBM Blue Gene. Параметры системы IBM Blue Gene/L. Узлы (виды узлов) системы IBM Blue Gene/L. Структурная схема BLC ASIC. Структурные компоненты системы IBM Blue Gene/L. Коллективные передачи в IBM Blue Gen e/L.
Системы типа IBM BlueGene. Их 3 разновидности:
1.IBM BlueGene /L - реальнодействующая система. Только она была в полностью конфигурации собрана. Производительность в полной конфигурации 367 TF. Три года (2004-2007) первый номер в списке Тор500.
2.IBM BlueGene /P – реальнодействующая система. По своей конфигурации более мощная, но в полном объеме нигде в мире не организована. Производительность в полной конфигурации 1002.7 TF.
3.IBM BlueGene /C – самая мощная по конфигурации. (около 3PF)
Параметры системы IBM Blue Gene/L
1. Относится к MPP системам кластерного типа.
2. Производительность в полной конфигурации составляет 367 TF, в расширенной 596 TF.
3. Имеет 65526 вычислительных однопроцессорных узлов (Compute Node), каждый процессор имеет 2 ядра с архитектурой IBM PowerPC 440.
4. Система может иметь до 4096 узлов ввода-вывода (I/O Node) и коммуникационные схемы.
5. Узлы системы построены по принципу SoC (Sistem on Chip). Вычислительные узлы и узлы вв/выв реализованы микросхемой BLC (Blue Gene/L Compute) ASIC, а коммуникационные схемы микросхемами BLL (Blue Gene/L Link) ASIC.
6. Конструктивно система состоит из следующих иерархических компонентов:
- BLC ASIC и BLL ASIC
- Compute Card (два BLC + RAM 256MB) и I/O Card (два BLC + RAM 512MB)
- Node Card (16 Compute Card + 0-2 I/O Card), Link Card (24 BLL) и Service Card
- Midplane (16 Node Card + 4 Link Card + 1 Service Card)
- Rack (два Midplane)
- IBM Blue Gene/L в целом (до 64 Rack в полной конфигурации)
7. Шесть сетей:
Внутренние сети – в них участвую вычислительные узлы.
1 – сеть для двух точечных передач (организована по принципу 3D тора)
2 – загрузки узлов и коллективных передач (организована по принципу дерева)
3 – сеть прерываний и барьерной синхронизации (по принципу дерева)
4 – сеть JTAG. Сеть диагностики и управления.
Внешние:
1. - функциональная (Gigabit Ethernet, осуществляет загрузку системы м ввод-вывод)
– диагностики и управления (Gigabit и Fast Ethernet, связана с JTAG)
К оллективные
передачи
оллективные
передачи

Быстро задействует все узлы.
Структурная схема BLC ASIC

Буфер L1: 32K – данные, 32К – команды.
L2 prefetch buffer – буфер предварительной выборки. Он как бы скрывает задержки при обращении к 3му уровню КЭШа (4Мб)
SRAM – статическая опреативная память с произвольным доступом (энергозависимая).
Имеется общая директория для КЭШа 3-го уровня и памяти.
КЭШ 3-его уровня с контролем циклического кода.
Обращение к RAM через контроллер DDR.
Multiported shared SRAM buffer хранит семафоры.
Тактовая частота всего 700МГц. Относительно небольшая. Во всех самых мощных машинах используются устаревшие процессоры, это объясняется ее надежностью и адаптированностью. Уже налажено производство надежных процессоров. Процесс брака должен быть сведен к минимуму. Время разработки – никогда такие системы не разрабатываются быстро.
Два ядра. Одно является вычислительным, другое ядром ввода-вывода. Когда второе ядро не занимается передачей, оно также выполняет вычисления.
Узел, который является вычислительным, не подключается к сети Gigabit Ethernet, все остальные сети задействованы.
Узел ввода-вывода подключается функционально к внешней сети Gigabit Ethernet, но не подключен к торовой сети и делают загрузку вычислительных узлов с помощью коллективной.
1.DDR control with ECC (error-correcting code)
2.Global interrupt/lockbox – интерфейс сети прерываний блокировок и синхронизации. Это сеть по которой распространяются все прерывания. Здесь 4 глобальных канала. (MPI_Barrier)
3.Collective - интерфейс сети коллективных передач. По этой сети осуществляются передачи MPI_Scatter, MPI_Gather, MPI_BCast. Три входных и три выходных канала.
4.Torus (построена по принципу 3хмерного тора) - сеть для двухточечных передач. Имеется 6 входных и 6 выходных каналов.
5.JTAG – Joint Test Action Group - сеть диагностики и управления. На нем находятся датчики температур и т.д.
6.Gigabit Ethernet.
28. Параметры системы IBM Blue Gene/L. Узлы (виды узлов) системы IBM Blue Gene/L. Сети и структуры сетей системы IBM Blue Gene/L. Структура схемы BLL ASIC и схема коммутации портов в ней. Конфигурация торовых колец.
Параметры системы IBM Blue Gene/L
1. Относится к MPP системам кластерного типа.
2. Производительность в полной конфигурации составляет 367 TF, в расширенной 596 TF.
3. Имеет 65526 вычислительных однопроцессорных узлов (Compute Node), каждый процессор имеет 2 ядра с архитектурой IBM PowerPC 440.
4. Система может иметь до 4096 узлов ввода-вывода (I/O Node) и коммуникационные схемы.
5. Узлы системы построены по принципу SoC (Sistem on Chip). Вычислительные узлы и узлы вв/выв реализованы микросхемой BLC (Blue Gene/L Compute) ASIC, а коммуникационные схемы микросхемами BLL (Blue Gene/L Link) ASIC.
6. Конструктивно система состоит из следующих иерархических компонентов:
- BLC ASIC и BLL ASIC
- Compute Card (два BLC + RAM 256MB) и I/O Card (два BLC + RAM 512MB)
- Node Card (16 Compute Card + 0-2 I/O Card), Link Card (24 BLL) и Service Card
- Midplane (16 Node Card + 4 Link Card + 1 Service Card)
- Rack (два Midplane)
- IBM Blue Gene/L в целом (до 64 Rack в полной конфигурации)
7. Шесть сетей:
Внутренние сети – в них участвую вычислительные узлы.
1 – сеть для двух точечных передач (организована по принципу 3D тора)
2 – загрузки узлов и коллективных передач (организована по принципу дерева)
3 – сеть прерываний и барьерной синхронизации (по принципу дерева)
4 – сеть JTAG. Сеть диагностики и управления.
Внешние:
5. - функциональная (Gigabit Ethernet, осуществляет загрузку системы м ввод-вывод)
6. – диагностики и управления (Gigabit и Fast Ethernet, связана с JTAG)
Структура сети коллективных передач: Структура сети i/o, диагностики и управления:

 Структура
схемы BLL
ASIC
Структура
схемы BLL
ASIC
 handling-
обработка особой ситуации;
handling-
обработка особой ситуации;
Схема коммутации портов (все порты 21 канальные с 0 по 20):
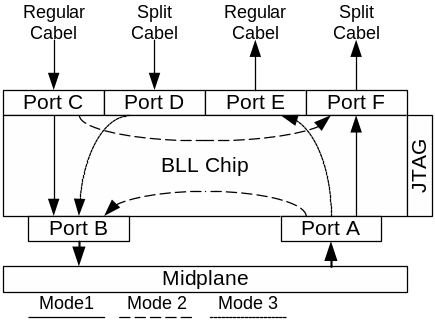
Конфигурирование торовых колец:

P.S. я незнаю что такое DPP и Delay/instage