

Высокопроизводительные вычислительные системы. Цели применения ВВС. Способы повышения производительности ВС. Цели применения ВВС. Проблемы внедрения параллельных ВС. Закон Гроша. Гипотеза Минского. Законы Амдала.
ВВС – это системы, у которых производительность выше, чем текущий уровень других основных систем. Самые высокопроизводительные системы называются – суперкомпютеры.
Цели применения ВВС:
Повышение производительности вычислений в единицу времени.
Увеличение объема данных обрабатываемых в единицу времени
Повышение точности вычислений
Повышение надежности вычислений за счет функционального резервирования.
Применение ВВС |
||
Цель применения |
Сферы применения |
|
Улучшаемый фактор |
Цель улучшения данного фактора |
1) наука (научные расчеты, создание имитационных моделей, математическое прогнозирование, экспертные системы. 2) промышленность/оборона (АСУ, системы принятия решений, системы массового обслуживания, системы слежения, БД). 3) образование: имитационных тренажеров 4) информатика: системы поиска и анализа информации, системы управления БД, системы обработки потоков информации. |
Увеличение скорости вычислений |
- сокращение временных затрат на решение. - создание систем реального времени - повышение оперативности систем управления - повышение точности вычислений
|
|
Увеличение объема обрабатываемых данных |
- повышение разрядности данных - увеличение масштаба вычислений - повышение точности вычислений |
|
Повышение надежности вычислений |
Возможность функционального резервирования. Улучшение качества расчетов за счет детализации и увеличения числа экспериментов. |
|
Направления повышения производительности ВС.
Улучшение элементной базы
Усовершенствование структуры и алгоритма функционирования аппаратуры ВС.
Введение параллелизма и конвейеризации (повышение разрядности устройств, введение
нескольких процессоров, АЛУ, ядер)
Устранение «узких мест» в системе (память, каналы связи)
Усовершенствование системы управления ВС, в т.ч. ОС.
Разработка эффективного ПО.
П роблемы
внедрения ПВС (параллельных ВС).
роблемы
внедрения ПВС (параллельных ВС).
Закон Гроша
Производительность процессора увеличивается пропорционально квадрату его стоимости.
Причины нарушения закона Гроша.
- ограничение скорости распространения электрического сигнала в схеме.
- для решения необходимо сократить путь прохождения сигнала, что приводит к появлению технологических проблем (отвод тепла, размеры)
- для снижения потребляемой мощности понижают напряжение, следовательно, увеличивается влияние помех.
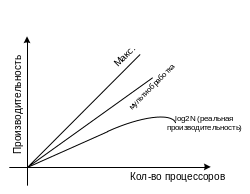
Гипотеза Минского (N-количество процессоров) |
Законы Амдала
|
Производительность многопроцессорных ВС растёт по закону Log2N
|
- Производительность ВС, состоящей из связанных между собой устройств, в общем случае определяется самым непроизводительным устройством. - Пусть система состоит из S одинаковых простых универсальных устройств. Предположим, что при выполнении параллельной части алгоритма все S устройств загружены полностью. Тогда максимально возможное ускорение равно R=S/(betta*S+(1-betta)), betta=n/N – доля последовательных вычислений. - При любом режиме работы системы ускорение не может превзойти 1/betta. - R= S/(betta*S+(1-betta)+c), c-коэффициент сетевой деградации. С=(L*tc)/(N*t), где L – число операций связи, tc- время выполнения одной операции связи, t – продолжительность каждой операции.
|
Модели программирования систем класса mimd. Стандарт mpi. Операции поддерживаемые и неподдерживаемые в mpi. Содержимое реализации стандарта mpi. Структура mpi-программы.
Модели программирования:
1. SPSD – single program single data
2. MPSD – multiple program single data (unix-программа с общей памятью)
3. SPMD – single program multiple data
4. MPMD – multiple program multiple data
Стандарт MPI.
MPI – Message Passing Interface – интерфейс приема сообщений.
MPI – стандарт на программный инструментарий для обеспечения связей между ветвями параллельной программы. Стандарт MPI определяет синтаксис, семантику библиотечных функций, используемых при написании параллельных программ с передачей сообщений на языках Fortran, C, C++. MPI предоставляет единый механизм взаимодействия ветвей параллельной программы, независимо от машинной архитектуры, расположения ветвей по процессорам и API операционных систем. MPI поддерживает архитектуры: одно- и многопроцессорные. С общей и распределенной памятью. Программы, использующие MPI, легче отлаживаются и быстрее переносятся на другие платформы, в идеале просто перекомпиляцией. Операции, поддерживаемые в MPI:
1.Операции взаимодействия процесс-процесс (двухточечная передача) MPI_Send
2.Коллективные операции. MPI_Bast – пересылка от одного ко всем.
3.Операции над группами процессов (пример операции над группами: создание, пересечение, сравнение и т.д.).
4.Операции над областями связи.
5.Операции над топологиями процессов.
6.Операции с типами данных.
7. Вспомогательная синхронизация и замеры времени.
Комментарий в лекции не было. Топология используется программистом для более удобного обозначения процессов, и таким образом, приближения параллельной программы к структуре математического алгоритма. Кроме того, топология может использоваться системой для оптимизации распределения процессов по физическим процессорам используемого параллельного компьютера при помощи изменения порядка нумерации процессов внутри коммуникатора. В MPI предусмотрены два типа топологий: Операции не поддерживаемые в MPI:
Явные операции с разделяемой памятью.
Средства конструирования программ.
Средства отладки.
Операции с большей поддержкой ОС.
Функции ввода-вывода на периферию.
Содержимое реализации MPI:
Библиотека функций
Загрузчик приложений
Система обеспечения коммуникаций
Структура MPI программы.
1) #include “mpi.h” //подключение библиотеки MPI
2) Часть программы до инициализации MPI. Здесь нельзя вызывать функции MPI, кроме функции:
Int MPI_Initialize(int *flag) //возвращает код ошибки, в качестве параметра возвращает адрес
Пример:
int a;
MPI_Initialized(&a);
С помощью этой функции процесс проверяет, была ли проведена инициализация MPI или еще нет. Инициализация MPI производиться путем вызова функции:
int MPI_Init(int *argc, char ***argv);
argc – рассылка числа параметров командной строки
argv – рассылка массива параметров
3) Работа с MPI функциями. По окончании вызывается функция
int MPI_Finalize();
Она завершает работу программы с MPI.
4) Часть программы, где работают с функциями MPI вызывать MPI_Finalize() нельзя, но можно
int MPI_Finalized(int *flag);
Она аналогична проверяет была ли выполнена команда MPI_Finalize или нет.