

Лекция №10 «Технология поиска информации»
Исходное множество элементов
X={Х1(a),Х2(a),…Хn(a)}
Эталон е(а)
Задача поиска: существует ли
Xi(a) э Х:Хi(a)=e(a),i=1,N
Разнообразие задач поиска существенно зависит от того каковы принципы сравнения объектов. В некоторых случаях сложность сравнения может превышать сложность поиска.
Вторым, существенно важным фактором, является число элементов исходного множества. Если оно велико требуется предпринимать специальные приемы для его представления.
В стандартной библиотеке с++ имеется библиотека алгоритмов <algorithm> она включает в себя специальные структуры данных и функции, реализующие определённые классы алгоритмов. Одним из этих классов является поиск.
Последовательный поиск в массиве.
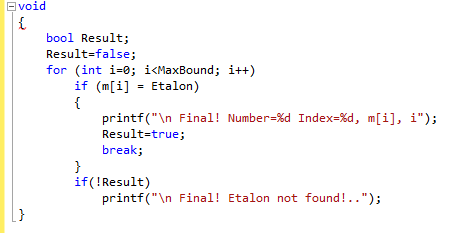
Функции и структуры данных в библиотеке направлены на максимально общее представление о процессе поиска и объектах, которые подлежат обработке.
Библиотека использует следующие абстракции:
- Контейнер. Это объект или класс объектов, который используется для хранения других объектов. Свойство и методы контейнеров позволяют манипулировать их содержимым независимо от того, как это содержимое выглядит.
- Итератор. Это объект, который используется для доступа к элементам контейнера. Итераторы можно считать обобщением понятий указателя или индекса в массиве.
- Алгоритм. Это функция, реализующая некоторый сценарий обработки информации. Все алгоритмы используют контейнеры и итераторы.
Последовательный поиск алгоритмом find.
Один из простейших контейнеров является vector. При описании вектора указывается тип его элементов. Он может быть любым, в том числе вектором и любым другим контейнером. При описании переменной вектора задается ее размер. С помощью методов вектора можно этот размер произвольно изменять, т.е. векторы схожи на динамические массивы.

Алгоритм find это функция, принимающая три параметра:
- Итератор начала последовательности в контейнере
- Итератор конца последовательности в контейнере
- Значение эталона для поиска.
Алгоритм возвращает итератор найденного объекта в противном случае если не найден, его значение равно итератору конца контейнера.
Если перегрузить оператор сравнения ==, то алгоритм будет использовать именно его для выяснения факта совпадения. В библиотеке есть несколько вариантов алгоритмов поиска. В частности алгоритм find_end позволяет искать в одной последовательности другую последовательность. Границы последовательностей задаются итераторами. Результатом поиска является начало одной последовательности найденной в другой последовательности.
Алгоритм find_end с предикатом сравнения.

Многие алгоритмы в качестве дополнительного параметра могут использовать предикат сравнения заданный пользователем. Предикат – это функция, которая возвращает истинное значение, если сравниваемые элементы в каком-то смысле эквиваленты.
Например, элементы могут быть эквиваленты, если они кратны 5.
Имя функции задается алгоритмом в качестве дополнительного параметра.
Лекция №11 «Технология поиска»
В контейнер вектор могут быть помещены элементы произвольного типа. В этом случае должно быть уточнено то, каким образом выполняется сравнения элементов. Это реализуется путем перегрузки оператора сравнения.
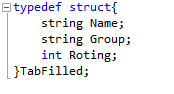
В языке существует ключевое слово typedef, позволяющее вводить наименования (синонимы) для любых созданных типов. Например, для структур введение наименования с помощью typedef упрощает описания переменных.

Перегрузка оператора
== (сравнения)
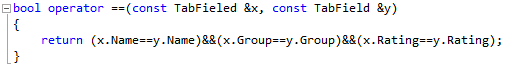
Синтаксически перегрузка оператора подобно описанию функции должно размещаться в программном коде до использования оператора.
В отличие от описания функций перегрузка оператора содержит ключевое слово оператор. Для двуместных операторов в качестве параметров указывается переменная справа и слева от знака оператора.
Все операции с указанными типами в программном коде, будут перегружены при компиляции.
Бинарный поиск. В основе бинарного поиска лежит идея сравнения атрибута поиска и принятие решения об отбрасывании части последовательности, в котором заведомо отсутствуют искомые элементы. Это возможно только для отсортированных последовательностей.
При бинарном поиске время нахождения элемента пропорционально логарифму числа элементов. Математически сложность поиска по времени выражается
как Тбин=о(log N) где N число элементов. Сложность последовательного поиска это Тпосл=о(N). Таким образом, бинарный поиск обладает преимуществом, которое растет с увеличением N. Функция «о» показывает асимптотическую скорость роста.
Пример кода для бинарного поиска

Алгоритм (binary_search) выполняет бинарный поиск и принимает 3 параметра:
- итераторы начала последовательности
- итераторы конца последовательности
- искомый элемент
Алгоритмы бинарного поиска применимы для любых элементов контейнеров подобно алгоритмам последовательного поиска. В частности требуется перегрузка оператора сравнения, если тип не является встроенным.
Самой главной особенностью применения бинарного поиска является необходимость сортировки контейнера. Практика показывает, что время сортировки занимает значительную долю в общем времени поиска.
Контейнер map. Контейнер map предназначен для хранения элементов представляющих собой пары. В каждой паре первый элемент является ключевым, второй информационный. Значение ключевого элемента является уникальным для текущего содержимого контейнера, т.е. попытка добавления пары с уже использованным ключом является
ошибкой. Поиск нужного элемента контейнера выполняется по значению ключа. Время поиска ведет себя, так же как и в случае бинарного поиска.
В описании переменной контейнера указываются два типа: первый из них является типом ключа, второй типом информационной части. Для поиска в контейнере используется метод find, который принимает один параметр значения ключа. Результат это итератор, указывающий на найденный элемент. Поскольку элемент является парой значений, выделить информационный элемент можно через свойство second значения итератора.
В общем случае при программировании поиска с самого начала учитывают вид исходных данных. Если это отсортированная последовательность, то применяют бинарный поиск. Если последовательность не отсортирована оценивают время ее сортировки. Может оказаться, что оно настолько велико, что целесообразнее использовать последовательный поиск. В том случае, когда данные в систему поступают последовательно имеет смысл помещать их в контейнер map, снабжая уникальным ключом. Любая операция поиска будет выполняться с высокой скоростью.