

Пример 4
Порт в Балтиморе имел большие очереди на разгрузку зерна из судов в течение последних восьми кварталов. Торговый операционный менеджер хочет применить экспоненциальное сглаживание, чтобы посмотреть, как хорошо эта техника работает применительно к тоннажу разгружаемого зерна. Он принимает, что прогноз разгружаемого зерна в первом квартале был 175 тонн. Рассматриваются два значения: α =.10 и α =.50. В следующей таблице показаны детальные расчеты только для α = .10.

* Прогнозы округляются до целых тонн.
Изменение точности для каждой константы сглаживания мы можем рассчитать по абсолютному отклонению и среднему абсолютному отклонению (МАD).

В результате этого анализа константа сглаживания α = .10 является предпочтительной по отношению к α = .50, так как ее МАD меньше.
Наряду со средним абсолютным отклонением (МАD), два других измерителя ошибок в прогнозировании иногда используются. Среднеквадратическое отклонение (МSЕ) — это среднее от квадрата разности между прогнозными и наблюдаемыми значениями. Среднее процентное отклонение (МАРЕ) является абсолютной разницей между прогнозируемыми и наблюдаемыми значениями в процентах к наблюдаемым значениям.
Экспоненциальное сглаживание с трендовым регулированием. Как и другие методы меняющегося среднего, простое экспоненциальное сглаживание не приспособлено к регулированию тренда. Иллюстрируя более сложную модель экспоненциального сглаживания, рассмотрим, что требуется для регулирования тренда. Идея заключается в расчете прогноза простым экспоненциальным сглаживанием, а затем в определении положительного или отрицательного лага в тренде.
Формула имеет вид следующего равенства:
Прогноз, включающий тренд (FITt) =
= Новый прогноз (Ft) + Коррекция тренда (Тt).
Сглаживая тренд, уравнение для коррекции тренда использует константу сглаживания β, так же как в простой экспоненциальной модели использовалась α.
Тt рассчитывается с помощью равенства
![]()
где Тt — сглаженный тренд для периода Г,
Tt - 1 — сглаженный тренд для предыдущего периода;
β — константа сглаживания, которую мы выбираем;
Ft — прогноз простого экспоненциального сглаживания для периода;
Ft - 1 — прогноз для предыдущего периода.
Имеются три шага расчета прогноза с регулируемым трендом.
Шаг 1. Расчет простого экспоненциального прогноза для периода t (Ft).
Шаг 2. Расчет тренда с использованием уравнения
![]()
Для начала шага 2 для первого периода начальное значение тренда должно быть заложено (или как хорошее предположение, или как обзор прошлых данных). После этого рассчитывается тренд.
Шаг 3. Расчет прогноза с регулируемым трендом методом экспоненциального сглаживания по формуле FITt = Ft + Tt.
Пример 5
Большое предприятие использует экспоненциальные сглаживания для прогноза спроса на оборудование для контроля за загрязнением. Считается, что тренд существует.

Константы сглаживания определены значениями α = .2 и β = .4. Предполагаемый начальный прогноз для месяца 1 был 11 единиц.
Шаг 1. Прогноз для месяца 2 (F2) = Прогноз для месяца 1 (F1)+(Спрос месяца 1 - Прогноз для месяца 1):
![]()

Так, простои экспоненциальный прогноз (без учета тренла) для месяца 2 был равен 11,2 единицам, а прогноз с регулируемым трендом был равен 11,28 единицам. В месяце 3 простой прогноз (без учета тренда) был равен 12,36 единицам, а прогноз с регулируемым трендом был равен 12,87 единицам. Естественно, различные значения T1 и β могут давать даже лучшие оценки.
Следующая таблица содержит прогнозы для девятимесячного периода. Рис. 4.3 сравнивает текущий спрос, прогноз без учета тренда (Ft) и прогноз с учетом тренда (FITt).

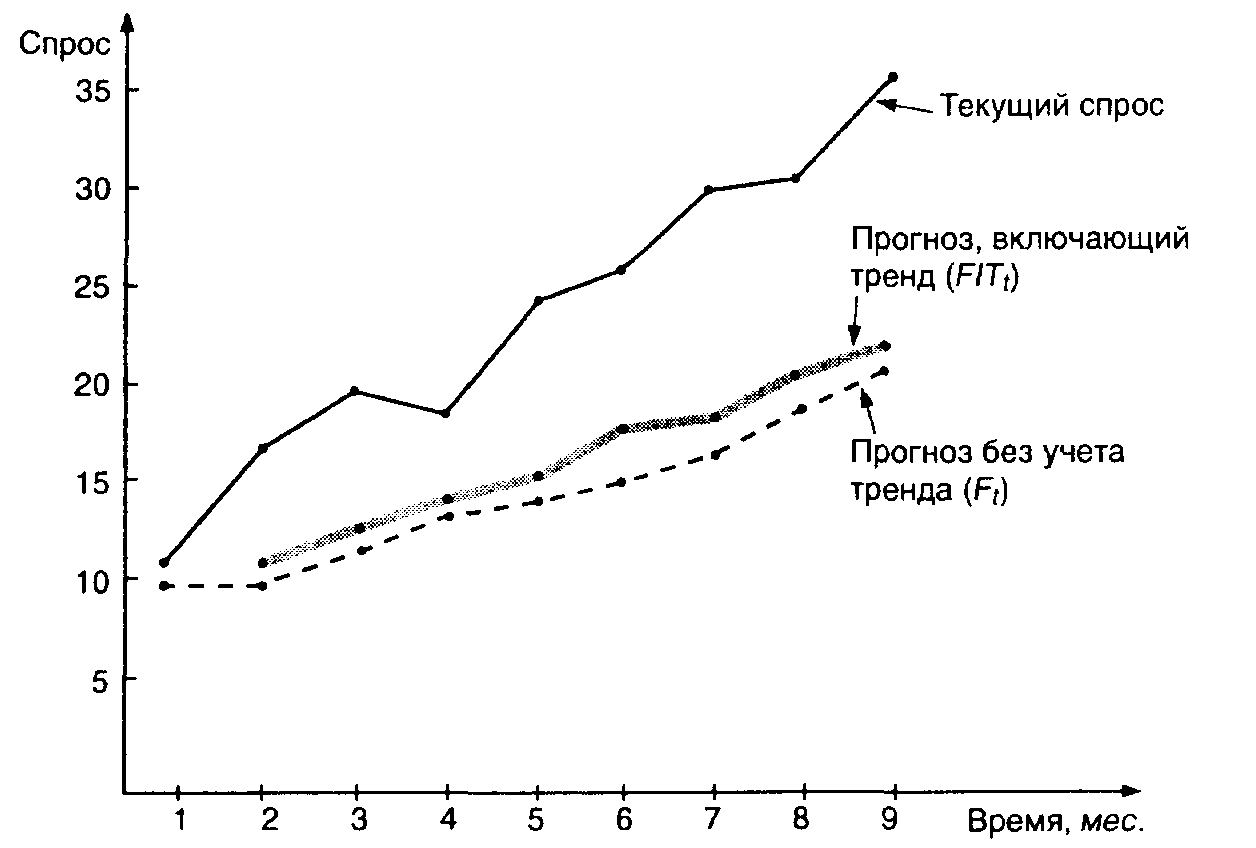
Рис. 4.3. Текущие значения сравнительно с прогнозами
Значение трендовой константы сглаживаются (β похоже на константу α в том, что высокое β делает более представительными текущие изменения в тренде. Низкое β дает меньший вес текущим трендам. Значение р может быть найдено путем определения ошибок и МАО, используемых как измеритель для сравнения.
Простое экспоненциальное сглаживание часто относится к сглаживанию первого порядка, а сглаживание с трендовым регулированием называется сглаживанием второго порядка. Другие модели экспоненциального сглаживания, включая сезонное регулирование и тройное сглаживание, также используются, но они не описаны в данной книге.
Трендовое проектирование. Метод прогнозирования на основе прошлых временных серий, который мы будем обсуждать, называется трендовым проектированием. Этот метод устанавливает линию тренда по серии точек прошлых данных, а затем проектирует линию в будущее для средне- и долгосрочных прогнозов. Ряд математических уравнений-трендов может быть использован (например, экспоненциальные и квадратные), но в данной секции мы будем рассматривать только линейные (прямолинейные) тренды.
Если мы решили развивать линейный тренд линейно точным статистическим методом, то можем применить метод наименьших квадратов. Этот метод позволяет получить прямую линию, которая минимизирует сумму квадратов вертикальных разностей между линией и каждым текущим наблюдением. Рис. 4.4 иллюстрирует метод наименьших квадратов.
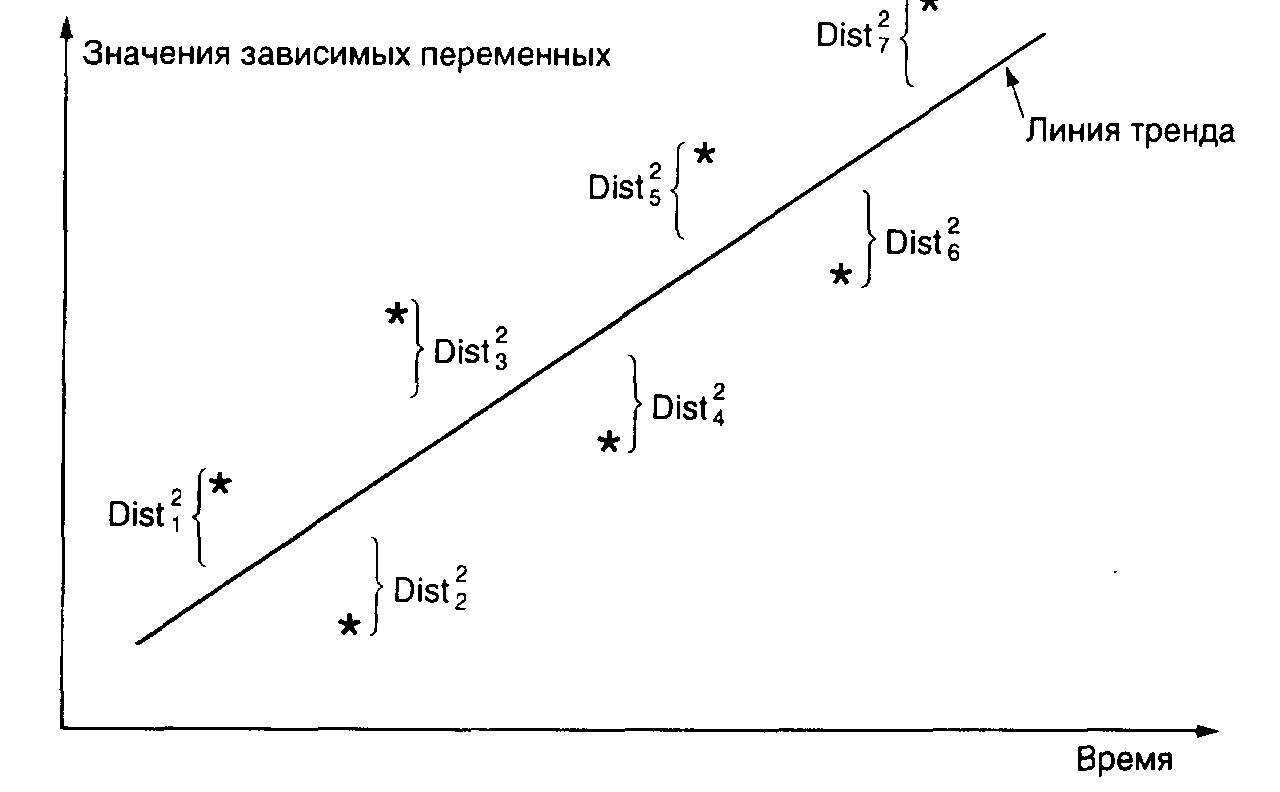
Pнс. 4.4. Метод наименьших квадратов для нахождения лучшей прямой линии (звездочки показывают семь текущих наблюдений или точек данных)
Линия, полученная методом наименьших квадратов, описывается в терминах ее y-значения (высотой, отсекаемой ею на оси у) и ее наклоном (линейным углом). Если мы можем рассчитать отсекаемое y-значение и наклон, то можем описать линию следующим уравнением:
y=а+bх, (4.8)
где у — расчетное значение предсказываемой переменной (зависимой переменной);
а — отрезок, отсекаемый прямой на оси у;
b — наклон линии регрессии (или коэффициент изменения значения у по отношению к изменению значения х);
х — независимая переменная (в данном случае время).
Статистически, имея уравнение, мы можем найти значения а и b для некоторой линии регрессии. Наклон линии регрессии находим так:


![]()
Пример 6 изображает, как использовать этот подход.