

4. Моделирование речи искусственная речь и связанные с ней проблемы
Говорящие машины уже существуют. Словарь их пока небольшой и состоит из слов, произнесенных человеком и записанных на магнитный барабан. Наиболее известный тому пример — говорящие часы, работающие на многих телефонных станциях.
Машины, использующие предварительно записанную речь, довольно дешевы и очень удобны, если число сообщений невелико, но непригодны, если требуется обычная непрерывная речь. Одна из причин состоит в том, что с возрастанием числа хранимых слов хранилище записанных слов становится слишком большим и дорогим. Другой причиной является то, что в разговорной речи одно и то же слово может участвовать в предложениях разного типа, с различными ударениями, интонациями и несколькими вариантами произношения. Поэтому невыгодно использовать непосредственную запись речи для говорящих машин более общего типа. Выгоднее машины, в некотором смысле моделирующие работу голосовой системы человека. Машины, которые не воспроизводят ранее записанную речь, а синтезируют ее, называют «синтезаторами речи».
История синтезаторов речи очень стара. Наиболее ранние были непосредственными копиями человеческого речевого аппарата и использовали воздуходувные меха, язычки и резонаторы. Управляли этими машинами, как правило, вручную, с помощью набора рычагов. Одна из таких машин была построена Вольфгангом фон Кемпелиа в конце XVIII века. Известно, что она очень хорошо имитировала речь, хотя не совсем правильно воспроизводила некоторые звуки. В 1920 году акустическая модель Р. Пэджета произносила целые фразы, например: «Алло, Лондон, вы слушаете?» или «О, Лейла, я люблю Вас!». Для этого автору приходилось руками очень искусно изменять форму резонирующей полости машины.
При дальнейшем моделировании оказалось (как часто бывает при моделировании функций человеческого организма), что воспроизведение человеческой речи исключительно сложно. Развитие говорящих машин стало действительно возможным только с появлением современной электронной техники, которая позволяет достигнуть необходимого уровня сложности.
Убедиться в сложности речевых сигналов позволяют спектрографы или анализаторы спектра. Простейшим прибором для частотного анализа является резонансный частотомер, содержащий ряд упругих стальных пластин с различной частотой собственных колебаний. При подаче на электромагнит этого прибора сигналов речи поле электромагнита возбуждает только ту пластину, собственная частота которой совпадает с частотой исследуемого сигнала.
На рис. 23 показан получающийся таким способом частотно — временной спектр звука сирены с постепенно повышающейся частотой, а на рис. 24 — спектр звука отдельного слова, произнесенного человеком. Как видно из рисунков, звуковые колебания, образующие речь (в отличие от речи автомата — сирены), содержат много составляющих, которые в сумме создают сложную звуковую картину. К сожалению, эти картины очень отличаются не только у различных дикторов, но даже у одного и того же человека в разное время.
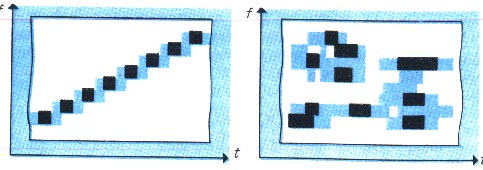
Рис. 23. Спектр звука сирены Рис. 24. Спектр слова, произнесенного человеком
Взгляните на шесть контурных диаграмм английского слова «You» (рис. 25) — и вы убедитесь в этом.

Рис. 25. Контурные диаграммы английского слова "You"
Диаграммы получены от пяти различных людей, только нижние две диаграммы — от одного человека (на диаграммах контурные линии отображают различную интенсивность звучания).