

It_is( X ) :- write( X, “?”), % Механизм диалога
readchar( A ), A = ‘y’.
Когда по какой-либо ветви достигается решение, факт прогноза помещается в динамическую базу данных.
Предикат proverka рассчитан на выполнение четырех проверок, хотя иногда достаточно двух или трех, при этом ответ помещается в базу данных. Однако предикат продолжает свою работу и пытается удовлетворить следующие тесты, что невозможно. В результате первое правило предиката proverka закончится ложно, сработает второй дизъюнкт. Ответ уже находится в динамической базе данных, и извлечь его оттуда несложно.
Отметим, что в этой реализации программы классификации ответы пользователя не сохраняются, однако при некоторой модификации несложно их запоминать и, соответственно, реализовать механизм объяснений. Кроме того, можно рассмотреть случаи, когда лингвистическая переменная принимать не только бинарные значения («снегу много» или «снегу мало»), но и любые дискретные.
Когда правила логически обусловлены, т.е. используются дискретные альтернативные данные (Да/Нет), удается написать достаточно простую программу для получения определенных выводов. Однако возможно применять и непрерывные переменные. Если они носят вероятностный характер, то нужен определенный метод обработки этих вероятностей. Существуют различные подходы к реализации неопределенностей в задачах поиска5.
Один из ранних подходов к представлению неопределенностей использовал теорию вероятностей, позже это механизм был заменен применением так называемого коэффициента определенности импликации, или уверенности (certainty factor, CF):
Если есть S то имеется D с уверенностью CF.
Значения коэффициента определенности лежат в диапазоне [ -1, +1 ].
С другой стороны, признак S тоже может проявиться с некоторой «силой», т.е. имеет свой CF. Правило комбинирования, позволяющее вычислить коэффициент определенности заключения, когда известен коэффициент определенности посылки, лежащей в его основе, записывается так:
CF (заключение) = CF(посылка) * CF(импликация)
Посылка правила может состоять из нескольких атомарных посылок, каждая из которых имеет свой коэффициент определенности. Они могут быть связаны между собой логическим операциями типа И, ИЛИ, НЕ. Принято, что коэффициент определенности посылки равен коэффициенту определенности наименее надежной из посылок:
CF( S1 И S2) = min(CF( S1 ), CF( S2)).
Коэффициент определенности дизъюнкции посылок равен коэффициенту определенности сильнейшей ее части:
CF( S1 ИЛИ S2) = max(CF( S1 ), CF( S2)).
Если сделать допущение, что события независимы друг от друга, программа может быть реализована достаточно просто. Продукционным правилам можно приписать числа, указывающие относительную важность (вес) фактов:
rule(hypothesis A, AND((cond1, CF1), (cond2, CF2), …) .
Для реализации механизма вывода на таких знаниях вполне можно использовать рекурсивный алгоритм, дополненный некоторым способом комбинирования посылок.
3.9. Обработка текстов
В разборе фраз ограниченного естественного языка особенно ярко проявляются преимущества Пролога по сравнению с традиционными процедурными языками программирования. Пролог обладает большими возможностями по сопоставлению объектов с образцом, поэтому данный язык программирования хорошо подходит для обработки текстов и разработки различного рода компиляторов.
В данном разделе продемонстрируем две системы грамматического разбора. Система грамматического разбора – это программа, которая распознает синтаксические объекты в потоке лексем, т.е. реализует какую-либо формальную грамматику. Грамматика представляет систему правил, определяющих принадлежность фразы к языку. Общеизвестны две основные стратегии грамматического разбора: нисходящая (сверху вниз) и восходящая (снизу вверх).
Система нисходящего грамматического разбора базируется на стратегии с обратной цепочкой рассуждений, а система восходящего разбора – с прямой. Следовательно, реализация на Прологе системы нисходящего разбора может быть осуществлена достаточно прямолинейным способом.
Продемонстрируем систему разбора сверху вниз примером простейшего синтаксического анализатора предложений. В описанной системе используется грамматика, которую можно схематически представить так:
предложение --> именная_группа глагольная_группа
именная_группа --> определение существительное
именная_группа --> существительное
глагольная_группа --> глагол существительное
Система нисходящего грамматического разбора начинает работу с принятия некоторой гипотезы, а затем проверяет верность следствий этой гипотезы по данным, содержащимся во входном списке. Первоначальной гипотезой может служить, например, предположение о том, что во входном списке можно обнаружить нетерминал "предложение". В соответствии с грамматическим правилом для нетерминала "предложение" данная гипотеза разбивается на две субгипотезы: на предположения о том, что во входном потоке содержатся группа подлежащего (именная группа) и группа сказуемого (глагольная группа). Эти две гипотезы в свою очередь разбиваются на субгипотезы более низкого уровня. Процесс разделения гипотез на субгипотезы продолжается до тех пор, пока система не встретит терминал (конечный символ, слово из словаря). В этом случае она пытается установить факт наличия терминала в начальной позиции входного списка.
Более важной сферой применения систем грамматического разбора является построение так называемого дерева грамматического разбора в том или ином виде, в котором явно указаны классы объектов и существующие между ними отношения
Пример анализатора, строящего дерево синтаксического разбора для простого английского предложения: "every man that lives loves a woman". Это предложение соответствует следующей грамматике, записанной в БНФ:
<SENTENCE> ::= <NOUN PHRASE> <VERB PHRASE>
<NOUN PHRASE> ::=<DETERMINER> <noun> <RELATIONAL CLAUSE>
<DETERMINER> ::= < > | <determiner>
<RELATIONAL CLAUSE> ::= < > | <relative> <VERB PHRASE>
<VERB PHRASE> ::= <verb> | <verb> <NOUN PHRASE>
Здесь прописными буквами записаны нетерминальные (промежуточные) символы, строчными – терминальные (словарь), вертикальная черта обозначает альтернативы для разбора. Например, глагольная группа <VERB PHRASE> может состоять из одного глагола <verb> или глагола, за которым следует дополнение в форме именной группы: <verb> <NOUN PHRASE> .
Данная грамматика, в частности, разбирает приведенную выше фразу, а также более короткие варианты, в которых могут отсутствовать отдельные группы и члены предложения:
"every man loves a woman", "every man that lives loves", "man loves".
Дерево грамматического разбора нашего предложения:
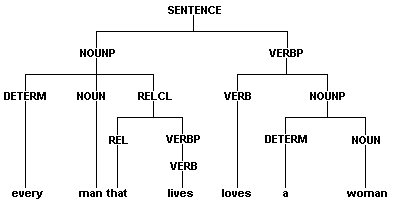
Рис.1. Дерево грамматического разбора предложения
Результат грамматического разбора должен получиться в виде объекта Пролога:
SENTENCE = sent(nounp(determ(“every”), “man”, relcl(“that”, verb(“lives”))),
verbp(“loves”, nounp(determ(“a”),”woman”, none))).
Грамматика, заданная в виде БНФ, переписывается в секции DOMAINS с учетом синтаксиса Пролога:
DOMAINS
DETERM = none ; determ( STRING )
NOUNP = nounp( DETERM, STRING, RELCL)
RELCL = none ; relcl( STRING, VERBP )
VERBP = verb( STRING ) ; verbp( STRING, NOUNP )
SENTENCE = sent( NOUNP, VERBP )
К области DOMAINS добавляется еще одно определение – список строковых величин. В качестве списка строк будет представлено разбираемое предложение, например список ["every”, “man’’, “loves”, “a”, “woman"]:
DOMAINS
TOKL = STRING*
Каждая строка представляет одно слово предложения и называется лексемой (токеном).
Все предикаты, участвующие в грамматическом разборе, делятся на две группы. Предикаты с префиксом is_ относятся к словарю, находят для выделенного слова его грамматическую статью (является ли слово существительным, или глаголом или т.д.) и далее идентифицируют его по словарю.
Предикаты с префиксом s_ выделяют соответствующую грамматическую конструкцию: s_nounp выделяет именную группу, s_verbp – глагольную группу и т.д.:
PREDICATES
s_verbp( TOKL, TOKL, VERBP )
Все предикаты с префиксом s_ имеют три аргумента. Первым аргументом TOKL является входной список лексем (слов), третий аргумент – это название выделенной грамматической конструкции, т.е. то, что удалось выделить из входного списка на данной стадии грамматического разбора. Второй аргумент образован частью списка, оставшегося после того, как из входного списка будет взята разобранная часть предложения.
При записи клозов предикатов с префиксом s_ должны учитываться следующие особенности:
число клозов каждого предиката соответствует количеству их альтернатив в описании DOMAINS;
В первую очередь записываются клозы, имеющие самую сложную реализацию.
Рассмотрим разбор глагольной группы. Поскольку в секции DOMAINS описаны две альтернативы разбора глагольной группы:
VERBP = verb( STRING ) ; verbp( STRING, NOUNP ),
у нас в реализации предиката разбора глагольной группы должно быть два клоза s_verbp. Это следующие предложения:
s_verbp ( [ VERB | TOKL ], TOKL1, verbp( VERB, NOUNP )):–
is_verb (VERB),
s_nounp ( TOKL, TOKL1, NOUNP).
s_verbp ( [ VERB | TOKL ], TOKL, verb( VERB )):–
is_ver ( VERB ).
Первый клоз s_verbp предполагает, что в начале списка слов находится глагол VERB и пытается распознать его по словарю предикатом is_verb (VERB). Если распознавание успешно, из остальной части списка TOKL выделяется именная группа NOUNP, тогда остаток списка после удачного распознавания – список TOKL1, возвращаемый третий аргумент – выделенная глагольная группа verbp(VERB, NOUNP). Второй клоз предиката s_verbp разбирает глагольную группу, состоящую из одного глагола.
В приведенном фрагменте
Полная программа на Прологе:
DATABASE % Слова , которые должны быть распознаны
det( STRING ) % Определитель
noun( STRING ) % Существительное
rel( STRING ) % Предлог