

6.2 Пакет программ statistica
Пакет STATISTICA фирмы StatSoft является интегрированной системой статистического анализа и обработки данных. Он позволяет проводить статистическую обработку данных в широком спектре на высоком профессиональном уровне, но при этом выдвигаются достаточно большие требования к пользователю в отношении теоретической подготовки в области математической статистики. Хотя и новички в статистике смогут выполнить, и, главное, интерпретировать некоторые статистические операции.
STATISTICA состоит из следующих компонент, которые объединены в рамках одной системы:
электронных таблиц для ввода, хранения и изменения данных (Spreadsheet);
электронных таблиц для вывода результатов статистического анализа (Scrooldsheet);
мощной графической системы;
набора специализированных статистических модулей, в которых собраны группы логически связанных между собой статистических процедур;
специального инструментария для подготовки отчетов;
встроенных языков программирования.
После запуска программы появляется пустая электронная таблица в STATISTICA File Server. Затем вводят данные в таблицу; заменяют стандартные названия переменных на требуемые; изменяют формат данных. Здесь же можно выполнить некоторые действия над данными: визуализация данных, основные статистические характеристики данных. Для более сложных действий применяют специализированные модули. Для запуска их требуется выбрать на панели инструментов Module Switcher - Переключатель модулей. Опишем основные статистические модули и их возможности.
Basic Statistics – Модуль Основные статистики и таблицы
Этот модуль включает в себя практически все описательные статистики, группировки, доверительные интервалы; тесты на нормальный закон распределения; расчет корреляционных матриц (размеров до 300 на 300); тесты на независимость признаков; гистограммы; таблицы частот.
Nonparametrics / Distrib. – Модуль Непараметрические статистики и подгонка распределений
Модуль содержит обширный набор непараметрических критериев согласия, в частности, критерий Колмогорова-Смирнова; ранговые критерии Манна-Уитни, Вилкоксона и многие другие.
Модуль позволяет подобрать к исходным данным подходящий закон распределения (13 наиболее известных видов).
Multiply Regression – Модуль Множественная регрессия
В этом модуле строятся зависимости между многомерными переменными; проверяется адекватность моделей; оцениваются и строятся остатки, исследуются мобели на наличие автокорреляции.
Nonlinear Estimation – Модуль Нелинейное оценивание
Этот модуль незаменим, если пользователю требуется составить нелинейное уравнение регрессии, проверить его на адекватность, рассчитать тесноту связи зависимого и независимых факторов.
Перечислим остальные модули:
Time series / Forecasting – Модуль Анализ временных рядов и прогнозирование
Cluster Analysis – Модуль Кластерный анализ
Process Analysis – –Модуль Анализ процессов
Canonical Analysis – Модуль Канонический анализ
Discriminant Function Analysis – Модуль Дискриминантный анализ
Factor Analysis –Модуль Факторный анализ
ANOVA/MANOVA – Модуль дисперсионного анализа
Classification Trees – Модуль Классификационное дерево
Data Management – Модуль Управление данными
Quality Control –Модуль Контроль качества
Более подробная информация о работе с данными в среде STATISTICA содержится в [3 ]
Для примера возьмем задачу о нахождении уравнения множественной регрессии, которая решалась нами средствами пакета Mathcad в пункте 5.8 и в среде Excel в пункте 6.1.
а) Заполняем данными исходную таблицу ( приводим фрагмент таблицы):
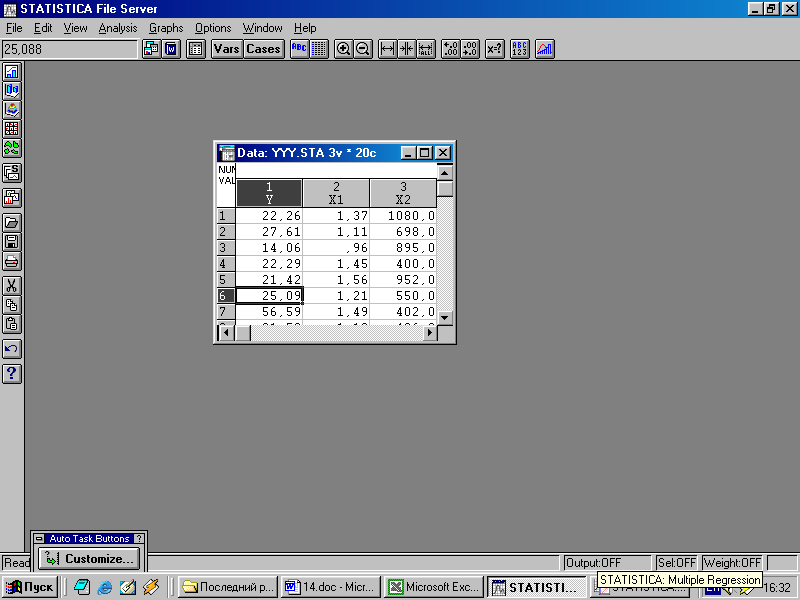
б) Используя переключатель модулей, переходим в модуль Множественная регрессия.
Выбираем зависимые (dependent -У) и независимые (independent X1, X2) переменные (variables). После нажатия кнопки ОК результаты можно вывести в виде таблицы
Regression Summary for Dependent Variable: Y (yyy.sta) |
||||||
R= ,78210169 RІ= ,61168305 Adjusted RІ= ,56599870 |
||||||
F(2,17)=13,389 p<,00032 Std.Error of estimate: 7,3732 |
||||||
|
|
St. Err. |
|
St. Err. |
|
|
|
BETA |
of BETA |
B |
of B |
t(17) |
p-level |
Своб.член |
|
|
10,986 |
12,145 |
0,905 |
0,378 |
X1 |
0,454 |
0,163 |
23,471 |
8,412 |
2,790 |
0,013 |
X2 |
-0,490 |
0,163 |
-0,018 |
0,006 |
-3,007 |
0,008 |
Здесь R=0,782 – корреляционное отношение; RI=0,612 – коэффициент детерминации; F(2,17)=13,389 – наблюдаемое значение критерия Фишера; p<0,00032 – значимость ошибки первого рода, при которой гипотезу об адекватности полученной модели нужно отвергнуть. Малая вероятность говорит о том, что модель адекватная.
Параметры модели содержатся в столбце В. Они совпадают с найденными ранее. В следующих столбцах помещены СКО этих параметров; их t-статистики и уровни вероятностей ошибок. Если выбрать значимость =0,1 , то коэффициенты регрессии при Х1 и Х2 признаются значимыми, свободный член уравнения регрессии признается незначимым. Это значит, что нужно выбрать другую спецификацию модели, возможно без свободного члена.