

2.3. Формування інформаційної бази дослідження
Поняття «інформаційна база» означає набір даних, систематизованих за певними ознаками, а формування інформаційної бази становить цілеспрямований добір відповідних інформативних показників - основного матеріалу для теоретичних узагальнень, аналізу, планування та прийняття оперативних і стратегічних рішень.
У наукових дослідженнях соціально-економічних явищ і процесів використовують два основних види даних: структурні й часові ряди. До першого виду відносяться сукупності одиниць (країн, регіонів, суб'єктів господарювання тощо), властивості яких характеризуються станом на певний момент чи за певний інтервал часу. Другим видом є ряди даних, що характеризують зміну показників одного і того самого об'єкта у часі (динамічні ряди).
Інформаційна база структурних рядів організуються у вигляді матриці даних Ху обсягом пхт, де п - кількість одиниць сукупності (/ = =1,2,...,и ), т - кількість зареєстрованих показників стосовно j-ої одиниці ( і =\,2,...,т ). При формуванні матриці даних доцільно дотримуватися певного стандарту їх розміщення: в рядках розміщувати одиниці сукупності, у стовпцях -показники. Фрагмент матриці даних такого типу наведено в табл. 2.3.1.
Кожний об'єкт дослідження характеризується практично необмеженим числом різнобічних показників. Які саме показни-
ки будуть використані у конкретному дослідженні, залежить від мети та концептуальної моделі предмета дослідження.
Як приклад розглянемо формування інформаційної бази для аналізу прибутковості комерційних банків. Кожен комерційний банк є підприємством і, відповідно, його цільовою функцією є отримання прибутку при менших витратах і з мінімальним ризиком. Прибутковість за своєю суттю є характеристикою ефективності ведення банком справ, віддачі наявних у нього ресурсів. На прибутковість банку чинить вплив багато як зовнішніх, так і внутрішніх факторів, але визначальними з-поміж них є внутрішні: зважена діяльність в умовах ризику та ефективне управління активами і витратами. Якщо «доходи > витрат», банк має прибуток, якщо «витрати > доходу», - банк несе збитки.
Основний показник, за яким оцінюється банк, - його активи. Саме за величиною активів НБУ складає рейтинг банків і поділяє банки на групи: найбільші, великі, середні, малі. Важливим показником діяльності банків є також його власний капітал. Активи і власний капітал взаємопов'язані:
Сумарні активи = сумарні пасиви + власний капітал.
Показники прибутковості визначаються відношенням прибутку до активів чи капіталу.
Прибутковість активів ROA свідчить про ефективність структури активів та їх використання
ROA = Прибуток / Активи.
Для співвласників банку важливим є показник доходності капіталу - норма прибутку на акціонерний капітал ROE
ROE = Прибуток /Акціонерний капітал.
Тобто показник прибутковості активів характеризує ефективність використання усіх ресурсів, якими розпоряджається банк, а показник доходності капіталу - ефективність використання коштів співвласників банку. Виходячи з того, що обидва показники важливі для оцінки результатів діяльності банку, в
Розділ 2. Інформаційне забезпечення наукових досліджень
с воїх опублікованих звітах, які розраховані на потенційних акціонерів і клієнтів, банки наводять обидва показники.
Капітал банку формується переважно з акціонерного капіталу і виступає як гарантійний фонд покриття можливих витрат, тому важливо оцінити ступінь покриття активів за рахунок акціонерного капіталу
Мультиплікатор акціонерного капіталу = Активи /Акціонерний капітал.
Чим вище значення мультиплікатора, тим менший розмір акціонерного капіталу і тим вищий потенційний ризик втрат. Для середнього банку мультиплікатор становить 14—15%, для великого - 20-25%. За означенням виконується співвідношення
ROE = ROA x Мультиплікатор акціонерного капіталу.
Отже, власний капітал є своєрідним гарантом безризикової діяльності банку, забезпечує його платоспроможність та фінансову стійкість.
Ще одним поширеним показником є норма прибутку на капітал в цілому
Прибутковість капіталу = Прибуток /Капітал.
Цей показник збігається з нормою прибутку на акціонерний капітал ROE, якщо капітал банку повністю належить власникам. При значній частці депозитів банк може мати високу норму прибутку на акціонерний капітал і низьку прибутковість капіталу. Такий банк з точки зору власників функціонує ефективно, оскільки забезпечує високу норму прибутку на капітал, але стосовно вкладників його діяльність досить ризикова. За світовими стандартами рівень прибутковості капіталу 13-16% вважається нормальним.
До показників прибутковості банків відносять також (дохо-дну) маржу. Розрахунок її ґрунтується на співвідношенні доходів та витрат з активами, які приносять прибуток:
Маржа = (Доходи - Витрати) /Активи, що приносять прибуток.
45
 За
світовими стандартами маржа на рівні
3% свідчить про те,
що банк обслуговує переважно суб'єктів
господарювання (компанії), 6% - що банк
більше уваги приділяє кінцевому
споживачеві
(дорожчому споживчому кредитові). Низький
рівень маржі показує, що банк залучає
дорогі депозити і бере участь в активних
операціях з низькою прибутковістю та
ризиком.
За
світовими стандартами маржа на рівні
3% свідчить про те,
що банк обслуговує переважно суб'єктів
господарювання (компанії), 6% - що банк
більше уваги приділяє кінцевому
споживачеві
(дорожчому споживчому кредитові). Низький
рівень маржі показує, що банк залучає
дорогі депозити і бере участь в активних
операціях з низькою прибутковістю та
ризиком.
Застосування наведених показників у комплексі дозволить отримати всебічну характеристику прибутковості банків. Необхідна інформація для розрахунку показників прибутковості міститься в балансах банків та звітах про прибутки і збитки. Основні показники публікуються (табл. 2.3.1).
Таблиця 2.3.1. Первинні дані для аналізу прибутковості комерційних банків станом на 01.04.2003 р.
Комерційний банк |
Активи, млн. грн. |
Усього зобов'язань, млн. грн. |
Власний капітал, млн. грн. |
Чистий прибуток банку, тис. грн. |
Прибутковість, в% |
|
активів ROA |
капіталу ROE |
|||||
«Аваль» |
6529 |
5925 |
604 |
892 |
0,014 |
0,147 |
Промінвест-банк |
5875 |
5029 |
846 |
17769 |
0,302 |
0,353 |
«Фінанси і кредит» |
985 |
913 |
73 |
957 |
0,097 |
0,105 |
Вабанк |
592 |
516 |
77 |
2385 |
0,403 |
0,462 |
«Мрія» |
494 |
434 |
60 |
2190 |
0,443 |
0,505 |
«Аркада» |
169 |
116 |
53 |
1858 |
1,158 |
1,602 |
Джерело: Вісник НБУ. - 2003. - № 6. - С. &-21.
Якщо явище вивчається в динаміці, то в рядках матриці доцільно розміщувати часову ознаку / - дати, періоди. Матриця первинних даних має розмір q х т , де q - календарний термін періоду з певними квантами часу (рік, квартал, місяць, доба тощо). В табл. 2.3.2 наведено динамічні ряди цін на золото на світовому ринку в серпні 2002 р. Котирування відбивають чотири
Розділ 2. Інформаційне забезпечення наукових досліджень
ціни золота: ціну відкриття і закриття торгів, максимальну і мінімальну ціну протягом торговельного дня.
Такого типу біржова інформація потрібна для аналізу і прогнозування кон'юнктури ринку. Ціна золота, як і будь-яка інша ціна, визначається на ринку через взаємну гру пропозиції і попиту. Вона постійно змінюється, коливається, утворюючи цикли коливань з різними періодами і амплітудою. За даними таблиці амплітуда денної ціни золота змінювалася від 1,35 USD (30.08) до 9,2 USD (19.08). Щодо коливань ціни за днями торгів, то в означений період вони не перевищили денної амплітуди, і тенденція до зростання чи зменшення ціни золота не простежується.
Таблиця 2.3.2. Динаміка котирувань золота на світовому ринку, USD за 1 тройську унцію (Bid)
Дата |
Курс відкриття |
Максимальний курс |
Мінімальний курс |
Курс закриття |
08.08.2002 |
314,1 |
314,4 |
310,25 |
310,4 |
09.08.2002 |
310,6 |
314,95 |
308,15 |
314,35 |
12.08.2002 |
313,3 |
317,8 |
313,25 |
314 |
13.08.2002 |
314 |
315,4 |
313,4 |
315,4 |
14.08.2002 |
315,25 |
317,4 |
310,9 |
311,4 |
15.08.2002 |
311,3 |
315,85 |
311,25 |
314,45 |
16.08.2002 |
314,95 |
315,25 |
312,25 |
313,75 |
19.08.2002 |
313,5 |
313,6 |
304,4 |
306,5 |
20.08.2002 |
306,8 |
309,7 |
306,55 |
308,8 |
21.08.2002 |
308,9 |
309,55 |
306,25 |
307,75 |
22.08.2002 |
307,6 |
307,8 |
304,7 |
306,8 |
23.08.2002 |
306,7 |
307,25 |
304,1 |
306,75 |
26.08.2002 |
307,1 |
310,45 |
306,4 |
309,2 |
27.08.2002 |
309,05 |
312,95 |
308,2 |
312,5 |
28.08.2002 |
312,2 |
312,4 |
309,3 |
309,9 |
29.08.2002 |
310 |
313,75 |
309,55 |
313,75 |
30.08.2002 |
314 |
314,45 |
313,1 |
313,2 |
Із становленням інформаційного суспільства підвищуються вимоги до інформаційного обслуговування, ускладнюються інформаційні запити конкретних споживачів, створюються і розвиваються ринки інформаційних продуктів та послуг. В Україні головним джерелом інформації виступають Держкомстат України, біржі, банки, юридичні центри, агенції новин, зарубіжні компанії.
З метою забезпечення прозорості статистичних даних про соціально-економічне становище країни 10.01.2003 р. Україна приєдналася до Спеціального стандарту поширення даних МВФ. Показники її економічного та фінансового розвитку розміщуються в Інтернеті на Web-мторінці Держкомстату в розділі «Спеціальний стандарт поширення даних» і на Web-сайті МВФ за адресою: http://dsbb.inf.org.
У глобалізованому світі інформації щодо окремих країн не бракує. Загальновизнаним джерелом міжнародної статистики, яке відображає всі аспекти міжнародних та національних фінансів, є щомісячний статистичний збірник МВФ - International Financial Statistics (IFS). Світовий банк пропонує базу даних по 200 країнах за період з 1960 р.
У наявних базах даних містяться цифри, факти, відомості щодо окремих одиниць досліджуваного об'єкта, характеристики яких мінливі у часі й просторі. Це так звана «статистична сировина», яку необхідно належним чином обробити, щоб сформулювати певні наукові висновки. Працювати з масою неузагаль-нених даних - все одно, що «блукати у лісових хащах без компаса»'. Лише систематизація, приведення даних до певного порядку, узагальнення одиничних фактів дозволить виявити типові риси і закономірності, які притаманні досліджуваному явищу в цілому, уможливить його подальший аналіз.
Розділ 3. АНАЛІЗ ДАНИХ:
МЕТОДИ, РЕЗУЛЬТАТИ
3.1. Систематизація та узагальнення емпіричних даних
У наукових дослідженнях термін емпіричні дані означає інформацію, результати аналізу якої є основою для наукових висновків і прийняття рішень. Щоб розкрити найістотніші особливості масового явища в цілому чи окремих його складових та сформулювати певні наукові висновки, масові емпіричні дані піддаються систематизації та узагальненню. Комплекс послідовних дій по узагальненню даних включає їх зведення, упорядкування й класифікацію, визначення типових рівнів явищ, оцінювання ступеня варіації.
Класифікація (типологія, групування) - це поділ сукупності на однорідні в певних межах групи одиниць. Саме однорідність (однотипність) забезпечує необхідну для узагальнення порівнянність даних, змістовність і реальну значущість узагальнюючих показників. Ідея класифікації сягає у далеке минуле. Дж. Бер-налл посилається на роботи Арістотеля, який увів чи, принаймні, кодифікував спосіб класифікації предметів, оснований на подібності й відмінності.
За традиційною схемою класифікації із множини ознак, які описують явище, добираються розмежувальні, і відповідно до значень цих ознак сукупність поділяється на групи та підгрупи. Головний принцип класифікацій ґрунтується на двох положеннях:
в один клас (групу) об'єднуються певною мірою схожі еле менти;
ступінь схожості елементів, що належать до одного кла су, значно вищий, ніж елементів, які належать до різних класів.
 Наприклад,
інвестиційні агенції, які постійно
аналізують рівень портфельного ризику
цінних паперів (Standart
& Poors, Moody's та
ін.), поділяють їх на класи за ступенем
надійності. Оцінки Standart
& Poor's позначаються
великими літерами латинського
алфавіту: ААА, АА, А, ВВВ, ВВ, В, ССС, СС,
C...D.
Цінні
папери категорій ААА...А мають високий
рівень платоспроможності
і через те найменш ризикові; для цінних
паперів категорій
ВВВ...ВВ характерна середня імовірність
сплати процентів і основної суми боргу,
для категорій В...СС - поступове
наростання ймовірності неплатежів, для
С - несплата процентів, а категорії
DDD...D
не
забезпечують повернення навіть
номінальної вартості.
Наприклад,
інвестиційні агенції, які постійно
аналізують рівень портфельного ризику
цінних паперів (Standart
& Poors, Moody's та
ін.), поділяють їх на класи за ступенем
надійності. Оцінки Standart
& Poor's позначаються
великими літерами латинського
алфавіту: ААА, АА, А, ВВВ, ВВ, В, ССС, СС,
C...D.
Цінні
папери категорій ААА...А мають високий
рівень платоспроможності
і через те найменш ризикові; для цінних
паперів категорій
ВВВ...ВВ характерна середня імовірність
сплати процентів і основної суми боргу,
для категорій В...СС - поступове
наростання ймовірності неплатежів, для
С - несплата процентів, а категорії
DDD...D
не
забезпечують повернення навіть
номінальної вартості.
У 2003 p. Standart & Poor's підтвердила кредитний рейтинг України по довгострокових і короткострокових зобов'язаннях в іноземній і національній валюті на рівні «В»/ стабільний.
У безмежній розмаїтості властивостей окремих елементів будь-якого об'єкта дослідження завжди можна виявити певну кількість груп чи типів. Так, суб'єкти господарювання об'єднуються у групи за видами економічної діяльності, за формами власності, за розміром, за прибутковістю тощо. На основі зведених за групами даних можна здійснити порівняння груп, визначити їх характерні риси та особливості, оцінити роль кожної групи у загальному підсумку, виявити причини міжгрупових відмінностей. Групувальною ознакою може бути будь-який показник. Залежно від складності масового явища (процесу) та мети дослідження групувальних ознак може бути дві й більше.
Аналітичні можливості статистичних методів зведення та групування поглиблюються завдяки використанню компактних та раціональних форм подання результатів узагальнення інформації. Такими формами є статистичні ряди, таблиці, графіки.
Статистична таблиця - це система рядків і граф, на перетині яких утворюються клітинки, призначені для цифрової інформації. Ліві бічні та верхні клітинки призначені для словесних
заголовків. Узагальнені дані стосовно певної класифікаційної позиції чи групи розміщуються в одному рядку чи в одній графі, що уможливлює порівняння, зіставлення та аналіз показників за різними групами, дає підстави для тих чи інших висновків. Основний зміст даних таблиці вказується в її назві. Так, за даними табл. 3.1.1 можна зробити висновок про абсолютний розмір і питому вагу кожного типу електростанцій у загальному обсязі виробництва електроенергії. Основні виробники електроенергії -теплові та атомні електростанції.
Таблиця 3.1.1. Виробництво електроенергії в Україні у 2003 р.
|
Млрд. |
В % до |
|
кВт-год |
підсумку |
Вироблено електроенергії всього |
180,3 |
100 |
У тому числі: |
|
|
атомними електростанціями |
81,4 |
45,2 |
тепловими електростанціями |
89,5 |
49,6 |
гідроелектростанціями |
9,4 |
5,2 |
Джерело: Послання Президента України до Верховної Ради України. Про внутрішнє і зовнішнє становище України у 2003 р. - К., 2004.
В аналізі співвідношення окремих груп і ролі кожної з них у загальному підсумку значну роль відіграють відносні величини структури - частки dj, де у - номер групи (j = 1, 2, ..., т ). Сума
часток для т груп дорівнює Vfl^ =1 або 100 %.
і
З плином часу частки окремих груп змінюються, що свідчить про структурні зрушення. Шляхом порівняння часток можна простежити зміни в структурі явищ, скажімо, в структурі господарюючих суб'єктів за формами власності, у віковій і професійній структурі працюючих, в асортименті товарного ринку, у структурі витрат домогосподарств тощо. Різниця між частками поточного і базисного періодів (dfji _ dp) вимірюється процентними пунктами (п.п.). Найпростішою узагальнюючою мірою інтенсивності структурних зрушень у цілому по сукупності, слугує середня з


 модулів
відхилень часток - лінійний коефіцієнт
структурних зрушень:
модулів
відхилень часток - лінійний коефіцієнт
структурних зрушень:
т
Ys\dn-dA
/>-! , (3-І)
т
де т - кількість груп чи складових, на які поділяється сукупність.
Як приклад, розглянемо структуру фінансового забезпечення наукових і науково-технічних робіт (далі - ННТР) в Україні. Основними джерелами фінансування ННТР є держбюджет, кошти вітчизняних та іноземних замовників. Останнім часом у структурі фінансового забезпечення ННТР відбуваються певні зміни, що видно за даними табл. 3.1.2.
Таблиця 3.1.2. Структура загального фінансування ННТР
в Україні
Джерела фінансування |
У % до підсумку |
Структурні зрушення, процентні пункти |
Модуль структурних зрушень |
|
1995 |
2001 |
|||
Держбюджет |
37,6 |
28,1 |
-9,5 |
9,5 |
Кошти місцевих бюджетів |
|
0,5 |
0,5 |
0,5 |
Позабюджетні фонди |
3,9 |
0,9 |
-3,0 |
3,0 |
Власні кошти |
2,2 |
9,2 |
7,0 |
7,0 |
Кошти замовників України |
35,8 |
33,0 |
-2,8 |
2,8 |
Кошти іноземних замовників |
15,6 |
25,0 |
9,4 |
9,4 |
Інші джерела |
4,9 |
3,3 |
-1,6 |
1,6 |
Разом |
100,0 |
100,0 |
0 |
33,8 |
Джерело: Послання Президента України до Верховної Ради України. Про внутрішнє і зовнішнє становите України у 2001 р. - К., 2002.
У 2001 р. порівняно з 1995 р. зменшилася частка фінансування ННТР за рахунок видатків держбюджету, позабюджетних коштів і коштів вітчизняних замовників, натомість зросла частка власних коштів і коштів іноземних замовників. Розрахований за даними табл. 3.2 лінійний коефіцієнт структурних зрушень свідчить, що у середньому за цей період частки джерел фінансування ННТР змінилися на 4,8 пункта:
/ -33'8-48
у - ~г- - 4>8 •
Різновидом групування є упорядкований поділ одиниць сукупності за зростанням чи зменшенням значень групувальної ознаки, який називається варіаційним рядом розподілу. Кожна j-'i група такого ряду має два елементи:
значення групувальної ознаки - варіанту х,;
абсолютну або відносну чисельність одиниць у групі, тобто частоту^ або частку dj.
При складанні варіаційного ряду розподілу постає питання про кількість груп та межі кожної з них. Кількість груп залежить від ступеня варіації групувальної ознаки та обсягу сукупності. Якщо групувальна ознака неперервна (стаж роботи працівника) або дискретна зі значною варіацією (кількість працюючих на підприємстві), діапазон варіації розбивається на інтервали, які власне і утворюють каркас групувань1.
На практиці формування груп найчастіше здійснюється за принципом рівності інтервалів. Ширина рівного інтервалу залежить від діапазону варіації ознаки х та обґрунтованої кількості груп т:
; _ max "^min /--j -j\
ТП
Визначаючи межі інтервалів, ширину h доцільно округлювати, самі межі слід позначати з такою точністю, щоб розподіл елементів сукупності по групах був однозначним. Якщо діапазон
варіації групувальної ознаки надто широкий і розподіл значень нерівномірний, можна застосувати нерівні інтервали, сформувавши їх так, щоб ширина кожного наступного інтервалу була в k разів більша (менша) за попередній.
Часто перший та останній інтервали (або один із них) відкриті, тобто мають лише одну межу (верхню чи нижню). За допомогою відкритих інтервалів усі крайні значення варіюючої ознаки зводяться в одну групу, завдяки чому групування виглядає компактним.
У табл. 3.1.3 подано ряд розподілу 124 комерційних банків за розміром кредитно-інвестиційного портфелю (далі - КІП). Кожна 7-а група представлена інтервалом значень розміру КІП (іс •*<£.)• Частоти^ показують, скільки банків мають той чи інший розмір КІП, частки dj характеризують вагу відповідної групи. Так, КІЛ кожного четвертого банку (31 із 124) не перевищує 1 млн. грн., а кожного п'ятого банку (20% від загальної кількості) - становить 10 млн. грн. і більше.
В аналізі рядів розподілу, окрім групових частот (часток), використовуються також кумулятивні, які визначаються шляхом послідовного об'єднання груп і підсумовування відповідних їм частот (часток). Кумулятивні частоти сит/, і частки cum dj показують ту частину сукупності, у якій значення показника не перевищує певної межі (в інтервальному ряду це верхня межа відповідного інтервалу Xj).
Таблиця 3.1.3. Розподіл комерційних банків за розміром кредитно-інвестиційного портфеля
КІП, млн. |
Кількість |
В % до |
Кумулятивні |
|
грн. */ |
банків /, |
підсумку 4 |
частоти, cumfj |
частки, cum dj |
До 1 1-5 5-10 10 і більше |
31 48 20 25 |
25 39 16 20 |
31 79 99 124 |
25 64 80 100 |
Разом |
124 |
100 |
X |
X |
Судячи з кумулятивних часток розподілу комерційних банків за розміром КІЛ (табл. 3.1.3), дві третини банків (64%) мають КІП, що не перевищує 5 млн. грн., у 80% банків КІЛ не перевищує 10 млн.грн.
При групуванні за двома ознаками масив даних спершу поділяється на групи за однією ознакою, потім кожна група поділяється на підгрупи за іншою ознакою. Результатом такого групування є комбінаційний розподіл, таблиця якого уможливлює більш детальний аналіз структури досліджуваного явища. Вибір групувальних ознак і їх поєднання підпорядковується меті дослідження.
Як приклад, розглянемо комбінаційний розподіл зареєстрованих службою зайнятості і працевлаштованих безробітних. За даними табл. 3.1.4 кількість працевлаштованих з-поміж тих, що володіють комп'ютерною технікою, становить 100 (24 : 60) = 60%, а з-поміж тих, що не володіють, - 100 (12 : 60) = 20%. Тобто шанси працевлаштуватися особам, що володіють комп'ютерною технікою, значно вищі, їх можна оцінити перехресним відношенням частот розподілу. У нашому прикладі відношення шансів становить:
yj = Добуток _ частот _ головної _ діагоналі 24 х 48 Добуток _ частот _ побічної _ діагоналі 12x16
тобто шанси працевлаштуватися особам, що володіють комп'ютерною технікою, у 6 разів вищі.
Таблиця 3.1.4. Розподіл зареєстрованих службою зайнятості і працевлаштованих безробітних
|
Праце- |
Не працевлаштовані |
|
Частка пра- |
Безробітні |
влашто- |
Разом |
цевлашто- |
|
|
вані |
|
|
ваних |
Володіють |
|
|
|
|
комп'ютерною |
24 |
16 |
40 |
0,6 |
технікою |
|
|
|
|
Не володіють |
12 |
48 |
60 |
0,2 |
Разом |
36 |
64 |
100 |
0,36 |
У середовищі Excel зведення та групування даних можна здійснити за допомогою автосуми £ , стандартної функції СУММ, а також команд головного меню Данньїе, зокрема:
Данньїе -* Сортировка;
Данньїе -* Итоги -* Промежуточние итоги;
Данньїе ~* Сводная таблица.
П
 ервинні
дані організуються у вигляді списку,
у першому рядку
якого подається назва показника, усі
комірки файла мають
містити інформацію. Як приклад, наведемо
дані щодо продажу інвестиційною
компанією нежитлових об'єктів нерухомості
за визначеною експертами вартістю
(табл. 3.1.5 ).
ервинні
дані організуються у вигляді списку,
у першому рядку
якого подається назва показника, усі
комірки файла мають
містити інформацію. Як приклад, наведемо
дані щодо продажу інвестиційною
компанією нежитлових об'єктів нерухомості
за визначеною експертами вартістю
(табл. 3.1.5 ).
Таблиця 3.1.5. Результати продажу нежилих об'єктів нерухомості
Упорядкуємо дані табл. 3.1.5 за допомогою команд Данньїе -* Сортировка. У діалоговому вікні (рис.3.1.1) вкажемо послідовність упорядкування. Перша ознака - Функціональне призначення об'єкта нерухомості, друга - Зона (місце розташування).
Відсортовані дані можна підсумувати за допомогою команди Данньїе -* Итоги -* Промежуточньїе итоги. Діалогове вікно представлено на рис. 3.1.2. Вказується групувальна ознака (у нашому прикладі Функціональне призначення об'єкта нерухомості), вид обчислювальної операції (у нашому прикладі Сумма) і показники, за якими визначаються групові і загальні підсумки. Результати групування і зведення даних за цими командами подано в табл. 3.1.6.
Згідно з даними табл. 3.1.6 загальна площа проданих об'єктів нерухомості 2114 кв. м, загальна вартість - 1 483 075 USD. В таблиці вказуються проміжні підсумки площ і вартості проданих об'єктів під кафе, магазини і офіси.

Функціональне призначення |
Зона* |
Загальна площа, кв. м |
Експертна оцінка, USD |
Офіс |
2 |
256 |
156 700 |
Кафе |
3 |
164 |
112 450 |
Офіс |
1 |
228 |
136 800 |
Кафе |
2 |
143 |
90 090 |
Магазин |
2 |
106 |
60 870 |
Магазин |
2 |
485 |
335 690 |
Офіс |
1 |
100 |
70 400 |
Магазин |
3 |
697 |
586 500 |
Офіс |
3 |
113 |
119 240 |
Магазин |
1 |
484 |
290 400 |
Кафе |
3 |
510 |
357 305 |
Магазин |
3 |
342 |
209 615 |
'Місце розташування об'єкта нерухомості: 3 - центр міста, 1- окраїна, 2 - серединна зона.
Таблиця 3.1.6. Результати торгів об'єктами нерухомості (за їх функціональним призначенням)
Таблиця 3.1.7. Результати торгів об'єктами нерухомості (за місцем розташування)

Функціональне о Загальна пло- Експертна призначення об'єкта ща, кв. м оцінка, USD Кафе 2 143 90090 Кафе 3 164 112450 Кафе 3 510 357305 Кафе Итог 817 559845 Магазин 1 484 290400 Магазин 2 106 60870 Магазин 2 485 335690 Магазин 3 342 209615 Магазин 3 697 586500 Магазин Итог 2114 1483075 Офіс 1 100 70400 Офіс 1 228 136800 Офіс 2 256 156700 Офіс 3 113 119240 Офіс Итог 697 483140 Общий итог 3628 2526060 |
|
|||
Зона |
Функціональне призначення об'єкта |
Загальна площа, кв. м |
Експертна оцінка, USD |
1 |
Магазин |
484 |
290 400 |
1 |
Офіс |
100 |
70 400 |
1 |
Офіс |
228 |
136 800 |
|
1 Итог |
812 |
497 600 |
2 |
Кафе |
143 |
90 090 |
2 |
Магазин |
106 |
60 870 |
2 |
Магазин |
485 |
335 690 |
2 |
Офіс |
256 |
156 700 |
|
2 Итог |
990 |
643 350 |
3 |
Кафе |
164 |
112 450 |
3 |
Кафе |
510 |
357 305 |
3 |
Магазин |
342 |
209 615 |
3 |
Магазин |
697 |
586 500 |
3 |
Офіс |
113 |
119 240 |
|
3 Итог |
1826 |
1 385 ПО |
|
Общий итог |
3628 |
2 526 060 |
Якщо першою ознакою групування вказати місце розташування об'єкта нерухомості (Зону), то й проміжні підсумки будуть за цією ознакою (табл. 3.1.7). Згідно з даними таблиці на околиці міста продано об'єктів нерухомості загальною площею 812 кв. м на суму 497 600 USD, в центрі міста, відповідно, 1826 кв. м на суму 1 385 110 USD.
Більш універсальним і одним з інтерактивних інструментів узагальнення даних є зведені таблиці (команда Данньїе -• Сво-дная таблиця). Будь-яка зведена таблиця створюється Масте-ром сводньїх таблиць за три кроки:
вибір джерела даних ;
визначення діапазону первинних даних;
визначення образу (макета) зведеної таблиці.
Процес створення зведеної таблиці розглянемо на прикладі списку зареєстрованих службою зайнятості безробітних (табл. 3.1.8). Групувальні ознаки: стать і освіта безробітного. Перший і другий кроки створення зведеної таблиці ілюструються відповідно рис. 3.1.3 і 3.1.4. Вказавши джерело даних (список Excel) і діапазон значень, за командою Далее переходимо до створення образу таблиці.
На третьому кроці визначається макет майбутньої зведеної таблиці. У макеті виокремлюються чотири зони: страница, строка, столбец, данньїе. Праворуч у вигляді кнопок розміщені поля даних, які заносяться у відповідні зони макета таблиці (рис.3.1.5). Щоб організувати дані в рядках з бічними заголовками, кнопку відповідного поля треба перетягнути у зону Строка.
Аналогічно, щоб організувати дані у стовпцях із заголовками зверху, кнопку відповідного поля треба перетягнути у зону Сто-лбец. У цих зонах розміщуються назви груп, регіонів, категорій тощо. Поля, за даними яких необхідно отримати підсумки, розміщуються у зоні Данньїе.
Таблиця 3.1.8. Характеристики зареєстрованих службою зайнятості безробітних
Номер за списком |
Стать |
Освіта |
Тривалість перерви в роботі, міс. |
1 |
ЖІН. |
середня спеціальна |
3 |
2 |
чол. |
середня загальна |
1 |
3 |
чол. |
середня загальна |
2 |
4 |
ЖІН. |
неповна середня |
3 |
5 |
чол. |
середня спеціальна |
4 |
6 |
ЖІН. |
середня загальна |
5 |
7 |
чол. |
вища |
3 |
8 |
ЖІН. |
середня спеціальна |
5 |
9 |
ЖІН. |
вища |
4 |
10 |
ЖІН. |
середня загальна |
6 |
11 |
чол. |
середня загальна |
3 |
12 |
ЖІН. |
вища |
5 |
13 |
ЖІН. |
середня спеціальна |
3 |
14 |
чол. |
неповна середня |
4 |
15 |
чол. |
середня спеціальна |
2 |

Рис. 3.1.4. Визначення діапазону первинних даних
Структура макета зведеної таблиці і поля даних щодо зареєстрованих безробітних (табл. 3.1.9) наведено на рис. 3.1.5. Праворуч розміщено дві кнопки - стать і освіта. Якщо кнопку поля Освіта перетягнути в зону Строка, кнопку поля Стать - у зону Столбец, і одне з них - у зону Данньїе, отримаємо комбінаційний розподіл безробітних за освітою і статтю (рис.3.1.6).

Рис. 3.1.5. Макет зведеної таблиці
Таблиця з результатами зведення та групування за процедурами Сводной таблицьі подається у стандартному вигляді. З метою подальшого аналізу згрупованих даних стандартну таблицю необхідно оформити за правилами, які викладено в розд.6.

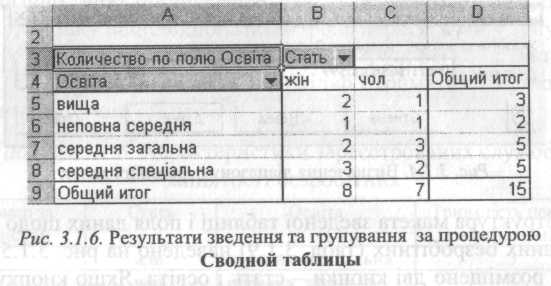
Комбінаційна таблиця такого типу є не лише засобом систематизації та упорядкування первинних даних, але й базою аналізу структури досліджуваного явища та взаємозв'язку між групувальними ознаками. Групування й частотний аналіз розподілу - лише перший крок узагальнення даних. Наступним кроком є розрахунок характеристик центру розподілу та варіації, які дозволяють глибше зрозуміти особливості об'єкта дослідження.
3.2. Узагальнюючі (типові) характеристики явищ 3.2.1. Середні величини
Будь-яке значення показника уу-ої одиниці поєднує в собі як спільні для всієї множини даних типові риси, так і властиві лише їй індивідуальні особливості. Узагальнення даних передбачає розрахунок такої характеристики, у якій би взаємно компенсувалися індивідуальні відмінності окремих одиниць і виявлялося те спільне, типове, загальне, що притаманне усій множині даних. Найпоширенішим узагальненням є середня величина х (риска над символом означає усереднення індивідуальних значень). Саме середня, абстрагуючись від індивідуальних значень, представляє усю множину даних і розглядається як типовий рівень ознаки в розрахунку на одиницю цієї множини.
У широкому розумінні середньою є величина, яка виражає найбільш фундаментальні властивості будь-якого масового явища чи процесу, скажімо, частка безробітних у загальній кількості
економічно активного населення, щільність автошляхів з твердим покриттям на 1000 кв. км. території, середня очікувана тривалість життя населення, темпи приросту (зниження) виробництва і т. ін. Можливість переходу від одиничного до загального, від випадкового до закономірного пояснює важливість і широке практичне використання методу середніх величин. На практиці залежно від змісту усереднюваного показника і наявної інформації використовуються різні середні (арифметична, гармонійна, геометрична, квадратична і т.д.). Найпоширенішою з-поміж них вважається середня арифметична.
Середня арифметична обчислюється діленням загального обсягу значень ознаки л: на обсяг сукупності:
п
_ Обсяг значень ознаки
О бсяг
сукупності п
бсяг
сукупності п
Наприклад, за місяць страхова компанія виплатила страхове відшкодування за п'ять ушкоджених об'єктів на суму, тис. грн.: 18, 27, 22, ЗО, 23. Середня сума виплати страхового відшкодування:
18 + 27 + 22+30+23 х= =24 тис. грн.
5
Моментні показники замінюються середніми як півсума значень на початок і кінець періоду. Якщо моментів більш ніж два, а інтервали часу між ними рівні, то середня обчислюється за формулою середньої хронологічної:
х, +хп
- +х2+х3+...хл_, j=_2
в-1

 У
середовищі Excel
розрахунок
середньої можна здійснити за
допомогою:
У
середовищі Excel
розрахунок
середньої можна здійснити за
допомогою:
■ Мастера функцій: £ (Среднее); категорія Статистиче- ские -* функція Срзнач;
команд головного меню Данньїе: Данньїе -* Итоги ~* Промежуточньїе итоги;
інструменту Описательная статистика пакету Анализ данньїх.
ження називають зважуванням, а число елементів сукупності з однаковими варіантами - вагами. Вагами можуть бути абсолютні частоти fj або частки dj варіаційного ряду, де у— номер групи (j =1,2,3... т). Сама назва «ваги» відображує факт різноваго-мості окремих варіант. Усереднення значень ознаки здійснюється за формулою середньої арифметичної зваженої:
т
pjfi
а) якщо вагами є частоти f: >——х— .

 Типовість
середньої як узагальнюючої характеристики
пов'язана
з однорідністю даних. Лише в однорідній
сукупності середня
характеризує типовий рівень ознаки в
розрахунку на одиницю
сукупності. У неоднорідній сукупності,
за влучним висловом П. Самуельсона,
осереднюються «тигри та кицьки», що
лише
створює ілюзію «благоденствія» і не
віддзеркалює реалій.
Типовість
середньої як узагальнюючої характеристики
пов'язана
з однорідністю даних. Лише в однорідній
сукупності середня
характеризує типовий рівень ознаки в
розрахунку на одиницю
сукупності. У неоднорідній сукупності,
за влучним висловом П. Самуельсона,
осереднюються «тигри та кицьки», що
лише
створює ілюзію «благоденствія» і не
віддзеркалює реалій.
Наприклад, акціонерний капітал компанії, заснованої чотирма власниками, становить 500 тис. грн., тобто середня вартість пакета акцій 500 : 4 = 125 тис. грн. Чи можна зробити висновок, що така вартість пакету акцій є типовою для засновників компанії? Насправді один з акціонерів має акцій на суму 425 тис. грн., а троє - на загальну суму 75 тис. грн. або в середньому по 25 тис. грн. Тобто один акціонер володіє понад 50% капіталу і здійснює контроль над усією компанією. Ясно, що акціонери належать до різних категорій, і середня в 125 тис. грн. не може вважатися типовою оцінкою вартості пакета акцій, оскільки вона вп'ятеро перевищує індивідуальні пакети акцій більшості (75%) акціонерів компанії.
Базою для розрахунку простої середньої арифметичної слугують первинні дані. Якщо дані попередньо згруповані за певними ознаками, застосовують зважену середню. У такому разі обсяг значень ознаки розраховується як сума добутків варіант х,
m
на відповідні їм частоти yj, тобто як /мХ//, . Такий процес мно-
d r
б) якщо вагами є частки df. х =
т
2>/
1
х =■
У разі, коли dj представлені процентами,
100
Наприклад, на акції трьох різних компаній очікується щорічний прибуток, %: 15, 22, 18. За умови, що інвестор розподілив свої внески між акціями цих компаній у пропорції ЗО, 20 та 50 %, очікуваний прибуток від такого портфеля акцій
=
100
Середня не збігається з жодним значенням ознаки, але це є типовий рівень прибутку.
Р
 озрахунок
зваженої середньої можна здійснити за
допомогою математичної
функції
Сумпроизв,
яка
множить значення варіант Xj
на
відповідні їм ваги^ та підсумовує
добутки. Отримана сума добутків
ділиться на суму ваг. Формула розрахунку
записується у ту комірку, куди необхідно
помістити
середню:
озрахунок
зваженої середньої можна здійснити за
допомогою математичної
функції
Сумпроизв,
яка
множить значення варіант Xj
на
відповідні їм ваги^ та підсумовує
добутки. Отримана сума добутків
ділиться на суму ваг. Формула розрахунку
записується у ту комірку, куди необхідно
помістити
середню:
/= СУММПРОИЗВ(ліасмв значень ознаки; масив значень ваг)/СУММ(масив значень ваг).
 В
інтервальних рядах розподілу, припускаючи
рівномірний розподіл
у межах у-го інтервалу, як варіант х,-
використовують середину інтервалу. При
цьому ширину відкритого інтервалу
умовно
вважають такою ж, як сусіднього закритого
інтервалу (табл.
3.2.1).
В
інтервальних рядах розподілу, припускаючи
рівномірний розподіл
у межах у-го інтервалу, як варіант х,-
використовують середину інтервалу. При
цьому ширину відкритого інтервалу
умовно
вважають такою ж, як сусіднього закритого
інтервалу (табл.
3.2.1).
Таблиця 3.2.1. Розподіл селянських (фермерських) господарств регіону за площею ріллі у розрахунку на одне господарство
Площа ріллі, га |
Кількість селянських (фермерських) господарств, в тисячах fj |
*/ |
XJ fj |
Кумулятивна частота, cumfj |
До 6 6-12 12-18 18-24 24-30 ЗО і більше |
17 32 24 16 8 3 |
3 9 15 21 27 33 |
51 288 360 336 216 99 |
17 49 73 89 97 100 |
Разом |
100 |
X |
1350 |
X |
Щоб визначити середню площу ріллі у розрахунку на одне господарство, визначимо спершу загальну площу ріллі у користуванні усіх господарств як добуток середньої площі ріллі у кожній групі (середина інтервалу xj) на кількість селянських (фермерських) господарств відповідних груп. Загальна площа ріллі становить І*у /;= 1350 тис. га, звідси середня площа у розрахунку на одне господарство х = 1350 : 100 = 13,5 га.
3.2.2. Порядкові характеристики набору даних
Якщо множину даних розмістити у порядку зростання чи зменшення значень ознаки, на основі такого упорядкованого ряду X/<х2<х3< х4<... хп_і <хп, можна визначити позиційні (порядкові) характеристики розподілу, тобто такі значення ознаки, які займають певні місця (кожне 10, 25 і т. д.). З-поміж них: медіана, екстремуми (крайні значення даних), квартилі, квинтилі, децилі тощо. У комплексі вони дають досить чітку уяву стосовно особливостей і характерних рис розподілу.
Медіана (Me) - значення ознаки, яке припадає на середину впорядкованого ряду, поділяє його на дві рівні за обсягом частини
(по 50% кожна). Ранг медіани визначається відношенням
2
Наприклад, упорядкуємо дані (п = 5) щодо суми страхового відшкодування, тис. грн.: 18, 22, 23,27, 30. Ранг медіани (1+5) /2 = 3, йому відповідає значення медіани - 23 тис. грн. Тобто половина випадків страхового відшкодування перевищує 23 тис. грн.
У середовищі Excel
медіана
визначається за статистичною функцією
Медиана.
середовищі Excel
медіана
визначається за статистичною функцією
Медиана.
З
 начення
медіани не залежить від крайніх значень
набору даних;
сума модулів відхилень індивідуальних
значень від медіани
мінімальна, тобто вона має властивість
лінійного мінімуму
начення
медіани не залежить від крайніх значень
набору даних;
сума модулів відхилень індивідуальних
значень від медіани
мінімальна, тобто вона має властивість
лінійного мінімуму
н . .
£| х. -Me І = min і є типовим рівнем для набору даних метричної чи порядкової (рангової) шкал.
Два екстремуми (найбільше і найменше значення ознаки) характеризують діапазон варіації даних. Різниця між ними називається варіаційним розмахом
Квартилі поділяють сукупність на чотири рівні за кількістю одиниць частини, квинтилі - на п'ять частин, децилі - на десять.
67
Вирізняють нижній Qi і верхній Q} квартилі. Нижній відповідає значенню, яке знаходиться на 25 місці упорядкованого ряду, верхній - значенню, що знаходиться на 75 місці. Квартильний
розмах RQ ~Q3- Qi охоплює (75 - 25) = 50 % обсягу сукупності. Ранги квартилів визначається на основі рангу медіани, яка є
а •
то:
int[(w
другим кварталем. Якщо ранг медіани =
ранг нижнього квартиля =
ранг верхнього квартиля = [(и+1) - ранг нижнього квартиля],
де int означає функцію цілого, яка відкидає дробову частину числа.
Квинтилів в упорядкованому ряду чотири. Це значення ознак, що знаходяться на 20, 40, 60 і 80 місцях. Аналогічно в ряду визначається 9 децилів: перша знаходиться на 10-му місці, дев'ята - на 90-му. Різниця між дев'ятою і першою децилями охоплює 80 % сукупності, між восьмою і другою - 60%.
Важливу роль для характеристики розподілу відіграють пе-рсентилі, які поділяють упорядкований ряд на 100 рівних за кількістю частин. Персентилі виражають ранги елементів у вигляді процентів від 0 до 100% таким чином, що найменшому значенню відповідає нульовий персентиль, найбільшому - 100-й. Очевидно, що медіана є 50-м персентилем, а верхній квартиль -75-м. Персентилі виражаються у тих же одиницях вимірювання, що й ознака. Якщо, скажімо, в ряду обсягів продажу косметики 70-й персентиль дорівнює 3205 USD і характеризує діяльність продавця Басі, то це означає, що приблизно 70% інших продавців мають результати нижчі, а 30% - вищі.
На рис. 3.2.1 подано блочну діаграму, яка містить п'ять базових характеристик одновимірного набору даних і дозволяє швидко визначати характер розподілу.
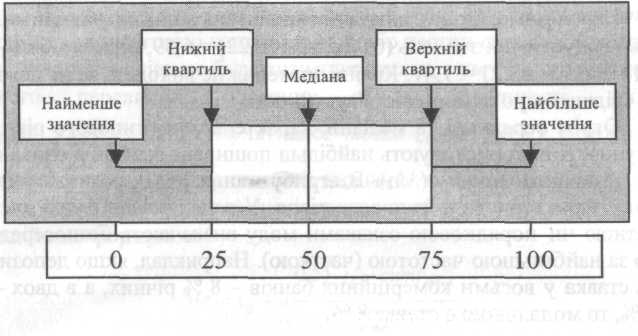
Рис. 3.2.1. Блочна діаграма розподілу [9, с. 139]
На основі порядкових характеристик розподілу можна виявити нехарактерні для множини даних значення, які називають викидами. Екстремуми будуть розглядатися як викиди за умови, що їх значення знаходяться далеко від центра розподілу:
Хпшх >К?3+1,5(&-Є/)]
Розглянемо методику розрахунку порядкових характеристик розподілу за даними 15 туристичних агенцій про витрати на рекламу, тис. USD:
6,64 6,87 7,00 7,10 7,22
6,75 6,90 7,05 7,13 7,25
6,82 6,94 7,07 7,15 7,36
Порядкові характеристики витрат на рекламу становлять, у тис. USD:
Варіаційний розмах R = 7,36 - 6,64 = 0,72;
Ранг медіани (15 + 1) / 2 = 8; значення медіани Me = 7,05;
Ранг нижнього квартиля = (1+ 8) / 2 = 4,5; значення Qi = (6,90 + 6,94) / 2 = 6,92;
Ранг верхнього квартиля = (15 + 1) - 4,5 = 11,5; значення Q3 = (7,13+ 7,15)/2 = 7,14;
Квартальний розмах Q3- Qi = 7,14 - 6,92 = 0,22.
Перевіримо, чи не є викидами крайні значення витрат. Нижня межа допустимих значень (6,92 - 1,5 х 0,22) = 6,59, верхня межа -(7,14 + 1,5 х 0,22) = 7,47. Крайні значення не виходять за ці межі, що свідчить про однорідність сукупності.
Окрім середньої та медіани, характеристику типового рівня сукупності використовують найбільш поширене значення ознаки, яке називають модою (Мо). В атрибутивних рядах розподілу це єдина характеристика типового рівня. У рядах розподілу за дискретною чи порядковою ознаками моду визначають безпосередньо за найбільшою частотою (часткою). Наприклад, якщо депозитна ставка у восьми комерційних банків - 8 % річних, а в двох -10 %, то модальною є ставка 8 %.
У
 середовищі Excel
для
визначення порядкових характеристик
розподілу передбачені статистичні
функції: квартиль,
медиана,
мода, наибольший, наименьший, персентиль,
ранг.
середовищі Excel
для
визначення порядкових характеристик
розподілу передбачені статистичні
функції: квартиль,
медиана,
мода, наибольший, наименьший, персентиль,
ранг.
В інтервальному ряду розподілу за тим
самим принципом визначається
модальний чи медіанний інтервали, а
конкретне значення
Мо
чи
Me
в
середині інтервалу розраховується за
відповідною інтерполяційною формулою,
зокрема:
інтервальному ряду розподілу за тим
самим принципом визначається
модальний чи медіанний інтервали, а
конкретне значення
Мо
чи
Me
в
середині інтервалу розраховується за
відповідною інтерполяційною формулою,
зокрема:
m r і J то J то~\
Мо = хо+п ,
W то J то-\ ' \J то J mo+\ /
де х0 та А — відповідно нижня межа та ширина модального інтервалу, fmo,fmo-\,fmo+\ ~ частоти (частки) відповідно модального, передмодального та післямодального інтервалів.
За даними табл. 3.1.1 модальним є інтервал 6-12, що має найбільшу частоту fmo = 32; ширина модального інтервалу h = 6; нижня межа xq= 6; передмодальна частота /,„0_і= 17, післямода-льна - fmo+\ = 24. За такого співвідношення частот модальне значення площі ріллі у розрахунку на одне господарство:
Мо = 6 + 6
= 9,9 га
32-17
( 32-17)+(32-24)
32-17)+(32-24)
При визначенні медіани за даними ряду розподілу використовують кумулятивні частоти cumfj або частки cum dj . У дискретному ряду медіаною буде значення ознаки, кумулятивна частота якого перевищує половину обсягу сукупності, тобто
cumf >0 5У f. (для кумулятивної частки cumd, > 0,5 )• В інтерва-
j j * і-* j j j
льному ряду за цим принципом визначають медіанний інтервал, а значення медіани в середині інтервалу обчислюють за інтерполяційною формулою
0,5Zfi-cumfme_x
Ме = х0
} 1
J me
де х0 та h - відповідно нижня межа та ширина медіанного інтервалу;
fme - частота медіанного інтервалу;
cumfme-i ~ кумулятивна частота передмедіанного інтервалу. За даними табл. 3.1.1 половина обсягу сукупності
0,51/, =Ю0 припадає на інтервал 12 - 18 з частотою /те= 24; і
передмедіанна кумулятивна частота cumfme_x = 49. Отже, медіана площі ріллі у розрахунку на одне господарство становить:
Me
=
12 + 6 5°~~49
= 12,2 га.
24
Тобто половина селянських господарств мають площу ріллі менше 12,2 га. Аналогічно розраховуються квартилі, квинтилі і децилі. У ряду розподілу за площею ріллі на одне господарство (табл. 3.1.1) нижній квартиль становить 7,5 га, верхній— 18,75 га, перша дециль - 3,5 га, дев'ята - 24,7 га:
=7,5;
0,25-100-17
16
 ,0,1-100-0
..
А
= 0 + 6——— =
3,5;
,0,1-100-0
..
А
= 0 + 6——— =
3,5;
17 0,9-100-89
= 24,7.
А, =24 + 6
Отже, у 10 % селянських (фермерських) господарств регіону площа ріллі у розрахунку на одне господарство не перевищує 3,5 га, у 25 % господарств - не перевищує 7,5 га, натомість у 10 % найпотужніших господарств - щонайменше 24,7 га ріллі.
У

 середовищі Excel
при
визначенні порядкових характеристик
за згрупованими даними з метою уникнення
можливих помилок рекомендується
складати формули частинами.
середовищі Excel
при
визначенні порядкових характеристик
за згрупованими даними з метою уникнення
можливих помилок рекомендується
складати формули частинами.
3
 .3.
Вимірювання диференціації та концентрації
явищ
.3.
Вимірювання диференціації та концентрації
явищ