Мал. 6.21. Файлова система, що архівується
Цей алгоритм також створює резервні копії усіх каталогів (навіть не модифікованих), розташованих на шляху до модифікованого файлу або каталогу. Робиться це з двох причин. По-перше, щоб усе збережені файли і каталоги можна було відновити на іншому комп'ютері. Завдяки цьому програма архівації може використовуватися для перенесення усій файловою системи з одного комп'ютера на інший.
По-друге, збереження резервних копій усіх каталогів, розташованих на шляху до модифікованого файлу, дозволяє відновити один окремий файл (наприклад, видалений помилково). Уявіть, що повна архівація системи проведена в неділю, а в понеділок виконана інкрементна архівація. У вівторок віддаляється каталог /usr/jhs/proj/nr3 з усіма каталогами, що містяться в нім, і файлами. В середу вранці користувач хоче відновити файл /usr/ jhs/proj/nr3/plans/summary. Проте не можна просто відновити файл summary, оскільки каталоги /usr/jhs/proj/ nr3/plans і /usr/jhs/proj/тЗ видалені і файл summary нікуди помістити. Спочатку треба відновити каталоги nr3 і plans. Щоб операційна система змогла коректно встановити такі параметри цих каталогів, як ідентифікатор власника, режими доступу, час створення, час зміни і т. д., ці каталоги мають бути присутній на архівній стрічці, не дивлячись на те, що самі каталоги не модифікувалися з моменту останньої архівації.
Алгоритм архівації створює бітовий масив, індексований по номеру i-вузла, в якому на кожного i-вузол відводиться декілька бітів. Робота алгоритму протікає в чотири етапи. Перший етап починається в початковому каталозі (напри-мер, в кореневому), в якому досліджуються усі елементи. Для кожного модифікованого файлу його i-вузол позначається в бітовому масиві. Кожен каталог також позначається (незалежно від того, був він змінений або ні), після чого він відкривається і рекурсивно досліджується увесь його вміст.
До кінця фази 1 усі модифіковані файли і усі каталоги позначаються в бітовому масиві, як показано (затінюванням) на мал. 6.22, а. На іншому етапі алгоритм знову рекурсивно крокує обвішай каталог, знімаючи відмітку з усіх каталогів, в яких немає модифікованих файлів або каталогів. У результаті цих дій бітовий масив набирає вигляду, показаного на малий. 6.22, би. Зверніть увагу, що каталоги 10, 11, 14, 27, 29 і 30 тепер вже не помічені, оскільки в них і в їх підкаталогах не міститься нічого модифікованого. Для цих каталогів не створюватиметься резервна копія. Навпаки, каталоги 5 і 6 заархівують, не дивлячись на ті, що самі сморід не булі модифіковані. Проте їх буде потрібно, щоб сьогоднішні зміни можна було відновити на новій машині. Для більшої ефективності фази 1 і 2 можна об'єднати, виконавши їх за один прохід.

Мал. 6.22. Бітові масиви, використовувані алгоритмом логічної архівації
До цього моменту алгоритму відомо, які каталоги і файли повинні архівуватись (помічені на мал. 6.22, б). Фаза 3 складається із сканування і-вузлів по порядку номерів і створення резервних копій усіх каталогів, помічених для архівації. Вони помічені на мал. 6.22, ст. Перед кожним каталогом записуються його атрибути (власник, часи і т. д.), необхідні для відновлення. Нарешті, на четвертому етапі файли, помічені на мал. 6.22,, г також архівуються зі своїми атрибутами, записуваними перед ними. На цьому архівація завершується.
Відновлення файлової системи відбувається досить просто. Спочатку на диску створюється порожня файлова система. Потім відновлюються дані останньої повної архівації. Спочатку відновлюються каталоги, створюючи скелет файлової системи, після чого відновлюються усі файли. Потім увесь процес повторюється з усіма інкрементними архіваціями по черзі.
Хоча алгоритм логічної архівації нескладний, в цій справі є декілька хитрощів. По-перше, оскільки список вільних блоків не являється файлом, він не архівується, отже, його доводиться відновлювати з нуля, після того, як були відновлені усі архіви. Це завжди є здійснимою задачею, оскільки безліч вільних блоків є усього лише сукупністю усіх блоків, що містяться в усіх файлах.
Другою проблемою є зв'язки файлів. Якщо у файлу є зв'язки в двох або більше каталогах, важливо, щоб цей файл був відновлений тільки один раз, і щоб в усіх каталогах, в яких були посилання на цей файл, з'явилися саме посилання.
Ще одна проблема полягає в тому, що в системі UNIX файли можуть містити діри. Вважається допустимим відкрити файл, записати в нього декілька байтів, потім перемістити покажчик у файлі на багато блоків в глиб файлу, після чого записати ще декілька байтів. Блоки посередині не є частиною файлу і не повинні архівуватися і відновлюватися. Файли, що містять образи пам'яті, часто містять великі порожні простори між сегментом даних і стеком. Якщо їх не обробляти належним чином, то кожен відновлений файл з образом пам'яті заповнить цю область нулями і виявиться того ж розміру, що і віртуальний адресний простір (наприклад, 232 байт або, що ще гірше 2е4 байт).
Нарешті, спеціальні файли, звані каналами або трубами і т. п., ніколи не повинні архівуватися, незалежно від того, в якому каталозі вони можуть виявитися (вони не зобов'язані знаходитися в каталозі /dev). Додаткові дані про файлову систему див. в [67,372].
Несуперечність файлової системи
Ще одним аспектом, що відноситься до проблеми надійності, є несуперечність файлової системи. Файлові системи зазвичай читають блоки даних, модифікують їх і записують назад. Якщо в системі станеться збій перед тим, як усі модифіковані блоки будуть записані на диск, файлова система може опинитися в суперечливому стані. Ця проблема стає особливо важливою у разі, якщо одним з модифікованих і не збережених блоків виявляється блок i-вузла, каталогу або списку вільних блоків.
Для вирішення проблеми суперечності файлової системи на більшості комп'ютерів є спеціальна обслуговуюча програма, перевіряюча несуперечність файлової системи. Наприклад, в системі UNIX такою програмою являється /^, а в системі Windows це програма scandisk. Ця програма може бути запущена відразу після завантаження системи, особливо якщо до цього був збій. Нижче буде описано, як працює утиліта fsck. Утиліта scandisk дещо відрізняється від fsck, оскільки працює в іншій файловій системі, проте для неї також залишається вірним принцип використання надмірної інформації для відновлення файлової системи. Усі програми перевірки файлової системи перевіряють різні файлові системи (дискові розділи) незалежно один від одного.
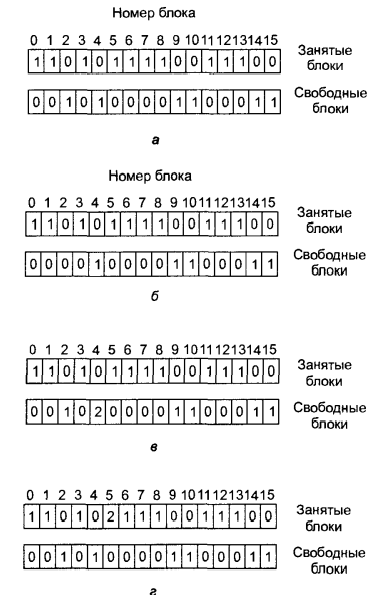
Існує два типи перевірки несуперечності : блоків і файлів. При перевірці несуперечності блоків програма створює дві таблиці, кожна з яких містить лічильник для кожного блоку, спочатку встановлений на 0. Лічильники в першій таблиці враховують, скільки разів кожен блок є присутній у файлі. Лічильники в другій таблиці записують, скільки разів кожен блок враховується в списку вільних блоків (чи в бітовому масиві вільних блоків).
Потім програма прочитує усі і-вузли. Починаючи з і-вузла, можна побудувати список усіх номерів блоків, використовуваних у відповідному файлі. При зчитуванні кожного номера блоку відповідний йому лічильник збільшується на одиницю. Потім програма аналізує список або бітовий масив вільних блоків, щоб виявити усі невживані блоки. Кожного разу, зустрічаючи номер блоку в списку вільних блоків, програма збільшує на одиницю відповідний лічильник в другій таблиці.
Якщо файлова система несуперечлива, то кожен блок зустрічатиметься тільки один раз, або в першій, або в другій таблиці, як показано на мал. 6.23, а. Проте в результаті збою ці таблиці можуть набрати вигляду, показаного на мал. 6.23,5. В цьому випадку блок два відсутній в кожній таблиці. Про такий блок програма повідомить як про бракуючий блок. Хоча зниклі блоки не завдають шкоди, вони займають місце на диску, знижуючи його місткість. Розв'язати проблему зниклих блоків дуже просто: програма перевірки файлової системи просто додає ці блоки до списку вільних блоків.