

Мал. 6.15. Файлова система, що містить сумісно використовуваний файл.
Спільне використання файлів зручне, але в той же час створює деякі нові проблеми. Якщо дискові адреси містяться в самих каталогових записах, тоді при додаванні нових даних до спільно використовуваного файлу нові блоки числитимуться тільки в каталозі того користувача, який проводив ці зміни з файлом. Іншим користувачам ці зміни будуть не видні.
Ця проблема має два рішення. По-перше, інформація про блоки диска, що займає файл, може міститися не в каталозі, а в спеціальній структурі даних, пов'язаній з файлом. В цьому випадку записи в каталогах будуть просто вказує на цю структуру даних. Цей метод використовується в системі UNIX (структура даних називається там і-вузлом).
Друге рішення полягає в тому, що коли користувач У встановлює зв'язок з одним з файлів користувача З, система створює в каталозі користувача В новий файл типу LINK (зв'язок). Новий файл містить просто ім'я шляху до файлу, з яким він пов'язаний. Коли користувач В читає дані з пов'язаного файлу, операційна система бачить, що звернення проводиться до файлу типу LINK, по-цьому вона відкриває файл, з яким пов'язаний цей файл, і читає дані з нього. Такий метод називається символьним зв'язуванням.
У кожного з цих методів є недоліки. У першому методі, коли користувач У встановлює зв'язок із спільно використовуваним файлом, в і -вузлі власник файлу числиться користувач С. Створення зв'язку не змінює власника файлу (мал. 6.16), а тільки збільшує лічильник і-вузла, що дозволяє системі відслідковувати кількість записів в каталогах, що посилаються на цей файл.
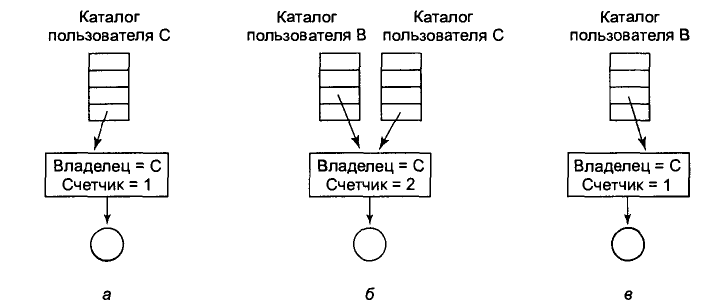
Мал. 6.16. Ситуація до зв’язку (а); після створення зв’язку (б); власник видалив свій файл (в)
Якщо згодом користувач Із спробує видалити цей файл, операційна система зіткнеться з проблемою. Якщо вона видалить файл і очистить і-вузол, у користувача У виявиться запис в каталозі, що вказує на невірний і -вузол. Якщо цей і-вузол згодом буде призначений іншому файлу, зв'язок в каталозі користувача В посилатиметься на невірний файл. За значенням лічильника і-вузла система зможе визначити, що цей файл використовується кимось ще, але у неї немає способу знайти усі записи в каталогах, що вказують на цей файл, щоб видалити їх. Покажчики на каталоги не можуть зберігатися в і-вузлах, оскільки число таких каталогів нічим не обмежується.
Єдине, що може зробити операційна система - це видалити запис в каталозі користувача С, але залишити на місці і-вузол, зменшивши значення лічильника на 1, як показано на мал. 6.16, в. Таким чином, ми тепер отримали ситуацію, в якій користувач В є єдиним користувачем, що має посилання на файл, власником якого вважається користувач С. Якщо система веде облік або виділяє обмежені квоти на використання дискового простору, користувач С продовжуватиме отримувати рахунки за цей файл до тих пір, поки користувач В не вирішить, нарешті, видалити його. В цьому випадку лічильник і-вузла зменьшиться до нуля і система видалить файл.
При символьному зв'язуванні такої проблеми не виникає, оскільки покажчик на і-вузол є тільки у власника файлу. У інших користувачів, що встановили зв'язок з цим файлом, є тільки шляхи до файлу, а не покажчики на і -вузол. Коли власник видаляє файл, файл знищується. Наступні спроби використовувати цей файл за допомогою символьного зв'язку не матимуть успіху, оскільки система не зможе знайти файл. Видалення символьного зв'язку жодним чином не вплине на файл.
Недоліком символьного зв'язку є необхідність накладних витрат. Щоб дістати доступ до і-вузла, слід спочатку прочитати файл, що містить шлях. Потім слід пройти по цьому шляху, відкриваючи каталог за каталогом, поки, нарешті, не буде отриманий потрібний і -вузол. Усі ці дії можуть зажадати істотної кількості звернень до диска. Крім того, для кожного символьного зв'язку потрібно додатковий і-вузол, а також додатковий блок диска для зберігання шляху до файлу, хоча, якщо ім'я шляху коротке, то як оптимізації система може зберігати його в самому i-вузлі. Перевага символьних зв'язків полягає в тому, що вони можуть використовуватися для посилань на файли, що знаходяться на видалених комп'ютерах в будь-якій точці земної кулі. Для цього, окрім звичайного шляху файлу, треба усього лише вказати мережеву адресу машини, на якій файл розташовується.
Використання зв'язків, як символьних, так і інших, створює ще одну проблему. При використанні зв'язків біля одного файлу опиняється декілька шляхів. Програми, скануючи каталоги з усіма підкаталогами, можуть наткнутися на один і той же файл кілька разів. Якщо така програма, наприклад, записує усі файли на магнітофонну стрічку, вона запише на стрічку декілька копій одного і того ж файлу. Більше того, якщо запис з цієї стрічки буде потім прочитаний на іншому комп'ютері, цей файл виявиться скопійованим на диск кілька разів, якщо програма, що тільки прочитує стрічку, не здогадається, що це один і той же файл.
Організація дискового простору
Зазвичай файли зберігаються на диску, тому організація дискового простору є основною турботою розробників файлової системи. Для зберігання файлу з п байтів можливе використання двох стратегій : виділення на диску п послідовних байтів або розбиття файлу на декілька безперервних блоків. Та ж дилема є присутній в системах управління пам'яті, де є вибір між чистою сегментацією і сторінковою організацією пам'яті.
Як вже було показано, при зберіганні файлу у вигляді безперервної послідовності байтів виникає проблема, пов'язана із збільшенням його розмірів. Єдиний спосіб збільшити безперервний файл полягає в переміщенні його на нове місце на диску. Проблема істотна і для управління сегментами пам’яті, з тією різницею, що переміщення сегменту в пам'яті є швидшою операцією в порівнянні з переміщенням файлу на диску. З цієї причини майже усі файлові системи зберігають файли у вигляді блоків фіксованого розміру, що містяться в різних частинах диска.
Розмір блоку
Як тільки прийнято рішення зберігати файли блоками фіксованого розміру, виникає питання про розмір цих блоків. Враховуючи організацію дисків, очевидними кандидатами на роль сегментів файлів є сектор, доріжка і циліндр диска (мінусом такого вибору є залежність цих параметрів від пристроїв). У системі управління сторінками пам'яті розмір сторінки також входить до числа основних претендентів.
Якщо вибрати велику одиницю зберігання, таку як циліндр, це буде означати, що будь-який файл, що навіть складається з одного байта, займе як мінімум цілий циліндр. Вивчення показали, що середній розмір файлу в системі UNIX близько 1 Кбайт, так що при виділенні кожному файлу 32-кілобайтного блоку буде використовуватись даремно 31/32 або 97 % загального дискового простору [241].
З іншого боку, при використанні маленьких одиниць зберігання кожен файл складатиметься з великого числа блоків. Для читання кожного блоку файлу зазвичай потрібно операцію пошуку потрібного циліндра і затримку обертання диска, тому читання файлу, що складається з великого числа блоків, буде повільним.
Наприклад, уявіть собі диск з 131 072 байтами (128 Кбайт) на доріжку, періодом обертання 8,33 мс і середнім часом пошуку 10 мс. При цьому час, що вимагається для читання блоку з k байтів, дорівнюватиме сумі часу пошуку, затримки обертання і часу перенесення даних :
10 + 4.165 + (k/131072) * 8.33
Жирна ламана лінія на мал. 6.17 показує залежність швидкості передачі даних від розміру блоку. Щоб вичислити ефективність використання дискового простору, нам треба зробити припущення про середній розмір файлу. Недавні виміри, проведені автором на факультеті, де близько 1000 користувачів комп'ютерів і більше мільйона дискових файлів системи UNIX, показали, що медіановий розмір файлу дорівнює 1680 байт. Це означає, що поло-провина файлів менше 1680 байт, а інша половина більше цього розміру. Слід зауважити, що медіановий розмір є кращою одиницею виміру, чим середній, оскільки невелика кількість файлів може дуже сильно вплинути на середнє значення, але не на медіану. (Середнє значення виявилося рівним 10 845 байт завдяки декільком 100-мегабайтним керівництву по апаратурі, яке виявилося у момент вимірів на дисках). Для простоти припустимо, що усі файли мають розмір, рівний 2 Кбайт, внаслідок чого ми отримаємо штри-ховую лінію, що зображує на мал. 6.17 ефективність використання диско-вого простору.
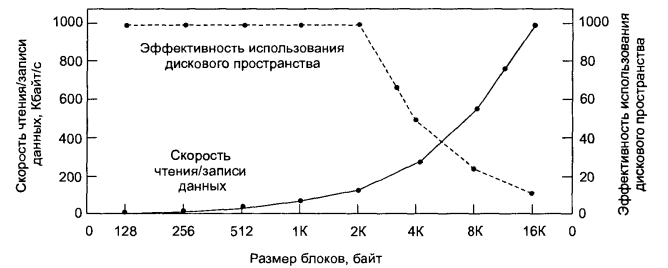
Ці дві криві можна розуміти таким чином. Час доступу до блоку практично повністю визначається часом пошуку і затримкою обертання, тому, якщо вважати, що для доступу до блоку потрібно 14 мс, чим більше даних вдасться зчитати за одну таку операцію, тим краще. Таким чином, швидкість читання/запису даних росте пропорційно розміру блоку до тих пір, поки блок не виросте настільки, що важливіше виявиться час передачі блоку. При використанні невеликих блоків, розмір яких складає міру числа два, і 2-кілобайтних файлів втрат дискового простору немає. Проте при збереженні 2-кілобайтних файлів в 4-кілобайтних блоках втрачається вже 50 % дискового простору. Насправді мало файлів мають довжину, кратну розміру блоку, тому якась частина дискового простору завжди втрачається в останньому блоці файлу.
Що показує цей графік? Те, що продуктивність і використання дискового простору є взаємовиключними цілями. При невеликих блоках низька продуктивність, зате хороше використання дискового простору, і навпаки. Вимагається знайти деякий компромісний розмір. Для подібних даних 4 Кбайт може виявитися оптимальним вибором, проте деякі операційні системи зробили свій вибір багато років тому, коли і параметри дисків, і розміри файлів були іншими. У системі UNIX зазвичай використовується розмір блоку 1 Кбайт. У системі MS - DOS розмір блоку може бути будь-який в степені двох від 512 байт до 32 Кбайт і визначається розміром диска (оскільки максимальне кількість блоків в розділі диска дорівнює 216 і розмір блоку виявляється пропорційним розміру диска).
Намагаючись визначити, чи являється використання файлів в Windows NT суттєво відмінним від їх вживання в UNIX, Фогельс в університеті Корнелла провів відповідні виміри [346]. Він дійшов висновку, що ввикористання файлів в NT складніше, ніж в UNIX. Він писав:
Коли ми вводимо декілька символів в текстовому редакторові notepad, зберігаючи їх у файлі, ми запускаємо 26 системних викликів, включаючи 3 невдалих спроби відкриття файлів, перезапис одного файлу і 4 додаткових послідовності операцій відкриття і закриття файлів.
Проте його виміри показали медіановий розмір (зважений по ис-пользованию) тільки читаних файлів, рівний 1 Кбайт, тільки записуваних файлів - 2,3 Кбайт, і файли, що читаються і записуваних, рівний 4,2 Кбайт. Учи-тивая, що університет Корнелла проводив значно більше масштабних наукових обчислень, чим установа автора, а також відмінність в техніці измере-ний (статичною і динамічною), отримані результати в достатній мірі узгоджуються з медіановим розміром файлів близько 2 Кбайт.
Облік вільних блоків
Після того, як ми вибрали розмір блоків, слід визначити, як враховувати вільні і зайняті блоки. Широке застосування отримали два методи, показані на мал. 6.18. Перший метод є використанням зв'язкового списку блоків диска. При цьому в кожному блоці списку міститься стільки номерів вільних блоків, скільки може поміститися в один блок. При розмірі блоку, рівному 1 Кбайт, і 32-розрядних номерах блоків кожен блок списку вільних блоків може містити номери 255 вільних блоків. (Одне 32-розрядне слово потрібне для покажчика на наступний блок списку). Для 16-гігабайтного диска буде потрібно список вільних блоків, що складається з 16 794 блоків, щоб містять усі 224 номери дискових блоків. Часто для списку резервується потрібне число блоків на початку диска.
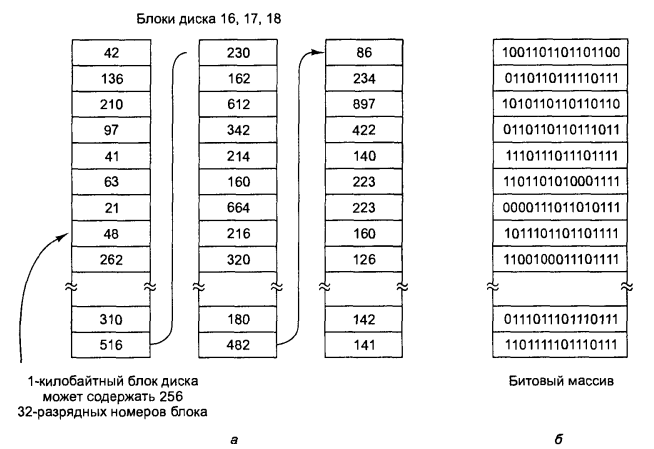
Мал. 6.18. Зберігання інформації про вільні блоки у вигляді списку (а); бітовий масив (б)
Інший метод обліку вільного дискового простору полягає в зберіганні цієї інформації у вигляді бітового масиву (іноді званого біт-картою). При цьому на кожен блок доводиться всього по одному біту замість 32. Вільні блоки позначаються в масиві одиницями, а зайняті - нулями (чи навпаки). 16-гігабайтний диск складається з 224 кілобайтних блоків, таким чином, для нього потрібно масив розміром 22А біт, тобто 2048 блоків.
При використанні методу обліку вільних блоків за допомогою списку в оперативної пам'яті вимагається зберігати тільки один блок покажчиків. Коли створюється файл, потрібні блоки беруться з блоку покажчиків. Коли покажчики в цьому блоці закінчуються, читається новий блок з диска. Відповідно, при видаленні файлу його блоки звільняються, а їх номери додаються в список, що зберігається в оперативної пам'яті. Коли блок покажчиків наповнюється, він записується на диск.
При певних обставинах такий метод призводить до зайвих операціям введення-виводу. Розглянемо ситуацію на мал. 6.19, а, в якій в блоці вказівників є місце тільки для ще двох записів (затінені прямокутники означають покажчики в блоці). При видаленні трьохблокового файлу блок покажчиків переповнюється і його треба записати на диск, що призводить до ситуації, показаної на мал. 6.19, б. Якщо тепер знову створюється трьохблоковий файл, повний блок покажчиків має бути знову прочитаний з диска, що нас повертає до ситуації на мал. 6.19, а. Якщо цей трьохблоковий файл був тимчасовим файлом, то він незабаром знову віддаляється, при цьому знову блок покажчиків пишеться на диск. Таким чином, коли покажчики в блоці виявляються на межі блоку, виникає необхідність в додаткових операціях введення-виводу.