Мал. 6.11. Таблиця розміщення файлів
Ця схема дозволяє використовувати для даних увесь блок. Крім того, випадковий доступ при цьому стає набагато простіший. Хоча для діставання доступу до якого-небудь блоку файлу все одно знадобиться проїхати по ланцюжку по усіх посиланнях аж до посилання на необхідний блок, проте в даному випадку увесь ланцюжок посилань вже зберігається в пам'яті, тому для слідування по ній не потрібно додаткові дискові операції. Як і у попередньому випадку, в каталозі достатньо зберігати одне ціле число (номер початкового блоку файлу) для забезпечення доступу до усього файлу.
Основний недолік цього методу полягає в тому, що уся таблиця повинна постійно знаходитися в пам'яті. Для 20-гігабайтного диска з блоками розміром 1 Кбайт було б потрібно таблицю з 20 млн записів, по одній для кожного з 20 млн блоків диска. Кожен запис повинен складатися як мінімум з трьох байтів. Для прискорення пошуку розмір записів має бути збільшений до 4 байт. Таким чином, таблиця постійно займатиме 60 або 80 Мбайт оперативної пам'яті. Таблиця, звичайно, може бути розміщена у віртуальній пам'яті, але і в цьому випадку її розмір виявляється надмірно великим, до того ж постійне вивантаження таблиці на диск і завантаження з диска істотно понизить продуктивність файлових операцій.
i-вузли
Останній метод відстежування приналежності блоків диска файлам полягає в зв'язуванні з кожним файлом структури даних, званої i-вузлом (index node - індекс-вузол), що містить атрибути файлу і адреси блоків файлу. Простий приклад і-вузла показаний на мал. 6.12. За наявності і-вузла можна знайти усі блоки файлу. Велика перевага такої схеми перед таблицею, що зберігається в пам'яті, із зв'язних списків полягає в тому, що кожен конкретний 1-вузол повинен знаходитися в пам'яті тільки тоді, коли відповідний йому файл відкритий. Якщо кожен і-вузол займає n байт, а одночасно відкрито може бути до k файлів, то для масиву i-вузлів буде потрібно в пам'яті усього kn байтів.
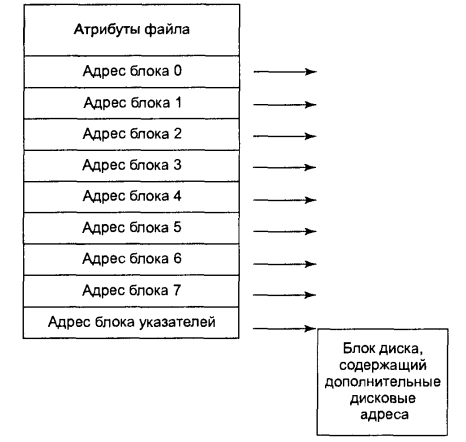
Мал. 6.12. Приклад і-вузла
Зазвичай цей розмір значно менший, ніж FAT-таблиця, описана в попередньому розділі. Це легко пояснюється. Розмір таблиці, що зберігає зв'язний список усіх блоків диска, пропорційний розміру самого диска. Для диска з n блоків буде потрібно n записів в таблиці. Таким чином, розмір таблиці лінійно росте із зростанням розміру диска. Для схеми i-вузлів, навпаки, потрібно масив в пам'яті розміром, пропорційним максимальній кількості файлів, які можуть бути відкриті одночасно. При цьому не важливо, чи буде розмір диска 1 Гбайт, 10 Гбайт або 100 Гбайт.
З такою схемою пов'язана проблема, що полягає в тому, що при виділенні кожному файлу фіксованої кількості дискових адрес цієї кількості може не вистачити. Одне з рішень полягає в резервуванні останньої дискової адреси не для блоку даних, а для наступного адресного блоку, як показано на мал. 6.12. Більше того, можна створювати цілі ланцюжки і навіть дерева адресних блоків. Ми знову повернемося до теми i-вузлів, коли приступимо до вивчення системи UNIX пізніше.
Реалізація каталогів
Перш ніж прочитати файл, його слід відкрити. При відкритті файлу операційна система використовує ім'я шляху, що поставляється користувачем, щоб знайти запис в каталозі. Запис в каталозі містить інформацію, необхідну для знаходження блоків диска. Залежно від системи це може бути дискова адреса усього файлу (для безперервних файлів), номер першого блоку файлу (обидві схеми зв'язних списків) або номер 1-узла. У усіх випадках основна функція каталогової системи полягає в перетворенні ASCII-імені в інформацію, необхідну для знаходження даних.
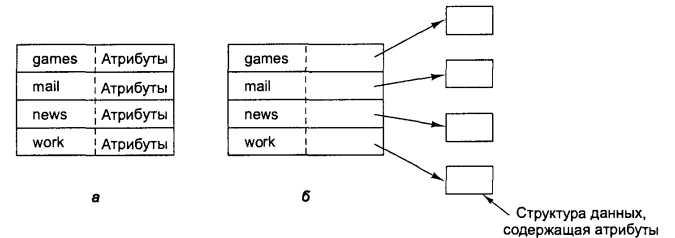
З цією проблемою тісно пов'язано питання розміщення атрибутів файлу. Кожна файлова система підтримує різні атрибути файлу, такі як дату створення файлу, ім'я власника файлу і т. д., і усю цю інформацію треба десь зберігати. Один з можливих варіантів полягає в зберіганні цих відомостей прямо в каталоговому записі. Багато файлових систем саме так і поступають. Цей варіант показаний на мал. 6.13, а. У цій простій схемі каталог складається із списку елементів фіксованої довжини по одному на файл, файлів, що містять імена, структуру атрибутів файлу, а також один або декілька дискових адрес, що вказують на розташування файлу на диску.