Мал. 6.5. Дворівнева каталогова система
Коли при такій схемі користувач намагається відкрити файл, система знає, що це за користувач, і шукає файл у відповідному каталозі. Отже, для роботи в такій системі потрібно початкову реєстрацію користувача, при якій користувач вказує своє ім'я або ідентифікатор. У однорівневій каталоговій системі така процедура не була потрібна.
При реалізації такої системи в її базовій формі користувачі можуть отримати доступ тільки до файлів у своєму власному каталозі. Проте невелика модифікація основної схеми дозволяє користувачам діставати доступ до файлів інших користувачів. Для цього їм треба вказати ідентифікатор власника файлу. Наприклад, команда
open(“x”)
може бути викликом для відкриття файлу х в каталозі користувача, а команда
open(“nancy/x”)
може бути викликом для відкриття файлу х в каталозі іншого користувача, Ненсі.
Одна з ситуацій, в якій користувачам може знадобитися отримати доступ до файлів, що не знаходяться в їх каталогах, - це виконання системних двійкових програм. Копіювання усіх системних програм в усі призначені для користувача каталоги украй неефективно. Таким чином, виникає необхідність в створені принаймні одного системного каталогу, що містить усі здійснимі двійкові системні файли.
Ієрархічні каталогові системи
Завдяки дворівневій ієрархії зникають конфлікти імен файлів між різними користувачами, але її недостатньо для користувачів з великим числом файлів. Зазвичай користувачам буває необхідно логічно групувати свої файли. Наприклад, у професора може бути набір файлів, що утворюють книгу, яку він пише для одного курсу, іншу безліч файлів, що містять програми студентів для іншого курсу. Третій набір файлів може містити початкові тексти нового компілятора, що розробляється їм, четверта група файлів - пропозиції різних грантів, а також електронну пошту, розклад зборів, статті, ігри і т. д. Потрібно деякий гнучкий спосіб, що дозволяє об'єднувати ці файли в групи.
Отже, потрібна деяка загальна ієрархія (тобто дерево каталогів). При такому підході кожен користувач може сам створити собі стільки каталогів, скільки йому треба, групуючи свої файли природним чином. Цей підхід проілюстрований на мал. 6.6. Тут каталоги А В і С, що містяться в кореневому каталозі, належать різним користувачам, два з яких створили підкаталоги для проектів, над якими вони працюють.
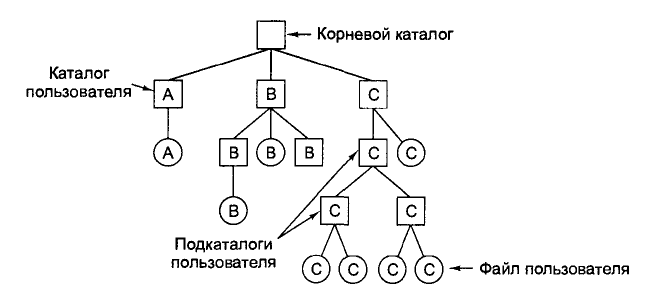
Мал. 6.6. Ієрархічна каталогова система
Можливість створювати довільну кількість підкаталогів являється потужним інструментом, що дозволяє користувачам організувати свою роботу. З цієї причини майже усі сучасні файлові системи організовані так само.
Ім'я шляху
При організації файлової системи у вигляді дерева каталогів потрібно деякий спосіб вказівки файлу. Для цього зазвичай використовуються два різні методи. У першому випадку кожному файлу дається абсолютне ім'я шляху, що складається з імен усіх каталогів від кореневого до того, в якому міститься файл, і імені самого файлу. Наприклад, шлях /usr/ast/mailbox означає, що кореневий каталог містить підкаталог usr який, у свою чергу, містить підкаталог ast, де знаходиться файл mailbox. Абсолютні імена шляхів завжди починаються від кореневого каталогу і є унікальними. У системі UNIX компоненти шляху розділяються косою рискою /. В Windows як роздільник використовується обернена коса риска \. В системі MULTICS використовувався символ >. Таким чином, одне і те ж ім'я шляху в цих трьох операційних системах виглядатиме таким чином:
Windows \usr\ast\mailbox
UNIX /usr/ast/maiIbox
MULTICS >usr>ast>mai1 box
Якщо першою буквою імені шляху був роздільник, це означало, незалежно від використовуваного як роздільник символу, що шлях абсолютний.
Застосовується і відносне ім'я шляху. Воно використовується разом з концепцією робочого каталогу (також званого поточним каталогом). Користувач може призначити один з каталогів поточним робочим каталогом. В цьому випадку усі імена шляхів, що не починаються з символу роздільника, вважаються відносними і відлічуються відносно поточного каталогу. Наприклад, якщо поточним каталогом є /usr/ast, тоді до файлу з абсолютним шляхом /usr/ast/mailbox можна звернутися просто як до mailbox. Іншими словами, команда UNIX
ср /usr/ast/mailbox /usr/ast/mai1box.bak
і команда
ср mailbox mailbox.bak
виконають одну і ту ж дію, якщо робочим каталогом є /usr/ast. відносна форма часто виявляється зручнішою, але вона виконує те ж саме, що і абсолютна.
Деяким програмам буває треба дістати доступ до файлів незалежно від того, який каталог є в даний момент поточним. В цьому випадку вони завжди повинні використовувати абсолютні імена. Наприклад, програмі перевірки правопису може знадобитися для виконання роботи прочитати файл /usr/lib/dictionary. В цьому випадку вона повинна використовувати повне, абсолютне ім'я файлу, оскільки вона не знає, яким буде робочий каталог при її виклику. Абсолютне ім'я файлу працюватиме завжди, незалежно від того, який каталог є поточним в даний момент.
Якщо програмі перевірки правопису знадобиться велика кількість файлів з каталогу /usr/lib, вона може, звернувшись до операційної системи, змінити робочий каталог на/usr/lib, після чого використовувати просто ім'я dictionary для першого параметра системного виклику open. Явно вказавши свій робочий каталог, програма може використовувати надалі відносні імена, оскільки точно знає, де вона знаходиться в дереві каталогів.
У кожного процесу є свій робочий каталог, тому, коли процес міняє свій робочий каталог і потім завершує роботу, це не впливає на роботу інших процесів, і у файловій системі не залишається ніяких слідів від подібних змін робочих каталогів. Таким чином, процес може спокійно міняти свій робочий каталог, коли це йому зручно. З іншого боку, якщо бібліотечна процедура поміняє свій робочий каталог і не відновить його при поверненні управління, програма, що викликала її, може виявитися не в змозі продовжувати свою раооту, оскільки її припущення про поточний каталог виявляться невірними. З цієї причини бібліотечні процедури рідко міняють свої робочі каталоги, а коли все-таки міняють, то обов'язково відновлюють робочий каталог перед поверненням.
/
Мал.
6.7. Дерево каталогів UNIX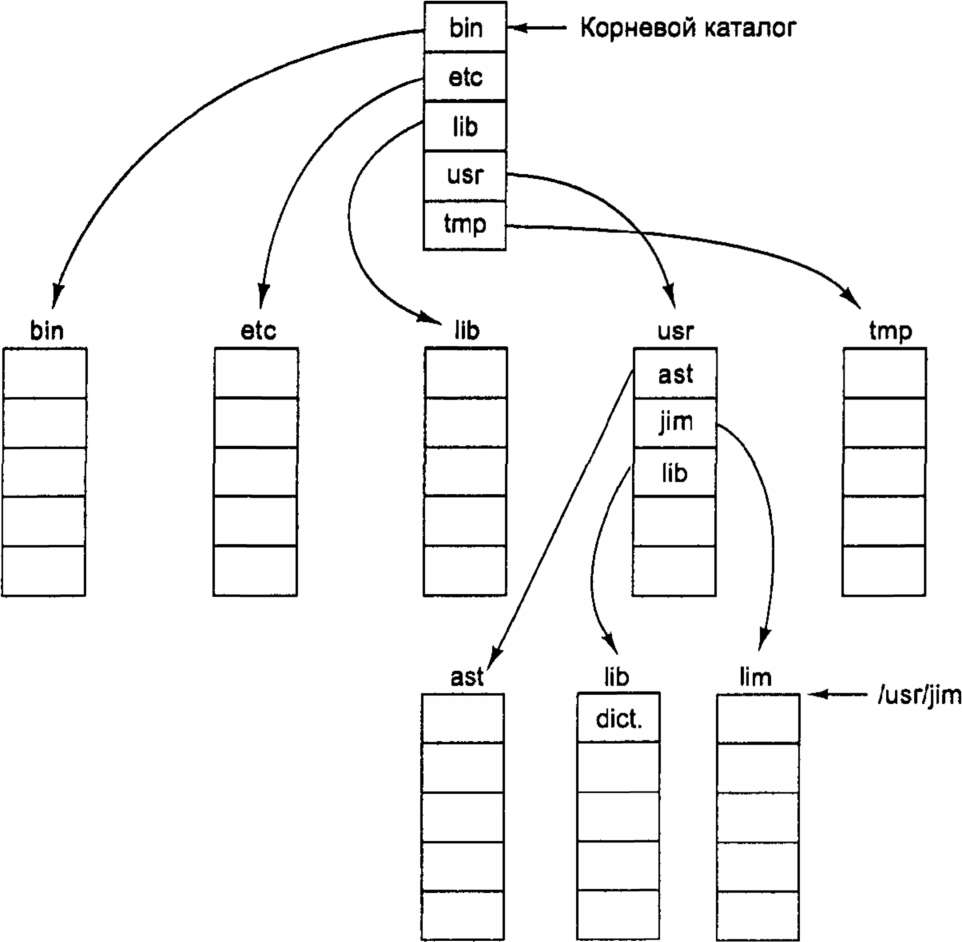
Більшість операційних систем, що підтримують ієрархічні каталоги, мають спеціальні елементи в кожному каталозі. Це "."і"..", що означають поточний каталог і батьківський каталог. Щоб продемонструвати, як це працює, звернемося до дерева каталогів системи UNIX, показаного на мал. 6.7. Для деякого процесу каталог /usr/ast є робітником. Щоб переміститися вгору по дереву, він може використовувати позначення ".". Наприклад, він може копіювати файл /usr/lib/dictionary у свій власний каталог за допомогою команди
ср../lib/dictionary .
Дві точки є інструкцією системі піднятися вгору (у каталог usr). Після цього треба відкрити каталог lib і знайти в нім файл dictionary.
Поодинока точка означає поточний каталог. Коли команда ср в якості аргумент отримує точку, вона інтерпретує її як поточний каталог і копіює усі файли туди. Звичайно, ту ж команду можна було задати і так:
ср/usr/lib/dictionary .
Тут використання точки дозволяє заощадити час, що витрачає користувач на набір слова dictionary другий раз. Проте команда
ср /usr/lib/dictionary dictionary
також прекрасно працює і робить те ж саме, що і команда
ср /usr/lib/dictionary /usr/ast/dictionary
Усі ці команди виконують одні і ті ж дії.
Операції з каталогами
Системні виклики, що управляють каталогами, значно менш схожі в різних системах, чим системні виклики для роботи з файлами. Щоб дати уявлення про те, що вони є і як працюють, наведемо наступний приклад (узятий з UNIX).
Create. Створити каталог. Тільки що створений каталог порожній і не містить інших елементів, окрім "". і "..", що автоматично поміщаються в каталог операційною системою
Delete. Видалити каталог. Може бути видалений тільки порожній каталог. елементи "." і ".." файлами не являються і видалені бути не можуть.
Opendir. Відкрити каталог. Після цієї операції каталог може бути прочитаний. Наприклад, для друку усіх файлів, що містяться в каталозі, програма, що створює лістинг, відкриває каталог, щоб прочитати імена усіх файлів, що містяться в нім. Перш ніж каталог може бути прочитаний, його слід відкрити, подібно до відкриття і читання файлу.
CIosedir. Закрити каталог. Коли каталог прочитаний, його слід закрити, щоб звільнити місце у внутрішній таблиці.
Readdіr. Прочитати наступний елемент відкритого каталогу. У колишні часи було можливо читати каталоги за допомогою звичайного системного виклику read, але такий підхід був небезпечний, оскільки вимагав від програміста уміння працювати з внутрішньою структурою каталогів. Тому був створений окремий системний виклик readdir, що завжди повертає один запис ката-балки стандартного формату незалежно від використовуваної структури каталогів.
Rename. Перейменування каталогу. У багатьох відношеннях каталоги аналогічні файлам і можуть перейменовуватися так само, як і файли.
Link. Зв'язування є технікою, що дозволяє файлу з’являтися відразу в декількох каталогах. Цей системний виклик приймає як вхідні параметри ім'я файлу і ім'я шляху і створює зв'язок між ними. Таким чином, один і той же файл може з'являтися відразу в декількох каталогах. Подібний зв'язок, що збільшує на одиницю лічильник i-вузла файлу (для обліку кількості каталогів з посиланнями на цей файл), іноді називається жорстким зв'язком.
Unlink. Видалення посилання на файл з каталогу. Якщо файл є присутній тільки в одному каталозі, то цей системний виклик видалить його з файлової системи. Якщо існує декілька посилань на цей файл, то буде видалено тільки вказане посилання, а інші залишаться. Цей системний виклик застосовується для видалення файлу в операційній системі UNIX.
Приведений вище список містить найбільш важливі системні виклики, але існує також множина інших, наприклад для управління захистом інформації.
Реалізація файлової системи
Тепер пора перейти від розгляду файлової системи з точки зору користувача до розгляду з точки зору розробника системи. Користувачів цікавить те, як називаються файли, які операції можливі з ними, як виглядає дерево каталогів і тому подібні інтерфейсні питання. Проектувальники файлових систем цікавляться тим, як зберігаються файли і каталоги, як відбувається управління дисковим простором і як добитися надійної і ефективної роботи файлової системи. У наступних розділах ми познайомимося з цією точкою зору на файлову систему.
Структура файлової системи
Файлові системи зберігаються на дисках. Більшість дисків діляться на декілька розділів з незалежною файловою системою на кожному розділі. Сектор 0 диска називається головним завантажувальним записом (MBR, Master Boot Record) і використовується для завантаження комп'ютера. У кінці головного завантажувального запису міститься таблиця розділів. У цієї таблиці зберігаються початкові і кінцеві адреси (номери блоків) кожного розділу. Один з розділів помічений в таблиці як активний. При завантаженні комп'ютера BIOS прочитує і виконує MBR-запис, після чого завантажник в MBR-записи визначає активний розділ диска, прочитує його перший блок, званий завантажувальним, і виконує його. Програма, що знаходиться в завантажувальному блоці, завантажує операційну систему, що міститься в цьому розділі.
Для одноманітності кожен дисковий розділ починається із завантажувального блоку, навіть якщо в нім не міститься завантажувальна операційна система. До того ж в цьому розділі може бути надалі встановлена операційна система, тому зарезервований завантажувальний блок виявляється корисним.
В усьому іншому будова розділу диска міняється від системи до системи. Часто файлові системи містять деякі з елементів, показаних на мал. 6.8. Один з таких елементів, званий суперблоком, містить ключові параметри файлової системи і прочитується в пам'ять при завантаженні комп'ютера або при першому зверненні до файлової системи. Типова інформація, що зберігається в суперблоці, включає "магічне" число, що дозволяє розрізняти системні файли, кількість блоків у файловій системі, а також іншу ключову адміністративну інформацію.

Мал. 6.8. Можлива структура файлової системи.
Услід розташовується інформація про вільні блоки файлової системи, напри-мер у вигляді бітового масиву або списку покажчиків. За цими даними може слідувати інформація про і-узлах, структур даних, що є масивом, по одній структурі на файл, що містять усю інформацію про файли. Далі може розміщуватись кореневий каталог, що містить вершину дерева файлової системи. На кінець, решту місця дискового розділу займають усі інші каталоги і файли.
Реалізація файлів
Ймовірно, найбільш важливим моментом в реалізації зберігання файлів є облік відповідності блоків диска файлам. Для визначення того, який блок якому файлу належить, в різних операційних системах застосовуються особисті методи. Деякі з них будуть розглянуті в цьому розділі.
Безперервні файли
Простою схемою виділення файлам певних блоків на диску є система, в якій файли є безперервними наборами сусідніх блоків диска. Тоді на диску, що складається з блоків по 1 Кбайт, файл розміром в 50 Кбайт займатиме 50 послідовних блоків. При 2-кілобайтних блоках такий файл займе 25 сусідніх блоків.
Приклад
безперервних файлів показаний на мал.
6.9, а.
Тут показані перші 40 блоків диска,
починаючи з блоку 0, ліворуч. Спочатку
диск був порожній. Потім на диск, починаючи
з блоку 0, був записаний файл А завдовжки
в чотири блоки. Після нього був записаний
шестиблоковий файл В, упритул до файлу
А. Зверніть увагу, що кожний файл
починається з нового блоку, так що якщо
довжина файлу А дорівнювала ![]() блоку, деяке місце у кінці останнього
блоку файлу пропадає. На малюнку усього
показано сім файлів. Кожен наступний
файл починається з блоку, наступного
за останнім блоком попереднього файлу.
Затінювання використовується тільки
для того, щоб було легше розрізняти
окремі файли.
блоку, деяке місце у кінці останнього
блоку файлу пропадає. На малюнку усього
показано сім файлів. Кожен наступний
файл починається з блоку, наступного
за останнім блоком попереднього файлу.
Затінювання використовується тільки
для того, щоб було легше розрізняти
окремі файли.
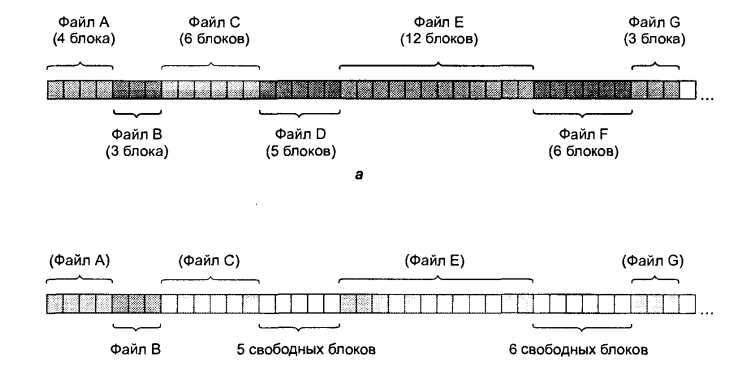
Мал 6.9. Сім неперервних файли на диску (а); стан диску після видалення двох файлів (б)
У неперервних файлів є дві суттєві переваги. По-перше, таку систему легко реалізувати, так як системі, щоб визначити, які блоки належать тому чи іншому файлу, потрібно слідкувати лише за двома числами: номером першого блоку файлу і числом блоків у файлі. Знаючи перший блок файлу, любий інший його блок легко отримати за допомогою простої операції додавання.
По-друге, при роботі з неперервними файлами продуктивність просто чудова, так як весь файл може бути прочитаний з диску за одну операцію. Потрібна лише одна операція пошуку (для першого блоку). Після цього більше не потрібно шукати циліндри і витрачати час на чекання, коли диск закрутиться, через це дані можуть зчитуватись з максимальною швидкістю, на яку здатен диск. Таким чином, неперервні файли легко реалізуються и мають високу продуктивність.
Нажаль, у такого способу розподілення дискового простору є серйозний недолік: з часом диск стає фрагментованим. Щоб зрозуміти, як це відбувається, розглянемо мал. 6.9, б. Два файли, D і F, були видалені. Коли файл видаляється, його блоки звільняються, залишаючи проміжки вільних блоків на диску. У міру видалення файлів диск стає усе більш "дірявим".
Спочатку ця фрагментація не представляє проблеми, оскільки кожен новий файл може бути записаний в кінець диска, услід за попереднім файлом. Проте врешті-решт диск заповниться і або потрібна буде спеціальна операція по ущільненню використовуваного простору диску, або потрібно буде знайти спосіб використовувати вільний простір на місці видалених файлів. Для повторного використання простору, що звільнився, потрібно буде містити список порожніх ділянок, що в принципі здійснимо. Проте при створенні нового файлу буде необхідно знати його остаточний розмір, щоб вибрати для нього ділянку відповідного розміру.
Уявіть собі наслідки такої структури. Користувач запускає текстовий редактор або текстовою процесор, щоб створити документ. Перше, що цікавить програму, це скільки байтів буде в документі. На це питання треба дати відповідь, інакше програма не зможе працювати. Якщо користувач вкаже занадто маленьке число, програма може закінчитися аварійно, так як вільна ділянка диска виявиться заповненою і буде ніде розмістити іншу частину файлу. Якщо користувач спробує обійти цю проблему, задавши свідомо великий остаточний розмір, наприклад 100 Мбайт, може статися, що редактор не зможе знайти таку велику вільну ділянку і повідомить, що не може створити файл. Звичайно, користувач може понизити свої вимоги до 50 Мбайт і т. д. до тих пір, поки не знайдеться вільна ділянка, що підходить. Проте така схема навряд чи задовольнить користувача.
І все-таки є ситуації, в яких безперервні файли можуть застосовуватись і справді широко використовуються, : на компакт-дисках. Тут усі розміри файлів відомі заздалегідь і не можуть мінятися при наступному використанні файлової системи CD - ROM. Найбільш поширену файлову систему CD - ROM ми розглянемо нижче в цій главі.
Як вже говорилося в главі 1, в кібернетиці історія часто повторюється з появою нових технологій. Файлові системи, що складаються з безперервних файлів, застосовувалися на магнітних дисках багато років тому завдяки їх просто-те і високій продуктивності (зручність для користувачів майже не приймалось тоді в розрахунок). Потім ця ідея була забута із-за необхідності задавати остаточний розмір файлу при його створенні. Але з появою CD - ROM і DVD, а також інших одноразових оптичних носіїв про переваги не-переривчастих файлів згадали знову. Вивчення старих систем і ідей виявляється корисним, оскільки багато простих і ясних концепцій тих систем знаходять застосування в нових системах самим дивним чином.
Зв'язні списки
Другий метод розміщення файлів полягає в поданні кожного файлу у вигляді зв'язного списку з блоків диска, як показано на мал. 6.10. Перше слово кожного блоку використовується як покажчик на наступний блок. У іншій частині блоку зберігаються дані.
Мал. 6.10. Розміщення файлу у вигляді зв’язного списку блоків дику.
На відміну від систем з безперервними файлами, такий метод дозволяє використовувати кожен блок диска. Немає втрат дискового простору на фрагментацію (окрім втрат в останніх блоках файлу). Крім того, в каталозі треба зберігати тільки адресу першого блоку файлу. Усю іншу інформацію можна знайти там.
З іншого боку, хоча послідовний доступ до такого файлу нескладний, довільний доступ буде досить повільним. Щоб дістати доступ до блоку n, операційна система повинна спочатку прочитати перші n - 1 блоків по черзі. Очевидно, така схема виявляється дуже повільною.
Крім того, розмір блоку зменшується на декілька байтів, потрібних для зберігання покажчика. Хоча це і не смертельно, але розмір блоку, що не являється степенем двох, буде менш ефективним, оскільки багато програм читають і пишуть блоками по 512, 1024, 2048 і т. д. байтів. Якщо перші декілька байтів кожного блоку будуть зайняті покажчиком на наступний блок, то для читання блоку повного розміру доведеться прочитувати і об'єднувати два сусідні блоки диска, для чого буде потрібно виконання додаткових операцій.
Зв'язний список за допомогою таблиці в пам'яті
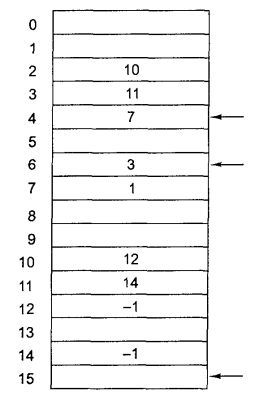
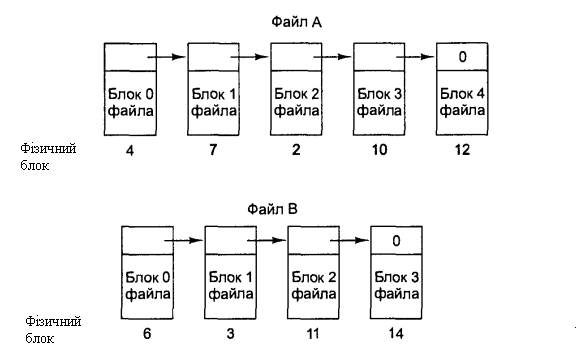
Обидва недоліки попередньої схеми організації файлів у вигляді зв'язних списків можуть бути усунені, якщо покажчики на наступні блоки зберігати не прямо в блоках, а в окремій таблиці, що завантажується в пам'ять. На мал. 6.11 показаний зовнішній вигляд такої таблиці для файлів з мал. 6.10. На обох малюнках показано два файли. Файл А використовує блоки диска 4, 7, 2,10 і 12, а файл В використовує блоки диска 6, 3,11 і 14. За допомогою таблиці, показаної на мал. 6.11, ми можемо почати з блоку 4 і слідувати по ланцюжку до кінця файлу. Те ж може бути зроблене для другого файлу, якщо почати з блоку 6. Обидва ланцюжки завершуються спеціальним маркером (наприклад - 1), що не є допустимим номером блоку. Така таблиця, що загружається в оперативну пам'ять, називається FAT – таблицею (File Allocation Table - таблиця розміщення файлів).
Фізичний блок
Файл А починається
тут
Файл В починається
тут
Блок, що не
використовується