Мал. 6.24.Структура даних блочного кеша
Коли вимагається завантажити блок в заповнений до межі кеш, який-небудь інший блок має бути видалений з кеша (і записаний на диск, якщо він був модифікований в кеші). Ця ситуація дуже схожа на сторінкову організацію пам'яті, і до неї застосовані усі звичайні алгоритми заміни, описані в главі 3, такі як FIFO (First in First Out - першим прибув - першим обслужений), "друга спроба" і LRU (Least Recently Used - з найбільш давнім використанням). Одна приємна відмінність кешування від сторінкової організації пам'яті полягає в тому, що звернення до кеша проводяться відносно нечасто, що дозволяє зберігати усі блоки в точному LRU-порядку із зв'язними списками.
На мал. 2.24 ми бачимо, що на додаток до ланцюгів, що починаються в хеш-таблиці використовується також і двонаправлений список, в якому містяться номери усіх блоків в порядку їх використання. При цьому найстаріший блок поміщається в початок списку, а найновіший блок - в його кінець. При зверненні до блоку блок може переміщатися зі своєї поточної позиції в кінець двонаправленого списку. Таким чином, може підтримуватися точний LRU -порядок.
На жаль, тут є одна заковика. Тепер, коли ми можемо реалізувати точне виконання алгоритму LRU, виявляється, що алгоритм LRU є небажаним. Викликано це тим, що буквальне застосування алгоритму LRU знижує надійність файлової системи і погрожує її несуперечності (що обговорювалось в попередньому розділі). Якщо в кеш прочитується і модифікується критичний блок, наприклад блок i-вузла, але не записується тут же на диск, то комп'ютерний збій може привести до того, що файлова система опиниться в суперечному стані. Якщо блок i-вузла помістити в кінець ланцюжка LRU, то може пройти досить багато часу, перш ніж цей блок потрапить в її початок і буде записаний на диск.
Більше того, до деяких блоків, таким як блоки i-вузлів, програми рідко звертаються двічі протягом короткого інтервалу часу. Виходячи з цих повідомлень, ми приходимо до модифікованої схеми LRU, приймаючи до уваги два наступні чинники:
Наскільки велика вірогідність того, що цей блок скоро знову знадобиться?
Чи важливий цей блок для несуперечності файлової системи?
Для відповіді на кожне з цих питань блоки можна розділити на такі категорії, як блоки i-вузлів, непрямі блоки, блоки каталогів, блоки, повні даних, і блоки, частково заповнені даними. Блоки, які, ймовірно, не знадобляться знову найближчим часом, поміщаються в початок списку LRU, щоб займані ними буфери могли незабаром звільнитися. Блоки, вірогідність повторного використання яких найближчим часом висока (наприклад, записуючі блоки, частково заповнені даними), поміщаються в кінець списку LRU, що дозволяє ним залишатися в кеші більше довгий час.
Друге питання не пов'язане з першим. Якщо блок представляє важливість для несуперечності файлової системи (звичайно це усе блоки, окрім блоків даних) і такий блок модифікується, то його слід негайно зберегти на диску незалежно від його положення в списку LRU. Швидко записуючи критичні блоки, ми значно знижуємо вірогідність того, що збій комп'ютера пошкодить файлову систему. Користувач навряд чи буде рад втраті одного зі своїх фай-лов із-за збою комп'ютера. Ще більше він засмутиться, якщо при цьому зіпсованою виявиться уся файлова система.
Навіть при вживанні усіх перерахованих вище заходів обережності по підтримці в робочому стані файлової системи занадто довге зберігання в кеші блоків з даними є небажаним. Уявіть собі користувача, що працює на персональному комп'ютері над написанням книги. Навіть якщо наш письменник періодично велить текстовому редакторові зберігати редактований файл на диску, є велика вірогідність, що усі блоки залишаться в кеші. Якщо станеться збій, структура файлової системи не постраждає, але робота цілого дня роботи буде втрачена.
Ця ситуація трапляється не занадто часто, якщо тільки з дуже невдачливими користувачами. Для вирішення цієї проблеми зазвичай застосовується два методи. У системі UNIX є системний виклик sync, що змушує збереження усіх модифікованих блоків кеша на диску. При завантаженні операційної системи запускається фонове завдання, зазвичай update, що називається, уся робота якої заключається в періодичному (зазвичай через кожні 30 с) зверненні до системного виклику sync. В результаті при будь-якому збої буде втрачено не більше 30 з роботи.
У системі MS - DOS використовується інший підхід, що полягає в тому, що кожен модифікований блок записується на диск відразу ж. Кеш, в якому усі модифіковані блоки негайно записуються на диск, називаються наскрізним кешем або кешем з наскрізним записом. При використанні наскрізного кеша кількість звернень вводу-виводу до диска більше, ніж при застосуванні звичайного кеша. Щоб краще зрозуміти різницю в цих двох підходах, уявіть собі програму, що записує блок розміром в 1 Кбайт по одному символу. Система UNIX збиратиме усі символи в кеші і записуватиме цей блок на диск кожні 30 з або коли блок буде видалений з кеша. Система MS - DOS звертатиметься до диска при кожному записуваному символі. Звичайно, більшістю програм застосовується внутрішня буферизація, тому зазвичай вони звертаються до системного виклику write не з одним символом, а з цілими рядками або великими одиницями даних.
Результатом відмінності стратегій кешування виявляється той факт, що просте видалення (гнучкого) диска з системи UNIX, без виконання системного виклику sync, майже завжди приведе до втрати даних і часто також до ушкодження файлової системи. У MS - DOS такої проблеми не виникає. Така відмінність в стратегаях пов'язана з тим, що система UNIX розроблялася в середовищі, в якому усі диски були жорсткими і постійними, тоді як система MS - DOS спочатку призначалася для роботи з гнучкими дисками. Коли жорсткі диски стали нормою, ефективніший метод, що застосовується в UNIX, став нормою і тепер також використовується в Windows для жорстких дисків.
Випереджаюче читання блоку
Другий метод збільшення продуктивності файлової системи полягає в спробі отримати блоки диска в кеш перш, ніж їх буде потрібно. Зокрема, багато файлів прочитуються послідовно. Коли файлова система отримує запит на читання блоку k файлу, вона виконує його, але після цього відразу перевіряє, чи є в кеші блок k + 1. Якщо цього блоку в кеші немає, файлова система читає його в надії, що до того моменту, коли він знадобиться, цей блок вже буде прочитаний в кеш. В крайньому випадку, він вже буде на шляху туди.
Звичайно, така стратегія працює тільки для тих файлів, які прочитуються послідовно. Якщо звернення до блоків файлу проводяться у випадковому порядку, випереджаюче читання не допомагає. Насправді, не хотілося б обтяжувати диск прочитуванням непотрібних блоків і видаленням потенційно корисних блоків з кеша (можливо, тим самим ще більше обтяжуючи диск необхідністю записувати ці блоки на диск, якщо вони модифіковані). Щоб визначити, чи слід використовувати випереджаюче читання блоків, файлова система може вести облік доступу до блоків кожного відкритого файлу. Наприклад, для кожного відкритого файлу один біт може означати "режим послідовного доступу" або "режим довільного доступу". Спочатку кожному файлу, що відкривається, відповідно до принципу презумпції невинності призначається режим послідовного до-ступа. Проте при переміщенні покажчика у файлі цей біт скидається. Якщо до цього файлу знову поводитимуться із запитами послідовного читання, біт буде встановлений знову. Таким чином, файлова система може будувати припущення про те, чи слід їй виконувати операції випереджаючого читання або ні. Якщо вона і помилятиметься час від часу, то нічого страшного не станеться, просто буде витрачений даремно деякий відсоток пропускної спроможності диска.
Зниження часу переміщення блоку голівок
Кешування і випереджаюче читання є не єдиними способами збільшення продуктивності системи. Інший важливий метод полягає в зменшенні витрат часу на переміщення блоку голівок. Досягається це приміщенням блоків, до яких висока вірогідність доступу протягом короткого інтервалу часу, близько один до одного, бажано на одному циліндрі. Коли записується вихідний файл, файлова система повинна зарезервувати місце для читання таких блоків за одну операцію. Якщо вільні блоки враховуються в бітовому мас-сиве, а увесь бітовий масив поміщається в оперативній пам'яті, то досить легко вибрати вільний блок як можна ближче до попереднього блоку. У разі коли вільні блоки зберігаються в списку, частина якого в оперативній пам'яті, а частина на диску, зробити це значно важче.
Проте навіть при використанні списку вільних блоків може бути виконана певна кластеризація блоків. Хитрість полягає в тому, щоб враховувати місце на диску не в блоках, а в групах послідовних блоків. Якщо сектор складається з 512 байт, система може використовувати блоки розміром в 1 Кбайт (2 сектори), але виділяти простір на диску в одиницях по 2 блоки (4 сектори). Це не те ж саме, що використання 2-кілобайтних дискових блоків, оскільки кеш як і раніше використовуватиме кілобайтні блоки і дискові операції читання і запису як і раніше працюватимуть з кілобайтними блоками. Проте при послідовному читанні файлу кількість операцій пошуку циліндра зменшиться удвічі, що значно збільшить продуктивність. Варіація цієї ж теми полягає в спробі системи врахувати позицію блоку в циліндрі.
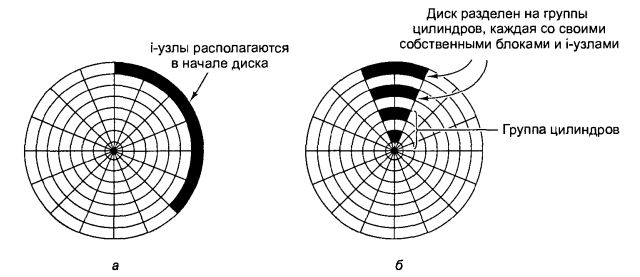
Ще один чинник, що знижує продуктивність файлових систем, пов'язаний з тим, що при використанні і-вузлів або чого-небудь еквівалентного їм, особливо при читанні коротких файлів, потрібно два звернення до диска замість одного: одне для і-вузла і одне для блоку даних. Звичайне розміщення і-вузлів на диску показане на мал. 6.25, а. Тут усі і-вузли розташовуються на початку диска, так що середня відстань між і-вузлом і його блоками складатиме біля половини кількості циліндрів, тобто при доступі практично до кожного файлу знадобляться значні переміщення блоку голівок.