

14. Свойства символа Лиспа.
В Лиспе с символом можно связать именованные свойства. Свойства символа записываются в хранимый вместе с символом список свойств.
Список свойств может быть пуст или содержать произвольное количество свойств
![]()
Список свойств символа можно использовать без особых ограничений, его можно по необходимости обновлять или удалять.
Значение и определение функции являются встроенными системными свойствами, которые управляют работой интерпретатора в различных ситуациях. Функции, используемые для чтения и изменения этих свойств (SETQ, SYMBOL-VALUE, DEFUN, FUNCTION-VALUE и другие), мы уже
ранее рассматривали. Весь список свойств также является системным свойством. Работающие со свойствами символов прикладные системы могут свободно определять новые свойства.
Чтение свойства
Выяснить значение свойства, связанного с символом, можно с помощью функции GET:
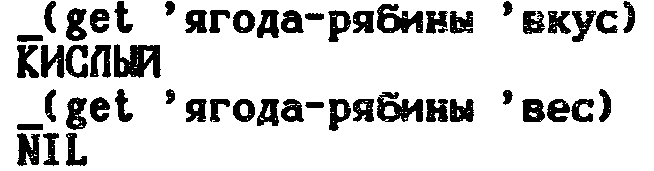
Присваивание свойства
Свойства символов находятся в связанных с символами ячейках памяти, для присваивания значений которым используется обобщенная функция присваивания SETF.
Присваивание свойства осуществляется через функции SETF и GET следующим образом:
![]()
Здесь вызов GET возвращает в качестве значения ячейку памяти для данного свойства, содержимое которой обновляет вызов SETF. Присваивание будет работать и в том случае, если ранее у символа не было
такого свойства.

Удаление свойства
Удаление свойства и его значения осуществляемся псевдофункцией RЕМPROР:
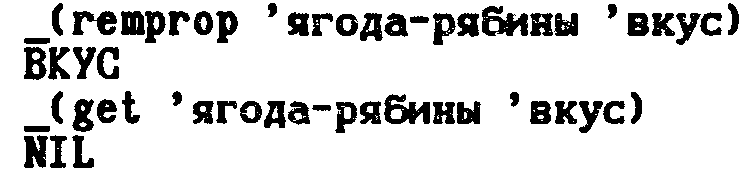
Читать из списка свойств, создавать и обновлять в нем свойства можно не только по отдельности, но и целиком.
![]()
![]()
Свойства символов независимо от их значений доступны из всех контекстов до тех пор, пока они не будут явно изменены или удалены. Использование символа в качестве функции или переменной, т.е. изменение
значения символа или определения функции, не влияет на другие свойства символа, и они сохраняются.
15. Ввод и вывод в Лиспе.
Лисповская функция чтения READ отличается от ввода в других языках программирования тем, что она обрабатывает выражение целиком, а не одиночные элементы данных. Как только интерпретатор встречает предложение READ, вычисления приостанавливаются до тех пор, пока пользователь не введет какой-нибудь символ или целиком выражение:

Обратите внимание, READ никак не показывает, что он ждет ввода выражения. Программист должен сам сообщить об этом при помощи рассматриваемых позже функций вывода. READ лишь читает выражение и
возвращает в качестве значения само это выражение, после чего вычисления продолжаются. У приведенного выше вызова функции READ не было аргументов, но у
этой функции есть значение, которое совпадаете введенным выражением. По своему
действию READ представляет собой функцию, но у нее есть побочный эффект, состоящий именно во вводе выражения. Если прочитанное значение необходимо сохранить для дальнейшего использования, то вызов READ должен быть аргументом какой-нибудь формы, например присваивания (SETQ), которая свяжет полученное выражение:

Процедура чтения содержит анализатор, проверяющий знаки в читаемой им
последовательности. Знаки, вызывающие специальные действия, называют макрознаками или макросами чтения , поскольку их чтение требует более сложных действий. Определим для примера макрос чтения %, действующий так же, как апостроф.
Действие блокировки вычисления пользователь может определить в виде функции, которая рекурсивно читает очередное выражение и возвращает его в составе формы QUOTE:
![]()
Запись символов и определенных для них макроинтерпретаций в таблицу чтения осуществляется командой
![]()
Здесь запись #\% обозначает знак процента (%) как объект с типом данных знак (в дальнейшем к типам данных мы вернемся подробнее).
Встроенными макросами чтения в Коммой Лиспе являются:

![]()
Читая и интерпретируя знаки, процедура чтения пытается строить атомы и из них списки. Прочитав имя символа, интерпретатор ищет, встречался ли ранее такой символ или он неизвестен. Для нового символа
нужно зарезервировать память для возможного значения, определения функции и других свойств.
Можно пользоваться несколькими различными списками объектов, которые называют пакетами или пространствами имен. Символы из различных пространств, имеющие одинаковые имена, могут использоваться различным образом. Это необходимо при построении
больших систем, при программировании различных ее подсистем программисты
частенько используют одинаковые имена для различных целей.
Перед использованием такой записи необходимо, чтобы символ, на который ссылаются, был объявлен внешней переменной пространства имен.
![]()
Для вывода выражений можно использовать функцию PRINT. Это функция с одним аргументом, которая сначала вычисляет значение аргумента, а затем выводит это значение. Функция PRINT перед выводом
аргумента переходит на новую строку, а после него выводит пробел.
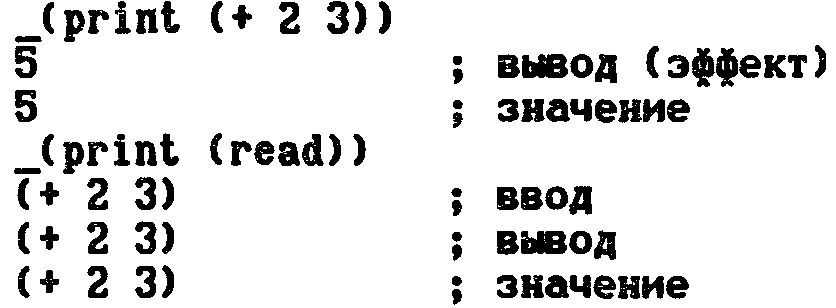
Лисповские операторы ввода-вывода, как и присваивания, очень гибки, поскольку их можно использовать в
качестве аргументов других функций, что в других языках программирования обычно невозможно:

Если желательно вывести последовательно на одну строку более одного выражения, то можно использовать функции PR1N1 или PRINC. PRIN1 работает так же, как PRINT, но не переходит на новую строку и не
выводит пробел:
![]()
Более приятный вид с точки зрения пользователя можно получить при помощи функции PRINC Она выводит лисповские объекты в том же виде как и PRIN1, но преобразует некоторые типы данных в более
простую форму. Такие выведенные выражения нельзя прочесть и получить выражения, логически идентичные выведенным. Функцией PRINC мы можем напечатать строку без ограничивающих ее кавычек и
специальные знаки без их выделения:
![]()
Перевод строки можно осуществить функцией PRINT, которая автоматически переводит строку перед выводом, или непосредственно для этого предназначенной функцией TERRRI . У функции TERPRI нет аргументов и в качестве значения она возвращает NIL:


![]()
Гибкость функции FORMAT основана на использовании управляющих кодов. Они выводят в порядке их появления слева направо каждый очередной отформатированный аргумент или осуществляют какие-нибудь действия, связанные с выводом.

Файлы используются, как правило, лишь для хранения программ в промежутке между сеансами. Ввод и вывод осуществляются независимо от конфигурации внешних устройств через потоки . Потоки представляют собой специальные резервуары данных, из которых можно читать ) или в которые можно писать (поток вывода) знаки или двоичные данные.
![]()
Если мы хотим обмениваться данными с каким-нибудь новым файлом, то сначала его нужно открыть в зависимости от его использования для чтения или для записи.

Потоковый объект, получаемый в результате вызова OPEN, можно для следующего
использования присвоить какой-нибудь переменной:
![]()
Этот вызов присваивает переменной ПОТОК
Наряду с файлами по умолчанию, другим способом задать источник для ввода или получатель для вывода является передача желаемого потока в качестве параметра вызова. Для функций READ, PRINx и TERPRI это осуществляется через
необязательный параметр. Более подробным описанием параметров этих функций будет:

Чтобы записанные в файл данные сохранились, надо не забыть закрыть файл директивой CLOSE:
![]()
Вообще-то работа с файлами более удобна через форму WITH-OPEN-FILE.
Вызов WITH-OPEN-FILE позволяет открыть определенный в пределах формы поток, который автоматически создается в самом начале вычислений и закрывается
после hx завершения
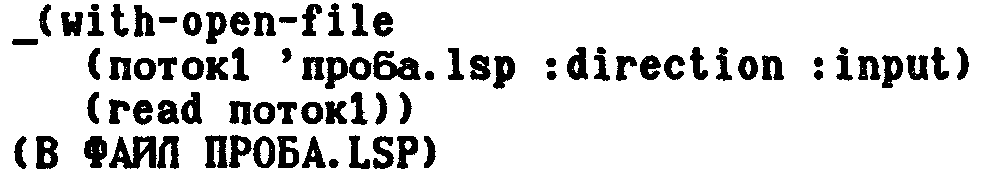
LOAD загружает определения
На практике написание программ осуществляется записью в файл определений функций, данных и других объектов с помощью имеющегося в программном окружении редактора. После этого для проверки
определений вызывают интерпретатор Лиспа, который может прочитать записанные в файл выражения директивой LOAD:
![]()
Читаемые выражения вычисляются так, как будто бы они были введены пользователем. После загрузки можно использовать функции, значения переменных, значения свойств и другие определения.