

1.4.3. Характеристика методів дейтамайнінгу
Існує два взаємозалежні методи аналізу даних: профайлінг даних і дейтамайнінг (Data Mining).
Профайлінг даних орієнтовано на попередній аналіз окремих атрибутів даних. При цьому здійснюється отримання, наприклад, такої інформації, як тип, довжина, спектр значень, дискретність значень даних та їх частота, зміни, унікальність, наявність невизначених значень, типових строкових моделей (наприклад, для номерів телефонів) та ін., що дозволяє забезпечити точне уявлення різних аспектів якості атрибута.
Дейтамайнінг допомагає знайти специфічні моделі у великих наборах даних, наприклад, взаємовідношення між різними атрибутами. Саме на це спрямовано так звані описові моделі дейтамайнінгу, які включають групи, узагальнення, пошук асоціацій і послідовностей. При цьому можуть бути отримані обмеження цілісності в атрибутах. Наприклад, функціональні залежності чи характерні для певних програм бізнес-правила, які можна використовувати для поповнення втрачених та виправлення неприпустимих значень, а також для виявлення дублікатів записів у джерелах даних.
-
Data Mining (Добування даних) — виявлення прихованих закономірностей або взаємозв’язків між змінними у великих масивах необроблених даних. Як правило поділяється на завдання класифікації, моделювання та прогнозування.
Проблема аналізу накопичених історичних даних чи даних транзакцій щодо операційних процесів (предметна область дейтамайнінгу) вже має достатній досвід використання на Заході, але у нас тільки починає використовуватись. Традиційно мають місце два типи статистичних аналізів: підтверджувальний аналіз (confirmatory analysis) і дослідницький аналіз (exploratory analysis). У підтверджувальному аналізі аналітик повинен мати конкретну гіпотезу і в результаті проведення аналізу цю гіпотезу або підтверджує або спростовує. Найбільш проблемним місцем у підтверджувальному аналізі є недостатність для аналітиків готових гіпотез чи їх окремих аспектів. У процесі дослідницького аналізу система перевіряє, підтверджуються або спростовуються підходящі до проблемної ситуації гіпотези, тобто система, а не користувач бере ініціативу на себе під час аналізу даних.
Концепція «ініціативи» також стосується багатовимірних просторів даних, що досліджуються, а відтак, наявність СД є необхідною передумовою успішного дейтамайнінгу. У випадку звичайного доступу до OLAP-системи користувачеві зазвичай потрібно сформулювати гіпотези і генерувати взірці (шаблони). В умовах дейтамайнінгу подібна система сама генерує запити. У більшості випадків термін «дейтамайнінг» використовується для опису автоматизованого процесу аналізу даних, в якому система сама бере ініціативу генерувати зразки результатної інформації, тобто за своєю суттю дейтамайнінг належить до інструментальних засобів дослідницького аналізу.
З точки зору орієнтації на дослідницький процес існують три класи процесів або методів дейтамайнінгу, які дозволяють комплексно уявити податкову аналітику (рис. 3), а саме:
відкриття (discovery, добування корисної інформації, знань);
пророче моделювання (predictive modeling, моделювання передбачень);
аналіз аномалій (forensic analysis).
Відкриття — це процес перегляду бази даних для знаходження невидимих зразків (шаблонів, англ. pattern) без наперед визначеної ідеї або гіпотези про те, що вони взагалі можуть існувати. Тобто програма бере ініціативу на себе без попередніх міркувань з метою виявлення, що зразки або шаблони, які можуть зацікавити користувачів, існують і можуть подаватися у вигляді доречних запитів. Для великих баз даних є ймовірність існування великої кількості зразків (образів) інформації, про які користувач практично може ніколи і не здогадуватися. Ключовим питанням в даному випадку є кількість зразків, які можуть бути сформульовані і знайдені, та якість інформації, що добувається. Власно даними можливостями і визначається потужність чи придатність технологій відкриття (discovery).
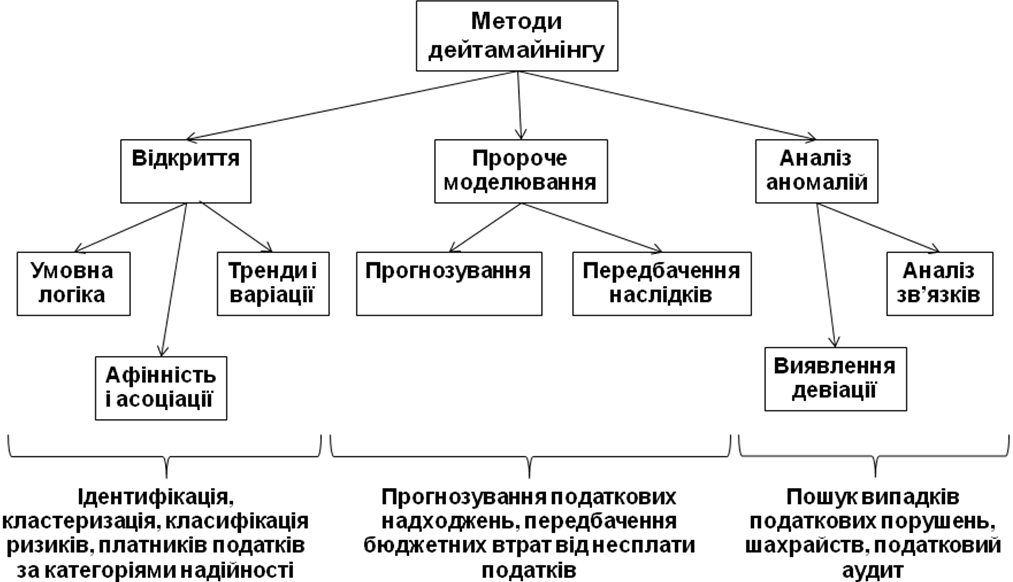
Рис. 3. Класифікація методів дейтамайнінгу
Як простий приклад відкриття за ініціативою системи можна уявити умовну базу даних платників податків з інформацією про виконання податкових платежів. Користувач може взяти ініціативу, щоб звернутися до бази даних із запитом: «Як платники податків виконують податкові платежі?» Система після аналізу може показати категорію «надійний» як очікувану ознаку сумлінних платників податків. Користувач після цього може сформулювати запит — взяти системі ініціативу не себе і знайти самостійно щось цікаве про концепцію «надійний», тобто в даному разі інформаційна система виконуватиме функції фахівця-аналітика. Система враховуватиме певні характеристики даних, розподілить їх тощо та спробує знайти деяку неординарну щільність записів. У цьому разі система може, наприклад, сформулювати правило:
«Якщо Категорія платника податків = надійний, то Показник виконання податкових платежів > 95% з впевненістю 75%».
Зазначене правило означає, що якщо ми обираємо випадково 100 надійних платників податків з бази даних, то 75 з них ймовірно матимуть близько 95% рівня сплати податкових платежів.
Під час пророчого моделювання отримуються зразки з бази даних з метою передбачення майбутнього. Пророче моделювання дозволяє користувачеві створити запис з деякими невідомими дослідницькими значеннями і система намагається вгадати невідомі значення, які ґрунтуються на попередніх шаблонах, що отримуються із бази даних. У той час як відкриття знаходить зразки в даних, у пророчому моделюванні застосовується зразок для вгадування значення щодо нових елементів даних, і в цьому полягає істотна різниця між цими видами процесів дейтамайнінгу.
Аналіз аномалій (forensic analysis) — це процес застосування відібраних зразків (шаблонів) для виявлення аномалій або незвичайних елементів даних. Щоб знайти незвичайний елемент, спочатку потрібно знайти те, що є нормою, а вже потім виявляти ті елементи, які відхиляються від звичайних у межах відповідної порогової величини. Необхідно звернути увагу, що процес «відкриття» допомагає знайти «звичайне знання», а процес аналізу аномалій розшукує незвичайні та специфічні випадки.
Всі зазначені методи дейтамайнінгу мають широкі можливості використання в процесах ризикоорієнтованого адміністрування податків, особливо методи класифікації та кластеризації, які дозволяють на початкових стадіях інформаційного аналізу забезпечити виявлення та ідентифікацію ризиків предметної області адміністрування податків, їх основних чинників, виконати підготовку та наступне супроводження аналітичних баз даних у середовищі сховищ інформації податкової служби.
Теоретико-методична основа методів дейтамайнінгу ґрунтується на кластерному аналізі, враховуючи поняття мір відстані або схожості з метою групування подібних елементів через обчислення ступеня близькості між об’єктами (наприклад записами), тобто міри відстані (дистанції) між ними. На прикладі ієрархічної кластеризації (рис. 4) показана можливість реалізації механізму розподілу платників податків за категоріями уваги на 3 групи відповідно до критерію «надійності».
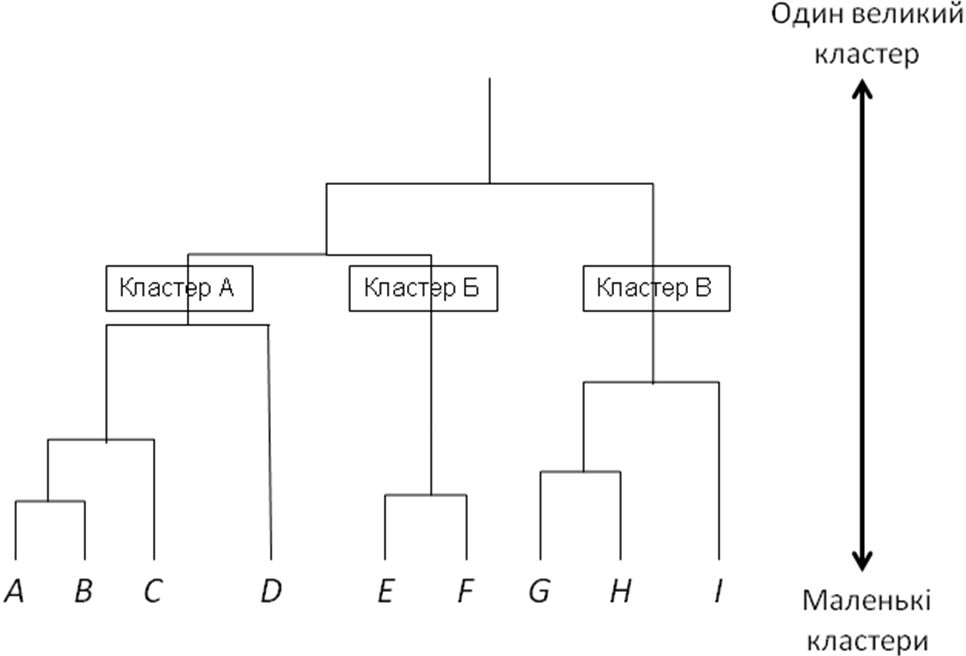
Рис. 4. Дендрограма (деревовидна схема) ієрархічних кластерів:
А — «надійні» платники податків, Б — «ризикові», В — «ненадійні»
Розглянуті в цьому підрозділі основні поняття та класифікація методів дейтамайнінгу в контексті вищенаведеної характеристики сховищ даних дозволяють дійти висновку про важливість концепції поєднаної архітектури СД з ВД, яка закладає основи ефективного використання потенціалу методів дейтамайнінгу в процесах інтелектуального аналізу даних такої предметної області, як ризикоорієнтоване адміністрування податків у процесі модернізації і реформування органів ДПС України.