

Эволюция и характеристика концепций обработки данных
Традиционные системы обработки данных представляют собой набор прикладных программ, позволяющих решать задачи пользователей, каждая из которых использует свои собственные данные и управляет ими.
Файл данных в традиционных системах обработки является простым набором записей, которые содержат логически связанные данные. Запись, в свою очередь, содержит логически связанный набор из одного или нескольких полей, каждое из которых представляет некоторую характеристику моделируемого объекта.
Обработка данных при этом велась по следующей схеме:
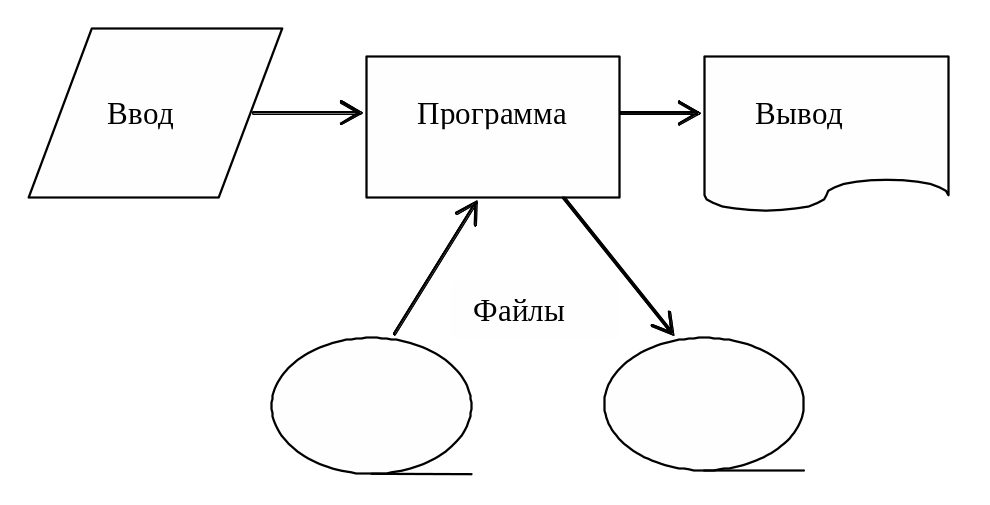
Рис. 1. Традиционный подход к обработке данных
Традиционные системы были первой попыткой компьютеризировать ручные картотеки, которые позволяют успешно справляться с поставленными задачами, если:
количество хранимых информационных объектов невелико
требуется только хранение и извлечение данных
Однако они совершенно не подходят для тех случаев, когда нужно выполнить обработку данных.
Сегодня пользователям приходится обрабатывать все большие объемы информации. В некоторых областях деятельности существуют даже правовые нормы, регламентирующие оформление ежемесячных, ежеквартальных и годовых отчетов. Ручная обработка данных не всегда подходит для выполнения работ подобного типа.
В ответ на потребность в получении более эффективных способов доступа к данным в процесс обработки были вовлечены ЭВМ. Однако вместо организации централизованного хранилища всех данных преимущественное развитие получил децентрализованный подход, при котором каждый пользователь хранил и работал со своими собственными данными. При этом при коллективной обработке данных большое их количество дублируется.
Несмотря на рост эффективности обработки данных, который обеспечил традиционный подход с использованием ЭВМ, децентрализация хранения и обработки данных имеет свои ограничения.
Ограничения, присущие файловым системам
Разделение и изоляция данных затрудняли одновременную обработку файлов. Когда данные хранятся в различных файлах, доступ к ним затруднялся в виду необходимости организации синхронной их обработки.
Децентрализация доступа и обработки данных допускает бесконтрольное дублирование информации, которое сопровождается неэффективным использованием имеющихся ресурсов. Ввод избыточных данных требует затрат дополнительного времени. Более того, для их хранения необходимо дополнительное место во внешней памяти, что связано с дополнительными накладными расходами.
Дублирование данных может привести к нарушению их целостности или к противоречивости.
Зависимость от данных. Физическая структура и способ хранения записей файлов данных определялись кодом приложения, что затрудняет изменение существующей структуры данных.
Несовместимость форматов файлов. Поскольку структура файлов определяется кодом приложений, она также зависит от языка программирования этого приложения. Например, структура файла, созданного программой на языке COBOL, может значительно отличаться от структуры файла, создаваемого программой на языке С. Прямая несовместимость таких файлов затрудняет процесс их совместной обработки.
Фиксированные запросы и быстрое увеличение количества приложений. Традиционные системы обработки данных требуют больших затрат труда программиста, поскольку все необходимые запросы и отчеты должны быть созданы именно им. В результате большинство применяемых запросов и отчетов имели фиксированную форму. Инструментов создания незапланированных запросов также не было. Со временем в подобных системах наблюдалось быстрое увеличение количества файлов данных и приложений. В конечном счете, наступал момент, когда имеющихся ресурсов ЭВМ было недостаточно для выполнения задач пользователя. В этом случае нагрузка на пользователя настолько возрастала, что программное обеспечение было неспособно адекватно отвечать запросам пользователей. При этом часто отсутствовали меры по обеспечению безопасности и целостности данных, средства восстановления в случае аппаратного или программного сбоя, доступ к файлам ограничивался узким кругом пользователей.
Все ограничения традиционного способа обработки данных с использованием ЭВМ являются следствием двух факторов.
1. определение данных содержится внутри приложений, а не хранится отдельно и независимо от них;
2. приложения являются единственным инструментом доступа к данным и их обработки.
Для повышения эффективности работы необходимо использовать новый подход, а именно базы данных и системы управления базами данных (СУБД). Пример реализации подхода с применением базы данных представлен на следующей схеме. (Рис. 2)

Рис. 2. Схема обработки данных с помощью СУБД
База данных - это совместно используемый набор логически связанных данных с их описанием, предназначенный для удовлетворения информационных потребностей пользователей.
База данных представляют единое, большое хранилище данных, которое однократно определяется, а затем используется одновременно многими пользователями. Вместо разрозненных файлов с избыточными данными все данные собраны вместе с минимальной степенью избыточности. База данных уже не принадлежит какому-либо пользователю, а является общим ресурсом. В базе данных хранятся не только рабочие данные, но и их описания. По этой причине базу данных еще называют набором интегрированных записей с самоописанием. В совокупности описание данных называется системным каталогом или словарем данных, а сами элементы описания принято называть метаданными, т.е. «данными о данных» Наличие самоописания данных в базе данных обеспечивает в ней независимость программ от данных.
СУБД - это совокупность программных и языковых средств, предназначенных для создания и ведения баз данных, поддержания целостности и организации контролируемого доступа к ним.
СУБД взаимодействует с прикладными программами пользователя и базой данных и обладает следующими возможностями:
позволяет создать базу данных, что обычно осуществляется с помощью языка определения данных (ЯОД). Язык ЯОД предоставляет пользователям средства указания типа данных, их структуры, определения ограничений для информации, хранимой в базе данных;
позволяет вставлять, обновлять, удалять и извлекать информацию из базы данных с помощью языка манипулирования данными (ЯМД). Наличие централизованного хранилища всех данных и их описаний позволяет использовать язык ЯМД как общий инструмент организации запросов,, который иногда называют языком запросов. Наличие языка запросов позволяет устранить присущие традиционным системам ограничения, при которых пользователям приходится иметь дело только с фиксированным набором запросов или постоянно возрастающим количеством программ. Наиболее распространенным типом непроцедурного языка является язык структурированных запросов (Structured Query Language — SQL), который в настоящее время определяется специальным стандартом и фактически является обязательным языком для любых реляционных СУБД.
предоставляет контролируемый доступ к базе данных с помощью следующих средств:
системы обеспечения зашиты, предотвращающей несанкционированный доступ к базе данных со стороны пользователей;
системы поддержки целостности данных, обеспечивающей непротиворечивое состояние хранимых данных;
системы управления параллельной работой приложений, контролирующей процессы их совместного доступа к базе данных;
системы восстановления, позволяющей восстановить базу данных до предыдущего непротиворечивого состояния, нарушенного в результате сбоя аппаратного или программного обеспечения;
доступного пользователям каталога, содержащего описание хранимой в базе данных информации.
Основными компонентами среды СУБД являются: аппаратное и программное обеспечение, данные, процедуры и пользователи.
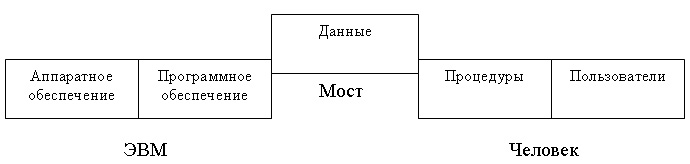
Рис. 3 Среда СУБД
Аппаратное обеспечение, используемое для работы с СУБД может варьировать в широких пределах — от единственного персонального компьютера до сети из множества ЭВМ. Используемое аппаратное обеспечение зависит от требований пользователей и типа СУБД.
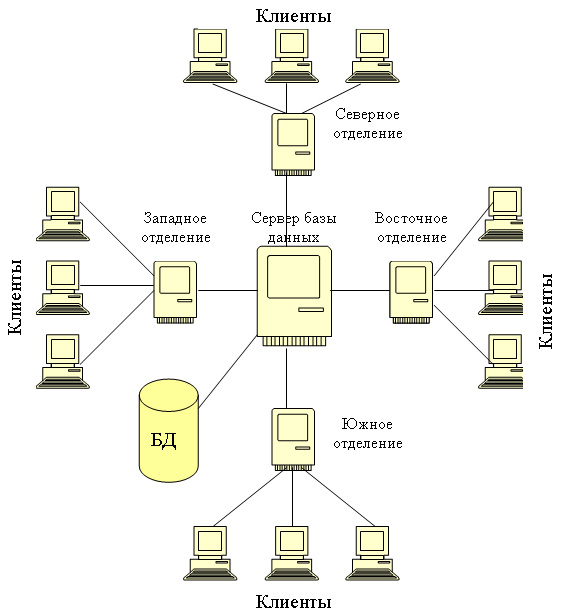
Рис. 4 Пример конфигурации аппаратного обеспечения
Программное обеспечение охватывает саму СУБД и прикладные программы, вместе с операционной системой и сетевыми программами, если СУБД используется в сети. Обычно приложения создаются на языках третьего поколения, таких как С, С++, Java, Visual Basic, COBOL, Fortran, Ada или Pascal, или на языках четвертого поколения, таких как SQL, операторы которых внедряются в программы на языках третьего поколения. СУБД может иметь свои собственные инструменты четвертого поколения, предназначенные для быстрой разработки приложений с использованием встроенных непроцедурных языков запросов, генераторов отчетов, форм, графических изображений и даже полномасштабных приложений.
Данные, с точки зрения конечных пользователей, являются самым важным компонентом среды СУБД. Они играют роль моста между компьютером и человеком. База данных содержит как рабочие данные, так и метаданные, т.е. "данные о данных".
К процедурам относятся инструкции и правила, которые должны учитываться при проектировании и использовании базы данных. Пользователям базы данных должны иметь документацию, подробно описывающую порядок использования и сопровождения данной системы. (регистрация в СУБД, использование приложений в СУБД, запуск и останов СУБД, создание резервных копий, обработка сбоев аппаратного и программного обеспечения, изменение структуры таблицы, реорганизация базы данных, размешенной на нескольких дисках, способы улучшения производительности и методы архивирования данных на вторичных устройствах хранения).
Среди пользователей СУБД можно выделить четыре основные группы: администраторы данных и баз данных, разработчики баз данных, прикладные программисты и конечные пользователи.
База данных и СУБД являются корпоративными ресурсами, которыми следует управлять так же, как и любыми другими ресурсами. Обычно управление данными и базой данных предусматривает управление и контроль за СУБД и помещенными в нее данными. Администратор данных, отвечает за управление данными, включая планирование базы данных, разработку и сопровождение стандартов, прикладных алгоритмов и деловых процедур, а также за концептуальное и логическое проектирование базы данных.
Администратор базы данных, или отвечает за физическую реализацию базы данных, включая физическое проектирование и воплощение проекта, за обеспечение безопасности и целостности данных, за сопровождение операционной системы, а также за обеспечение максимальной производительности приложений и пользователей. По сравнению с администратором данных обязанности администратора базы данных носят более технический характер, и для него необходимо знание конкретной СУБД и системного окружения.
В проектировании больших баз данных участвуют разработчики двух разных типов: разработчики логической базы данных и разработчики физической базы данных. Разработчик логической базы данных занимается идентификацией данных (т.е. сущностей и их атрибутов), связей между данными, и устанавливает ограничения, накладываемые на хранимые данные. Разработчик логической базы данных должен обладать всесторонним и полным пониманием структуры данных организации и ее делового регламента. Деловой регламент описывает основные требования к системе с точки зрения пользователей.
Для эффективной работы разработчик логической базы данных должен как можно раньше вовлечь всех предполагаемых пользователей базы данных в процесс создания модели данных. Работу разработчика логической базы данных можно разделить на два этапа.
концептуальное проектирование базы данных, которое совершенно не зависит от таких деталей ее воплощения, как конкретная СУБД, приложения, языки программирования или любые другие физические характеристики.
логическое проектирование базы данных, которое проводится с учетом особенностей выбранной модели данных: реляционной, сетевой, иерархической или объектно-ориентированной.
Разработчик физической базы данных получает готовую логическую модель данных и занимается ее физической реализацией, в том числе:
преобразованием логической модели данных в набор таблиц и ограничений целостности данных;
выбором конкретных структур хранения и методов доступа к данным, обеспечивающих необходимый уровень производительности при работе с базой данных;
проектированием мер зашиты данных.
Многие этапы физического проектирования базы данных в значительной степени зависят от выбранной СУБД, а потому может существовать несколько различных способов воплощения требуемой схемы. Следовательно, разработчик физической базы данных должен разбираться в функциональных возможностях выбранной СУБД и понимать достоинства и недостатки каждого возможного варианта реализации. Разработчик физической базы данных должен уметь выбрать наиболее подходящую стратегию хранения данных с учетом всех существующих особенностей их использования.
Если концептуальное и логическое проектирование базы данных отвечает на вопрос «что?», то физическое проектирование отвечает на вопрос «как?».
Разработку приложений, предоставляющих пользователям необходимые им функциональные возможности, выполняют прикладные программисты.
Пользователи являются клиентами базы данных — она проектируется, создается и поддерживается для того, чтобы обслуживать их информационные потребности. По степени использования системы можно выделить следующие группы пользователей:
рядовые;
опытные.
Рядовые пользователи могут и не подозревают о наличии СУБД. Они обращаются к базе данных с помощью специальных приложений, позволяющих в максимальной степени упростить выполняемые ими операции. Такие пользователи инициируют выполнение операций базы данных, вводя простейшие команды или выбирая команды меню. Таким пользователям не нужно ничего знать о базе данных или СУБД. (кассир в супермаркете).
Опытные пользователи знакомы со структурой базы данных и возможностями СУБД. Для выполнения требуемых операций они могут использовать язык запросов высокого уровня и создавать собственные прикладные программы.