

Технологии экспертных систем. Базы знаний. Извлечение знаний из данных. Информационные хранилища. Совокупная стоимость владения, решения по оптимизации. Olap-технология.
Экспертные системы -это направление исследований в области искусственного интеллекта по созданию вычислительных систем, умеющих принимать решения, схожие с решениями экспертов в заданной предметной области. Экспертные системы является плодом совместной работы экспертов в данной предметной области, инженеров по знаниям и программистов и дают возможность менеджеру или специалисту получать консультации экспертов по любым проблемам, о которых этими системами накоплены знания.
Под искусственным интеллектом обычно понимают способности компьютерных систем к таким действиям, которые назывались бы интеллектуальными, если бы исходили от человека.
Основными компонентами информационной технологии, используемой в экспертной системе, являются (рис. ): интерфейс пользователя, база знаний, интерпретатор, модуль создания системы.
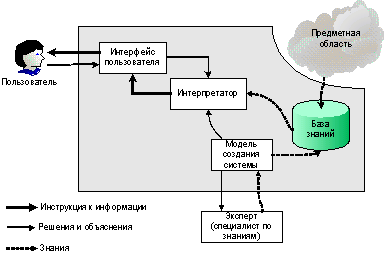
База знаний содержит факты, описывающие проблемную область, а также логическую взаимосвязь этих фактов. Центральное место в базе знаний принадлежит правилам. Правило определяет, что следует делать в данной конкретной ситуации, и состоит из двух частей: условие, которое может выполняться или нет, и действие, которое следует произвести, если выполняется условие.
Все используемые в экспертной системе правила образуют систему правил, которая даже для сравнительно простой системы может содержать несколько тысяч правил.
Оболочка экспертных систем представляет собой готовую программную среду, которая может быть приспособлена к решению определенной проблемы путем создания соответствующей базы знаний. В большинстве случаев использование оболочек позволяет создавать экспертные системы быстрее и легче в сравнении с программированием.
Процесс извлечения знаний из данных называется анализом данных (Data Mining).
Сферы использования Data Mining:
Розничная торговля
анализ покупательской корзины (анализ сходства) предназначен для выявления товаров, которые покупатели стремятся приобретать вместе;
исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа "Если сегодня покупатель приобрел видеокамеру, то через какое время он вероятнее всего купит новые батарейки и пленку?"
создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи.
Банковское дело
выявление мошенничества с кредитными карточками. Путем анализа прошлых транзакций, которые впоследствии оказались мошенническими, банк выявляет некоторые стереотипы такого мошенничества
прогнозирование изменений клиентуры. Data Mining помогает банкам строить прогнозные модели ценности своих клиентов, и соответствующим образом обслуживать каждую категорию.
Страхование
выявление мошенничества
анализ риска. Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам. Известен случай, когда в США крупная страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания отреагировала на это новое знание пересмотром своей общей политики предоставления скидок семейным клиентам.
Без мощного аналитического инструментария извлечение полезных знаний, скрытых в огромных количествах сырых, необработанных данных, представляет собой сложную, практически невыполнимую задачу. Экспоненциальный рост данных, в отличие от природы данных и целей анализа, сложности анализа перемемешанных структурных данных и текста, представляет собой фактор, делающий из сбора и анализа данных настоящую проблему.
Data Mining предоставяет инструментарий для автоматического изучения как исторических данных так и совершенствующихся моделей для прогнозирования последствий будущих ситуаций. Самые лучшие инструментальные программные средства Data Mining предоставляют многообразие алгоритмов машинного обучения для моделирования, таких как Нейронная сеть, Дерево решений, Байесовские сети и другие.
Технологии информационного хранилища обеспечивают сбор данных из существующих внутренних баз предприятия и внешних источников, формирование, хранение и эксплуатацию информации как единой, хранение аналитических данных (знаний) в форме, удобной для анализа и принятия управленческих решений. К внутренним базам данных предприятия относятся локальные базы подсистем ЭИС (бухгалтерский учет, финансовый анализ, кадры, расчеты с поставщиками и покупателями и т.д.). К внешним базам – любые данные, доступные по интернету и размещенные на web cepвеpax предприятий-конкурентов, правительственных и законодательных органов, других учреждений.
Всем хранилищам данных свойственны следующие общие черты:
Предметная ориентированность. Данные объединяются в категории и хранятся в соответствии с областями, которые они описывают, а не с приложениями, которые они используют.
Интегрированность. Данные объединены так, чтобы они удовлетворяли всем требованиям предприятия в целом, а не единственной функции бизнеса.
Привязка ко времени. Данные в хранилище всегда напрямую связаны с определенным периодом времени. Это позволяет анализировать тенденции в развитии бизнеса.
Неизменяемость. Попав в определенный "исторический слой" хранилища, данные уже никогда не будут изменены.
Хранилища данных могут быть разбиты на два типа: корпоративные хранилища данных (enterprise data warehouses) и киоски данных (data marts).
Корпоративные хранилища данных содержат информацию, относящуюся ко всей корпорации и собранную из множества оперативных источников для консолидированного анализа. Обычно такие хранилища охватывают целый ряд аспектов деятельности корпорации и используются для принятия как тактических, так и стратегических решений. Киоски данных содержат подмножество корпоративных данных и строятся для отделов или подразделений внутри организации. Киоски данных часто строятся силами самого отдела и охватывают конкретный аспект, интересующий сотрудников данного отдела.
Отличие реляционных баз данных, используемых в ЭИС, от информационного хранилища заключается в следующем:
• Реляционные базы данных содержат только оперативные данные организации. Информационное хранилище обеспечивает доступ как к внутренним данным организации, так и к внешним источникам данных, доступным по интернету.
• База данных ориентирована на одну модель данных функциональной подсистемы ЭИС. Базы обеспечивают запросы оперативных данных организации. Информационные хранилища поддерживают большое число моделей данных, включая многомерные, что обеспечивает ретроспективные запросы (запросы за прошлые годы и десятилетия), запросы как к оперативным данным организации, так и к данным внешних источников.
• Данные информационных хранилищ могут размещаться не только на сервере, но и на вторичных устройствах хранения.
Совокупная стоимость владения, решения по оптимизации.
Под совокупной стоимостью владении понимается сумма прямых и косвенных затрат, которые несет владелец системы за период жизненного цикла последней.
Прямые затраты.
1.1. Основные затраты: создание информационной системы; оборудование — серверы, клиентские места, периферия, сетевые компоненты; ПО, приложения, утилиты, управляющее ПО; обновление (модернизация).
1.2. Эксплуатационные затраты: управление задачами; поддержка работоспособности системы — персонал, функционирование справочной службы, обучение, закупки, подготовка контрактов на поддержку системы; разработка инфраструктуры, бизнес приложений.
1.3. Прочие затраты: создание коммуникаций — глобальные сети, взаимодействие с поставщиками сервиса, удаленный доступ, Internet, доступ клиента; управление и поддержка — аутсорсинг, сопровождение, справочная система.
Косвенные затраты
Затраты, связанные с оплатой действий, напрямую не являющихся рабочими функциями Контроль, отправка и получение почты, телефонные разговоры, ввод информации, переводы, расходы n.i помещение, потери от плановых и внеплановых простоев, коммунальные услуги и поддержку административного и конторского персонала
Говоря про TCO применительно к СУБД, можно выделить следующие составные части:
Стоимость самой СУБД, состоящая из первоначального платежа за приобретение лицензий и ежегодных платежей за поддержку от производителя.
Стоимость сопровождения СУБД, которая определяется заработной платой сотрудников, ответственных за обслуживание и администрирование баз данных.
Стоимость платформы для разворачивания СУБД — серверного оборудования и операционной системы. Эта стоимость также складывается из первоначального платежа за приобретение оборудования и лицензий на ОС, а также ежегодных платежей за поддержку от производителей.
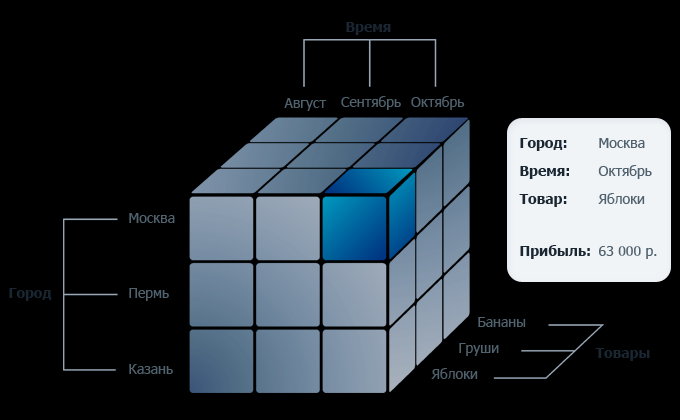
OLAP (on-line analytical processing) — набор технологий для оперативной обработки информации, включающих динамическое построение отчётов в различных разрезах, анализ данных, мониторинг и прогнозирование ключевых показателей бизнеса. В основе OLAP-технологий лежит представление информации в виде OLAP-кубов.
Известные производители коммерческих OLAP-продуктов, согласно OLAP Report на 2007 год: Microsoft, Hyperion, Cognos, Business Objects, MicroStrategy, SAP, Cartesis, Systems Union/MIS AG, Oracle, Applix.
Чем отличается олап куб от таблицы город, время, товары, прибыль.
Понятие гипертекста и гипертекстовые технологии. Дескрипторная классификация документов (списки ключевых слов, понятий, поисковые запросы как основа классификации, электронное рубрицирование, «истинная» электронная классификация). Фактографические БД.
Гипертекстовая технология – это технология представления неструктурированной свободно наращиваемой информации. Этим она отличается от других технологий, где создаются модели структурирования данных, например, в базах данных. Вместо поиска информации по ключу (например, по запросу в базах данных) гипертекстовая технология предлагает перемещение по ключу от одних объектов информации к другим с учетом их смысловой, семантической близости.
Гипертекстовая технология ориентирована на обработку информации не вместо человека, а вместе с человеком, т. е. становится авторской. Удобство ее использования состоит в том, что пользователь сам определяет подход к изучению или созданию материала с учетом своих индивидуальных способностей, знаний, уровня квалификации и подготовки. Гипертекст содержит не только информацию, но и аппарат ее эффективного поиска для перемещения.
Структурно гипертекст состоит из информационного материала, тезауруса гипертекста, списка главных тем и алфавитного словаря.
Информационный материал подразделяется на информационные статьи, состоящие из заголовка статьи и текста. Информационная статья может представлять собой файл, закладку в тексте, web-страницу. Заголовок (имя файла) – это название темы или наименование описываемого в информационной статье понятия.
Тезаурус гипертекста - это автоматизированный словарь, отображающий семантические отношения между информационными статьями и предназначенный для поиска слов по их смысловому содержанию. Тезаурус гипертекста состоит из тезаурусных статей. Тезаурусная статья имеет заголовок и список заголовков родственных тезаурусных статей, где указаны тип родства и заголовки информационных статей. Заголовок тезаурусной статьи совпадает с заголовком информационной статьи.
Формирование тезаурусных статей в соответствии с моделью гипертекста означает индексирование текста. Полнота связей, отражаемых в модели, и точность установления этих связей в тезаурусных статьях, в конечном итоге, определяют полноту и точность поиска информационной статьи гипертекста.
Список главных тем содержит заголовки информационных статей с организационными отношениями. Обычно он представляет собой меню, содержание книги, отчета или информационного материала.
Алфавитный словарь содержит перечень наименований всех информационных статей в алфавитном порядке. Он реализует организационные отношения.
Гипертексты, составленные вручную, используются давно. К ним относятся справочники, энциклопедии, а также словари, снабженные развитой системой ссылок.
Дескрипторная система классификации - система структурирования объектов информации для облегчения их дальнейшего использования с применением специальных меток-описателей - дескрипторов.
Короче говоря - раскладывание по папочкам на которых написано: "кот", "пес", "дом". Надо тебе найти что-то про котов черных по имени Вася. Открываешь папку "кот", находишь папку "цвет" и "имя", открываешь, находишь в них папку "черный" или "вася" соответственно и так далее.
Особенно широко дескрипторы используются в библиотечной системе поиска. Суть дескрипторного метода классификации заключается в следующем:
отбирается совокупность ключевых слов или словосочетаний, описывающих определенную предметную область или совокупность однородных объектов. Причем среди ключевых слов могут находиться синонимы;
выбранные ключевые слова и словосочетания подвергаются нормализации, т.е. из совокупности синонимов выбирается один или несколько наиболее употребимых;
создается словарь дескрипторов (пример), т.е. словарь ключевых слов и словосочетаний, отобранных в результате процедуры нормализации.
Между дескрипторами устанавливаются связи, которые позволяют расширить область поиска информации. Связи могут быть трех видов: синонимические, указывающие некоторую совокупность ключевых слов как синонимы; родо-видовые, отражающие включение некоторого класса объектов в более представительный класс; ассоциативные, соединяющие дескрипторы, обладающие общими свойствами.
Пример.
Синонимическая связь: студент - учащийся - обучаемый.
Родо-видовая связь: университет - факультет - кафедра.
Ассоциативная связь: студент - экзамен - профессор - аудитория
Современная компьютерная техника снимает ограничения по объёму каталогов и снижает трудоёмкость их составления. Поэтому получила распространение идея приписывать документам все ключевые слова, используемые в документе, и в электронном каталоге иметь инверсный файл записи адресов документов, использовавших каждое ключевое слово.
Под ключевыми словами в данном случае понимаются наиболее существенные для выражения содержания документа полнозначные слова и словосочетания, обладающие назывной (номинативной) функцией
Задачей систем автоматического (электронного) рубрицирования является разбиение поступающего потока текстов на тематические подпотоки в соответствии с заранее заданными рубриками.
Под рубрикатором понимается классификационная таблица иерархической классификации, содержащая полный перечень включенных в систему классов и предназначенная для систематизации информационных фондов, массивов и изданий, а также для поиска в них (ГОСТ 7.74-96).
Критерии оценки качества рубрицирования
Для оценки эффективности работы систем рубрицирования используются такие характеристики, как точность и полнота.
Точность (precision)
- это отношение ![]() ,
где
,
где ![]() -
количество текстов, правильно отнесенных
системой к некоторой рубрике, а
-
количество текстов, правильно отнесенных
системой к некоторой рубрике, а ![]() -
общее количество текстов, отнесенных
системой к этой рубрике.
-
общее количество текстов, отнесенных
системой к этой рубрике.
Полнота (recall)
- это отношение ![]() ,
где
-
количество текстов, правильно отнесенных
системой к некоторой рубрике, а
,
где
-
количество текстов, правильно отнесенных
системой к некоторой рубрике, а ![]() -
общее количество текстов, которые должны
быть отнесены к этой рубрике.
-
общее количество текстов, которые должны
быть отнесены к этой рубрике.
Фактографические БД.
По характеру хранимой информации базы данных делятся на фактографические и документальные.
В фактографических БД содержатся краткие сведения об описываемых объектах, представленные в строго определенном формате. Например, в БД библиотеки о каждой книге хранятся библиографические сведения: год издания, автор, название и пр.; в записной книжке школьника могут храниться фамилии, имена, даты рождения, телефоны, адреса друзей и знакомых.
В документальных БД содержатся документы (информация) самого разного типа: текстового, графического, звукового, мультимедийного (например, различные справочники, словари).
Примеры баз данных:
Фактографические
БД книжного фонда библиотеки;
БД кадрового состава учреждения;
Документальные
БД законодательных актов в области уголовного права;
БД современной рок музыки и пр.
Релевантность, пертинентность. Способы повышения результативности информационного поиска в полнотекстовых базах данных и глобальной сети (контекстный поиск по ключевым словам, нечеткий поиск, семантический поиск). Фактографические БД. Примеры реализации, эффективность использования.
Основной задачей документальных информационных систем является накопление и предоставление пользователю документов, содержание, тематика, реквизиты и т.п. которых адекватны его информационным потребностям.
Поисковый характер документальных информационных систем исторически определил еще одно их название — информационно-поисковые системы (ИПС).
Релевантность - степень соответствия содержания документа, найденного в результате информационного поиска, содержанию информационного запроса.
Пертинентность - степень соответствия содержания документа, найденного в результате информационного поиска, информационной потребности пользователя, сформулированной в виде информационного запроса.
Сложное психологическое явление информационной потребности не всегда удается точно, однозначно и исчерпывающе сформулировать в виде информационного запроса.
Цель индексирования документов – возможность их быстрого поиска. Индекс – это набор слов документа или о документе, по которым этот поиск производится.
Индексирование документа обычно организуется через автоматическую обработку его текста и заполнение метаданных. Автоматическая обработка – полнотекстовое индексирование – заключается в преобразовании текста документа в набор слов. Причем обычно для слов сохраняется их позиция в документе, для обеспечения возможности поиска по словосочетаниям.
Существуют два принципиально различных метода такого индексирования с учетом применяемых в дальнейшем методов поиска:
При бинарном индексировании (контекстно-независимом по классификации [1]) поиск ведется на основе алгоритмов “нечеткого поиска”, т.е. поиска с ошибками. В этом случае допускается неполное (с заданным количеством ошибок в начале, середине и конце слова) совпадение слов с шаблоном. При втором методе индексации (контекстно-зависимом по классификации) слова преобразуются в словоформы с отсечением суффиксов и окончаний, что позволяет искать склонения и спряжения шаблонов.
Фактографические БД.
По характеру хранимой информации базы данных делятся на фактографические и документальные.
В фактографических БД содержатся краткие сведения об описываемых объектах, представленные в строго определенном формате. Например, в БД библиотеки о каждой книге хранятся библиографические сведения: год издания, автор, название и пр.; в записной книжке школьника могут храниться фамилии, имена, даты рождения, телефоны, адреса друзей и знакомых.
В документальных БД содержатся документы (информация) самого разного типа: текстового, графического, звукового, мультимедийного (например, различные справочники, словари).
Примеры баз данных:
Фактографические
БД книжного фонда библиотеки;
БД кадрового состава учреждения;
Документальные
БД законодательных актов в области уголовного права;
БД современной рок музыки и пр.