

Лекція 12.
4.3. Текстологічні методи
Група методів текстологій об’єднує методи видобування знань, засновані на вивченні спеціальних текстів з підручників, монографій, статі, методик і інших носіїв професійних знань.
В буквальному розумінні методи текстологій не відносяться до текстології – науки, яка народилася в руслі філології з метою критичного прочитання літературних текстів, вивчення і інтерпретації джерел з вузькоприкладеною задачею – підготовки текстів до видання. Зараз текстологія розширила свої межі включенням аспектів суміжних наук – герменевтики (науки правильного тлумачення стародавніх текстів – біблії, античних рукописів і ін.), семіотики, психолінгвістіки і ін.
Методи текстологій видобування знань, безумовно, використовуючи основні положення текстології, відрізняються принципово від її методології, по-перше, характером і природою своїх джерел (професійна спеціальна література, а не художня, що живе за своїми особливими законами), а по-друге, жорсткою прагматичною спрямованістю видобування конкретних професійних знань.
Серед методів видобування знань ця група є якнайменше розробленою, по ній практично немає ніякої бібліографії, тому подальший виклад є як би введенням в методи вивчення текстів в тому вигляді, як це представляють автори.
Задачу видобування знань з текстів можна сформулювати як задачу розуміння і виділення значення тексту. Сам текст на природній мові є лише провідником значення, а задум і знання автора лежать у вторинній структурі (смисловій структурі або макроструктурі тексту), що настроюється над природним текстом [Велічковській, Капіца, 1987], або, як сформульовано в роботі [Файн, 1987], «текст не містить і не передає значення, а є лише інструментом для автора тексту».
При цьому можна виділити дві такі смислові структури:
М1 – значення, яке намагався закласти автор, це його модель світу, і М2 – значення, яке осягає читач, в даному випадку інженер по знаннях (Рис.4.6), в процесі інтерпретації I. При цьому Т – це словесне одіяння М1, тобто результат вербалізациі V.
Складність процесу полягає в принциповій неможливості збігу знань, створюючих М1, і М2, через те, що М1 утворюється за рахунок всієї сукупності уявлень, потреб, інтересів і досвіду автора, лише мала частина яких знаходить віддзеркалення в тексті Т. Відповідно, і М2 утворюється в процесі інтерпретації тексту Т за рахунок залучення всієї сукупності наукового і людського багажу читача. Таким чином, два інженери по знаннях витягнуть з одного Т дві різні моделі Мі1 і М і 2 .


Т екст
книги
екст
книги
 V I
V I


Експерт Інженер по
знаннях
Рис.4.6. Схема видобування знань із спеціальних текстів
Постає задача: з’ясувати, за рахунок чого можна досягти максимальної адекватності М1 і М2, пам’ятаючи при цьому, що розуміння завжди відносне, оскільки це синтез двох значень «своє-чуже» [Бахтін, 1975].
Розглянемо докладніше, які джерела живлять модель М1 і створюють текст Т. В роботі [Сергєєв, 1987] вказані два компоненти будь-якого наукового тексту. Це первинний матеріал спостережень α і система наукових понять β у момент створення тексту. На додаток до цього, на наш погляд, крім об’єктивних даних експериментів і спостережень, в тексті обов’язково присутні суб’єктивні погляди автора γ, результат його особистого досвіду, а також деякі «загальні місця» або «вода» δ. Окрім цього, будь-який науковий текст містить запозичення з інших джерел (статі, монографій) і т.д. При цьому всі компоненти занурені в мовне середовище L. Можна записати:
Т = (α, β, γ, δ, θ)L.
Таким чином, компоненти наукового тексту можна представити у вигляді наступної схеми (Рис.4.7). При цьому компоненти β, γ, частина α входять і в модель М1.

Текст
Текст θ
δ
γ
β
α
Рис.4.7. Компоненти наукового тексту
При здобуванні знань аналітику, що інтерпретує текст, доводиться вирішувати задачу декомпозиції цього тексту на перераховані вище компоненти для виділення істинно значущих для реалізації бази знань фрагментів. Складність інтерпретації наукових і спеціальних текстів полягає ще і у тому, що будь-який текст набуває значення тільки в контексті, де під контекстом розуміється оточення, в яке «занурений» текст.
Розрізняють мікро- і макроконтекст. Мікроконтекст – це найближче оточення тексту. Так, пропозиція одержує значення в контексті абзацу, абзац в контексті глави і т.д. Макроконтекст – це вся система знань, пов’язана з предметною областю (тобто знання про особливості і властивості, явно не вказані в тексті). Іншими словами, будь-яке знання знаходить значення в контексті деякого метазнання.
Тепер трохи докладніше про центральну ланку процедури видобування знаннь – про розуміння тексту. Класичним в текстології є визначення німецького філософа і мовознавця В. фон Гумбольдта [Фон Гумбольдт, 1984]:
«...Люди розуміють один одного не тому, що передають співбесіднику знаки предметів, і навіть не тому, що взаємно настроюють один одного на точне і повне відтворення ідентичного поняття, а тому, що взаємно зачіпають один в одному одну і ту ж ланку ланцюга плотських уявлень і зачатків внутрішніх понять, торкаються до одних і тих же клавіш інструменту свого духу, завдяки чому у кожного спалахують в свідомості відповідні, але не тотожні значення.»
Кажучи на мові сучасного мовознавства, розуміння – це формування «другого тексту», тобто семантичної структури (понятійної структури) [Сиротко-сибирский, 1968]. У нашій термінології – це спроба відтворення семантичної структури М1 в процесі формування моделі М2, тобто це перший крок структуризації знань.
Як відбувається процес розуміння I? Одна з можливих схем висловлена в роботі [Соколів, 1947; Соколів, 1968]. Ми внесли декілька змін в цю схему у зв’язку з тим, що в ній трактується розуміння тексту на іноземній мові, а нас цікавить розуміння тексту в новій для суб’єкта, що пізнає, предметній області. Окрім цього, доповнимо її деякими положеннями герменевтики. В цілому одержана схема узгоджується із стратегією вивчення всього нового.
Основними моментами розуміння тексту є:
Висунення попередньої гіпотези про значення всього тексту (передбачення).
Визначення значень незрозумілих слів (тобто спеціальної термінології).
Виникнення загальної гіпотези про зміст тексту (про знання).
Уточнення значення термінів і інтерпретація окремих фрагментів тексту під впливом загальної гіпотези (від цілого до частин).
Формування деякої смислової структури тексту за рахунок встановлення внутрішніх зв’язків між окремими важливими (ключовими) словами і фрагментами, а також за рахунок утворення абстрактних понять, узагальнюючих конкретні фрагменти знань.
Коректування загальної гіпотези щодо тих, що містяться в тексті фрагментів знань (від частин до цілого).
Ухвалення основної гіпотези, тобто формування М2.
Слід зазначити наявність як дедуктивної (від цілого до частин), так і індуктивної (від частин до цілого) складової процесу розуміння. Такий двоєдиний підхід дозволяє охоплювати текст як смислову єдність особливого роду, з його основними ознаками, такими як зв’язність, цілісність, закінченість і ін. [Сиротко-сибирский, 1968].
Центральними моментами процесу I є кроки 5 і 7, тобто формування смислової структури або виділення «опорних», ключових, слів або «смислових віх» [Сиротко-сибирский, 1968], а також завершальне зв’язування «смислових віх» в єдину семантичну структуру.
При аналізі тексту важливе виявлення внутрішніх зв’язків між окремими елементами тексту і поняттями. Традиційно виділяють два види зв’язків в тексті – експліцитні (або явні зв’язки), які виражаються в зовнішньому дробленні тексту, і імпліцитні (приховані зв’язки). Експліцитні зв’язки ділять текст на параграфи за допомогою переліку компонентів, ввідних слів (або коннекторів) типу «по-перше..., по-друге..., проте і т. д.». Імпліцитні, або внутрішні, зв’язки між окремими «смисловими віхами» викликають основне затруднення при розумінні.
Отже, семантична структура тексту утворюється в свідомості суб’єкта, що пізнає, за допомогою знань про мову, знань про світ, а також загальних (фонових) знань в тій предметній області, якій присвячений текст. «Тексти пишуть для присвячених». Іншими словами, якщо текст не є науково-популярним, то для його адекватного прочитання потрібна деяка підготовка.
Таким чином, шлях до знань подовжується ще на одну ланку. Якщо ми раніше говорили, що самі методи текстологій рідко уживаються як самостійний метод видобування, а звичайно використовуються як деяка підготовка до комунікативної взаємодії, то тепер затверджуємо, що і для прочитання текстів потрібна підготовка. Яка ж?
Підготовкою до прочитання спеціальних текстів є вибір спільно з експертами деякого «базового» списку літератури, який поступово введе аналітика в наочну область. У цьому списку можуть бути підручники для початківців, глави і фрагменти з монографій, популярні видання. Тільки після ознайомлення з «базовим» списком доцільно приступати до читання спеціальних текстів.
Таким чином, на процес розуміння (або інтерпретації) I і модель М2 впливають наступні компоненти (Рис.4.8):
екстракт компонентів (α, β, γ, θ)’, почерпнутий з тексту Т;
попередні знання аналітика про предметну область ω;
загальнонаукова ерудиція аналітика ε;
його особистий досвід φ.
М2 = [(α, β, γ, θ)’,ω, ε, φ].
Процес I – це складний, непіддатливий формалізації процес, на який істотним чином впливають такі чисто індивідуальні компоненти, як когнітивний стиль пізнання, інтелектуальні характеристики і ін.

Рис. 4.8. Компоненти формування змісту тексту
Але процедура розбивки тексту на частини («змістові групи»), а потім згущення, стискання кожного змістовного шматка в «змістовну віху» є напевно, основою для будь-якого індивідуального процесу розуміння. Така компресія (стискання) тексту у вигляді набору ключових слів, що передають основний зміст тексту, може служити зручною методологічною основою для проведення текстологічних процедур витягу знань.
Як ключове слово може служити будь-яка частина мови (іменник, прикметник, дієслово й т.д.) або їхнє сполучення. Набір ключових слів (НКС) - це набір опорних крапок, по яких розгортається текст при кодуванні на згадку й усвідомлюється при декодуванні, це семантичне ядро цілісності [Сиротко-Сибиірский, 1968].
Приклад 4.7
Як приклад приведемо результати експерименту по формуванню НКС. Знання витягалися з наступного тексту [Уэпо, Исидзука, 1989].
«Теорія фреймів відноситься до психологічних понять, що стосується розуміння того, що ми бачимо й чуємо. Ці способи сприйняття трактуються з послідовної точки зору, на їхній підставі здійснюється концептуальне моделювання, доцільність отриманих моделей досліджується разом з різними проблемами, що виникають у цих двох областях.
Для усвідомлення того факту, що задана інформація в цих областях має єдиний сенс, людська пам'ять насамперед повинна бути здатна погоджувати цю інформацію зі спеціальними концептуальними об'єктами. У противному випадку не вдається систематизувати інформацію, що виглядає розрізненою. В основі теорії фреймів лежить сприйняття фактів за допомогою зіставлення отриманої ззовні інформації з конкретними елементами й значеннями, а також з рамками, що приділенні для кожного концептуального об'єкта в нашій пам'яті. Структура, що представляє ці рамки, називається фреймом. Оскільки між різними концептуальними об'єктами є деякі аналогії, то утвориться ієрархічна структура із класифікаційними й узагальнюючими властивостями. Власне, вона являє собою ієрархічну структуру відносин типу «абстрактне-конкретне». Складні об'єкти представлені комбінацією декількох фреймів, інакше кажучи, вони відповідають фреймовій мережі. Крім того, кожний фрейм доповнюється пов'язаними з ним фактами й процедурою, що забезпечує виконання запитів до інших фреймів.
Причиною, по якій подання знань фреймами виглядає досить точним є можливість більше повного опису процесу мислення людини за допомогою визначення великої й структурованої основної одиниці подання знань і більше тісного зв'язку знань заснованих на фактах, і процедурних знань. Проте, як було відзначено її автором, теорію фреймів варто скоріше віднести до теорії постановки завдань, чим до результативної теорії. Можна вважати, що вона істотно підвищує рівень і деталізує механізм пам'яті людини, висновків, розуміння й навчання.»
У групі з 34 випробуваних не було отримано жодного співпадаючого НКС і, відповідно, всі структури істотно відрізнялися. Для приклада приведемо дві роботи (Рис. 4.9, а, б).
Цікаво, що одна з гіпотез лінгвостатистики про те, що найбільш уживані слова є найбільш важливими з погляду змісту тексту, тобто відображають його тематичну структуру, частково підтвердилася.

Рис. 4.9. Приклади значеннєвих структур, витягнутих з тексту
Варто сказати кілька слів про те, чому ми виділяємо три види текстологічних методів (див. Рис. 4.1):
• аналіз спеціальної літератури;
• аналіз підручників;
• аналіз методик.
Перераховані три методи істотно відрізняються, по-перше, по степені концентрованості спеціальних знань і, по-друге, по співвідношенню спеціальних і фонових знань. Найбільш простим методом є аналіз підручників, у яких логіка викладу звичайно відповідає логіці предмета й тому макроструктура такого тексту буде, напевно, більш значима ніж структура тексту якої-небудь спеціальної статті. Аналіз методик утруднений саме стислістю викладу й практичною відсутністю коментарів, тобто фонових знань, що полегшують розуміння для неспеціалістів. Тому можна рекомендувати для практичної роботи комбінацію перерахованих методів.
На закінчення запропонуємо одну з можливих практичних методик аналізу текстів з метою витягу й структурування знань.

4.4. Найпростіші методи структурування
Методи витягу знань, розглянуті вище є безпосередньою підготовкою до структурування знань. Даний параграф присвячений вивченню практичних методів структурування знань.
4.4.1. Алгоритм для «чайників»
У якості найпростішого прагматичного підходу до формування поля знань починаючому інженерові по знаннях можна запропонувати наступний алгоритм для «чайників» (Рис. 4.10).
1. Визначення вхідних {X} і вихідних {Y} даних. Цей крок необхідний, тому що він визначає напрямок руху в поле знань - від X до Y.
Крім того, структура вхідних і вихідних даних істотно впливає на форму й зміст поля знань. На цьому кроці визначення може бути досить розмитим, надалі воно буде уточнюватися.
2. Складання словника термінів і наборів ключових слів N. На цьому кроці проводиться текстуальний аналіз всіх протоколів сеансів витягу знань і виписуються всі значимі слова, що позначають поняття, явища, процеси, предмети, дії, ознаки й т.п. При цьому варто спробувати розібратися в значенні термінів. Важливий осмислений словник.
3. Виявлення об'єктів і понять {А}. Виробляється «просівання» словника N і вибір значимих для ухвалення рішення понять і їхніх ознак. В ідеалі на цьому кроці утвориться повний систематичний набір термінів у який-небудь області знань.
4. Виявлення зв'язків між поняттями. Усе у світі зв'язано. Але визначити, як спрямовані зв'язки, що ближче, а що далі необхідно на цьому етапі. Так будується мережа асоціацій, де зв'язки тільки намічені, але поки не поіменовані. Наприклад, поняття «день», «ніч», «ранок» і «вечір» явно якось зв'язані, зв'язані також і поняття «червоний прапор» і «червона краватка», але характер зв'язку отут істотно відмінний.
5. Виявлення метапонять і деталізації понять. Зв'язки, отримані на попередньому кроці, дозволяють інженерові по знаннях структурувати поняття й виявляти поняття більш високого рівня узагальнення (метапоняття), так і деталізувати на більш низькому рівні.
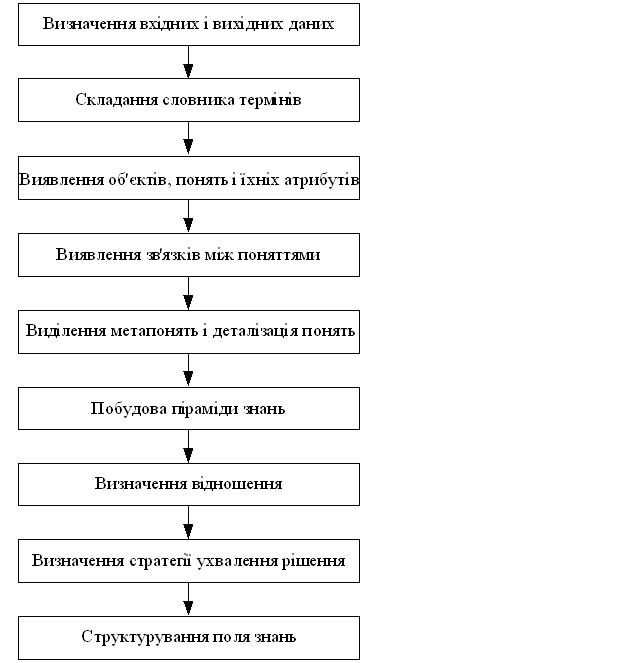
Рис. 4.10. Стадії структурування знань - алгоритм для «чайників»
6. Побудова піраміди знань. Під пірамідою знань ми розуміємо ієрархічні сходи понять, підйом по який означає поглиблення понять й підвищення рівня абстракції (узагальненості) понять. Кількість рівнів у піраміді залежить від особливостей предметної області, професіоналізму експертів і інженерів по знаннях.
7. Визначення відносин {RA}. Відносини між поняттями виявляються як усередині кожного з рівнів піраміди, так і між рівнями. Фактично на цьому кроці даються імена тим зв'язкам, які виявляються на кроках 4 і 5, а також позначаються причинно-наслідкові, лінгвістичні, часові й інші види відносин.
8. Визначення стратегій прийняття рішень (Si). Визначення стратегій прийняття рішення, тобто виявлення ланцюжків міркувань, зв'язує всі сформовані раніше поняття й відносини в динамічну систему поля знань. Саме стратегії надають активність знанням, саме вони «перетрушують» модель М у пошуку від X до У.
Однак на практиці при використанні даного алгоритму можна стикнутися з непередбаченими труднощами, пов'язаними з помилками на стадії витягу знань і з особливостями знань різних предметних областей. Тоді можливе залучення інших, більш «прицільних» методів структурування. При цьому на різних етапах схеми (Рис. 4.10) можливе використання різних методик.
4.4.2. Спеціальні методи структурування
Використовуючи представлений на Рис. 4.10 алгоритм, інженер по знаннях може випробовувати необхідність у застосуванні спеціальних методів структурування на різних кроках алгоритму. При цьому, природно, для таких простих і очевидних кроків, як визначення вхідних і вихідних понять або складання словника, ніяких штучних методів пропонуватися не буде.