

Сведения о внутренней организации 32-х разрядных процессорах, (состав, назначение).
МП 8086 состоит из двух полунезависимых блоков: операционного устройства и шинного интерфейса. Такая структура позволяет организовать двухступенчатый конвейер (пока одна команда выполняется, другие команды выбираются из ОП).
В более старших процессорах глубина конвейера была значительно увеличена. Например, МП 486 состоит из девяти полунезависимых блоков:
Шинный интерфейс. Этот блок обеспечивает обмен между процессором и ОП, процессором и портами ВУ. Шинный интерфейс инициирует все циклы шины. Стандартный цикл шины в МП 486 занимает 2 машинных такта.
Внутренняя кэш-память. Доступ к данным при кэш-попадании занимает 1 машинный такт.
Блок предвыборки команд. Основной частью этого блока является 32 байтная очередь команд. В процессе выполнения любой команды имеется промежуток времени, когда системная шина оказывается свободна. Шинный интерфейс использует эти промежутки для опережающей выборки команд из памяти. Выбранные с опережением из ОП команды внутри МП хранятся в очереди команд.
Блок дешифрации. Преобразует команды в микрокоманды.
Блок управления. Формирует все внутренние управляющие сигналы.
Устройство с плавающей точкой. Выполняет команды арифметического сопроцессора.
Целочисленное устройство. Выполняет команды процессора.
Блок сегментации. Обеспечивает работу сегментного механизма.
Блок страничного преобразования. Включает в себя буфер TLB и обеспечивает работу страничного механизма.
Все эти блоки могут работать параллельно, что обеспечивает достаточно большую глубину конвейера: одна команда выполняется, другая выбирается из ОП, третья дешифрируется, для четвертой формируется адрес и. т. д. Только за счет внутренней организации МП 486 на одинаковой частоте работает в 2,5 раза быстрее МП 386. Внутренняя организация МП 486 такова, что при оптимальной организации программы этот процессор способен обеспечить выполнение одной команды за один машинный такт. Конечно в общем случае выполнение конкретной команды может занимать несколько тактов, но это компенсируется наличием конвейера. То есть за один машинный такт конвейер выдает результат одной машинной команды.
Все процессоры, до МП 486 включительно, имели скалярную архитектуру, проще говоря, имели один конвейер. Начиная с Pentium, в процессорах реализована суперскалярная архитектура, то есть внутри процессора теперь имеется сразу несколько конвейеров, способных работать параллельно.
В Pentium имеется два конвейера и при их оптимальной загрузке процессор способен выдавать за один такт результаты двух машинных команд. Один из этих конвейеров называется U-конвейером, а другой- V-конвейером. Между этими конвейерами имеется различие, хотя и не очень существенное. Разница заключается в том, что на U-конвейере можно запустить любую команду, а V-конвейер имеет в этом смысле определенные ограничения. Кроме того не любая пара даже допустимых команд может быть одновременно запущена на этих конвейерах. Сведения об этих ограничениях приводятся в справочной литературе. Программист, желающий получить максимальную производительность процессора, должен компоновать команды программы таким образом, чтобы обеспечить максимальную загрузку конвейеров (или использовать специальные компиляторы, если программа пишется на языке высокого уровня).
Очевидно, что подобная структура будет работать максимально эффективно при максимальной загрузке конвейеров. Узким местом, в этом смысле, являются команды переходов. До МП 486 включительно, процессор, встречая команду перехода, очищал очередь команд и начинал заполнять ее заново, что естественно приводило к снижению производительности. Для обхода этого узкого места в Pentium было введено «предсказание перехода» (branch prediction). То есть, встретив команду перехода процессор предсказывает произойдет переход или нет и в соответствии с этим предсказанием продолжает выборку команд из памяти. Если предсказание оказалось неверным, вводятся штрафные циклы (penalty), во время которых вся неправильно выбранная информация сбрасывается и выборка команд начинается сначала (по правильной ветви перехода). Для реализации стратегии предсказания переходов в состав процессора введен буфер целевых адресов переходов BTB (branch target buffer). В этом буфере можно хранить до 256 адресов переходов и статистику о переходах на эти адреса (сведения о четырех последних переходах на этот адрес – «был – не был»). Наличие статистики позволяет реализовать стратегию динамического предсказания перехода. Естественно, когда процессор встречает переход впервые, никакой статистики об этом переходе у него нет. В этом случае используется статическое предсказание перехода: переход назад предсказывается, а вперед – нет. Связано это с тем, что переход назад чаще всего –цикл.
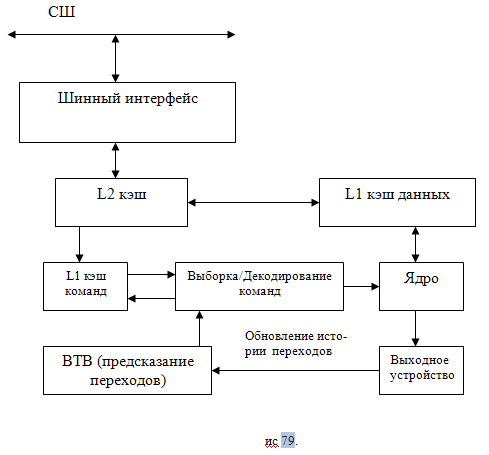
В семействе Р6 (процессоры Pentium Pro, Pentium II, Celerone и Pentium III, в которых используется микроархитектура Р6, см. рис. 79) введены следующие новые архитектурные решения:
процессор за такт способен выдавать результаты трех команд;
ядро процессора выполняет команды не в том порядке, в котором они заданны в программе, а в порядке «выгодном» процессору (out of order), естественно соблюдая все зависимости по данным. Связано это нововведение со следующим соображением. Пусть у нас есть три подряд идущие команды, причем вторая команда зависит от результата первой. Очевидно, что первую и вторую команды нельзя выполнить одновременно, но если третья команда никак не связана по данным ни с первой, ни со второй мы можем одновременно выполнить первую и третью команды, отложив выполнение второй команды. Работа процессора семейства Р6 строиться следующим образом. Команды считываются из кэш памяти команд в порядке, заданном программой и поступают на устройство декодирования (decode unit). Последнее «разворачивает» команды в последовательность микроопераций ( μops ). При этом различается два вида команд: команда декодируется в последовательность до 4-х μops (такая команда может декодироваться за один такт); команда декодируется в последовательность больше 4-х μops (декодируется за несколько тактов). Само устройство декодирования включает в себя три независимых декодера. Один из них за такт способен декодировать команду, содержащую до 4-х μops, а два других – только 1 μops. Таким образом, для достижения максимальной производительности надо компоновать команды с учетом соотношения 4-1-1 μops. Декодированные команды поступают в накопитель ядра (reorder buffer). Устройство диспетчеризации (dispatch unit) постоянно просматривает накопитель, выявляя команды, для которых готовы все данные, и направляя такие команды на одно из имеющихся в ядре исполнительных устройств. Выходное устройство (retirement unit) обеспечивает выдачу результатов уже в порядке, заданном программой.
Как и в Pentium, реализовано предсказание переходов, только в ВТВ может храниться до 512 целевых адресов переходов.
Реализовано «спекулятивное» выполнение команд (speculative execution). То есть предсказанные после перехода команды не только выбираются из кэша и декодируются, но и по возможности выполняются до проверки условия перехода. При неверном предсказании перехода результаты выполнения таких команд аннулируются.
Реализовано «переименование регистров» (registers renaming). Узким местом процессоров фирмы Intel является малое число внутренних регистров. Это приводит к резкому возрастанию зависимости по данным между командами и, соответственно снижает загрузку конвейеров. Для обхода этого узкого места в состав процессора введено значительно больше регистров, чем дается в описании программной модели, и процессор сам присваивает им временные имена.
Процессор Pentium 4 относится к новому семейству прцессоров, реализованному на основе микроархитектуры NetBurst (см. рис. 80). Как видно из рис 79 и 80 отличие между микроархитектурой Р6 и микроархитектурой NetBurst заключается в отсутствии в последней L1 кэша команд, который заменен trace кэшем, стоящем на выходе устройства декодирования. Пооследнее выбирает команды из L2 кэша и разворачивает их в последовательности μops, которые называются trace (трек).
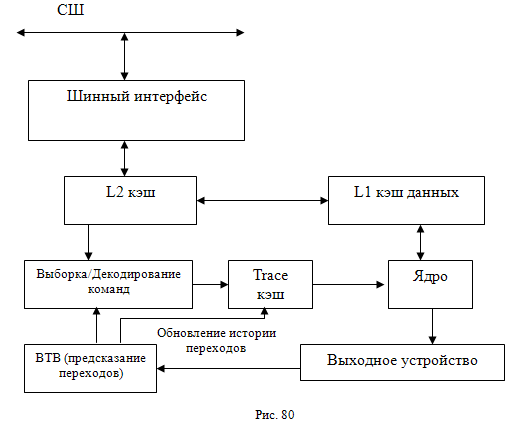
Эти треки и храняться в trace кэше. Такая микроархитектура позволяет снизить некоторые потери в быстродействии, связанные с предсказанием переходов.
Наличие нескольких конвейеров, а тем более неупорядоченного выполнения команд программы может привести к разного рода коллизиям, например, при переключении одного режима в другой. Поэтому, начиная с Pentium появились, так называемые, «сериалайзд» команды (serialized instruction), которые гарантируют, что выполнение всех предыдущих команд программы будет полностью завершено перед выполнением такой команды. «Сериалайзд» команда – это обычная команда, выполняющаяся самым обычным образом, но, плюс к этому, обладающая описанным выше свойством. Таких команд в системе команд порядка десятка и большинство из них в защищенном режиме доступны только на нулевом уровне привилегий. Пользователю всегда доступна только одна такая команда – cpuid.