

II.6. Работа с прочими веб-частями.
Веб-часть разделения страницы на зоны ZoneTabs необходимо разместить в одной области несколько веб-частей. Если открыть «Изменить общую веб-часть», появится панель настроек. Где в полях Tab Names следует написать названия разделов.
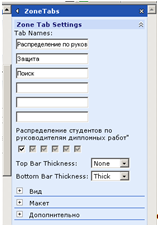
Далее галочками связываются по порядку каждая веб-часть с нужным разделом. Ниже опять же видны настройки вида, макета и дополнительные настройки.
Смысл этой веб-части заключается в том, что на одной странице можно создать несколько скрытых разделов, которые будут выглядеть как будто это разные страницы, хотя это не так. Эта веб-часть помогает избавиться от большого количества страниц на узле, упрощая администрирование каждой.
Веб-часть TitleBarWepPart является стандартной майкрософтовской веб-частью панели инструментов. Именно на ней расположено меню изменения общей страницы. Необходима для всех действий со страницами портала. И без нее ничего не будет работать
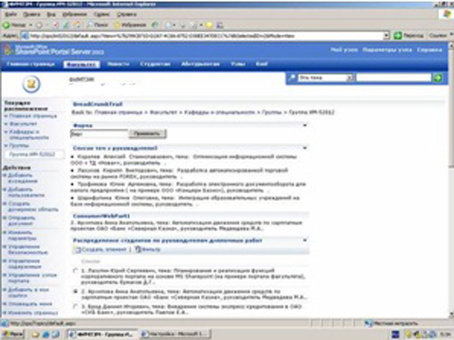
Веб-часть BreadCrambTrial описания пути страницы. Просто добавляешь ее на рабочую зону, и она прописывает путь к странице.
Например: Back to: Главная страница > Филиал>Специальности > Группы > Группа ПИ-4110
С помощью этой веб-части пользователь может вернуться назад на порядок выше.
Веб-часть панели инструментов RightBodySectionSearchBox, предназначена для поиска на узле. Можно задавать категории поиска. Размещается она обычно внизу «шапки» портала.
Веб-часть ConsumerWebPart, связываемая со списками. Например, если нужно, чтобы показывала значения отдельного столбца. Для этого надо открыть меню этой веб-части, выбрать «Соединение» и соединить с нужным столбцом нужной таблицы.
В результате список преобразуется в выбираемый, и при выборе определенного элемента значения нужного столбца отобразятся в этой веб-части.
Вот так выглядит применение этих веб-частей на портале.
Теперь мы подошли к одной из самых интересных веб-частей непосредственно связанной с программированием.
II.6.6..
Работать мы с Веб-частью CsegRollUp ней начнем с добавления ее на рабочую область. Процедура стандартная. Мы открыли веб-часть CsegRollUp, открываем меню изменить общую веб-часть. Появляется панель настроек.
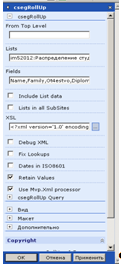
В поле Lists вводим название страницы, на которой расположена веб-часть и через двоеточие название списка. Далее в поле Fields названия столбцов, которые будут включены в веб-часть, через запятую без пробела.
Далее идет написание XSL кода. Не забываем, что этот код служит для XML с HTML разметкой. Поэтому при разработке кода необходимо проработать структуру выводимого текста. Структура у нас останется та же:
Голутвин Павел Викторович, тема: «Повышение функциональных возможностей корпоративного портала филиала с помощью MS SharePoint», руководитель Пригарин А.С.
Суть здесь такова, что CsegRollUp выбирает все элементы каждого столбца и выводит в виде структурированного текста. Разметка та же самая, что и в HTML, поэтому очень удобно работать с выводом. Единственное, что не надо прописывать разметку для каждой строки. Веб-часть сама выбирает все имеющиеся элементы.
Итак, составляем код:
<?xml version='1.0' encoding='utf-8'?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" />
<xsl:template match="/">
<xsl:for-each select="Rows/Row"><ol>
<xsl:value-of select="Family" />
<xsl:value-of select="Name" />
<xsl:value-of select="Ot4estvo" />, тема:
<xsl:value-of select="Diplom" />, руководитель
<xsl:value-of select="Rukovod" />.</ol>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
После чего страница портала стала выглядеть вот так:
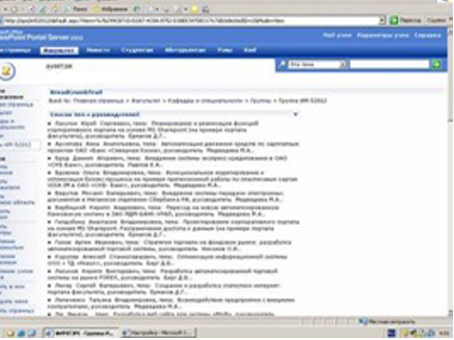
Очень похоже, что список просто разместили через «Редактор содержимого», но это конечно же не так. Самым главным плюсом такого размещения списков является тот факт, что эта информация не запоминается на странице, запоминается только механизм получения информации, поэтому каждое обновление будет сразу отображено.
В CsegRollUp кроме вывода списков можно еще делать запросы на них. Для этого используется язык CAML. С помощью него можно, например, осуществить выборку по руководителям дипломных работ для определенного руководителя. Что я сейчас и продемонстрирую. Все в той же панели настроек веб-части есть раздел CsegRollUp Query. Выбираем его. Там есть поле для ввода текста под названием CAML Query, в это поле необходимо вписать запрос, написанный на языке CAML.
Можно делать запросы по нескольким критериям, а можно составлять запросы по нескольким именам из одного столбца. Но для простоты примера я покажу как делать запрос по одному критерию.
<Where>
<Contains>
<FieldRef Name="Rukovod" />
<Value Type='Text'>Тюрин В.В.</Value>
</Contains>
</Where>
После прогона этого кода, выводится необходимый список. Это далеко не единственное применение CAML-запросов. Очень хорошо они подходят для веб-части Форма.
Форма. Веб-часть Форма можно использовать как формуляр для поиска чего либо. Сейчас я продемонстрирую, как можно использовать форму для поиска. Основное свойство этой веб-части то, что ее можно связывать с остальными. Однако основной недостаток-связывание происходит только по одному имени или запросу. В поле может находиться только одно значение. Однако свяжем ее с уже готовой веб-частью CsegRollUp. Далее открываем панель настройки и через уже знакомый «Редактор исходного текста» правим HTML код. Через него можно настроить форму. Она может быть как полем для ввода текста, списком, набором кнопок, всем, чем угодно, но с ограничением единичной ссылки.
Со стороны CsegRollUp связать его с формой можно с помощью CAML. Для этого открываем настройки и изменяем код запроса.
<Where>
<Contains>
<FieldRef Name="Rukovod" />
<Value Type=”Text”>[CellProvider] </Value>
</Contains>
</Where>
Получаем:
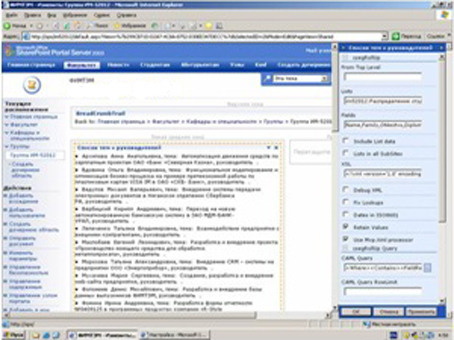
Как видим, вместо имени в запросе поставили ссылку на поле ввода текста в форме.
Теперь можно вручную набирать нужного руководителя, и поисковик найдет нужного. И выведет всех связанных с ним студентов.
II.7. RSS
RSS — семейство XML-форматов, предназначенных для описания лент новостей, анонсов статей, изменений в блогах и т. п.
В разных версиях аббревиатура RSS имела разные расшифровки:
Rich Site Summary (RSS 0.9x) — обогащённая сводка сайта;
RDF Site Summary (RSS 0.9 и 1.0) — сводка сайта с применением инфраструктуры описания ресурсов;
Really Simple Syndication (RSS 2.x) — очень простое приобретение информации.
RSS - это формат, предназначенный для публикации новостей на новостных и подобных им сайтах, начиная от таких ведущих новостных сайтов, как Wired, Slashdot, и кончая личными сетевыми дневникам. Но по сути, публиковать можно не только новости. Практически любой материал, который можно разделить на отдельные части, можно публиковать с помощью RSS: например, объявления о последних публикациях, информация об обновлениях, история изменений, внесенных в книгу. После того, как информация преобразована в формат RSS, программа, понимающая этот формат, может вытягивать сведения о внесенных изменениях и в зависимости от результата, например, автоматически предпринимать какие-либо действия.
Программы, умеющие работать с RSS, называются агрегаторами, и они очень популярны среди людей, ведущих сетевые дневники (weblog-и). Некоторые программы-дневники даже позволяют другим делать комментарии к записям. И многие дневники умеют публиковать записи в формате RSS. Программа-агрегатор позволяет вам собирать все эти публикации вместе, и вы получаете возможность одновременно следить за появлением новых новостей на всех сайтах сразу и читать их краткое содержание, не посещая каждый сайт в отдельности.
Разработка того, что впоследствии стало известно как RSS, началась ещё в 1997 году. Первую известность эта технология получила, когда компания Netscape использовала её для наполнения каналов своего портала Netcenter. Вскоре эта технология уже использовалась для трансляции контента на многих новостных сайтах — в том числе таких, как BBC, CNET, CNN, Disney, Forbes, Wired, Red Herring, Slashdot, ZDNet и многих других. Первой открытой официальной версией RSS стала версия 0.90. Формат был основан на RDF (Resource Description Framework — стандарт схемы описания источников) и многим показался слишком сложным, и тогда Netscape представила его упрощённую версию — 0.91. В 2000 году произошло разделение формата:
группа разработчиков из списка рассылки «RSS-DEV» предложила формат RSS 1.0, который был основан на стандартах XML и RDF организации W3C. Расширения формата предлагалось делать через модули расширений, описываемые в своих пространствах имён. Так как проект использует уже существующие стандарты, рассматривается его использование в рамках технологии Semantic Web.
Дейв Вайнер, работающий в компании «UserLand Software», опубликовал спецификацию RSS 0.92, которая является развитием версии 0.91 и ориентируется на тех пользователей, которым RDF-описание показалось излишне сложным. Вайнер смог популяризовать свою разработку среди многих изданий (в том числе «The New York Times») и придумал свою расшифровку аббревиатуры — Really Simple Syndication (очень простое приобретение информации). Дальнейшим развитием этой ветки стал формат RSS 2.0, который тоже поддерживает расширения с помощью модулей, лежащих в своих пространствах имён.
5 января 2006 года с сайта my.netscape.com был удален файл rss-0.91.dtd, ссылки на который были размещены в большом количестве трансляций формата RSS версии 0.91. Это событие привело к сбою некоторых онлайновых и офлайновых агрегаторов, так как потоки, ссылающиеся на этот DTD, стали невалидными.
Существует 7 различных форматов, и все они называются RSS. Как программисту, пишущему программу-агрегатор, придется сражаться со всеми этими форматами.
Netscape версия 0.90
UserLand версия 0.91. Используют для простых публикаций. Если понадобится большее, можно легко перейти на версию 2.0
UserLand версия 0.92
UserLand версия 0.93
UserLand версия 0.94
RSS-DEV Working Group версия 1.0. Для приложений, где используется RDF, либо в том случае, если нужен какой-то определенный модуль
UserLand версия 2.0. Используется для публикации новостей общего назначения
Напишем программу, которая считывает новости в формате RSS, чтобы, например, публиковать заголовки новостей на своем сайте, или чтобы создать портал новостей. Все зависит от того, о какой версии RSS идет речь. Вот пример файла в формате RSS 0.91 (урезанная версия новостей с http://www.xml.com/):
<rss version="0.91">
<channel>
<title>XML.com</title>
<link>http://www.xml.com/</link>
<description>XML.com features a rich mix of information and services for the XMLcommunity.</description>
<language>en-us</language>
<item>
<title>Normalizing XML, Part 2</title>
<link>http://www.xml.com/pub/a/2002/12/04/normalizing.html</link>
<description>In this second and final look at applying relational normalization techniques to W3C XML Schema data modeling, Will Provost discusses when not to normalize, the scope of uniqueness and the fourth and fifth normal forms.</description>
</item>
</channel>
</rss>
Блок новостей (channel) состоит из заголовка, ссылки, данных о языке новостей и описания. После этого идет список самих новостей, где в каждом пункте указывается заголовок, ссылка и краткое описание новости.
Та же самая информация выглядит в формате RSS 1.0:
<rdf:RDF xmlns:rdf=http://www.w3.org/1999/02/22-rdf-syntax-ns#xmlns="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<channel rdf:about="http://www.xml.com/cs/xml/query/q/19">
<title>XML.com</title>
<link>http://www.xml.com/</link>
<description>XML.com features a rich mix of information and services for the XML community.</description>
<language>en-us</language>
<items>
<rdf:Seq>
<rdf:li rdf:resource="http://www.xml.com/pub/a/2002/12/04/normalizing.html"/>
<rdf:li rdf:resource="http://www.xml.com/pub/a/2002/12/04/som.html"/>
<rdf:li rdf:resource="http://www.xml.com/pub/a/2002/12/04/svg.html"/>
</rdf:Seq>
</items>
</channel>
<item rdf:about="http://www.xml.com/pub/a/2002/12/04/normalizing.html">
<title>Normalizing XML, Part 2</title>
<link>http://www.xml.com/pub/a/2002/12/04/normalizing.html</link>
<description>In this second and final look at applying relational normalization techniques to W3C XML Schema data modeling...</description>
<dc:creator>Will Provost</dc:creator>
<dc:date>2002-12-04</dc:date>
</item>
</rdf:RDF>
Этот файл является RDF-документом, сохраненным в XML. В нем представлена вся та же информация, что и в первом примере. Добавлена только еще некоторая дополнительная информация, как, например, авторство каждой новости, и дату публикации, которых нет в RSS 0.91.
Несмотря на то, что RSS 1.0 является смесью RDF и XML, структурно он схож с предыдущими версиями RSS - схож достаточно, чтобы его рассматривали как обычный XML-файл. Следовательно, можно написать одну программу, которая будет уметь извлекать информацию из обоих форматов: и из RSS 0.91 и из RSS 1.0. Однако есть все-таки некоторые различия, о которых надо знать:
Корневым элементом в RSS 1.0 является rdf:RDF, а не rss. Либо придется явно обрабатывать оба этих элемента, либо просто игнорировать их и слепо извлекать только ту информацию, которая нужна.
В RSS 1.0 используются пространства имен (namespaces). Пространство имен для RSS 1.0 выглядит так http://purl.org/rss/1.0/. И это пространство имен принимается по умолчанию. Кроме того, в файле используются пространства имен http://www.w3.org/1999/02/22-rdf-syntax-ns# для элементов, специфичных для RDF, и http://purl.org/dc/elements/1.1/ (Dublin Core) для дополнительных метаданных об авторах статей и датах публикаций.
Можно пойти двумя путями: если ваш XML-парсер не понимает пространства имен, можно просто считать, что в файле используются элементы с префиксами и слепо искать в них элементы items и dc:creator. Такой способ сработает в большинстве случаев, так как в новостях формата RSS 1.0 чаще всего используется только пространство имен, принятое по умолчанию, и пространство имён Dublin Core. Конечно, данный способ - не элегантен, ведь нет никаких гарантий, что в каких-нибудь новостях не будет использовано какое-либо другое пространство имен (что вполне легально с точки зрения RDF и XML).
Если же XML-парсер понимает пространства имен, можно построить более изящное решение, которое сумеет разобрать новости и формате 0.91 и в формате 1.0.
Менее очевидный, но важный факт состоит в том, что в RSS 1.0 элементы item находятся вне элемента channel. В RSS 0.91 элементы item расположены внутри channel. В 0.90 они были снаружи. В 2.0 - они внутри. Важно точно знать, в каком элементе надо искать новости.
Наконец, можно заметить, что в элементе channel есть один элемент items. Он нужен только для RDF-парсеров (задает порядок новостей). Можно его игнорировать и считать, что все новости идут в том порядке, в каком расположены элементы item.
А так выглядит формат RSS 2.0:
<rss version="2.0" xmlns:dc="http://purl.org/dc/elements/1.1/">
<channel>
<title>XML.com</title>
<link>http://www.xml.com/</link>
<description>XML.com features a rich mix of information and services for the XML community.</description>
<language>en-us</language>
<item>
<title>Normalizing XML, Part 2</title>
<link>http://www.xml.com/pub/a/2002/12/04/normalizing.html</link>
<description>In this second and final look at applying relational normalization techniques to W3C XML Schema data modeling...</description>
<dc:creator>Will Provost</dc:creator>
<dc:date>2002-12-04</dc:date>
</item>
</channel>
</rss>
Как показывает данный пример, в RSS 2.0 тоже используются пространства имен, как и в RSS 1.0. Но это не RDF. Как и в RSS 0.91, нет пространства имен, принятого по умолчанию, а новости (в элементах item) размещены опять в элементе channel.
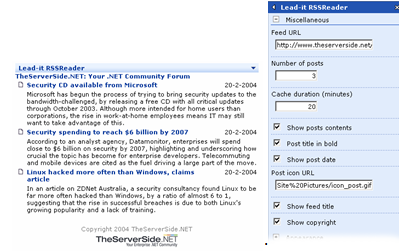
В SharePoint нет специальной веб-части, которая могла бы просматривать и создавать RSS каналы. Поэтому, как вариант, используют стороннюю веб-часть RSS Reader. Создал эту веб-часть Ян Тиленс (Jan Tielens). Выглядит это следующим образом:
Эта веб-часть достаточно гибка, в ней можно изменять следующие параметры:
URL источника
Число постов
Продолжительность показа
Показывать или нет содержание постов
Выделение названия поста
Показывать дату поста
Настройка URL картинки для постов (если никакой URL введен не будет, то не будет и картинки)
Показывать название источника
Самый легкий способ использовать эту веб-часть состоит в том, чтобы поместить Leadit.SharePoint.RSSReader.dll в GAC (на это требуется небольшое количество привилегий), и файл DWP в \wpcatalog в справочнике.
На этом моя работа с SharePoint завершена, надеюсь, я рассказал обо всех важных функциях и о том, как их можно усовершенствовать.