

Билет 18
Задание 1.
Оцените качество предлагаемого Вам программного средства учебного назначения.
Вопросы:
Каковы эргономические требования к созданию и использованию программных средств учебного назначения.
Каковы психолого-педагогические требования к созданию и использованию программных средств учебного назначения.
Что требуется от учителя, решившего использовать программные средства учебного назначения в своей практике.
Задание 2.
Произвести проверку магнитного диска только в области данных.
Произвести полную проверку поверхности диска. При этом проверять дату и время создания файлов, правильность и уникальность имен файлов.
Произвести стандартную проверку поверхности диска. При этом сообщать об ошибках длины имен файлов для режима MS DOS.
Восстановить файлы, удаленные из каталога C:\WIN\TEMP.
Восстановить все удаленные файлы, созданные при помощи программы Excel.
Восстановить все удаленные файлы.
Вопросы:
На чем основан принцип восстановления удаленных файлов и каталогов?
Для чего предназначены программы-архиваторы и за счет чего происходит сжатие файлов при архивации?
Назовите основные меры по защите от компьютерных вирусов?
2. Архивирование – это упаковка (сжатие) файла или группы файлов с целью уменьшить место, занимаемое ими на диске.
Архиватором (упаковщиком) называется программа, позволяющая за счет применения специальных методов сжатия информации создавать копии файлов меньшего размера.
Архивирование используют при хранении запасных (резервных) копий на дискетах или жестких дисках. Для упаковки файлов используются служебные программы–архиваторы, каждая из которых вместо одного или нескольких файлов создает один архивный файл. Основными характеристиками программы–архиватора являются:
степень сжатия файла (отношение размера исходного файла к размеру упакованного файла);
скорость работы;
возможности программы.
Резервное копирование – создание архивированных копий файла или группы файлов.
Если вам нужно передать много файлов по электронной почте, то для экономии времени и трафика их следует заархивировать. А так же при создании резервных копий на CD или DVD исходные данные необходимо сжать, чтобы на диске их уместилось как можно больше.
Сжатием информации в памяти компьютера называют такое ее преобразование, которое ведет к сокращению объема занимаемой памяти при сохранении закодированного содержания. Существуют разные способы сжатия для разных типов данных. Только для сжатия графической информации используется около десятка различных методов. Здесь мы рассмотрим один из способов сжатия текстовой информации.
В восьмиразрядной таблице символьной кодировки (например, ASCII) каждый символ кодируется восемью битами и, следовательно, занимает в памяти 1 байт. В разд. 1.3 нашего учебника рассказывалось о том, что частота встречаемости разных букв (знаков) в тексте — разная. Там же было показано, что информационный вес символов тем больше, чем меньше его частота встречаемости. С этим обстоятельством и связана идея сжатия текста в компьютерной памяти: отказаться от кодирования всех символов кодами одинаковой длины. Символы с меньшим информационным весом, то есть часто встречающиеся, кодировать более коротким кодом по сравнению с реже встречающимися символами. При таком подходе можно существенно сократить объем общего кода текста и соответственно места, занимаемого им в памяти компьютера.
Такой подход известен давно. Он используется в широко известной азбуке Морзе, несколько кодов которой приведены в табл. 3.1, где «точка» кодируется нулем, а «тире» — единицей.
Таблица 3.1

Как видно из этого примера и табл. 1.3, чаще встречающиеся буквы имеют более короткий код.
В отличие от кодов равной длины, которые используются в стандарте ASCII, в этом случае возникает проблема разделения между кодами отдельных букв. В азбуке Морзе эта проблема решается с помощью «паузы» (пробела), которая, по сути, является третьим символом алфавита Морзе, то есть алфавит Морзе не двух-, а трехсимвольный.
А как быть с компьютерной кодировкой, где используется двоичный алфавит? Одним из простейших, но весьма эффективных способов построения кодов разной длины, не требующих специального разделителя, является алгоритм Д. Хаффмена (D. A. Huffman, 1952 г.). С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьных кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рис. 3.2 приведен пример такого дерева, построенного для алфавита английского языка с учетом частоты встречаемости его букв.
Полученные таким образом коды можно свести в таблицу-Таблица 3.2
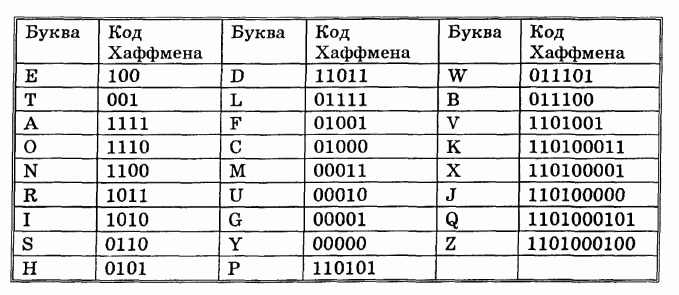
С помощью табл. 3.2 легко кодировать текст. Так, например, строка из 29 знаков
WENEEDMORESNOWFORBETTERSKIING преобразуется в код:
011101 100 1100 100 100 11011 00011 1110 1011 100 ОНО 1100 1110 011101 01001 1110 1011 011100 100 001 001 100 1011 ОНО 110100011 1010 1010 1100 00001,
который при размещении его в памяти побайтно, примет вид:
01110110 01100100 10011011 00011111 01011100 01101100 11100111 01010011 11010110 11100100 00100110 01011011 01101000 11101010 10110000001.
Таким образом, текст, занимающий в кодировке ASCII 29 байтов, в кодировке Хаффмена займет только 16 байтов.
О братная
же задача, переход от кодов Хаффмена к
буквам английского алфавита,
осуществляется с помощью двоичного
дерева (рис. 3.2). При этом перекодировка
происходит путем сканирования текста
слева направо с первого разряда,
продвигаясь по соответствующим (имеющим
тот же двоичный код) ветвям дерева до
тех пор, пока не попадем в концевую
вершину с буквой. После выделения в
коде буквы процесс раскодирования
следующей буквы начинаем снова с вершины
двоичного дерева.
братная
же задача, переход от кодов Хаффмена к
буквам английского алфавита,
осуществляется с помощью двоичного
дерева (рис. 3.2). При этом перекодировка
происходит путем сканирования текста
слева направо с первого разряда,
продвигаясь по соответствующим (имеющим
тот же двоичный код) ветвям дерева до
тех пор, пока не попадем в концевую
вершину с буквой. После выделения в
коде буквы процесс раскодирования
следующей буквы начинаем снова с вершины
двоичного дерева.
Нетрудно догадаться, что дерево на рис. 3.2 представляет сокращенный вариант кода Хаффмена. В полном объеме в нем должны быть учтены все возможные символы, встречающиеся в тексте: пробелы, знаки препинания, скобки и др.